mirror of
https://github.com/isar/libmdbx.git
synced 2025-12-16 17:12:23 +08:00
Compare commits
195 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e819099dec | ||
|
|
2689d0a71f | ||
|
|
d56c9a881e | ||
|
|
0b870648af | ||
|
|
2ff1096c49 | ||
|
|
cd1b9ea1cf | ||
|
|
31810c9957 | ||
|
|
a5cdbda9d8 | ||
|
|
b868765ddf | ||
|
|
2fc42fab7f | ||
|
|
60271687ef | ||
|
|
d6c954cd43 | ||
|
|
0b4c957bd5 | ||
|
|
e73df34619 | ||
|
|
f7bd98a4ce | ||
|
|
82c975e174 | ||
|
|
4117c9f111 | ||
|
|
b52e878c4f | ||
|
|
c4e1c2b488 | ||
|
|
60bba72aa1 | ||
|
|
8e8b40e7a2 | ||
|
|
ab5668cf29 | ||
|
|
d6d03639a2 | ||
|
|
137f443e57 | ||
|
|
c6dccdc91a | ||
|
|
c287f88dbd | ||
|
|
844e39ebef | ||
|
|
01ae5bad7d | ||
|
|
68fd9c9908 | ||
|
|
940138fbda | ||
|
|
79633ecfd7 | ||
|
|
35cf4bb60f | ||
|
|
a91eef0c0f | ||
|
|
ff336fa65e | ||
|
|
5cc4bec7b7 | ||
|
|
49a3e04d92 | ||
|
|
0a6af9bca0 | ||
|
|
bcbf040f5d | ||
|
|
40edf7e323 | ||
|
|
c945359858 | ||
|
|
d299a2601d | ||
|
|
1fca3d4c93 | ||
|
|
6043181636 | ||
|
|
5a461a84e0 | ||
|
|
bf29182eda | ||
|
|
b4eb9dda5c | ||
|
|
f25c20693f | ||
|
|
30949031c1 | ||
|
|
bf22699fb3 | ||
|
|
e08409d209 | ||
|
|
70c796463b | ||
|
|
3b80b358e5 | ||
|
|
561d30518a | ||
|
|
01e016e6aa | ||
|
|
94aa20febc | ||
|
|
f22c0856bf | ||
|
|
76f7c118c6 | ||
|
|
ff738f1512 | ||
|
|
36fe81edad | ||
|
|
8cd0107e6a | ||
|
|
cbd0b42e20 | ||
|
|
6d33c137f6 | ||
|
|
78143d9a48 | ||
|
|
6206b67d32 | ||
|
|
771ac1928b | ||
|
|
b6aace0825 | ||
|
|
a30828b457 | ||
|
|
ecb0e268b0 | ||
|
|
859f306c9f | ||
|
|
82ff482a0a | ||
|
|
b2ddd49b77 | ||
|
|
69c14f3694 | ||
|
|
22e7630d53 | ||
|
|
a150b791a4 | ||
|
|
94b1553637 | ||
|
|
f1bb2f1ec2 | ||
|
|
64fb9b81f3 | ||
|
|
6fb628d88d | ||
|
|
7ffff48fdc | ||
|
|
cbafb3f471 | ||
|
|
7ce1a4c0cf | ||
|
|
e00dce3543 | ||
|
|
8f51b6bac2 | ||
|
|
438bda3ee3 | ||
|
|
6be164a45b | ||
|
|
3cf6bc0639 | ||
|
|
6b5d973a31 | ||
|
|
99934bc845 | ||
|
|
2b305d33a3 | ||
|
|
5051603c56 | ||
|
|
102f57dd15 | ||
|
|
f4cd7b5418 | ||
|
|
0ecc5226d6 | ||
|
|
289da70a67 | ||
|
|
96bdf6559e | ||
|
|
0be592530e | ||
|
|
6ce08100fa | ||
|
|
c3a9ad52ed | ||
|
|
7c5d24f99a | ||
|
|
3a8d73b7ef | ||
|
|
5c06a4c917 | ||
|
|
02f3230e0c | ||
|
|
e25b30b5ce | ||
|
|
676fc941f1 | ||
|
|
f62bb4b6a7 | ||
|
|
e7da946fac | ||
|
|
7498286e3a | ||
|
|
3bc339ef19 | ||
|
|
3a2ea85c79 | ||
|
|
e9d63315d1 | ||
|
|
073ee8888c | ||
|
|
ceac458b4e | ||
|
|
20022658be | ||
|
|
3c87e02716 | ||
|
|
51b89c9690 | ||
|
|
ee21afce1e | ||
|
|
8966a1773c | ||
|
|
f373a0ca84 | ||
|
|
8abff4773f | ||
|
|
25fc9305dd | ||
|
|
93a71c29e7 | ||
|
|
30b084724a | ||
|
|
e3ff19a722 | ||
|
|
f58185afa6 | ||
|
|
8364427d02 | ||
|
|
15a9fb9b98 | ||
|
|
2791224542 | ||
|
|
c362ad9465 | ||
|
|
3727a2a099 | ||
|
|
490addef18 | ||
|
|
c7a6e9c8ae | ||
|
|
8acc1979bb | ||
|
|
f371f10743 | ||
|
|
7aab221bf4 | ||
|
|
e7d4d24265 | ||
|
|
b41bef8307 | ||
|
|
a0d10e41b8 | ||
|
|
08fa2c1746 | ||
|
|
ffdd487037 | ||
|
|
0797ae2270 | ||
|
|
0f63ab0385 | ||
|
|
cb081424ff | ||
|
|
d3e9626a15 | ||
|
|
8b24c65119 | ||
|
|
3e9e52e0ce | ||
|
|
434f0d5b57 | ||
|
|
3964c58b80 | ||
|
|
c43b7d1aba | ||
|
|
26c4b673c4 | ||
|
|
6b5ada7b6e | ||
|
|
111befb695 | ||
|
|
559e7bc8de | ||
|
|
1d716c043d | ||
|
|
bc45eb30fb | ||
|
|
c472300b13 | ||
|
|
b4fd29a67b | ||
|
|
e0fcd6e0ec | ||
|
|
6a51343b89 | ||
|
|
d72ba6fd69 | ||
|
|
275b80e086 | ||
|
|
cb70cb18fc | ||
|
|
5ed725dc29 | ||
|
|
e06ab1d2a5 | ||
|
|
ac54a3959d | ||
|
|
5a1f388db5 | ||
|
|
da98692273 | ||
|
|
dd4da591af | ||
|
|
dbf66ec0bb | ||
|
|
32c63077a4 | ||
|
|
21858201e0 | ||
|
|
dfea68270a | ||
|
|
f425e98eb5 | ||
|
|
20a61f273c | ||
|
|
8e0f5bea4a | ||
|
|
c9d0c8edeb | ||
|
|
e57d4bbb00 | ||
|
|
797bcf9aca | ||
|
|
ba1387b791 | ||
|
|
d90e6187f7 | ||
|
|
9e81d5b631 | ||
|
|
639e639fa3 | ||
|
|
f4a01da47f | ||
|
|
b9d3eac12e | ||
|
|
40d5db2418 | ||
|
|
bc77ab3cca | ||
|
|
31b5f64054 | ||
|
|
9b39b959de | ||
|
|
40ec114048 | ||
|
|
b57c3b2503 | ||
|
|
f625b6cb42 | ||
|
|
0dfa9cd09a | ||
|
|
09ad941a05 | ||
|
|
28eda32c12 | ||
|
|
fc41cd64d1 | ||
|
|
9f2bf6a377 |
860
README-RU.md
860
README-RU.md
@@ -12,31 +12,31 @@ and [by Yandex](https://translate.yandex.ru/translate?url=https%3A%2F%2Fgithub.c
|
||||
|
||||
### Project Status
|
||||
|
||||
**Сейчас MDBX _активно перерабатывается_** и к середине 2018 ожидается
|
||||
большое изменение как API, так и формата базы данных. К сожалению,
|
||||
обновление приведет к потере совместимости с предыдущими версиями.
|
||||
|
||||
**Сейчас MDBX _активно перерабатывается_** и к середине 2018
|
||||
ожидается большое изменение как API, так и формата базы данных.
|
||||
К сожалению, обновление приведет к потере совместимости с
|
||||
предыдущими версиями.
|
||||
Цель этой революции - обеспечение более четкого надежного API и
|
||||
добавление новых функции, а также наделение базы данных новыми
|
||||
свойствами.
|
||||
|
||||
Цель этой революции - обеспечение более четкого надежного
|
||||
API и добавление новых функции, а также наделение базы данных
|
||||
новыми свойствами.
|
||||
|
||||
В настоящее время MDBX предназначена для Linux, а также
|
||||
поддерживает Windows (начиная с Windows Server 2008) в качестве
|
||||
дополнительной платформы. Поддержка других ОС может быть
|
||||
обеспечена на коммерческой основе. Однако такие
|
||||
усовершенствования (т. е. pull-requests) могут быть приняты в
|
||||
мейнстрим только в том случае, если будет доступен
|
||||
соответствующий публичный и бесплатный сервис непрерывной
|
||||
интеграции (aka Continuous Integration).
|
||||
В настоящее время MDBX предназначена для Linux, а также поддерживает
|
||||
Windows (начиная с Windows Server 2008) в качестве дополнительной
|
||||
платформы. Поддержка других ОС может быть обеспечена на коммерческой
|
||||
основе. Однако такие усовершенствования (т. е. pull-requests) могут быть
|
||||
приняты в мейнстрим только в том случае, если будет доступен
|
||||
соответствующий публичный и бесплатный сервис непрерывной интеграции
|
||||
(aka Continuous Integration).
|
||||
|
||||
## Содержание
|
||||
|
||||
- [Обзор](#Обзор)
|
||||
- [Сравнение с другими СУБД](#Сравнение-с-другими-СУБД)
|
||||
- [История & Acknowledgments](#История)
|
||||
- [Основные свойства](#Основные-свойства)
|
||||
- [Доработки и усовершенствования относительно LMDB](#Доработки-и-усовершенствования-относительно-lmdb)
|
||||
- [Недостатки и Компромиссы](#Недостатки-и-Компромиссы)
|
||||
- [Проблема долгих чтений](#Проблема-долгих-чтений)
|
||||
- [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации)
|
||||
- [Сравнение производительности](#Сравнение-производительности)
|
||||
- [Интегральная производительность](#Интегральная-производительность)
|
||||
- [Масштабируемость чтения](#Масштабируемость-чтения)
|
||||
@@ -44,21 +44,18 @@ API и добавление новых функции, а также надел
|
||||
- [Отложенная фиксация](#Отложенная-фиксация)
|
||||
- [Асинхронная фиксация](#Асинхронная-фиксация)
|
||||
- [Потребление ресурсов](#Потребление-ресурсов)
|
||||
- [Недостатки и Компромиссы](#Недостатки-и-Компромиссы)
|
||||
- [Проблема долгих чтений](#Проблема-долгих-чтений)
|
||||
- [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации)
|
||||
- [Доработки и усовершенствования относительно LMDB](#Доработки-и-усовершенствования-относительно-lmdb)
|
||||
|
||||
|
||||
## Обзор
|
||||
|
||||
_libmdbx_ - это встраиваемый key-value движок хранения со специфическим
|
||||
набором свойств и возможностей, ориентированный на создание уникальных
|
||||
легковесных решений с предельной производительностью под Linux и Windows.
|
||||
легковесных решений с предельной производительностью под Linux и
|
||||
Windows.
|
||||
|
||||
_libmdbx_ позволяет множеству процессов совместно читать и обновлять
|
||||
несколько key-value таблиц с соблюдением [ACID](https://ru.wikipedia.org/wiki/ACID),
|
||||
при минимальных накладных расходах и амортизационной стоимости любых операций Olog(N).
|
||||
несколько key-value таблиц с соблюдением
|
||||
[ACID](https://ru.wikipedia.org/wiki/ACID), при минимальных накладных
|
||||
расходах и амортизационной стоимости любых операций Olog(N).
|
||||
|
||||
_libmdbx_ обеспечивает
|
||||
[serializability](https://en.wikipedia.org/wiki/Serializability)
|
||||
@@ -72,20 +69,26 @@ _libmdbx_ позволяет выполнять операции чтения с
|
||||
параллельно на каждом ядре CPU, без использования атомарных операций
|
||||
и/или примитивов синхронизации.
|
||||
|
||||
_libmdbx_ не использует [LSM](https://en.wikipedia.org/wiki/Log-structured_merge-tree), а основан на [B+Tree](https://en.wikipedia.org/wiki/B%2B_tree) с [отображением](https://en.wikipedia.org/wiki/Memory-mapped_file) всех данных в память,
|
||||
при этом текущая версия не использует [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging).
|
||||
Это предопределяет многие свойства, в том числе удачные и противопоказанные сценарии использования.
|
||||
_libmdbx_ не использует
|
||||
[LSM](https://en.wikipedia.org/wiki/Log-structured_merge-tree), а
|
||||
основан на [B+Tree](https://en.wikipedia.org/wiki/B%2B_tree) с
|
||||
[отображением](https://en.wikipedia.org/wiki/Memory-mapped_file) всех
|
||||
данных в память, при этом текущая версия не использует
|
||||
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). Это
|
||||
предопределяет многие свойства, в том числе удачные и противопоказанные
|
||||
сценарии использования.
|
||||
|
||||
|
||||
### Сравнение с другими СУБД
|
||||
|
||||
Ввиду того, что в _libmdbx_ сейчас происходит революция, я посчитал лучшим решением
|
||||
ограничится здесь ссылкой на [главу Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) в описании _BoltDB_.
|
||||
Ввиду того, что в _libmdbx_ сейчас происходит революция, я посчитал
|
||||
лучшим решением ограничится здесь ссылкой на [главу Comparison with
|
||||
other databases](https://github.com/coreos/bbolt#comparison-with-other-databases)
|
||||
в описании _BoltDB_.
|
||||
|
||||
|
||||
### История
|
||||
|
||||
_libmdbx_ является результатом переработки и развития "Lightning Memory-Mapped Database",
|
||||
известной под аббревиатурой
|
||||
_libmdbx_ является результатом переработки и развития "Lightning
|
||||
Memory-Mapped Database", известной под аббревиатурой
|
||||
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
Изначально доработка производилась в составе проекта
|
||||
[ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP). Примерно за год
|
||||
@@ -102,63 +105,410 @@ Technologies](https://www.ptsecurity.ru).
|
||||
|
||||
|
||||
#### Acknowledgments
|
||||
Howard Chu (Symas Corporation) - the author of LMDB, from which
|
||||
originated the MDBX in 2015.
|
||||
|
||||
Howard Chu (Symas Corporation) - the author of LMDB,
|
||||
from which originated the MDBX in 2015.
|
||||
|
||||
Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code,
|
||||
which was used for begin development of LMDB.
|
||||
Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code, which
|
||||
was used for begin development of LMDB.
|
||||
|
||||
|
||||
Основные свойства
|
||||
=================
|
||||
|
||||
_libmdbx_ наследует все ключевые возможности и особенности
|
||||
своего прародителя [LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database),
|
||||
но с устранением ряда описываемых далее проблем и архитектурных недочетов.
|
||||
_libmdbx_ наследует все ключевые возможности и особенности своего
|
||||
прародителя
|
||||
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database),
|
||||
но с устранением ряда описываемых далее проблем и архитектурных
|
||||
недочетов.
|
||||
|
||||
1. Данные хранятся в упорядоченном отображении (ordered map), ключи всегда
|
||||
отсортированы, поддерживается выборка диапазонов (range lookups).
|
||||
1. Данные хранятся в упорядоченном отображении (ordered map), ключи
|
||||
всегда отсортированы, поддерживается выборка диапазонов (range lookups).
|
||||
|
||||
2. Данные отображается в память каждого работающего с БД процесса.
|
||||
К данным и ключам обеспечивается прямой доступ в памяти без необходимости их
|
||||
копирования.
|
||||
2. Данные отображается в память каждого работающего с БД процесса. К
|
||||
данным и ключам обеспечивается прямой доступ в памяти без необходимости
|
||||
их копирования.
|
||||
|
||||
3. Транзакции согласно
|
||||
[ACID](https://ru.wikipedia.org/wiki/ACID), посредством
|
||||
[MVCC](https://ru.wikipedia.org/wiki/MVCC) и
|
||||
[COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8).
|
||||
Изменения строго последовательны и не блокируются чтением,
|
||||
конфликты между транзакциями невозможны.
|
||||
При этом гарантируется чтение только зафиксированных данных, см [relaxing serializability](https://en.wikipedia.org/wiki/Serializability).
|
||||
3. Транзакции согласно [ACID](https://ru.wikipedia.org/wiki/ACID),
|
||||
посредством [MVCC](https://ru.wikipedia.org/wiki/MVCC) и
|
||||
[COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8).
|
||||
Изменения строго последовательны и не блокируются чтением, конфликты
|
||||
между транзакциями невозможны. При этом гарантируется чтение только
|
||||
зафиксированных данных, см [relaxing
|
||||
serializability](https://en.wikipedia.org/wiki/Serializability).
|
||||
|
||||
4. Чтение и поиск [без блокировок](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B1%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B0%D1%8F_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F),
|
||||
без [атомарных операций](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F).
|
||||
Читатели не блокируются операциями записи и не конкурируют
|
||||
между собой, чтение масштабируется линейно по ядрам CPU.
|
||||
4. Чтение и поиск [без
|
||||
блокировок](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B1%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B0%D1%8F_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F),
|
||||
без [атомарных
|
||||
операций](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F).
|
||||
Читатели не блокируются операциями записи и не конкурируют между собой,
|
||||
чтение масштабируется линейно по ядрам CPU.
|
||||
> Для точности следует отметить, что "подключение к БД" (старт первой
|
||||
> читающей транзакции в потоке) и "отключение от БД" (закрытие БД или
|
||||
> завершение потока) требуют краткосрочного захвата блокировки для
|
||||
> регистрации/дерегистрации текущего потока в "таблице читателей".
|
||||
|
||||
5. Эффективное хранение дубликатов (ключей с несколькими
|
||||
значениями), без дублирования ключей, с сортировкой значений, в
|
||||
том числе целочисленных (для вторичных индексов).
|
||||
5. Эффективное хранение дубликатов (ключей с несколькими значениями),
|
||||
без дублирования ключей, с сортировкой значений, в том числе
|
||||
целочисленных (для вторичных индексов).
|
||||
|
||||
6. Эффективная поддержка коротких ключей фиксированной длины, в том числе целочисленных.
|
||||
6. Эффективная поддержка коротких ключей фиксированной длины, в том
|
||||
числе целочисленных.
|
||||
|
||||
7. Амортизационная стоимость любой операции Olog(N),
|
||||
[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor) и RAF (Read Amplification Factor) также Olog(N).
|
||||
|
||||
8. Нет [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) и
|
||||
журнала транзакций, после сбоев не требуется восстановление. Не
|
||||
требуется компактификация или какое-либо периодическое обслуживание.
|
||||
Поддерживается резервное копирование "по горячему", на работающей БД без
|
||||
приостановки изменения данных.
|
||||
|
||||
9. Отсутствует какое-либо внутреннее управление памятью или
|
||||
кэшированием. Всё необходимое штатно выполняет ядро ОС.
|
||||
|
||||
|
||||
Доработки и усовершенствования относительно LMDB
|
||||
================================================
|
||||
|
||||
1. Утилита `mdbx_chk` для проверки целостности структуры БД.
|
||||
|
||||
2. Автоматическое динамическое управление размером БД согласно
|
||||
параметрам задаваемым функцией `mdbx_env_set_geometry()`, включая шаг
|
||||
приращения и порог уменьшения размера БД, а также выбор размера
|
||||
страницы. Соответственно, это позволяет снизить фрагментированность
|
||||
файла БД на диске и освободить место, в том числе в **Windows**.
|
||||
|
||||
3. Автоматическая без-затратная компактификация БД путем возврата
|
||||
освобождающихся страниц в область нераспределенного резерва в конце
|
||||
файла данных. При этом уменьшается количество страниц находящихся в
|
||||
памяти и участвующих в в обмене с диском.
|
||||
|
||||
4. Поддержка ключей и значений нулевой длины, включая сортированные
|
||||
дубликаты.
|
||||
|
||||
5. Возможность связать с каждой завершаемой транзакцией до 3
|
||||
дополнительных маркеров посредством `mdbx_canary_put()`, и прочитать их
|
||||
в транзакции чтения посредством `mdbx_canary_get()`.
|
||||
|
||||
6. Возможность посредством `mdbx_replace()` обновить или удалить запись
|
||||
с получением предыдущего значения данных, а также адресно изменить
|
||||
конкретное multi-значение.
|
||||
|
||||
7. Режим `LIFO RECLAIM`.
|
||||
|
||||
Для повторного использования выбираются не самые старые, а
|
||||
самые новые страницы из доступных. За счет этого цикл
|
||||
использования страниц всегда имеет минимальную длину и не
|
||||
зависит от общего числа выделенных страниц.
|
||||
|
||||
В результате механизмы кэширования и обратной записи работают с
|
||||
максимально возможной эффективностью. В случае использования
|
||||
контроллера дисков или системы хранения с
|
||||
[BBWC](https://en.wikipedia.org/wiki/BBWC) возможно
|
||||
многократное увеличение производительности по записи
|
||||
(обновлению данных).
|
||||
|
||||
8. Генерация последовательностей посредством `mdbx_dbi_sequence()`.
|
||||
|
||||
9. Обработчик `OOM-KICK`.
|
||||
|
||||
Посредством `mdbx_env_set_oomfunc()` может быть установлен
|
||||
внешний обработчик (callback), который будет вызван при
|
||||
исчерпании свободных страниц по причине долгой операцией чтения
|
||||
на фоне интенсивного изменения данных.
|
||||
Обработчику будет передан PID и pthread_id виновника.
|
||||
В свою очередь обработчик может предпринять одно из действий:
|
||||
|
||||
* нейтрализовать виновника (отправить сигнал kill #9), если
|
||||
долгое чтение выполняется сторонним процессом;
|
||||
|
||||
* отменить или перезапустить проблемную операцию чтения, если
|
||||
операция выполняется одним из потоков текущего процесса;
|
||||
|
||||
* подождать некоторое время, в расчете на то, что проблемная операция
|
||||
чтения будет штатно завершена;
|
||||
|
||||
* прервать текущую операцию изменения данных с возвратом кода
|
||||
ошибки.
|
||||
|
||||
10. Возможность открыть БД в эксклюзивном режиме посредством флага
|
||||
`MDBX_EXCLUSIVE`.
|
||||
|
||||
11. Возможность получить отставание текущей транзакции чтения от
|
||||
последней версии данных в БД посредством `mdbx_txn_straggler()`.
|
||||
|
||||
12. Возможность явно запросить обновление существующей записи, без
|
||||
создания новой посредством флажка `MDBX_CURRENT` для `mdbx_put()`.
|
||||
|
||||
13. Исправленный вариант `mdbx_cursor_count()`, возвращающий корректное
|
||||
количество дубликатов для всех типов таблиц и любого положения курсора.
|
||||
|
||||
14. Возможность получить посредством `mdbx_env_info()` дополнительную
|
||||
информацию, включая номер самой старой версии БД (снимка данных),
|
||||
который используется одним из читателей.
|
||||
|
||||
15. Функция `mdbx_del()` не игнорирует дополнительный (уточняющий)
|
||||
аргумент `data` для таблиц без дубликатов (без флажка `MDBX_DUPSORT`), а
|
||||
при его ненулевом значении всегда использует его для сверки с удаляемой
|
||||
записью.
|
||||
|
||||
16. Возможность открыть dbi-таблицу, одновременно с установкой
|
||||
компараторов для ключей и данных, посредством `mdbx_dbi_open_ex()`.
|
||||
|
||||
17. Возможность посредством `mdbx_is_dirty()` определить находятся ли
|
||||
некоторый ключ или данные в "грязной" странице БД. Таким образом,
|
||||
избегая лишнего копирования данных перед выполнением модифицирующих
|
||||
операций (значения, размещенные в "грязных" страницах, могут быть
|
||||
перезаписаны при изменениях, иначе они будут неизменны).
|
||||
|
||||
18. Корректное обновление текущей записи, в том числе сортированного
|
||||
дубликата, при использовании режима `MDBX_CURRENT` в
|
||||
`mdbx_cursor_put()`.
|
||||
|
||||
19. Возможность узнать есть ли за текущей позицией курсора строка данных
|
||||
посредством `mdbx_cursor_eof()`.
|
||||
|
||||
20. Дополнительный код ошибки `MDBX_EMULTIVAL`, который возвращается из
|
||||
`mdbx_put()` и `mdbx_replace()` при попытке выполнить неоднозначное
|
||||
обновление или удаления одного из нескольких значений с одним ключом.
|
||||
|
||||
21. Возможность посредством `mdbx_get_ex()` получить значение по
|
||||
заданному ключу, одновременно с количеством дубликатов.
|
||||
|
||||
22. Наличие функций `mdbx_cursor_on_first()` и `mdbx_cursor_on_last()`,
|
||||
которые позволяют быстро выяснить стоит ли курсор на первой/последней
|
||||
позиции.
|
||||
|
||||
23. Возможность автоматического формирования контрольных точек (сброса
|
||||
данных на диск) при накоплении заданного объёма изменений,
|
||||
устанавливаемого функцией `mdbx_env_set_syncbytes()`.
|
||||
|
||||
24. Управление отладкой и получение отладочных сообщений посредством
|
||||
`mdbx_setup_debug()`.
|
||||
|
||||
25. Функция `mdbx_env_pgwalk()` для обхода всех страниц БД.
|
||||
|
||||
26. Три мета-страницы вместо двух, что позволяет гарантированно
|
||||
консистентно обновлять слабые контрольные точки фиксации без риска
|
||||
повредить крайнюю сильную точку фиксации.
|
||||
|
||||
27. Гарантия сохранности БД в режиме `WRITEMAP+MAPSYNC`.
|
||||
> В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
> режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC`
|
||||
> когда при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
> Для подробностей смотрите раздел
|
||||
> [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации).
|
||||
|
||||
28. Возможность закрыть БД в "грязном" состоянии (без сброса данных и
|
||||
формирования сильной точки фиксации) посредством `mdbx_env_close_ex()`.
|
||||
|
||||
29. При завершении читающих транзакций, открытые в них DBI-хендлы не
|
||||
закрываются и не теряются при завершении таких транзакций посредством
|
||||
`mdbx_txn_abort()` или `mdbx_txn_reset()`. Что позволяет избавится от ряда
|
||||
сложно обнаруживаемых ошибок.
|
||||
|
||||
30. Все курсоры, как в транзакциях только для чтения, так и в пишущих,
|
||||
могут быть переиспользованы посредством `mdbx_cursor_renew()` и ДОЛЖНЫ
|
||||
ОСВОБОЖДАТЬСЯ ЯВНО.
|
||||
>
|
||||
> ## _ВАЖНО_, Обратите внимание!
|
||||
>
|
||||
> Это единственное изменение в API, которое значимо меняет
|
||||
> семантику управления курсорами и может приводить к утечкам
|
||||
> памяти. Следует отметить, что это изменение вынужденно.
|
||||
> Так устраняется неоднозначность с массой тяжких последствий:
|
||||
>
|
||||
> - обращение к уже освобожденной памяти;
|
||||
> - попытки повторного освобождения памяти;
|
||||
> - повреждение памяти и ошибки сегментации.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
## Недостатки и Компромиссы
|
||||
|
||||
1. Единовременно может выполняться не более одной транзакция изменения данных
|
||||
(один писатель). Зато все изменения всегда последовательны, не может быть
|
||||
конфликтов или логических ошибок при откате транзакций.
|
||||
|
||||
2. Отсутствие [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging)
|
||||
обуславливает относительно большой
|
||||
[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor) и RAF (Read Amplification Factor) также Olog(N).
|
||||
Amplification Factor). Поэтому фиксация изменений на диске может быть
|
||||
достаточно дорогой и являться главным ограничением производительности
|
||||
при интенсивном изменении данных.
|
||||
> В качестве компромисса _libmdbx_ предлагает несколько режимов ленивой
|
||||
> и/или периодической фиксации. В том числе режим `MAPASYNC`, при котором
|
||||
> изменения происходят только в памяти и асинхронно фиксируются на диске
|
||||
> ядром ОС.
|
||||
>
|
||||
> Однако, следует воспринимать это свойство аккуратно и взвешенно.
|
||||
> Например, полная фиксация транзакции в БД с журналом потребует минимум 2
|
||||
> IOPS (скорее всего 3-4) из-за накладных расходов в файловой системе. В
|
||||
> _libmdbx_ фиксация транзакции также требует от 2 IOPS. Однако, в БД с
|
||||
> журналом кол-во IOPS будет меняться в зависимости от файловой системы,
|
||||
> но не от кол-ва записей или их объема. Тогда как в _libmdbx_ кол-во
|
||||
> будет расти логарифмически от кол-ва записей/строк в БД (по высоте
|
||||
> b+tree).
|
||||
|
||||
8. Нет [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) и журнала
|
||||
транзакций, после сбоев не требуется восстановление. Не требуется компактификация
|
||||
или какое-либо периодическое обслуживание. Поддерживается резервное копирование
|
||||
"по горячему", на работающей БД без приостановки изменения данных.
|
||||
3. [COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8)
|
||||
для реализации [MVCC](https://ru.wikipedia.org/wiki/MVCC) выполняется на
|
||||
уровне страниц в [B+
|
||||
дереве](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
||||
Поэтому изменение данных амортизационно требует копирования Olog(N)
|
||||
страниц, что расходует [пропускную способность оперативной
|
||||
памяти](https://en.wikipedia.org/wiki/Memory_bandwidth) и является
|
||||
основным ограничителем производительности в режиме `MAPASYNC`.
|
||||
> Этот недостаток неустраним, тем не менее следует дать некоторые пояснения.
|
||||
> Дело в том, что фиксация изменений на диске потребует гораздо более
|
||||
> значительного копирования данных в памяти и массы других затратных операций.
|
||||
> Поэтому обусловленное этим недостатком падение производительности становится
|
||||
> заметным только при отказе от фиксации изменений на диске.
|
||||
> Соответственно, корректнее сказать, что _libmdbx_ позволяет
|
||||
> получить персистентность ценой минимального падения производительности.
|
||||
> Если же нет необходимости оперативно сохранять данные, то логичнее
|
||||
> использовать `std::map`.
|
||||
|
||||
9. Отсутствует какое-либо внутреннее управление памятью или кэшированием. Всё
|
||||
необходимое штатно выполняет ядро ОС!
|
||||
4. В _LMDB_ существует проблема долгих чтений (приостановленных читателей),
|
||||
которая приводит к деградации производительности и переполнению БД.
|
||||
> В _libmdbx_ предложены средства для предотвращения, быстрого выхода из
|
||||
> некомфортной ситуации и устранения её последствий. Подробности ниже.
|
||||
|
||||
5. В _LMDB_ есть вероятность разрушения БД в режиме `WRITEMAP+MAPASYNC`.
|
||||
В _libmdbx_ для `WRITEMAP+MAPASYNC` гарантируется как сохранность базы,
|
||||
так и согласованность данных.
|
||||
> Дополнительно, в качестве альтернативы, предложен режим `UTTERLY_NOSYNC`.
|
||||
> Подробности ниже.
|
||||
|
||||
|
||||
#### Проблема долгих чтений
|
||||
*Следует отметить*, что проблема "сборки мусора" так или иначе
|
||||
существует во всех СУБД (Vacuum в PostgreSQL). Однако в случае _libmdbx_
|
||||
и LMDB она проявляется более остро, прежде всего из-за высокой
|
||||
производительности, а также из-за намеренного упрощения внутренних
|
||||
механизмов ради производительности.
|
||||
|
||||
Понимание проблемы требует некоторых пояснений, которые
|
||||
изложены ниже, но могут быть сложны для быстрого восприятия.
|
||||
Поэтому, тезисно:
|
||||
|
||||
* Изменение данных на фоне долгой операции чтения может
|
||||
приводить к исчерпанию места в БД.
|
||||
|
||||
* После чего любая попытка обновить данные будет приводить к
|
||||
ошибке `MAP_FULL` до завершения долгой операции чтения.
|
||||
|
||||
* Характерными примерами долгих чтений являются горячее
|
||||
резервное копирования и отладка клиентского приложения при
|
||||
активной транзакции чтения.
|
||||
|
||||
* В оригинальной _LMDB_ после этого будет наблюдаться
|
||||
устойчивая деградация производительности всех механизмов
|
||||
обратной записи на диск (в I/O контроллере, в гипервизоре,
|
||||
в ядре ОС).
|
||||
|
||||
* В _libmdbx_ предусмотрен механизм аварийного прерывания таких
|
||||
операций, а также режим `LIFO RECLAIM` устраняющий последующую
|
||||
деградацию производительности.
|
||||
|
||||
Операции чтения выполняются в контексте снимка данных (версии
|
||||
БД), который был актуальным на момент старта транзакции чтения. Такой
|
||||
читаемый снимок поддерживается неизменным до завершения операции. В свою
|
||||
очередь, это не позволяет повторно использовать страницы БД в
|
||||
последующих версиях (снимках БД).
|
||||
|
||||
Другими словами, если обновление данных выполняется на фоне долгой
|
||||
операции чтения, то вместо повторного использования "старых" ненужных
|
||||
страниц будут выделяться новые, так как "старые" страницы составляют
|
||||
снимок БД, который еще используется долгой операцией чтения.
|
||||
|
||||
В результате, при интенсивном изменении данных и достаточно длительной
|
||||
операции чтения, в БД могут быть исчерпаны свободные страницы, что не
|
||||
позволит создавать новые снимки/версии БД. Такая ситуация будет
|
||||
сохраняться до завершения операции чтения, которая использует старый
|
||||
снимок данных и препятствует повторному использованию страниц БД.
|
||||
|
||||
Однако, на этом проблемы не заканчиваются. После описанной ситуации, все
|
||||
дополнительные страницы, которые были выделены пока переработка старых
|
||||
была невозможна, будут участвовать в цикле выделения/освобождения до
|
||||
конца жизни экземпляра БД. В оригинальной _LMDB_ этот цикл использования
|
||||
страниц работает по принципу [FIFO](https://ru.wikipedia.org/wiki/FIFO).
|
||||
Поэтому увеличение количества циркулирующий страниц, с точки зрения
|
||||
механизмов кэширования и/или обратной записи, выглядит как увеличение
|
||||
рабочего набор данных. Проще говоря, однократное попадание в ситуацию
|
||||
"уснувшего читателя" приводит к устойчивому эффекту вымывания I/O кэша
|
||||
при всех последующих изменениях данных.
|
||||
|
||||
Для устранения описанных проблемы в _libmdbx_ сделаны существенные
|
||||
доработки, подробности ниже. Иллюстрации к проблеме "долгих чтений"
|
||||
можно найти в [слайдах презентации](http://www.slideshare.net/leoyuriev/lmdb).
|
||||
|
||||
Там же приведен пример количественной оценки прироста производительности
|
||||
за счет эффективной работы [BBWC](https://en.wikipedia.org/wiki/BBWC)
|
||||
при включении `LIFO RECLAIM` в _libmdbx_.
|
||||
|
||||
#### Сохранность данных в режиме асинхронной фиксации
|
||||
При работе в режиме `WRITEMAP+MAPSYNC` запись измененных страниц
|
||||
выполняется ядром ОС, что имеет ряд преимуществ. Так например, при крахе
|
||||
приложения, ядро ОС сохранит все изменения.
|
||||
|
||||
Однако, при аварийном отключении питания или сбое в ядре ОС, на диске
|
||||
может быть сохранена только часть измененных страниц БД. При этом с
|
||||
большой вероятностью может оказаться, что будут сохранены мета-страницы
|
||||
со ссылками на страницы с новыми версиями данных, но не сами новые
|
||||
данные. В этом случае БД будет безвозвратна разрушена, даже если до
|
||||
аварии производилась полная синхронизация данных (посредством
|
||||
`mdbx_env_sync()`).
|
||||
|
||||
В _libmdbx_ эта проблема устранена путем полной переработки
|
||||
пути записи данных:
|
||||
|
||||
* В режиме `WRITEMAP+MAPSYNC` _libmdbx_ не обновляет
|
||||
мета-страницы непосредственно, а поддерживает их теневые копии
|
||||
с переносом изменений после фиксации данных.
|
||||
|
||||
* При завершении транзакций, в зависимости от состояния
|
||||
синхронности данных между диском и оперативной памятью,
|
||||
_libmdbx_ помечает точки фиксации либо как сильные (strong),
|
||||
либо как слабые (weak). Так например, в режиме
|
||||
`WRITEMAP+MAPSYNC` завершаемые транзакции помечаются как
|
||||
слабые, а при явной синхронизации данных - как сильные.
|
||||
|
||||
* В _libmdbx_ поддерживается не две, а три отдельные мета-страницы.
|
||||
Это позволяет выполнять фиксацию транзакций с формированием как
|
||||
сильной, так и слабой точки фиксации, без потери двух предыдущих
|
||||
точек фиксации (из которых одна может быть сильной, а вторая слабой).
|
||||
В результате, _libmdbx_ позволяет в произвольном порядке чередовать
|
||||
сильные и слабые точки фиксации без нарушения соответствующих
|
||||
гарантий в случае неожиданной системной аварии во время фиксации.
|
||||
|
||||
* При открытии БД выполняется автоматический откат к последней
|
||||
сильной фиксации. Этим обеспечивается гарантия сохранности БД.
|
||||
|
||||
Такая гарантия надежности не дается бесплатно. Для сохранности данных,
|
||||
страницы, формирующие крайний снимок с сильной фиксацией, не должны
|
||||
повторно использоваться (перезаписываться) до формирования следующей
|
||||
сильной точки фиксации. Таким образом, крайняя точка фиксации создает
|
||||
описанный выше эффект "долгого чтения". Разница же здесь в том, что при
|
||||
исчерпании свободных страниц ситуация будет автоматически исправлена,
|
||||
посредством записи изменений на диск и формирования новой сильной точки
|
||||
фиксации.
|
||||
|
||||
Таким образом, в режиме безопасной асинхронной фиксации _libmdbx_ будет
|
||||
всегда использовать новые страницы до исчерпания места в БД или до
|
||||
явного формирования сильной точки фиксации посредством
|
||||
`mdbx_env_sync()`. При этом суммарный трафик записи на диск будет
|
||||
примерно такой же, как если бы отдельно фиксировалась каждая транзакция.
|
||||
|
||||
В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC`
|
||||
когда при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
|
||||
В последующих версиях _libmdbx_ будут предусмотрены средства для
|
||||
асинхронной записи данных на диск с автоматическим формированием сильных
|
||||
точек фиксации.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Сравнение производительности
|
||||
============================
|
||||
@@ -302,14 +652,15 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
Показана соотнесенная сумма использованных ресурсов в ходе бенчмарка в
|
||||
режиме отложенной фиксации:
|
||||
|
||||
- суммарное количество операций ввода-вывода (IOPS), как записи, так и
|
||||
чтения.
|
||||
- суммарное количество операций ввода-вывода (IOPS), как записи, так и
|
||||
чтения.
|
||||
|
||||
- суммарное затраченное время процессора, как в режиме пользовательских процессов,
|
||||
так и в режиме ядра ОС.
|
||||
- суммарное затраченное время процессора, как в режиме пользовательских
|
||||
процессов, так и в режиме ядра ОС.
|
||||
|
||||
- использованное место на диске при завершении теста, после закрытия БД из тестирующего процесса,
|
||||
но без ожидания всех внутренних операций обслуживания (компактификации LSM и т.п.).
|
||||
- использованное место на диске при завершении теста, после закрытия БД
|
||||
из тестирующего процесса, но без ожидания всех внутренних операций
|
||||
обслуживания (компактификации LSM и т.п.).
|
||||
|
||||
Движок _ForestDB_ был исключен при оформлении результатов, так как
|
||||
относительно конкурентов многократно превысил потребление каждого из
|
||||
@@ -325,352 +676,6 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
## Недостатки и Компромиссы
|
||||
|
||||
1. Единовременно может выполняться не более одной транзакция изменения данных
|
||||
(один писатель). Зато все изменения всегда последовательны, не может быть
|
||||
конфликтов или логических ошибок при откате транзакций.
|
||||
|
||||
2. Отсутствие [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging)
|
||||
обуславливает относительно большой
|
||||
[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor). Поэтому фиксация изменений на диске может быть
|
||||
достаточно дорогой и являться главным ограничением производительности
|
||||
при интенсивном изменении данных.
|
||||
> В качестве компромисса _libmdbx_ предлагает несколько режимов ленивой
|
||||
> и/или периодической фиксации. В том числе режим `MAPASYNC`, при котором
|
||||
> изменения происходят только в памяти и асинхронно фиксируются на диске
|
||||
> ядром ОС.
|
||||
>
|
||||
> Однако, следует воспринимать это свойство аккуратно и взвешенно.
|
||||
> Например, полная фиксация транзакции в БД с журналом потребует минимум 2
|
||||
> IOPS (скорее всего 3-4) из-за накладных расходов в файловой системе. В
|
||||
> _libmdbx_ фиксация транзакции также требует от 2 IOPS. Однако, в БД с
|
||||
> журналом кол-во IOPS будет меняться в зависимости от файловой системы,
|
||||
> но не от кол-ва записей или их объема. Тогда как в _libmdbx_ кол-во
|
||||
> будет расти логарифмически от кол-ва записей/строк в БД (по высоте
|
||||
> b+tree).
|
||||
|
||||
3. [COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8)
|
||||
для реализации [MVCC](https://ru.wikipedia.org/wiki/MVCC) выполняется на
|
||||
уровне страниц в [B+
|
||||
дереве](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
||||
Поэтому изменение данных амортизационно требует копирования Olog(N)
|
||||
страниц, что расходует [пропускную способность оперативной
|
||||
памяти](https://en.wikipedia.org/wiki/Memory_bandwidth) и является
|
||||
основным ограничителем производительности в режиме `MAPASYNC`.
|
||||
> Этот недостаток неустраним, тем не менее следует дать некоторые пояснения.
|
||||
> Дело в том, что фиксация изменений на диске потребует гораздо более
|
||||
> значительного копирования данных в памяти и массы других затратных операций.
|
||||
> Поэтому обусловленное этим недостатком падение производительности становится
|
||||
> заметным только при отказе от фиксации изменений на диске.
|
||||
> Соответственно, корректнее сказать, что _libmdbx_ позволяет
|
||||
> получить персистентность ценой минимального падения производительности.
|
||||
> Если же нет необходимости оперативно сохранять данные, то логичнее
|
||||
> использовать `std::map`.
|
||||
|
||||
4. В _LMDB_ существует проблема долгих чтений (приостановленных читателей),
|
||||
которая приводит к деградации производительности и переполнению БД.
|
||||
> В _libmdbx_ предложены средства для предотвращения, быстрого выхода из
|
||||
> некомфортной ситуации и устранения её последствий. Подробности ниже.
|
||||
|
||||
5. В _LMDB_ есть вероятность разрушения БД в режиме `WRITEMAP+MAPASYNC`.
|
||||
В _libmdbx_ для `WRITEMAP+MAPASYNC` гарантируется как сохранность базы,
|
||||
так и согласованность данных.
|
||||
> Дополнительно, в качестве альтернативы, предложен режим `UTTERLY_NOSYNC`.
|
||||
> Подробности ниже.
|
||||
|
||||
|
||||
#### Проблема долгих чтений
|
||||
|
||||
*Следует отметить*, что проблема "сборки мусора" так или иначе
|
||||
существует во всех СУБД (Vacuum в PostgreSQL). Однако в случае _libmdbx_
|
||||
и LMDB она проявляется более остро, прежде всего из-за высокой
|
||||
производительности, а также из-за намеренного упрощения внутренних
|
||||
механизмов ради производительности.
|
||||
|
||||
Понимание проблемы требует некоторых пояснений, которые
|
||||
изложены ниже, но могут быть сложны для быстрого восприятия.
|
||||
Поэтому, тезисно:
|
||||
|
||||
* Изменение данных на фоне долгой операции чтения может
|
||||
приводить к исчерпанию места в БД.
|
||||
|
||||
* После чего любая попытка обновить данные будет приводить к
|
||||
ошибке `MAP_FULL` до завершения долгой операции чтения.
|
||||
|
||||
* Характерными примерами долгих чтений являются горячее
|
||||
резервное копирования и отладка клиентского приложения при
|
||||
активной транзакции чтения.
|
||||
|
||||
* В оригинальной _LMDB_ после этого будет наблюдаться
|
||||
устойчивая деградация производительности всех механизмов
|
||||
обратной записи на диск (в I/O контроллере, в гипервизоре,
|
||||
в ядре ОС).
|
||||
|
||||
* В _libmdbx_ предусмотрен механизм аварийного прерывания таких
|
||||
операций, а также режим `LIFO RECLAIM` устраняющий последующую
|
||||
деградацию производительности.
|
||||
|
||||
Операции чтения выполняются в контексте снимка данных (версии
|
||||
БД), который был актуальным на момент старта транзакции чтения. Такой
|
||||
читаемый снимок поддерживается неизменным до завершения операции. В свою
|
||||
очередь, это не позволяет повторно использовать страницы БД в
|
||||
последующих версиях (снимках БД).
|
||||
|
||||
Другими словами, если обновление данных выполняется на фоне долгой
|
||||
операции чтения, то вместо повторного использования "старых" ненужных
|
||||
страниц будут выделяться новые, так как "старые" страницы составляют
|
||||
снимок БД, который еще используется долгой операцией чтения.
|
||||
|
||||
В результате, при интенсивном изменении данных и достаточно длительной
|
||||
операции чтения, в БД могут быть исчерпаны свободные страницы, что не
|
||||
позволит создавать новые снимки/версии БД. Такая ситуация будет
|
||||
сохраняться до завершения операции чтения, которая использует старый
|
||||
снимок данных и препятствует повторному использованию страниц БД.
|
||||
|
||||
Однако, на этом проблемы не заканчиваются. После описанной ситуации, все
|
||||
дополнительные страницы, которые были выделены пока переработка старых
|
||||
была невозможна, будут участвовать в цикле выделения/освобождения до
|
||||
конца жизни экземпляра БД. В оригинальной _LMDB_ этот цикл использования
|
||||
страниц работает по принципу [FIFO](https://ru.wikipedia.org/wiki/FIFO).
|
||||
Поэтому увеличение количества циркулирующий страниц, с точки зрения
|
||||
механизмов кэширования и/или обратной записи, выглядит как увеличение
|
||||
рабочего набор данных. Проще говоря, однократное попадание в ситуацию
|
||||
"уснувшего читателя" приводит к устойчивому эффекту вымывания I/O кэша
|
||||
при всех последующих изменениях данных.
|
||||
|
||||
Для устранения описанных проблемы в _libmdbx_ сделаны существенные
|
||||
доработки, подробности ниже. Иллюстрации к проблеме "долгих чтений"
|
||||
можно найти в [слайдах презентации](http://www.slideshare.net/leoyuriev/lmdb).
|
||||
|
||||
Там же приведен пример количественной оценки прироста производительности
|
||||
за счет эффективной работы [BBWC](https://en.wikipedia.org/wiki/BBWC)
|
||||
при включении `LIFO RECLAIM` в _libmdbx_.
|
||||
|
||||
|
||||
#### Сохранность данных в режиме асинхронной фиксации
|
||||
|
||||
При работе в режиме `WRITEMAP+MAPSYNC` запись измененных страниц
|
||||
выполняется ядром ОС, что имеет ряд преимуществ. Так например, при крахе
|
||||
приложения, ядро ОС сохранит все изменения.
|
||||
|
||||
Однако, при аварийном отключении питания или сбое в ядре ОС, на диске
|
||||
может быть сохранена только часть измененных страниц БД. При этом с большой
|
||||
вероятностью может оказаться, что будут сохранены мета-страницы со
|
||||
ссылками на страницы с новыми версиями данных, но не сами новые данные.
|
||||
В этом случае БД будет безвозвратна разрушена, даже если до аварии
|
||||
производилась полная синхронизация данных (посредством
|
||||
`mdbx_env_sync()`).
|
||||
|
||||
В _libmdbx_ эта проблема устранена путем полной переработки
|
||||
пути записи данных:
|
||||
|
||||
* В режиме `WRITEMAP+MAPSYNC` _libmdbx_ не обновляет
|
||||
мета-страницы непосредственно, а поддерживает их теневые копии
|
||||
с переносом изменений после фиксации данных.
|
||||
|
||||
* При завершении транзакций, в зависимости от состояния
|
||||
синхронности данных между диском и оперативной памятью,
|
||||
_libmdbx_ помечает точки фиксации либо как сильные (strong),
|
||||
либо как слабые (weak). Так например, в режиме
|
||||
`WRITEMAP+MAPSYNC` завершаемые транзакции помечаются как
|
||||
слабые, а при явной синхронизации данных - как сильные.
|
||||
|
||||
* В _libmdbx_ поддерживается не две, а три отдельные мета-страницы.
|
||||
Это позволяет выполнять фиксацию транзакций с формированием как
|
||||
сильной, так и слабой точки фиксации, без потери двух предыдущих
|
||||
точек фиксации (из которых одна может быть сильной, а вторая слабой).
|
||||
В результате, _libmdbx_ позволяет в произвольном порядке чередовать
|
||||
сильные и слабые точки фиксации без нарушения соответствующих
|
||||
гарантий в случае неожиданной системной аварии во время фиксации.
|
||||
|
||||
* При открытии БД выполняется автоматический откат к последней
|
||||
сильной фиксации. Этим обеспечивается гарантия сохранности БД.
|
||||
|
||||
Такая гарантия надежности не дается бесплатно. Для
|
||||
сохранности данных, страницы, формирующие крайний снимок с
|
||||
сильной фиксацией, не должны повторно использоваться
|
||||
(перезаписываться) до формирования следующей сильной точки
|
||||
фиксации. Таким образом, крайняя точка фиксации создает
|
||||
описанный выше эффект "долгого чтения". Разница же здесь в том,
|
||||
что при исчерпании свободных страниц ситуация будет
|
||||
автоматически исправлена, посредством записи изменений на диск
|
||||
и формирования новой сильной точки фиксации.
|
||||
|
||||
Таким образом, в режиме безопасной асинхронной фиксации _libmdbx_ будет
|
||||
всегда использовать новые страницы до исчерпания места в БД или до явного
|
||||
формирования сильной точки фиксации посредством `mdbx_env_sync()`.
|
||||
При этом суммарный трафик записи на диск будет примерно такой же,
|
||||
как если бы отдельно фиксировалась каждая транзакция.
|
||||
|
||||
В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` когда
|
||||
при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
|
||||
В последующих версиях _libmdbx_ будут предусмотрены средства
|
||||
для асинхронной записи данных на диск с автоматическим
|
||||
формированием сильных точек фиксации.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Доработки и усовершенствования относительно LMDB
|
||||
================================================
|
||||
|
||||
1. Режим `LIFO RECLAIM`.
|
||||
|
||||
Для повторного использования выбираются не самые старые, а
|
||||
самые новые страницы из доступных. За счет этого цикл
|
||||
использования страниц всегда имеет минимальную длину и не
|
||||
зависит от общего числа выделенных страниц.
|
||||
|
||||
В результате механизмы кэширования и обратной записи работают с
|
||||
максимально возможной эффективностью. В случае использования
|
||||
контроллера дисков или системы хранения с
|
||||
[BBWC](https://en.wikipedia.org/wiki/BBWC) возможно
|
||||
многократное увеличение производительности по записи
|
||||
(обновлению данных).
|
||||
|
||||
2. Обработчик `OOM-KICK`.
|
||||
|
||||
Посредством `mdbx_env_set_oomfunc()` может быть установлен
|
||||
внешний обработчик (callback), который будет вызван при
|
||||
исчерпании свободных страниц из-за долгой операцией чтения.
|
||||
Обработчику будет передан PID и pthread_id виновника.
|
||||
В свою очередь обработчик может предпринять одно из действий:
|
||||
|
||||
* нейтрализовать виновника (отправить сигнал kill #9), если
|
||||
долгое чтение выполняется сторонним процессом;
|
||||
|
||||
* отменить или перезапустить проблемную операцию чтения, если
|
||||
операция выполняется одним из потоков текущего процесса;
|
||||
|
||||
* подождать некоторое время, в расчете на то, что проблемная операция
|
||||
чтения будет штатно завершена;
|
||||
|
||||
* прервать текущую операцию изменения данных с возвратом кода
|
||||
ошибки.
|
||||
|
||||
3. Гарантия сохранности БД в режиме `WRITEMAP+MAPSYNC`.
|
||||
> В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
> режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC`
|
||||
> когда при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
> Для подробностей смотрите раздел
|
||||
> [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации).
|
||||
|
||||
4. Возможность автоматического формирования контрольных точек
|
||||
(сброса данных на диск) при накоплении заданного объёма изменений,
|
||||
устанавливаемого функцией `mdbx_env_set_syncbytes()`.
|
||||
|
||||
5. Возможность получить отставание текущей транзакции чтения от
|
||||
последней версии данных в БД посредством `mdbx_txn_straggler()`.
|
||||
|
||||
6. Утилита mdbx_chk для проверки БД и функция `mdbx_env_pgwalk()` для
|
||||
обхода всех страниц БД.
|
||||
|
||||
7. Управление отладкой и получение отладочных сообщений посредством
|
||||
`mdbx_setup_debug()`.
|
||||
|
||||
8. Возможность связать с каждой завершаемой транзакцией до 3
|
||||
дополнительных маркеров посредством `mdbx_canary_put()`, и прочитать их
|
||||
в транзакции чтения посредством `mdbx_canary_get()`.
|
||||
|
||||
9. Возможность узнать есть ли за текущей позицией курсора строка данных
|
||||
посредством `mdbx_cursor_eof()`.
|
||||
|
||||
10. Возможность явно запросить обновление существующей записи, без
|
||||
создания новой посредством флажка `MDBX_CURRENT` для `mdbx_put()`.
|
||||
|
||||
11. Возможность посредством `mdbx_replace()` обновить или удалить запись
|
||||
с получением предыдущего значения данных, а также адресно изменить
|
||||
конкретное multi-значение.
|
||||
|
||||
12. Поддержка ключей и значений нулевой длины, включая сортированные
|
||||
дубликаты.
|
||||
|
||||
13. Исправленный вариант `mdbx_cursor_count()`, возвращающий корректное
|
||||
количество дубликатов для всех типов таблиц и любого положения курсора.
|
||||
|
||||
14. Возможность открыть БД в эксклюзивном режиме посредством
|
||||
`mdbx_env_open_ex()`, например в целях её проверки.
|
||||
|
||||
15. Возможность закрыть БД в "грязном" состоянии (без сброса данных и
|
||||
формирования сильной точки фиксации) посредством `mdbx_env_close_ex()`.
|
||||
|
||||
16. Возможность получить посредством `mdbx_env_info()` дополнительную
|
||||
информацию, включая номер самой старой версии БД (снимка данных),
|
||||
который используется одним из читателей.
|
||||
|
||||
17. Функция `mdbx_del()` не игнорирует дополнительный (уточняющий)
|
||||
аргумент `data` для таблиц без дубликатов (без флажка `MDBX_DUPSORT`), а
|
||||
при его ненулевом значении всегда использует его для сверки с удаляемой
|
||||
записью.
|
||||
|
||||
18. Возможность открыть dbi-таблицу, одновременно с установкой
|
||||
компараторов для ключей и данных, посредством `mdbx_dbi_open_ex()`.
|
||||
|
||||
19. Возможность посредством `mdbx_is_dirty()` определить находятся ли
|
||||
некоторый ключ или данные в "грязной" странице БД. Таким образом,
|
||||
избегая лишнего копирования данных перед выполнением модифицирующих
|
||||
операций (значения, размещенные в "грязных" страницах, могут быть
|
||||
перезаписаны при изменениях, иначе они будут неизменны).
|
||||
|
||||
20. Корректное обновление текущей записи, в том числе сортированного
|
||||
дубликата, при использовании режима `MDBX_CURRENT` в
|
||||
`mdbx_cursor_put()`.
|
||||
|
||||
21. Все курсоры, как в транзакциях только для чтения, так и в пишущих,
|
||||
могут быть переиспользованы посредством `mdbx_cursor_renew()` и ДОЛЖНЫ
|
||||
ОСВОБОЖДАТЬСЯ ЯВНО.
|
||||
>
|
||||
> ## _ВАЖНО_, Обратите внимание!
|
||||
>
|
||||
> Это единственное изменение в API, которое значимо меняет
|
||||
> семантику управления курсорами и может приводить к утечкам
|
||||
> памяти. Следует отметить, что это изменение вынужденно.
|
||||
> Так устраняется неоднозначность с массой тяжких последствий:
|
||||
>
|
||||
> - обращение к уже освобожденной памяти;
|
||||
> - попытки повторного освобождения памяти;
|
||||
> - повреждение памяти и ошибки сегментации.
|
||||
|
||||
22. Дополнительный код ошибки `MDBX_EMULTIVAL`, который возвращается из
|
||||
`mdbx_put()` и `mdbx_replace()` при попытке выполнить неоднозначное
|
||||
обновление или удаления одного из нескольких значений с одним ключом.
|
||||
|
||||
23. Возможность посредством `mdbx_get_ex()` получить значение по
|
||||
заданному ключу, одновременно с количеством дубликатов.
|
||||
|
||||
24. Наличие функций `mdbx_cursor_on_first()` и `mdbx_cursor_on_last()`,
|
||||
которые позволяют быстро выяснить стоит ли курсор на первой/последней
|
||||
позиции.
|
||||
|
||||
25. При завершении читающих транзакций, открытые в них DBI-хендлы не
|
||||
закрываются и не теряются при завершении таких транзакций посредством
|
||||
`mdbx_txn_abort()` или `mdbx_txn_reset()`. Что позволяет избавится от ряда
|
||||
сложно обнаруживаемых ошибок.
|
||||
|
||||
26. Генерация последовательностей посредством `mdbx_dbi_sequence()`.
|
||||
|
||||
27. Расширенное динамическое управление размером БД, включая выбор
|
||||
размера страницы посредством `mdbx_env_set_geometry()`,
|
||||
в том числе в **Windows**
|
||||
|
||||
28. Три мета-страницы вместо двух, что позволяет гарантированно
|
||||
консистентно обновлять слабые контрольные точки фиксации без риска
|
||||
повредить крайнюю сильную точку фиксации.
|
||||
|
||||
29. В _libmdbx_ реализован автоматический возврат освобождающихся
|
||||
страниц в область нераспределенного резерва в конце файла данных. При
|
||||
этом уменьшается количество страниц загруженных в память и участвующих в
|
||||
цикле обновления данных и записи на диск. Фактически _libmdbx_ выполняет
|
||||
постоянную компактификацию данных, но не затрачивая на это
|
||||
дополнительных ресурсов, а только освобождая их. При освобождении места
|
||||
в БД и установке соответствующих параметров геометрии базы данных, также будет
|
||||
уменьшаться размер файла на диске, в том числе в **Windows**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
$ objdump -f -h -j .text libmdbx.so
|
||||
|
||||
@@ -685,16 +690,3 @@ Idx Name Size VMA LMA File off Algn
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
$ gcc -v
|
||||
Using built-in specs.
|
||||
COLLECT_GCC=gcc
|
||||
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/7/lto-wrapper
|
||||
OFFLOAD_TARGET_NAMES=nvptx-none
|
||||
OFFLOAD_TARGET_DEFAULT=1
|
||||
Target: x86_64-linux-gnu
|
||||
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 7.2.0-8ubuntu3' --with-bugurl=file:///usr/share/doc/gcc-7/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-7 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
|
||||
Thread model: posix
|
||||
gcc version 7.2.0 (Ubuntu 7.2.0-8ubuntu3)
|
||||
```
|
||||
|
||||
758
README.md
758
README.md
@@ -9,9 +9,21 @@ libmdbx
|
||||
|
||||
## Project Status for now
|
||||
|
||||
- The stable versions ([_stable/0.0_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.0) and [_stable/0.1_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.1) branches) of _MDBX_ are frozen, i.e. no new features or API changes, but only bug fixes.
|
||||
- The next version ([_devel_](https://github.com/leo-yuriev/libmdbx/tree/devel) branch) **is under active non-public development**, i.e. current API and set of features are extreme volatile.
|
||||
- The immediate goal of development is formation of the stable API and the stable internal database format, which allows realise all PLANNED FEATURES:
|
||||
- The stable versions
|
||||
([_stable/0.0_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.0)
|
||||
and
|
||||
[_stable/0.1_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.1)
|
||||
branches) of _MDBX_ are frozen, i.e. no new features or API changes, but
|
||||
only bug fixes.
|
||||
|
||||
- The next version
|
||||
([_devel_](https://github.com/leo-yuriev/libmdbx/tree/devel) branch)
|
||||
**is under active non-public development**, i.e. current API and set of
|
||||
features are extreme volatile.
|
||||
|
||||
- The immediate goal of development is formation of the stable API and
|
||||
the stable internal database format, which allows realise all PLANNED
|
||||
FEATURES:
|
||||
1. Integrity check by [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree);
|
||||
2. Support for [raw block devices](https://en.wikipedia.org/wiki/Raw_device);
|
||||
3. Separate place (HDD) for large data items;
|
||||
@@ -24,19 +36,21 @@ Don't miss [Java Native Interface](https://github.com/castortech/mdbxjni) by [Ca
|
||||
|
||||
-----
|
||||
|
||||
Nowadays MDBX intended for Linux, and support Windows (since
|
||||
Windows Server 2008) as a complementary platform. Support for
|
||||
other OS could be implemented on commercial basis. However such
|
||||
enhancements (i.e. pull requests) could be accepted in
|
||||
mainstream only when corresponding public and free Continuous
|
||||
Integration service will be available.
|
||||
Nowadays MDBX intended for Linux, and support Windows (since Windows
|
||||
Server 2008) as a complementary platform. Support for other OS could be
|
||||
implemented on commercial basis. However such enhancements (i.e. pull
|
||||
requests) could be accepted in mainstream only when corresponding public
|
||||
and free Continuous Integration service will be available.
|
||||
|
||||
## Contents
|
||||
|
||||
- [Overview](#overview)
|
||||
- [Comparison with other DBs](#comparison-with-other-dbs)
|
||||
- [History & Acknowledgments](#history)
|
||||
- [Main features](#main-features)
|
||||
- [Improvements over LMDB](#improvements-over-lmdb)
|
||||
- [Gotchas](#gotchas)
|
||||
- [Long-time read transactions problem](#long-time-read-transactions-problem)
|
||||
- [Data safety in async-write-mode](#data-safety-in-async-write-mode)
|
||||
- [Performance comparison](#performance-comparison)
|
||||
- [Integral performance](#integral-performance)
|
||||
- [Read scalability](#read-scalability)
|
||||
@@ -44,52 +58,58 @@ Integration service will be available.
|
||||
- [Lazy-write mode](#lazy-write-mode)
|
||||
- [Async-write mode](#async-write-mode)
|
||||
- [Cost comparison](#cost-comparison)
|
||||
- [Gotchas](#gotchas)
|
||||
- [Long-time read transactions problem](#long-time-read-transactions-problem)
|
||||
- [Data safety in async-write-mode](#data-safety-in-async-write-mode)
|
||||
- [Improvements over LMDB](#improvements-over-lmdb)
|
||||
|
||||
|
||||
## Overview
|
||||
_libmdbx_ is an embedded lightweight key-value database engine oriented
|
||||
for performance under Linux and Windows.
|
||||
|
||||
_libmdbx_ is an embedded lightweight key-value database engine oriented for performance under Linux and Windows.
|
||||
|
||||
_libmdbx_ allows multiple processes to read and update several key-value tables concurrently,
|
||||
while being [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, with minimal overhead and operation cost of Olog(N).
|
||||
_libmdbx_ allows multiple processes to read and update several key-value
|
||||
tables concurrently, while being
|
||||
[ACID](https://en.wikipedia.org/wiki/ACID)-compliant, with minimal
|
||||
overhead and operation cost of Olog(N).
|
||||
|
||||
_libmdbx_ provides
|
||||
[serializability](https://en.wikipedia.org/wiki/Serializability) and consistency of data after crash.
|
||||
Read-write transactions don't block read-only transactions and are
|
||||
[serialized](https://en.wikipedia.org/wiki/Serializability) by [mutex](https://en.wikipedia.org/wiki/Mutual_exclusion).
|
||||
[serializability](https://en.wikipedia.org/wiki/Serializability) and
|
||||
consistency of data after crash. Read-write transactions don't block
|
||||
read-only transactions and are
|
||||
[serialized](https://en.wikipedia.org/wiki/Serializability) by
|
||||
[mutex](https://en.wikipedia.org/wiki/Mutual_exclusion).
|
||||
|
||||
_libmdbx_ [wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom) provides parallel read transactions
|
||||
without atomic operations or synchronization primitives.
|
||||
_libmdbx_
|
||||
[wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom)
|
||||
provides parallel read transactions without atomic operations or
|
||||
synchronization primitives.
|
||||
|
||||
_libmdbx_ uses [B+Trees](https://en.wikipedia.org/wiki/B%2B_tree) and [mmap](https://en.wikipedia.org/wiki/Memory-mapped_file),
|
||||
doesn't use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). This might have caveats for some workloads.
|
||||
_libmdbx_ uses [B+Trees](https://en.wikipedia.org/wiki/B%2B_tree) and
|
||||
[mmap](https://en.wikipedia.org/wiki/Memory-mapped_file), doesn't use
|
||||
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). This might
|
||||
have caveats for some workloads.
|
||||
|
||||
### Comparison with other DBs
|
||||
|
||||
Because _libmdbx_ is currently overhauled, I think it's better to just link
|
||||
[chapter of Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) here.
|
||||
Because _libmdbx_ is currently overhauled, I think it's better to just
|
||||
link [chapter of Comparison with other
|
||||
databases](https://github.com/coreos/bbolt#comparison-with-other-databases)
|
||||
here.
|
||||
|
||||
### History
|
||||
The _libmdbx_ design is based on [Lightning Memory-Mapped
|
||||
Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
Initial development was going in
|
||||
[ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project, about a
|
||||
year later it received separate development effort and in autumn 2015
|
||||
was isolated to separate project, which was [presented at Highload++
|
||||
2015 conference](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
|
||||
The _libmdbx_ design is based on [Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
Initial development was going in [ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project, about a year later it
|
||||
received separate development effort and in autumn 2015 was isolated to separate project, which was
|
||||
[presented at Highload++ 2015 conference](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
|
||||
Since early 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/leo-yuriev/libfpta),
|
||||
Since early 2017 _libmdbx_ is used in [Fast PositiveTables](https://github.com/leo-yuriev/libfpta),
|
||||
by [Positive Technologies](https://www.ptsecurity.com).
|
||||
|
||||
#### Acknowledgments
|
||||
Howard Chu (Symas Corporation) - the author of LMDB, from which
|
||||
originated the MDBX in 2015.
|
||||
|
||||
Howard Chu (Symas Corporation) - the author of LMDB,
|
||||
from which originated the MDBX in 2015.
|
||||
|
||||
Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code,
|
||||
which was used for begin development of LMDB.
|
||||
Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code, which
|
||||
was used for begin development of LMDB.
|
||||
|
||||
|
||||
Main features
|
||||
@@ -98,39 +118,331 @@ Main features
|
||||
_libmdbx_ inherits all keys features and characteristics from
|
||||
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database):
|
||||
|
||||
1. Data is stored in ordered map, keys are always sorted, range lookups are supported.
|
||||
1. Data is stored in ordered map, keys are always sorted, range lookups
|
||||
are supported.
|
||||
|
||||
2. Data is [mmaped](https://en.wikipedia.org/wiki/Memory-mapped_file) to memory of each worker DB process, read transactions are zero-copy.
|
||||
2. Data is [mmaped](https://en.wikipedia.org/wiki/Memory-mapped_file) to
|
||||
memory of each worker DB process, read transactions are zero-copy.
|
||||
|
||||
3. Transactions are [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, thanks to
|
||||
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) and [CoW](https://en.wikipedia.org/wiki/Copy-on-write).
|
||||
Writes are strongly serialized and aren't blocked by reads, transactions can't conflict with each other.
|
||||
Reads are guaranteed to get only commited data
|
||||
([relaxing serializability](https://en.wikipedia.org/wiki/Serializability#Relaxing_serializability)).
|
||||
3. Transactions are
|
||||
[ACID](https://en.wikipedia.org/wiki/ACID)-compliant, thanks to
|
||||
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control)
|
||||
and [CoW](https://en.wikipedia.org/wiki/Copy-on-write). Writes are
|
||||
strongly serialized and aren't blocked by reads, transactions can't
|
||||
conflict with each other. Reads are guaranteed to get only commited data
|
||||
([relaxing serializability](https://en.wikipedia.org/wiki/Serializability#Relaxing_serializability)).
|
||||
|
||||
4. Reads and queries are [non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm),
|
||||
don't use [atomic operations](https://en.wikipedia.org/wiki/Linearizability#High-level_atomic_operations).
|
||||
Readers don't block each other and aren't blocked by writers. Read performance scales linearly with CPU core count.
|
||||
> Though "connect to DB" (start of first read transaction in thread) and "disconnect from DB" (shutdown or thread
|
||||
> termination) requires to acquire a lock to register/unregister current thread from "readers table"
|
||||
4. Reads and queries are
|
||||
[non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm),
|
||||
don't use [atomic
|
||||
operations](https://en.wikipedia.org/wiki/Linearizability#High-level_atomic_operations).
|
||||
Readers don't block each other and aren't blocked by writers. Read
|
||||
performance scales linearly with CPU core count.
|
||||
> Though "connect to DB" (start of first read transaction in thread) and
|
||||
> "disconnect from DB" (shutdown or thread termination) requires to
|
||||
> acquire a lock to register/unregister current thread from "readers
|
||||
> table"
|
||||
|
||||
5. Keys with multiple values are stored efficiently without key duplication, sorted by value, including integers
|
||||
(reasonable for secondary indexes).
|
||||
5. Keys with multiple values are stored efficiently without key
|
||||
duplication, sorted by value, including integers (reasonable for
|
||||
secondary indexes).
|
||||
|
||||
6. Efficient operation on short fixed length keys, including integer ones.
|
||||
6. Efficient operation on short fixed length keys, including integer
|
||||
ones.
|
||||
|
||||
7. [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor) и RAF (Read Amplification Factor)
|
||||
are Olog(N).
|
||||
7. [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor) и RAF (Read Amplification Factor) are Olog(N).
|
||||
|
||||
8. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) and transaction journal.
|
||||
In case of a crash no recovery needed. No need for regular maintenance. Backups can be made on the fly on working DB
|
||||
without freezing writers.
|
||||
8. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) and
|
||||
transaction journal. In case of a crash no recovery needed. No need for
|
||||
regular maintenance. Backups can be made on the fly on working DB
|
||||
without freezing writers.
|
||||
|
||||
9. No custom memory management, all done with standard OS syscalls.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Improvements over LMDB
|
||||
======================
|
||||
|
||||
1. `mdbx_chk` tool for DB integrity check.
|
||||
|
||||
2. Automatic dynamic DB size management according to the parameters
|
||||
specified by `mdbx_env_set_geometry()` function. Including including
|
||||
growth step and truncation threshold, as well as the choice of page
|
||||
size.
|
||||
|
||||
3. Automatic returning of freed pages into unallocated space at the end
|
||||
of database file with optionally automatic shrinking it. This reduces
|
||||
amount of pages resides in RAM and circulated in disk I/O. In fact
|
||||
_libmdbx_ constantly performs DB compactification, without spending
|
||||
additional resources for that.
|
||||
|
||||
4. Support for keys and values of zero length, including sorted
|
||||
duplicates.
|
||||
|
||||
5. Ability to assign up to 3 markers to commiting transaction with
|
||||
`mdbx_canary_put()` and then get them in read transaction by
|
||||
`mdbx_canary_get()`.
|
||||
|
||||
6. Ability to update or delete record and get previous value via
|
||||
`mdbx_replace()` Also can update specific multi-value.
|
||||
|
||||
7. `LIFO RECLAIM` mode:
|
||||
|
||||
The newest pages are picked for reuse instead of the oldest. This allows
|
||||
to minimize reclaim loop and make it execution time independent of total
|
||||
page count.
|
||||
|
||||
This results in OS kernel cache mechanisms working with maximum
|
||||
efficiency. In case of using disk controllers or storages with
|
||||
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration)
|
||||
this may greatly improve write performance.
|
||||
|
||||
8. Sequence generation via `mdbx_dbi_sequence()`.
|
||||
|
||||
9. `OOM-KICK` callback.
|
||||
|
||||
`mdbx_env_set_oomfunc()` allows to set a callback, which will be called
|
||||
in the event of DB space exhausting during long-time read transaction in
|
||||
parallel with extensive updating. Callback will be invoked with PID and
|
||||
pthread_id of offending thread as parameters. Callback can do any of
|
||||
these things to remedy the problem:
|
||||
|
||||
* wait for read transaction to finish normally;
|
||||
|
||||
* kill the offending process (signal 9), if separate process is doing
|
||||
long-time read;
|
||||
|
||||
* abort or restart offending read transaction if it's running in sibling
|
||||
thread;
|
||||
|
||||
* abort current write transaction with returning error code.
|
||||
|
||||
10. Ability to open DB in exclusive mode with `MDBX_EXCLUSIVE` flag.
|
||||
|
||||
11. Ability to get how far current read-only snapshot is from latest
|
||||
version of the DB by `mdbx_txn_straggler()`.
|
||||
|
||||
12. Ability to explicitly request update of present record without
|
||||
creating new record. Implemented as `MDBX_CURRENT` flag for
|
||||
`mdbx_put()`.
|
||||
|
||||
13. Fixed `mdbx_cursor_count()`, which returns correct count of
|
||||
duplicated for all table types and any cursor position.
|
||||
|
||||
14. `mdbx_env_info()` to getting additional info, including number of
|
||||
the oldest snapshot of DB, which is used by one of the readers.
|
||||
|
||||
15. `mdbx_del()` doesn't ignore additional argument (specifier) `data`
|
||||
for tables without duplicates (without flag `MDBX_DUPSORT`), if `data`
|
||||
is not null then always uses it to verify record, which is being
|
||||
deleted.
|
||||
|
||||
16. Ability to open dbi-table with simultaneous setup of comparators for
|
||||
keys and values, via `mdbx_dbi_open_ex()`.
|
||||
|
||||
17. `mdbx_is_dirty()`to find out if key or value is on dirty page, that
|
||||
useful to avoid copy-out before updates.
|
||||
|
||||
18. Correct update of current record in `MDBX_CURRENT` mode of
|
||||
`mdbx_cursor_put()`, including sorted duplicated.
|
||||
|
||||
19. Check if there is a row with data after current cursor position via
|
||||
`mdbx_cursor_eof()`.
|
||||
|
||||
20. Additional error code `MDBX_EMULTIVAL`, which is returned by
|
||||
`mdbx_put()` and `mdbx_replace()` in case is ambiguous update or delete.
|
||||
|
||||
21. Ability to get value by key and duplicates count by `mdbx_get_ex()`.
|
||||
|
||||
22. Functions `mdbx_cursor_on_first()` and `mdbx_cursor_on_last()`,
|
||||
which allows to know if cursor is currently on first or last position
|
||||
respectively.
|
||||
|
||||
23. Automatic creation of synchronization points (flush changes to
|
||||
persistent storage) when changes reach set threshold (threshold can be
|
||||
set by `mdbx_env_set_syncbytes()`).
|
||||
|
||||
24. Control over debugging and receiving of debugging messages via
|
||||
`mdbx_setup_debug()`.
|
||||
|
||||
25. Function `mdbx_env_pgwalk()` for page-walking all pages in DB.
|
||||
|
||||
26. Three meta-pages instead of two, this allows to guarantee
|
||||
consistently update weak sync-points without risking to corrupt last
|
||||
steady sync-point.
|
||||
|
||||
27. Guarantee of DB integrity in `WRITEMAP+MAPSYNC` mode:
|
||||
> Current _libmdbx_ gives a choice of safe async-write mode (default)
|
||||
> and `UTTERLY_NOSYNC` mode which may result in full
|
||||
> DB corruption during system crash as with LMDB. For details see
|
||||
> [Data safety in async-write mode](#data-safety-in-async-write-mode).
|
||||
|
||||
28. Ability to close DB in "dirty" state (without data flush and
|
||||
creation of steady synchronization point) via `mdbx_env_close_ex()`.
|
||||
|
||||
29. If read transaction is aborted via `mdbx_txn_abort()` or
|
||||
`mdbx_txn_reset()` then DBI-handles, which were opened in it, aren't
|
||||
closed or deleted. This allows to avoid several types of hard-to-debug
|
||||
errors.
|
||||
|
||||
30. All cursors in all read and write transactions can be reused by
|
||||
`mdbx_cursor_renew()` and MUST be freed explicitly.
|
||||
> ## Caution, please pay attention!
|
||||
>
|
||||
> This is the only change of API, which changes semantics of cursor management
|
||||
> and can lead to memory leaks on misuse. This is a needed change as it eliminates ambiguity
|
||||
> which helps to avoid such errors as:
|
||||
> - use-after-free;
|
||||
> - double-free;
|
||||
> - memory corruption and segfaults.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
## Gotchas
|
||||
|
||||
1. At one moment there can be only one writer. But this allows to
|
||||
serialize writes and eliminate any possibility of conflict or logical
|
||||
errors during transaction rollback.
|
||||
|
||||
2. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) means
|
||||
relatively big [WAF](https://en.wikipedia.org/wiki/Write_amplification)
|
||||
(Write Amplification Factor). Because of this syncing data to disk might
|
||||
be quite resource intensive and be main performance bottleneck during
|
||||
intensive write workload.
|
||||
> As compromise _libmdbx_ allows several modes of lazy and/or periodic
|
||||
> syncing, including `MAPASYNC` mode, which modificate data in memory and
|
||||
> asynchronously syncs data to disk, moment to sync is picked by OS.
|
||||
>
|
||||
> Although this should be used with care, synchronous transactions in a DB
|
||||
> with transaction journal will require 2 IOPS minimum (probably 3-4 in
|
||||
> practice) because of filesystem overhead, overhead depends on
|
||||
> filesystem, not on record count or record size. In _libmdbx_ IOPS count
|
||||
> will grow logarithmically depending on record count in DB (height of B+
|
||||
> tree) and will require at least 2 IOPS per transaction too.
|
||||
|
||||
3. [CoW](https://en.wikipedia.org/wiki/Copy-on-write) for
|
||||
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control)
|
||||
is done on memory page level with
|
||||
[B+trees](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
||||
Therefore altering data requires to copy about Olog(N) memory pages,
|
||||
which uses [memory bandwidth](https://en.wikipedia.org/wiki/Memory_bandwidth) and is main
|
||||
performance bottleneck in `MAPASYNC` mode.
|
||||
> This is unavoidable, but isn't that bad. Syncing data to disk requires
|
||||
> much more similar operations which will be done by OS, therefore this is
|
||||
> noticeable only if data sync to persistent storage is fully disabled.
|
||||
> _libmdbx_ allows to safely save data to persistent storage with minimal
|
||||
> performance overhead. If there is no need to save data to persistent
|
||||
> storage then it's much more preferable to use `std::map`.
|
||||
|
||||
|
||||
4. LMDB has a problem of long-time readers which degrades performance
|
||||
and bloats DB.
|
||||
> _libmdbx_ addresses that, details below.
|
||||
|
||||
5. _LMDB_ is susceptible to DB corruption in `WRITEMAP+MAPASYNC` mode.
|
||||
_libmdbx_ in `WRITEMAP+MAPASYNC` guarantees DB integrity and consistency
|
||||
of data.
|
||||
> Additionally there is an alternative: `UTTERLY_NOSYNC` mode.
|
||||
> Details below.
|
||||
|
||||
|
||||
#### Long-time read transactions problem
|
||||
Garbage collection problem exists in all databases one way or another
|
||||
(e.g. VACUUM in PostgreSQL). But in _libmdbx_ and LMDB it's even more
|
||||
important because of high performance and deliberate simplification of
|
||||
internals with emphasis on performance.
|
||||
|
||||
* Altering data during long read operation may exhaust available space
|
||||
on persistent storage.
|
||||
|
||||
* If available space is exhausted then any attempt to update data
|
||||
results in `MAP_FULL` error until long read operation ends.
|
||||
|
||||
* Main examples of long readers is hot backup and debugging of client
|
||||
application which actively uses read transactions.
|
||||
|
||||
* In _LMDB_ this results in degraded performance of all operations of
|
||||
syncing data to persistent storage.
|
||||
|
||||
* _libmdbx_ has a mechanism which aborts such operations and `LIFO RECLAIM`
|
||||
mode which addresses performance degradation.
|
||||
|
||||
Read operations operate only over snapshot of DB which is consistent on
|
||||
the moment when read transaction started. This snapshot doesn't change
|
||||
throughout the transaction but this leads to inability to reclaim the
|
||||
pages until read transaction ends.
|
||||
|
||||
In _LMDB_ this leads to a problem that memory pages, allocated for
|
||||
operations during long read, will be used for operations and won't be
|
||||
reclaimed until DB process terminates. In _LMDB_ they are used in
|
||||
[FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics))
|
||||
manner, which causes increased page count and less chance of cache hit
|
||||
during I/O. In other words: one long-time reader can impact performance
|
||||
of all database until it'll be reopened.
|
||||
|
||||
_libmdbx_ addresses the problem, details below. Illustrations to this
|
||||
problem can be found in the
|
||||
[presentation](http://www.slideshare.net/leoyuriev/lmdb). There is also
|
||||
example of performance increase thanks to
|
||||
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration)
|
||||
when `LIFO RECLAIM` enabled in _libmdbx_.
|
||||
|
||||
#### Data safety in async-write mode
|
||||
In `WRITEMAP+MAPSYNC` mode dirty pages are written to persistent storage
|
||||
by kernel. This means that in case of application crash OS kernel will
|
||||
write all dirty data to disk and nothing will be lost. But in case of
|
||||
hardware malfunction or OS kernel fatal error only some dirty data might
|
||||
be synced to disk, and there is high probability that pages with
|
||||
metadata saved, will point to non-saved, hence non-existent, data pages.
|
||||
In such situation, DB is completely corrupted and can't be repaired even
|
||||
if there was full sync before the crash via `mdbx_env_sync().
|
||||
|
||||
_libmdbx_ addresses this by fully reimplementing write path of data:
|
||||
|
||||
* In `WRITEMAP+MAPSYNC` mode meta-data pages aren't updated in place,
|
||||
instead their shadow copies are used and their updates are synced after
|
||||
data is flushed to disk.
|
||||
|
||||
* During transaction commit _libmdbx_ marks synchronization points as
|
||||
steady or weak depending on how much synchronization needed between RAM
|
||||
and persistent storage, e.g. in `WRITEMAP+MAPSYNC` commited transactions
|
||||
are marked as weak, but during explicit data synchronization - as
|
||||
steady.
|
||||
|
||||
* _libmdbx_ maintains three separate meta-pages instead of two. This
|
||||
allows to commit transaction with steady or weak synchronization point
|
||||
without losing two previous synchronization points (one of them can be
|
||||
steady, and second - weak). This allows to order weak and steady
|
||||
synchronization points in any order without losing consistency in case
|
||||
of system crash.
|
||||
|
||||
* During DB open _libmdbx_ rollbacks to the last steady synchronization
|
||||
point, this guarantees database integrity.
|
||||
|
||||
For data safety pages which form database snapshot with steady
|
||||
synchronization point must not be updated until next steady
|
||||
synchronization point. So last steady synchronization point creates
|
||||
"long-time read" effect. The only difference that in case of memory
|
||||
exhaustion the problem will be immediately addressed by flushing changes
|
||||
to persistent storage and forming new steady synchronization point.
|
||||
|
||||
So in async-write mode _libmdbx_ will always use new pages until memory
|
||||
is exhausted or `mdbx_env_sync()` is invoked. Total disk usage will be
|
||||
almost the same as in sync-write mode.
|
||||
|
||||
Current _libmdbx_ gives a choice of safe async-write mode (default) and
|
||||
`UTTERLY_NOSYNC` mode which may result in full DB corruption during
|
||||
system crash as with LMDB.
|
||||
|
||||
Next version of _libmdbx_ will create steady synchronization points
|
||||
automatically in async-write mode.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Performance comparison
|
||||
=====================
|
||||
======================
|
||||
|
||||
All benchmarks were done by [IOArena](https://github.com/pmwkaa/ioarena)
|
||||
and multiple [scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015)
|
||||
@@ -143,18 +455,21 @@ SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
|
||||
|
||||
Here showed sum of performance metrics in 3 benchmarks:
|
||||
|
||||
- Read/Search on 4 CPU cores machine;
|
||||
- Read/Search on 4 CPU cores machine;
|
||||
|
||||
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations
|
||||
in sync-write mode (fdatasync is called after each transaction);
|
||||
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD)
|
||||
operations in sync-write mode (fdatasync is called after each
|
||||
transaction);
|
||||
|
||||
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations
|
||||
in lazy-write mode (moment to sync data to persistent storage is decided by OS).
|
||||
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD)
|
||||
operations in lazy-write mode (moment to sync data to persistent storage
|
||||
is decided by OS).
|
||||
|
||||
*Reasons why asynchronous mode isn't benchmarked here:*
|
||||
|
||||
1. It doesn't make sense as it has to be done with DB engines, oriented for keeping data in memory e.g.
|
||||
[Tarantool](https://tarantool.io/), [Redis](https://redis.io/)), etc.
|
||||
1. It doesn't make sense as it has to be done with DB engines, oriented
|
||||
for keeping data in memory e.g. [Tarantool](https://tarantool.io/),
|
||||
[Redis](https://redis.io/)), etc.
|
||||
|
||||
2. Performance gap is too high to compare in any meaningful way.
|
||||
|
||||
@@ -164,7 +479,8 @@ Here showed sum of performance metrics in 3 benchmarks:
|
||||
|
||||
### Read Scalability
|
||||
|
||||
Summary performance with concurrent read/search queries in 1-2-4-8 threads on 4 CPU cores machine.
|
||||
Summary performance with concurrent read/search queries in 1-2-4-8
|
||||
threads on 4 CPU cores machine.
|
||||
|
||||
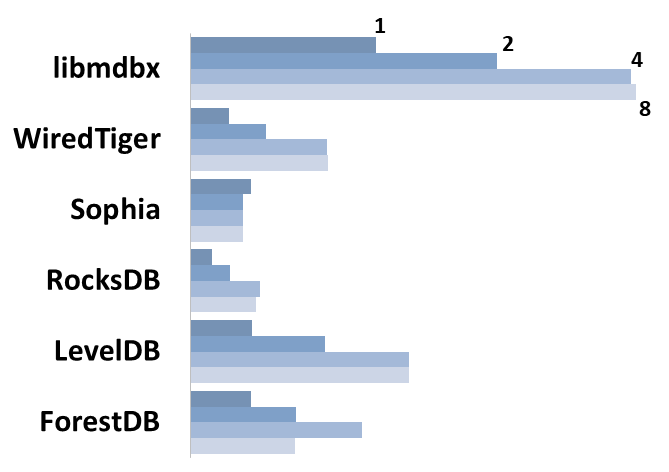
|
||||
|
||||
@@ -172,15 +488,21 @@ Summary performance with concurrent read/search queries in 1-2-4-8 threads on 4
|
||||
|
||||
### Sync-write mode
|
||||
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean transactions per second;
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean
|
||||
transactions per second;
|
||||
|
||||
- Logarithmic scale on right is in seconds and yellow intervals mean execution time of transactions.
|
||||
Each interval shows minimal and maximum execution time, cross marks standard deviation.
|
||||
- Logarithmic scale on right is in seconds and yellow intervals mean
|
||||
execution time of transactions. Each interval shows minimal and maximum
|
||||
execution time, cross marks standard deviation.
|
||||
|
||||
**10,000 transactions in sync-write mode**. In case of a crash all data is consistent and state is right after last successful transaction. [fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after each write transaction in this mode.
|
||||
**10,000 transactions in sync-write mode**. In case of a crash all data
|
||||
is consistent and state is right after last successful transaction.
|
||||
[fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after
|
||||
each write transaction in this mode.
|
||||
|
||||
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
|
||||
Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
|
||||
In the benchmark each transaction contains combined CRUD operations (2
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
||||
and after full run the database contains 10,000 small key-value records.
|
||||
|
||||
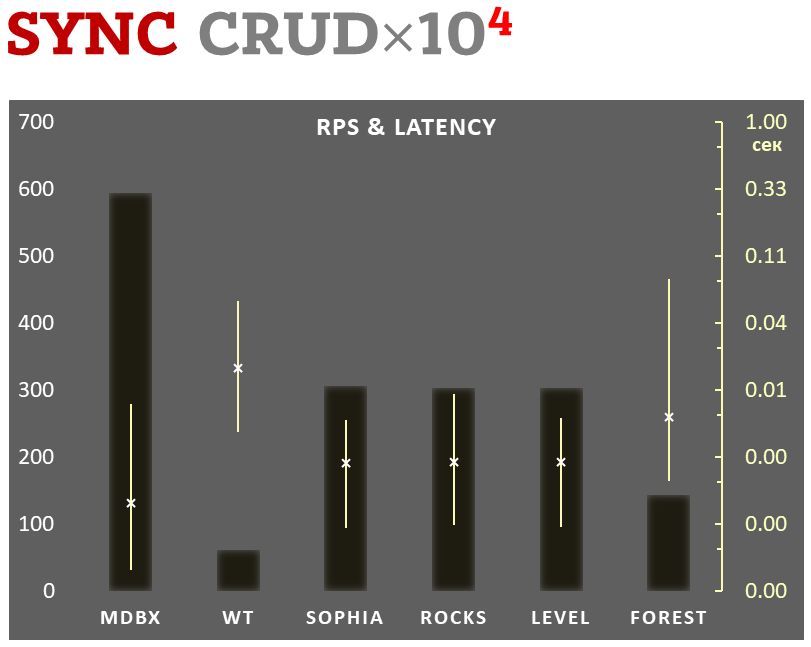
|
||||
|
||||
@@ -188,18 +510,25 @@ Benchmark starts on empty database and after full run the database contains 10,0
|
||||
|
||||
### Lazy-write mode
|
||||
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean of
|
||||
thousands transactions per second;
|
||||
|
||||
- Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
|
||||
- Logarithmic scale on right in seconds and yellow intervals mean
|
||||
execution time of transactions. Each interval shows minimal and maximum
|
||||
execution time, cross marks standard deviation.
|
||||
|
||||
**100,000 transactions in lazy-write mode**.
|
||||
In case of a crash all data is consistent and state is right after one of last transactions, but transactions after it
|
||||
will be lost. Other DB engines use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction journal for that,
|
||||
which in turn depends on order of operations in journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations
|
||||
**100,000 transactions in lazy-write mode**. In case of a crash all data
|
||||
is consistent and state is right after one of last transactions, but
|
||||
transactions after it will be lost. Other DB engines use
|
||||
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction
|
||||
journal for that, which in turn depends on order of operations in
|
||||
journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations
|
||||
to filesystem and OS kernel (mmap).
|
||||
|
||||
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
|
||||
Benchmark starts on empty database and after full run the database contains 100,000 small key-value records.
|
||||
In the benchmark each transaction contains combined CRUD operations (2
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
||||
and after full run the database contains 100,000 small key-value
|
||||
records.
|
||||
|
||||
|
||||
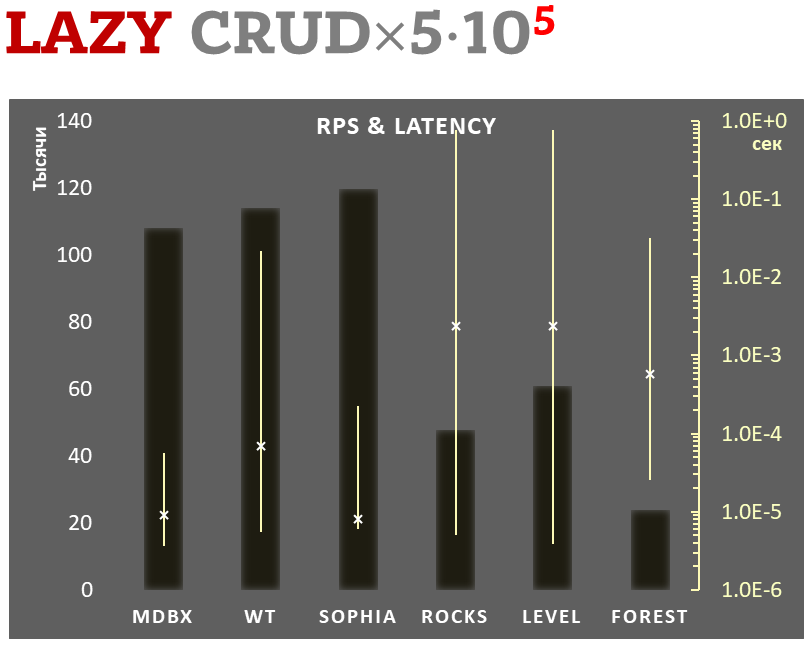
|
||||
@@ -208,14 +537,23 @@ Benchmark starts on empty database and after full run the database contains 100,
|
||||
|
||||
### Async-write mode
|
||||
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean of
|
||||
thousands transactions per second;
|
||||
|
||||
- Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
|
||||
- Logarithmic scale on right in seconds and yellow intervals mean
|
||||
execution time of transactions. Each interval shows minimal and maximum
|
||||
execution time, cross marks standard deviation.
|
||||
|
||||
**1,000,000 transactions in async-write mode**. In case of a crash all data will be consistent and state will be right after one of last transactions, but lost transaction count is much higher than in lazy-write mode. All DB engines in this mode do as little writes as possible on persistent storage. _libmdbx_ uses [msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode.
|
||||
**1,000,000 transactions in async-write mode**. In case of a crash all
|
||||
data will be consistent and state will be right after one of last
|
||||
transactions, but lost transaction count is much higher than in
|
||||
lazy-write mode. All DB engines in this mode do as little writes as
|
||||
possible on persistent storage. _libmdbx_ uses
|
||||
[msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode.
|
||||
|
||||
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
|
||||
Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
|
||||
In the benchmark each transaction contains combined CRUD operations (2
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
||||
and after full run the database contains 10,000 small key-value records.
|
||||
|
||||
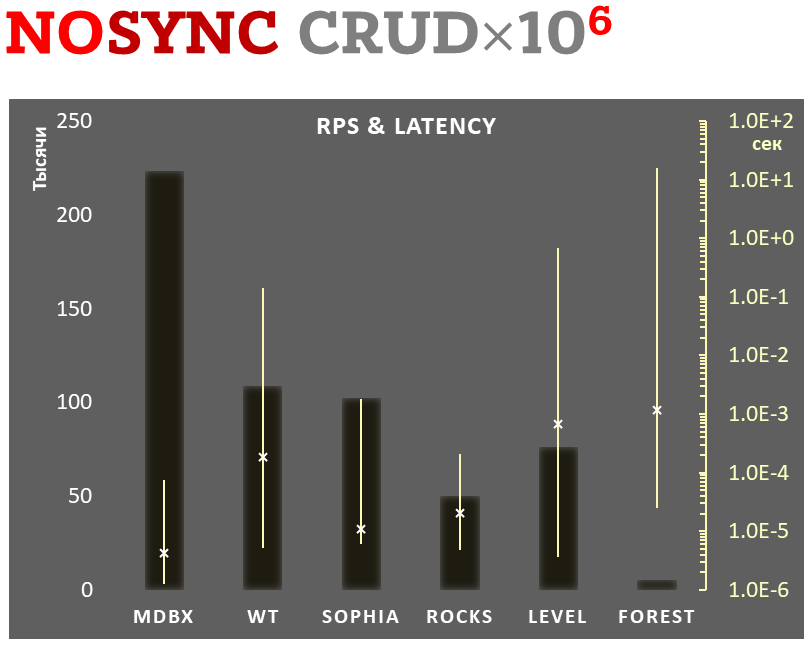
|
||||
|
||||
@@ -229,237 +567,22 @@ Summary of used resources during lazy-write mode benchmarks:
|
||||
|
||||
- Sum of user CPU time and sys CPU time;
|
||||
|
||||
- Used space on persistent storage after the test and closed DB, but not waiting for the end of all internal
|
||||
housekeeping operations (LSM compactification, etc).
|
||||
- Used space on persistent storage after the test and closed DB, but not
|
||||
waiting for the end of all internal housekeeping operations (LSM
|
||||
compactification, etc).
|
||||
|
||||
_ForestDB_ is excluded because benchmark showed it's resource consumption for each resource (CPU, IOPS) much higher than other engines which prevents to meaningfully compare it with them.
|
||||
_ForestDB_ is excluded because benchmark showed it's resource
|
||||
consumption for each resource (CPU, IOPS) much higher than other engines
|
||||
which prevents to meaningfully compare it with them.
|
||||
|
||||
All benchmark data is gathered by [getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) syscall and by
|
||||
scanning data directory.
|
||||
All benchmark data is gathered by
|
||||
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html)
|
||||
syscall and by scanning data directory.
|
||||
|
||||
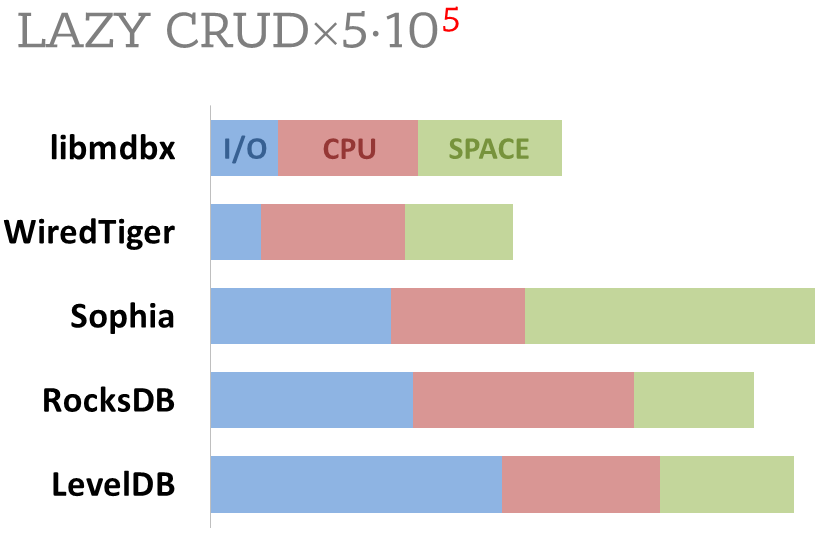
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
## Gotchas
|
||||
|
||||
1. At one moment there can be only one writer. But this allows to serialize writes and eliminate any possibility
|
||||
of conflict or logical errors during transaction rollback.
|
||||
|
||||
2. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) means relatively
|
||||
big [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor).
|
||||
Because of this syncing data to disk might be quite resource intensive and be main performance bottleneck
|
||||
during intensive write workload.
|
||||
> As compromise _libmdbx_ allows several modes of lazy and/or periodic syncing, including `MAPASYNC` mode, which modificate
|
||||
> data in memory and asynchronously syncs data to disk, moment to sync is picked by OS.
|
||||
>
|
||||
> Although this should be used with care, synchronous transactions in a DB with transaction journal will require 2 IOPS
|
||||
> minimum (probably 3-4 in practice) because of filesystem overhead, overhead depends on filesystem, not on record
|
||||
> count or record size. In _libmdbx_ IOPS count will grow logarithmically depending on record count in DB (height of B+ tree)
|
||||
> and will require at least 2 IOPS per transaction too.
|
||||
|
||||
3. [CoW](https://en.wikipedia.org/wiki/Copy-on-write)
|
||||
for [MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) is done on memory page level with [B+
|
||||
trees](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
||||
Therefore altering data requires to copy about Olog(N) memory pages, which uses [memory bandwidth](https://en.wikipedia.org/wiki/Memory_bandwidth) and is main performance bottleneck in `MAPASYNC` mode.
|
||||
> This is unavoidable, but isn't that bad. Syncing data to disk requires much more similar operations which will
|
||||
> be done by OS, therefore this is noticeable only if data sync to persistent storage is fully disabled.
|
||||
> _libmdbx_ allows to safely save data to persistent storage with minimal performance overhead. If there is no need
|
||||
> to save data to persistent storage then it's much more preferable to use `std::map`.
|
||||
|
||||
|
||||
4. LMDB has a problem of long-time readers which degrades performance and bloats DB
|
||||
> _libmdbx_ addresses that, details below.
|
||||
|
||||
5. _LMDB_ is susceptible to DB corruption in `WRITEMAP+MAPASYNC` mode.
|
||||
_libmdbx_ in `WRITEMAP+MAPASYNC` guarantees DB integrity and consistency of data.
|
||||
> Additionally there is an alternative: `UTTERLY_NOSYNC` mode. Details below.
|
||||
|
||||
|
||||
#### Long-time read transactions problem
|
||||
|
||||
Garbage collection problem exists in all databases one way or another (e.g. VACUUM in PostgreSQL).
|
||||
But in _libmdbx_ and LMDB it's even more important because of high performance and deliberate
|
||||
simplification of internals with emphasis on performance.
|
||||
|
||||
* Altering data during long read operation may exhaust available space on persistent storage.
|
||||
|
||||
* If available space is exhausted then any attempt to update data
|
||||
results in `MAP_FULL` error until long read operation ends.
|
||||
|
||||
* Main examples of long readers is hot backup
|
||||
and debugging of client application which actively uses read transactions.
|
||||
|
||||
* In _LMDB_ this results in degraded performance of all operations
|
||||
of syncing data to persistent storage.
|
||||
|
||||
* _libmdbx_ has a mechanism which aborts such operations and `LIFO RECLAIM`
|
||||
mode which addresses performance degradation.
|
||||
|
||||
Read operations operate only over snapshot of DB which is consistent on the moment when read transaction started.
|
||||
This snapshot doesn't change throughout the transaction but this leads to inability to reclaim the pages until
|
||||
read transaction ends.
|
||||
|
||||
In _LMDB_ this leads to a problem that memory pages, allocated for operations during long read, will be used for operations
|
||||
and won't be reclaimed until DB process terminates. In _LMDB_ they are used in
|
||||
[FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)) manner, which causes increased page count
|
||||
and less chance of cache hit during I/O. In other words: one long-time reader can impact performance of all database
|
||||
until it'll be reopened.
|
||||
|
||||
_libmdbx_ addresses the problem, details below. Illustrations to this problem can be found in the
|
||||
[presentation](http://www.slideshare.net/leoyuriev/lmdb). There is also example of performance increase thanks to
|
||||
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) when `LIFO RECLAIM` enabled in _libmdbx_.
|
||||
|
||||
#### Data safety in async-write mode
|
||||
|
||||
In `WRITEMAP+MAPSYNC` mode dirty pages are written to persistent storage by kernel. This means that in case of application
|
||||
crash OS kernel will write all dirty data to disk and nothing will be lost. But in case of hardware malfunction or OS kernel
|
||||
fatal error only some dirty data might be synced to disk, and there is high probability that pages with metadata saved,
|
||||
will point to non-saved, hence non-existent, data pages. In such situation, DB is completely corrupted and can't be
|
||||
repaired even if there was full sync before the crash via `mdbx_env_sync().
|
||||
|
||||
_libmdbx_ addresses this by fully reimplementing write path of data:
|
||||
|
||||
* In `WRITEMAP+MAPSYNC` mode meta-data pages aren't updated in place, instead their shadow copies are used and their updates
|
||||
are synced after data is flushed to disk.
|
||||
|
||||
* During transaction commit _libmdbx_ marks synchronization points as steady or weak depending on how much synchronization
|
||||
needed between RAM and persistent storage, e.g. in `WRITEMAP+MAPSYNC` commited transactions are marked as weak,
|
||||
but during explicit data synchronization - as steady.
|
||||
|
||||
* _libmdbx_ maintains three separate meta-pages instead of two. This allows to commit transaction with steady or
|
||||
weak synchronization point without losing two previous synchronization points (one of them can be steady, and second - weak).
|
||||
This allows to order weak and steady synchronization points in any order without losing consistency in case of system crash.
|
||||
|
||||
* During DB open _libmdbx_ rollbacks to the last steady synchronization point, this guarantees database integrity.
|
||||
|
||||
For data safety pages which form database snapshot with steady synchronization point must not be updated until next steady
|
||||
synchronization point. So last steady synchronization point creates "long-time read" effect. The only difference that in case
|
||||
of memory exhaustion the problem will be immediately addressed by flushing changes to persistent storage and forming new steady
|
||||
synchronization point.
|
||||
|
||||
So in async-write mode _libmdbx_ will always use new pages until memory is exhausted or `mdbx_env_sync()` is invoked. Total
|
||||
disk usage will be almost the same as in sync-write mode.
|
||||
|
||||
Current _libmdbx_ gives a choice of safe async-write mode (default) and `UTTERLY_NOSYNC` mode which may result in full DB
|
||||
corruption during system crash as with LMDB.
|
||||
|
||||
Next version of _libmdbx_ will create steady synchronization points automatically in async-write mode.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Improvements over LMDB
|
||||
================================================
|
||||
|
||||
1. `LIFO RECLAIM` mode:
|
||||
|
||||
The newest pages are picked for reuse instead of the oldest.
|
||||
This allows to minimize reclaim loop and make it execution time independent of total page count.
|
||||
|
||||
This results in OS kernel cache mechanisms working with maximum efficiency.
|
||||
In case of using disk controllers or storages with
|
||||
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) this may greatly improve
|
||||
write performance.
|
||||
|
||||
2. `OOM-KICK` callback.
|
||||
|
||||
`mdbx_env_set_oomfunc()` allows to set a callback, which will be called
|
||||
in the event of memory exhausting during long-time read transaction.
|
||||
Callback will be invoked with PID and pthread_id of offending thread as parameters.
|
||||
Callback can do any of these things to remedy the problem:
|
||||
|
||||
* wait for read transaction to finish normally;
|
||||
|
||||
* kill the offending process (signal 9), if separate process is doing long-time read;
|
||||
|
||||
* abort or restart offending read transaction if it's running in sibling thread;
|
||||
|
||||
* abort current write transaction with returning error code.
|
||||
|
||||
3. Guarantee of DB integrity in `WRITEMAP+MAPSYNC` mode:
|
||||
> Current _libmdbx_ gives a choice of safe async-write mode (default)
|
||||
> and `UTTERLY_NOSYNC` mode which may result in full
|
||||
> DB corruption during system crash as with LMDB. For details see
|
||||
> [Data safety in async-write mode](#data-safety-in-async-write-mode).
|
||||
|
||||
4. Automatic creation of synchronization points (flush changes to persistent storage)
|
||||
when changes reach set threshold (threshold can be set by `mdbx_env_set_syncbytes()`).
|
||||
|
||||
5. Ability to get how far current read-only snapshot is from latest version of the DB by `mdbx_txn_straggler()`.
|
||||
|
||||
6. `mdbx_chk` tool for DB checking and `mdbx_env_pgwalk()` for page-walking all pages in DB.
|
||||
|
||||
7. Control over debugging and receiving of debugging messages via `mdbx_setup_debug()`.
|
||||
|
||||
8. Ability to assign up to 3 markers to commiting transaction with `mdbx_canary_put()` and then get them in read transaction
|
||||
by `mdbx_canary_get()`.
|
||||
|
||||
9. Check if there is a row with data after current cursor position via `mdbx_cursor_eof()`.
|
||||
|
||||
10. Ability to explicitly request update of present record without creating new record. Implemented as `MDBX_CURRENT` flag
|
||||
for `mdbx_put()`.
|
||||
|
||||
11. Ability to update or delete record and get previous value via `mdbx_replace()` Also can update specific multi-value.
|
||||
|
||||
12. Support for keys and values of zero length, including sorted duplicates.
|
||||
|
||||
13. Fixed `mdbx_cursor_count()`, which returns correct count of duplicated for all table types and any cursor position.
|
||||
|
||||
14. Ability to open DB in exclusive mode via `mdbx_env_open_ex()`, e.g. for integrity check.
|
||||
|
||||
15. Ability to close DB in "dirty" state (without data flush and creation of steady synchronization point)
|
||||
via `mdbx_env_close_ex()`.
|
||||
|
||||
16. Ability to get additional info, including number of the oldest snapshot of DB, which is used by one of the readers.
|
||||
Implemented via `mdbx_env_info()`.
|
||||
|
||||
17. `mdbx_del()` doesn't ignore additional argument (specifier) `data`
|
||||
for tables without duplicates (without flag `MDBX_DUPSORT`), if `data` is not zero then always uses it to verify
|
||||
record, which is being deleted.
|
||||
|
||||
18. Ability to open dbi-table with simultaneous setup of comparators for keys and values, via `mdbx_dbi_open_ex()`.
|
||||
|
||||
19. Ability to find out if key or value is in dirty page. This may be useful to make a decision to avoid
|
||||
excessive CoW before updates. Implemented via `mdbx_is_dirty()`.
|
||||
|
||||
20. Correct update of current record in `MDBX_CURRENT` mode of `mdbx_cursor_put()`, including sorted duplicated.
|
||||
|
||||
21. All cursors in all read and write transactions can be reused by `mdbx_cursor_renew()` and MUST be freed explicitly.
|
||||
> ## Caution, please pay attention!
|
||||
>
|
||||
> This is the only change of API, which changes semantics of cursor management
|
||||
> and can lead to memory leaks on misuse. This is a needed change as it eliminates ambiguity
|
||||
> which helps to avoid such errors as:
|
||||
> - use-after-free;
|
||||
> - double-free;
|
||||
> - memory corruption and segfaults.
|
||||
|
||||
22. Additional error code `MDBX_EMULTIVAL`, which is returned by `mdbx_put()` and
|
||||
`mdbx_replace()` in case is ambiguous update or delete.
|
||||
|
||||
23. Ability to get value by key and duplicates count by `mdbx_get_ex()`.
|
||||
|
||||
24. Functions `mdbx_cursor_on_first() and mdbx_cursor_on_last(), which allows to know if cursor is currently on first or
|
||||
last position respectively.
|
||||
|
||||
25. If read transaction is aborted via `mdbx_txn_abort()` or `mdbx_txn_reset()` then DBI-handles, which were opened in it,
|
||||
aren't closed or deleted. This allows to avoid several types of hard-to-debug errors.
|
||||
|
||||
26. Sequence generation via `mdbx_dbi_sequence()`.
|
||||
|
||||
27. Advanced dynamic control over DB size, including ability to choose page size via `mdbx_env_set_geometry()`,
|
||||
including on Windows.
|
||||
|
||||
28. Three meta-pages instead of two, this allows to guarantee consistently update weak sync-points without risking to
|
||||
corrupt last steady sync-point.
|
||||
|
||||
29. Automatic reclaim of freed pages to specific reserved space at the end of database file. This lowers amount of pages,
|
||||
loaded to memory, used in update/flush loop. In fact _libmdbx_ constantly performs compactification of data,
|
||||
but doesn't use additional resources for that. Space reclaim of DB and setup of database geometry parameters also decreases
|
||||
size of the database on disk, including on Windows.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
$ objdump -f -h -j .text libmdbx.so
|
||||
|
||||
@@ -474,16 +597,3 @@ Idx Name Size VMA LMA File off Algn
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
$ gcc -v
|
||||
Using built-in specs.
|
||||
COLLECT_GCC=gcc
|
||||
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/7/lto-wrapper
|
||||
OFFLOAD_TARGET_NAMES=nvptx-none
|
||||
OFFLOAD_TARGET_DEFAULT=1
|
||||
Target: x86_64-linux-gnu
|
||||
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 7.2.0-8ubuntu3' --with-bugurl=file:///usr/share/doc/gcc-7/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-7 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
|
||||
Thread model: posix
|
||||
gcc version 7.2.0 (Ubuntu 7.2.0-8ubuntu3)
|
||||
```
|
||||
|
||||
89
TODO.md
89
TODO.md
@@ -1,89 +0,0 @@
|
||||
Допеределки
|
||||
===========
|
||||
- [ ] Перевод mdbx-tools на С++ и сборка для Windows.
|
||||
- [ ] Переход на CMake, замена заглушек mdbx_version и mdbx_build.
|
||||
- [ ] Актуализация README.md
|
||||
- [ ] Переход на C++11, добавление #pramga detect_mismatch().
|
||||
- [ ] Убрать MDB_DEBUG (всегда: логирование важный ситуаций и ошибок, опционально: включение ассертов и трассировка).
|
||||
- [ ] Заменить mdbx_debug на mdbx_trace, и почистить...
|
||||
- [ ] Заметить максимум assert() на mdbx_assert(env, ...).
|
||||
|
||||
Качество и CI
|
||||
=============
|
||||
- [ ] Добавить в CI linux сборки для 32-битных таргетов.
|
||||
|
||||
Доработки API
|
||||
=============
|
||||
- [ ] Поправить/Добавить описание нового API.
|
||||
- [ ] Добавить возможность "подбора" режима для mdbx_env_open().
|
||||
- [ ] Переименовать в API: env->db, db->tbl.
|
||||
|
||||
Тесты
|
||||
=====
|
||||
- [ ] Тестирование поддержки lockless-режима.
|
||||
- [x] Додумать имя и размещение тестовой БД по-умолчанию.
|
||||
- [ ] Реализовать cleanup в тесте.
|
||||
- [ ] usage для теста.
|
||||
- [ ] Логирование в файл, плюс более полный progress bar.
|
||||
- [ ] Опция игнорирования (пропуска части теста) при переполнении БД.
|
||||
- [ ] Базовый бенчмарк.
|
||||
|
||||
Развитие
|
||||
========
|
||||
- [ ] Отслеживание времени жизни DBI-хендлов.
|
||||
- [ ] Отрефакторить mdbx_freelist_save().
|
||||
- [ ] Хранить "свободный хвост" не связанный с freeDB в META.
|
||||
- [x] Возврат выделенных страниц в unallocated tail-pool.
|
||||
- [ ] Валидатор страниц БД по номеру транзакции:
|
||||
~0 при переработке и номер транзакции при выделении,
|
||||
проверять что этот номер больше головы реклайминга и не-больше текущей транзакции.
|
||||
- [ ] Размещение overflow-pages в отдельном mmap/файле с собственной геометрией.
|
||||
- [ ] Зафиксировать формат БД.
|
||||
- [ ] Валидатор страниц по CRC32, плюс контроль номер транзакии под модулю 2^32.
|
||||
- [ ] Валидатор страниц по t1ha c контролем снимков/версий БД на основе Merkle Tree.
|
||||
- [ ] Возможность хранения ключей внутри data (libfptu).
|
||||
- [ ] Асинхронная фиксация (https://github.com/leo-yuriev/libmdbx/issues/5).
|
||||
- [ ] (Пере)Выделять память под IDL-списки с учетом реального кол-ва страниц, т.е. max(MDB_IDL_UM_MAX/MDB_IDL_UM_MAX, npages).
|
||||
|
||||
-----------------------------------------------------------------------
|
||||
|
||||
Сделано
|
||||
=======
|
||||
- [x] разделение errno и GetLastError().
|
||||
- [x] CI посредством AppVeyor.
|
||||
- [x] тест конкурентного доступа.
|
||||
- [x] тест основного функционала (заменить текущий треш).
|
||||
- [x] uint32/uint64 в структурах.
|
||||
- [x] Завершить переименование.
|
||||
- [x] Макросы версионности, сделать как в fpta (cmake?).
|
||||
- [x] Попробовать убрать yield (или что там с местом?).
|
||||
- [x] trinity для copy/compaction.
|
||||
- [x] trinity для mdbx_chk и mdbx_stat.
|
||||
- [x] проверки с mdbx_meta_eq.
|
||||
- [x] Не проверять режим при открытии в readonly.
|
||||
- [x] Поправить выбор tail в mdbx_chk.
|
||||
- [x] Там-же проверять позицию реклайминга.
|
||||
- [x] поправить проблему открытия после READ-ONLY.
|
||||
- [x] static-assertы на размер/выравнивание lck, meta и т.п.
|
||||
- [x] Зачистить size_t.
|
||||
- [x] Добавить локи вокруг dbi.
|
||||
- [x] Привести в порядок volatile.
|
||||
- [x] контроль meta.mapsize.
|
||||
- [x] переработка формата: заголовки страниц, meta, clk...
|
||||
- [x] зачистка Doxygen и бесполезных комментариев.
|
||||
- [x] Добавить поле типа контрольной суммы.
|
||||
- [x] Добавить поле/флаг размера pgno_t.
|
||||
- [x] Поменять сигнатуры.
|
||||
- [x] Добавить мета-страницы в coredump, проверить lck.
|
||||
- [x] Сделать список для txnid_t, кода sizeof(txnid_t) > sizeof(pgno_t) и вернуть размер pgno_t.
|
||||
- [x] Избавиться от умножения на размер страницы (заменить на сдвиг).
|
||||
- [x] Устранение всех предупреждений (в том числе под Windows).
|
||||
- [x] Добавить 'mti_reader_finished_flag'.
|
||||
- [x] Погасить все level4-warnings от MSVC, включить /WX.
|
||||
- [x] Проверка посредством Coverity с гашением всех дефектов.
|
||||
- [x] Полная матрица Windows-сборок (2013/2015/2017).
|
||||
- [x] Дать возможность задавать размер страницы при создании БД.
|
||||
- [x] Изменение mapsize через API с блокировкой и увеличением txn.
|
||||
- [x] Контроль размера страницы полного размера и кол-ва страниц при создании и обновлении.
|
||||
- [x] Инкрементальный mmap.
|
||||
- [x] Инкрементальное приращение размера (колбэк стратегии?).
|
||||
@@ -1,4 +1,4 @@
|
||||
version: 0.1.6.{build}
|
||||
version: 0.2.0.{build}
|
||||
|
||||
environment:
|
||||
matrix:
|
||||
|
||||
58
mdbx.h
58
mdbx.h
@@ -100,6 +100,7 @@ typedef DWORD mdbx_tid_t;
|
||||
#define MDBX_EIO ERROR_WRITE_FAULT
|
||||
#define MDBX_EPERM ERROR_INVALID_FUNCTION
|
||||
#define MDBX_EINTR ERROR_CANCELLED
|
||||
#define MDBX_ENOFILE ERROR_FILE_NOT_FOUND
|
||||
|
||||
#else
|
||||
|
||||
@@ -120,6 +121,8 @@ typedef pthread_t mdbx_tid_t;
|
||||
#define MDBX_EIO EIO
|
||||
#define MDBX_EPERM EPERM
|
||||
#define MDBX_EINTR EINTR
|
||||
#define MDBX_ENOFILE ENOENT
|
||||
|
||||
#endif
|
||||
|
||||
#ifdef _MSC_VER
|
||||
@@ -165,7 +168,7 @@ typedef pthread_t mdbx_tid_t;
|
||||
/*--------------------------------------------------------------------------*/
|
||||
|
||||
#define MDBX_VERSION_MAJOR 0
|
||||
#define MDBX_VERSION_MINOR 1
|
||||
#define MDBX_VERSION_MINOR 2
|
||||
|
||||
#if defined(LIBMDBX_EXPORTS)
|
||||
#define LIBMDBX_API __dll_export
|
||||
@@ -203,6 +206,24 @@ typedef struct mdbx_build_info {
|
||||
extern LIBMDBX_API const mdbx_version_info mdbx_version;
|
||||
extern LIBMDBX_API const mdbx_build_info mdbx_build;
|
||||
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
|
||||
/* Dll initialization callback for ability to dynamically load MDBX DLL by
|
||||
* LoadLibrary() on Windows versions before Windows Vista. This function MUST be
|
||||
* called once from DllMain() for each reason (DLL_PROCESS_ATTACH,
|
||||
* DLL_PROCESS_DETACH, DLL_THREAD_ATTACH and DLL_THREAD_DETACH). Do this
|
||||
* carefully and ONLY when actual Windows version don't support initialization
|
||||
* via "TLS Directory" (e.g .CRT$XL[A-Z] sections in executable or dll file). */
|
||||
|
||||
#ifndef MDBX_CONFIG_MANUAL_TLS_CALLBACK
|
||||
#define MDBX_CONFIG_MANUAL_TLS_CALLBACK 0
|
||||
#endif
|
||||
#if MDBX_CONFIG_MANUAL_TLS_CALLBACK
|
||||
void LIBMDBX_API NTAPI mdbx_dll_callback(PVOID module, DWORD reason,
|
||||
PVOID reserved);
|
||||
#endif /* MDBX_CONFIG_MANUAL_TLS_CALLBACK */
|
||||
#endif /* Windows */
|
||||
|
||||
/* The name of the lock file in the DB environment */
|
||||
#define MDBX_LOCKNAME "/mdbx.lck"
|
||||
/* The name of the data file in the DB environment */
|
||||
@@ -270,9 +291,8 @@ typedef int(MDBX_cmp_func)(const MDBX_val *a, const MDBX_val *b);
|
||||
#define MDBX_MAPASYNC 0x100000u
|
||||
/* tie reader locktable slots to MDBX_txn objects instead of to threads */
|
||||
#define MDBX_NOTLS 0x200000u
|
||||
/* don't do any locking, caller must manage their own locks
|
||||
* WARNING: libmdbx don't support this mode. */
|
||||
#define MDBX_NOLOCK__UNSUPPORTED 0x400000u
|
||||
/* open DB in exclusive/monopolistic mode. */
|
||||
#define MDBX_EXCLUSIVE 0x400000u
|
||||
/* don't do readahead */
|
||||
#define MDBX_NORDAHEAD 0x800000u
|
||||
/* don't initialize malloc'd memory before writing to datafile */
|
||||
@@ -652,8 +672,6 @@ LIBMDBX_API int mdbx_env_create(MDBX_env **penv);
|
||||
* - MDBX_EAGAIN - the environment was locked by another process. */
|
||||
LIBMDBX_API int mdbx_env_open(MDBX_env *env, const char *path, unsigned flags,
|
||||
mode_t mode);
|
||||
LIBMDBX_API int mdbx_env_open_ex(MDBX_env *env, const char *path,
|
||||
unsigned flags, mode_t mode, int *exclusive);
|
||||
|
||||
/* Copy an MDBX environment to the specified path, with options.
|
||||
*
|
||||
@@ -680,7 +698,8 @@ LIBMDBX_API int mdbx_env_open_ex(MDBX_env *env, const char *path,
|
||||
* NOTE: Currently it fails if the environment has suffered a page leak.
|
||||
*
|
||||
* Returns A non-zero error value on failure and 0 on success. */
|
||||
LIBMDBX_API int mdbx_env_copy(MDBX_env *env, const char *path, unsigned flags);
|
||||
LIBMDBX_API int mdbx_env_copy(MDBX_env *env, const char *dest_path,
|
||||
unsigned flags);
|
||||
|
||||
/* Copy an MDBX environment to the specified file descriptor,
|
||||
* with options.
|
||||
@@ -900,7 +919,6 @@ LIBMDBX_API int mdbx_env_set_maxdbs(MDBX_env *env, MDBX_dbi dbs);
|
||||
*
|
||||
* Returns The maximum size of a key we can write. */
|
||||
LIBMDBX_API int mdbx_env_get_maxkeysize(MDBX_env *env);
|
||||
LIBMDBX_API int mdbx_get_maxkeysize(intptr_t pagesize);
|
||||
|
||||
/* Set application information associated with the MDBX_env.
|
||||
*
|
||||
@@ -1228,6 +1246,8 @@ LIBMDBX_API int mdbx_drop(MDBX_txn *txn, MDBX_dbi dbi, int del);
|
||||
* - MDBX_EINVAL - an invalid parameter was specified. */
|
||||
LIBMDBX_API int mdbx_get(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key,
|
||||
MDBX_val *data);
|
||||
LIBMDBX_API int mdbx_get2(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key,
|
||||
MDBX_val *data);
|
||||
|
||||
/* Store items into a database.
|
||||
*
|
||||
@@ -1633,10 +1653,22 @@ typedef void MDBX_debug_func(int type, const char *function, int line,
|
||||
|
||||
LIBMDBX_API int mdbx_setup_debug(int flags, MDBX_debug_func *logger);
|
||||
|
||||
typedef int MDBX_pgvisitor_func(uint64_t pgno, unsigned pgnumber, void *ctx,
|
||||
const char *dbi, const char *type,
|
||||
size_t nentries, size_t payload_bytes,
|
||||
size_t header_bytes, size_t unused_bytes);
|
||||
typedef enum {
|
||||
MDBX_page_void,
|
||||
MDBX_page_meta,
|
||||
MDBX_page_large,
|
||||
MDBX_page_branch,
|
||||
MDBX_page_leaf,
|
||||
MDBX_page_dupfixed_leaf,
|
||||
MDBX_subpage_leaf,
|
||||
MDBX_subpage_dupfixed_leaf
|
||||
} MDBX_page_type_t;
|
||||
|
||||
typedef int MDBX_pgvisitor_func(uint64_t pgno, unsigned number, void *ctx,
|
||||
int deep, const char *dbi, size_t page_size,
|
||||
MDBX_page_type_t type, size_t nentries,
|
||||
size_t payload_bytes, size_t header_bytes,
|
||||
size_t unused_bytes);
|
||||
LIBMDBX_API int mdbx_env_pgwalk(MDBX_txn *txn, MDBX_pgvisitor_func *visitor,
|
||||
void *ctx);
|
||||
|
||||
@@ -1680,6 +1712,8 @@ LIBMDBX_API int mdbx_limits_pgsize_min(void);
|
||||
LIBMDBX_API int mdbx_limits_pgsize_max(void);
|
||||
LIBMDBX_API intptr_t mdbx_limits_dbsize_min(intptr_t pagesize);
|
||||
LIBMDBX_API intptr_t mdbx_limits_dbsize_max(intptr_t pagesize);
|
||||
LIBMDBX_API intptr_t mdbx_limits_keysize_max(intptr_t pagesize);
|
||||
LIBMDBX_API intptr_t mdbx_limits_txnsize_max(intptr_t pagesize);
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
/* attribute support functions for Nexenta */
|
||||
|
||||
@@ -3,8 +3,8 @@ set(TARGET mdbx)
|
||||
project(${TARGET})
|
||||
|
||||
set(MDBX_VERSION_MAJOR 0)
|
||||
set(MDBX_VERSION_MINOR 1)
|
||||
set(MDBX_VERSION_RELEASE 6)
|
||||
set(MDBX_VERSION_MINOR 2)
|
||||
set(MDBX_VERSION_RELEASE 0)
|
||||
set(MDBX_VERSION_REVISION 0)
|
||||
|
||||
set(MDBX_VERSION_STRING ${MDBX_VERSION_MAJOR}.${MDBX_VERSION_MINOR}.${MDBX_VERSION_RELEASE})
|
||||
133
src/bits.h
133
src/bits.h
@@ -34,6 +34,9 @@
|
||||
#endif
|
||||
|
||||
#ifdef _MSC_VER
|
||||
# if _MSC_VER < 1400
|
||||
# error "Microsoft Visual C++ 8.0 (Visual Studio 2005) or later version is required"
|
||||
# endif
|
||||
# ifndef _CRT_SECURE_NO_WARNINGS
|
||||
# define _CRT_SECURE_NO_WARNINGS
|
||||
# endif
|
||||
@@ -117,6 +120,12 @@
|
||||
/* *INDENT-ON* */
|
||||
/* clang-format on */
|
||||
|
||||
#if UINTPTR_MAX > 0xffffFFFFul || ULONG_MAX > 0xffffFFFFul
|
||||
#define MDBX_WORDBITS 64
|
||||
#else
|
||||
#define MDBX_WORDBITS 32
|
||||
#endif /* MDBX_WORDBITS */
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
/* Basic constants and types */
|
||||
|
||||
@@ -391,7 +400,11 @@ typedef struct MDBX_page {
|
||||
#endif
|
||||
#define MAX_MAPSIZE64 (MAX_PAGENO * (uint64_t)MAX_PAGESIZE)
|
||||
|
||||
#define MAX_MAPSIZE ((sizeof(size_t) < 8) ? MAX_MAPSIZE32 : MAX_MAPSIZE64)
|
||||
#if MDBX_WORDBITS >= 64
|
||||
#define MAX_MAPSIZE MAX_MAPSIZE64
|
||||
#else
|
||||
#define MAX_MAPSIZE MAX_MAPSIZE32
|
||||
#endif /* MDBX_WORDBITS */
|
||||
|
||||
/* The header for the reader table (a memory-mapped lock file). */
|
||||
typedef struct MDBX_lockinfo {
|
||||
@@ -466,6 +479,10 @@ typedef struct MDBX_lockinfo {
|
||||
|
||||
#define MDBX_LOCK_MAGIC ((MDBX_MAGIC << 8) + MDBX_LOCK_VERSION)
|
||||
|
||||
#ifndef MDBX_ASSUME_MALLOC_OVERHEAD
|
||||
#define MDBX_ASSUME_MALLOC_OVERHEAD (sizeof(void *) * 2u)
|
||||
#endif /* MDBX_ASSUME_MALLOC_OVERHEAD */
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
/* Two kind lists of pages (aka PNL) */
|
||||
|
||||
@@ -487,35 +504,46 @@ typedef pgno_t *MDBX_PNL;
|
||||
/* List of txnid, only for MDBX_env.mt_lifo_reclaimed */
|
||||
typedef txnid_t *MDBX_TXL;
|
||||
|
||||
/* An ID2 is an ID/pointer pair. */
|
||||
typedef struct MDBX_ID2 {
|
||||
pgno_t mid; /* The ID */
|
||||
void *mptr; /* The pointer */
|
||||
} MDBX_ID2;
|
||||
/* An Dirty-Page list item is an pgno/pointer pair. */
|
||||
typedef union MDBX_DP {
|
||||
struct {
|
||||
pgno_t pgno;
|
||||
void *ptr;
|
||||
};
|
||||
struct {
|
||||
pgno_t unused;
|
||||
unsigned length;
|
||||
};
|
||||
} MDBX_DP;
|
||||
|
||||
/* An ID2L is an ID2 List, a sorted array of ID2s.
|
||||
* The first element's mid member is a count of how many actual
|
||||
* elements are in the array. The mptr member of the first element is
|
||||
* unused. The array is sorted in ascending order by mid. */
|
||||
typedef MDBX_ID2 *MDBX_ID2L;
|
||||
/* An DPL (dirty-page list) is a sorted array of MDBX_DPs.
|
||||
* The first element's length member is a count of how many actual
|
||||
* elements are in the array. */
|
||||
typedef MDBX_DP *MDBX_DPL;
|
||||
|
||||
/* PNL sizes - likely should be even bigger
|
||||
* limiting factors: sizeof(pgno_t), thread stack size */
|
||||
#define MDBX_PNL_LOGN 16 /* DB_SIZE is 2^16, UM_SIZE is 2^17 */
|
||||
#define MDBX_PNL_DB_SIZE (1 << MDBX_PNL_LOGN)
|
||||
#define MDBX_PNL_UM_SIZE (1 << (MDBX_PNL_LOGN + 1))
|
||||
/* PNL sizes - likely should be even bigger */
|
||||
#define MDBX_PNL_GRANULATE 1024
|
||||
#define MDBX_PNL_INITIAL \
|
||||
(MDBX_PNL_GRANULATE - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(pgno_t))
|
||||
#define MDBX_PNL_MAX \
|
||||
((1u << 24) - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(pgno_t))
|
||||
#define MDBX_DPL_TXNFULL (MDBX_PNL_MAX / 4)
|
||||
|
||||
#define MDBX_PNL_DB_MAX (MDBX_PNL_DB_SIZE - 1)
|
||||
#define MDBX_PNL_UM_MAX (MDBX_PNL_UM_SIZE - 1)
|
||||
#define MDBX_TXL_GRANULATE 32
|
||||
#define MDBX_TXL_INITIAL \
|
||||
(MDBX_TXL_GRANULATE - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(txnid_t))
|
||||
#define MDBX_TXL_MAX \
|
||||
((1u << 17) - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(txnid_t))
|
||||
|
||||
#define MDBX_PNL_SIZEOF(pl) (((pl)[0] + 1) * sizeof(pgno_t))
|
||||
#define MDBX_PNL_IS_ZERO(pl) ((pl)[0] == 0)
|
||||
#define MDBX_PNL_CPY(dst, src) (memcpy(dst, src, MDBX_PNL_SIZEOF(src)))
|
||||
#define MDBX_PNL_FIRST(pl) ((pl)[1])
|
||||
#define MDBX_PNL_LAST(pl) ((pl)[(pl)[0]])
|
||||
|
||||
/* Current max length of an mdbx_pnl_alloc()ed PNL */
|
||||
#define MDBX_PNL_ALLOCLEN(pl) ((pl)[-1])
|
||||
#define MDBX_PNL_SIZE(pl) ((pl)[0])
|
||||
#define MDBX_PNL_FIRST(pl) ((pl)[1])
|
||||
#define MDBX_PNL_LAST(pl) ((pl)[MDBX_PNL_SIZE(pl)])
|
||||
#define MDBX_PNL_BEGIN(pl) (&(pl)[1])
|
||||
#define MDBX_PNL_END(pl) (&(pl)[MDBX_PNL_SIZE(pl) + 1])
|
||||
|
||||
#define MDBX_PNL_SIZEOF(pl) ((MDBX_PNL_SIZE(pl) + 1) * sizeof(pgno_t))
|
||||
#define MDBX_PNL_IS_EMPTY(pl) (MDBX_PNL_SIZE(pl) == 0)
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
/* Internal structures */
|
||||
@@ -559,7 +587,7 @@ struct MDBX_txn {
|
||||
MDBX_PNL mt_spill_pages;
|
||||
union {
|
||||
/* For write txns: Modified pages. Sorted when not MDBX_WRITEMAP. */
|
||||
MDBX_ID2L mt_rw_dirtylist;
|
||||
MDBX_DPL mt_rw_dirtylist;
|
||||
/* For read txns: This thread/txn's reader table slot, or NULL. */
|
||||
MDBX_reader *mt_ro_reader;
|
||||
};
|
||||
@@ -657,8 +685,9 @@ struct MDBX_cursor {
|
||||
#define C_EOF 0x02 /* No more data */
|
||||
#define C_SUB 0x04 /* Cursor is a sub-cursor */
|
||||
#define C_DEL 0x08 /* last op was a cursor_del */
|
||||
#define C_UNTRACK 0x40 /* Un-track cursor when closing */
|
||||
#define C_RECLAIMING 0x80 /* FreeDB lookup is prohibited */
|
||||
#define C_UNTRACK 0x10 /* Un-track cursor when closing */
|
||||
#define C_RECLAIMING 0x20 /* FreeDB lookup is prohibited */
|
||||
#define C_GCFREEZE 0x40 /* me_reclaimed_pglist must not be updated */
|
||||
unsigned mc_flags; /* see mdbx_cursor */
|
||||
MDBX_page *mc_pg[CURSOR_STACK]; /* stack of pushed pages */
|
||||
indx_t mc_ki[CURSOR_STACK]; /* stack of page indices */
|
||||
@@ -679,6 +708,11 @@ typedef struct MDBX_xcursor {
|
||||
uint8_t mx_dbflag;
|
||||
} MDBX_xcursor;
|
||||
|
||||
typedef struct MDBX_cursor_couple {
|
||||
MDBX_cursor outer;
|
||||
MDBX_xcursor inner;
|
||||
} MDBX_cursor_couple;
|
||||
|
||||
/* Check if there is an inited xcursor, so XCURSOR_REFRESH() is proper */
|
||||
#define XCURSOR_INITED(mc) \
|
||||
((mc)->mc_xcursor && ((mc)->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED))
|
||||
@@ -729,14 +763,17 @@ struct MDBX_env {
|
||||
/* Max MDBX_lockinfo.mti_numreaders of interest to mdbx_env_close() */
|
||||
unsigned me_close_readers;
|
||||
mdbx_fastmutex_t me_dbi_lock;
|
||||
MDBX_dbi me_numdbs; /* number of DBs opened */
|
||||
MDBX_dbi me_maxdbs; /* size of the DB table */
|
||||
mdbx_pid_t me_pid; /* process ID of this env */
|
||||
mdbx_thread_key_t me_txkey; /* thread-key for readers */
|
||||
char *me_path; /* path to the DB files */
|
||||
void *me_pbuf; /* scratch area for DUPSORT put() */
|
||||
MDBX_txn *me_txn; /* current write transaction */
|
||||
MDBX_txn *me_txn0; /* prealloc'd write transaction */
|
||||
MDBX_dbi me_numdbs; /* number of DBs opened */
|
||||
MDBX_dbi me_maxdbs; /* size of the DB table */
|
||||
mdbx_pid_t me_pid; /* process ID of this env */
|
||||
mdbx_thread_key_t me_txkey; /* thread-key for readers */
|
||||
char *me_path; /* path to the DB files */
|
||||
void *me_pbuf; /* scratch area for DUPSORT put() */
|
||||
MDBX_txn *me_txn; /* current write transaction */
|
||||
MDBX_txn *me_txn0; /* prealloc'd write transaction */
|
||||
#ifdef MDBX_OSAL_LOCK
|
||||
MDBX_OSAL_LOCK *me_wmutex; /* write-txn mutex */
|
||||
#endif
|
||||
MDBX_dbx *me_dbxs; /* array of static DB info */
|
||||
uint16_t *me_dbflags; /* array of flags from MDBX_db.md_flags */
|
||||
unsigned *me_dbiseqs; /* array of dbi sequence numbers */
|
||||
@@ -747,8 +784,8 @@ struct MDBX_env {
|
||||
MDBX_page *me_dpages; /* list of malloc'd blocks for re-use */
|
||||
/* PNL of pages that became unused in a write txn */
|
||||
MDBX_PNL me_free_pgs;
|
||||
/* ID2L of pages written during a write txn. Length MDBX_PNL_UM_SIZE. */
|
||||
MDBX_ID2L me_dirtylist;
|
||||
/* MDBX_DP of pages written during a write txn. Length MDBX_DPL_TXNFULL. */
|
||||
MDBX_DPL me_dirtylist;
|
||||
/* Number of freelist items that can fit in a single overflow page */
|
||||
unsigned me_maxgc_ov1page;
|
||||
/* Max size of a node on a page */
|
||||
@@ -777,10 +814,11 @@ struct MDBX_env {
|
||||
} me_dbgeo; /* */
|
||||
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
SRWLOCK me_remap_guard;
|
||||
MDBX_srwlock me_remap_guard;
|
||||
/* Workaround for LockFileEx and WriteFile multithread bug */
|
||||
CRITICAL_SECTION me_windowsbug_lock;
|
||||
#else
|
||||
mdbx_fastmutex_t me_lckless_wmutex;
|
||||
mdbx_fastmutex_t me_remap_guard;
|
||||
#endif
|
||||
};
|
||||
@@ -815,11 +853,14 @@ void mdbx_panic(const char *fmt, ...)
|
||||
|
||||
#define mdbx_assert_enabled() unlikely(mdbx_runtime_flags &MDBX_DBG_ASSERT)
|
||||
|
||||
#define mdbx_audit_enabled() unlikely(mdbx_runtime_flags &MDBX_DBG_AUDIT)
|
||||
|
||||
#define mdbx_debug_enabled(type) \
|
||||
unlikely(mdbx_runtime_flags &(type & (MDBX_DBG_TRACE | MDBX_DBG_EXTRA)))
|
||||
|
||||
#else
|
||||
#define mdbx_debug_enabled(type) (0)
|
||||
#define mdbx_audit_enabled() (0)
|
||||
#if !defined(NDEBUG) || defined(MDBX_FORCE_ASSERT)
|
||||
#define mdbx_assert_enabled() (1)
|
||||
#else
|
||||
@@ -990,7 +1031,7 @@ void mdbx_rthc_thread_dtor(void *ptr);
|
||||
#define NUMKEYS(p) ((unsigned)(p)->mp_lower >> 1)
|
||||
|
||||
/* The amount of space remaining in the page */
|
||||
#define SIZELEFT(p) (indx_t)((p)->mp_upper - (p)->mp_lower)
|
||||
#define SIZELEFT(p) ((indx_t)((p)->mp_upper - (p)->mp_lower))
|
||||
|
||||
/* The percentage of space used in the page, in tenths of a percent. */
|
||||
#define PAGEFILL(env, p) \
|
||||
@@ -1001,15 +1042,17 @@ void mdbx_rthc_thread_dtor(void *ptr);
|
||||
#define FILL_THRESHOLD 256
|
||||
|
||||
/* Test if a page is a leaf page */
|
||||
#define IS_LEAF(p) F_ISSET((p)->mp_flags, P_LEAF)
|
||||
#define IS_LEAF(p) (((p)->mp_flags & P_LEAF) != 0)
|
||||
/* Test if a page is a LEAF2 page */
|
||||
#define IS_LEAF2(p) F_ISSET((p)->mp_flags, P_LEAF2)
|
||||
#define IS_LEAF2(p) unlikely(((p)->mp_flags & P_LEAF2) != 0)
|
||||
/* Test if a page is a branch page */
|
||||
#define IS_BRANCH(p) F_ISSET((p)->mp_flags, P_BRANCH)
|
||||
#define IS_BRANCH(p) (((p)->mp_flags & P_BRANCH) != 0)
|
||||
/* Test if a page is an overflow page */
|
||||
#define IS_OVERFLOW(p) unlikely(F_ISSET((p)->mp_flags, P_OVERFLOW))
|
||||
#define IS_OVERFLOW(p) unlikely(((p)->mp_flags & P_OVERFLOW) != 0)
|
||||
/* Test if a page is a sub page */
|
||||
#define IS_SUBP(p) F_ISSET((p)->mp_flags, P_SUBP)
|
||||
#define IS_SUBP(p) (((p)->mp_flags & P_SUBP) != 0)
|
||||
/* Test if a page is dirty */
|
||||
#define IS_DIRTY(p) (((p)->mp_flags & P_DIRTY) != 0)
|
||||
|
||||
#define PAGETYPE(p) ((p)->mp_flags & (P_BRANCH | P_LEAF | P_LEAF2 | P_OVERFLOW))
|
||||
|
||||
|
||||
11
src/defs.h
11
src/defs.h
@@ -103,10 +103,6 @@
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
|
||||
#if !defined(__thread) && (defined(_MSC_VER) || defined(__DMC__))
|
||||
# define __thread __declspec(thread)
|
||||
#endif /* __thread */
|
||||
|
||||
#ifndef __alwaysinline
|
||||
# if defined(__GNUC__) || __has_attribute(always_inline)
|
||||
# define __alwaysinline __inline __attribute__((always_inline))
|
||||
@@ -331,6 +327,13 @@
|
||||
# define mdbx_func_ "<mdbx_unknown>"
|
||||
#endif
|
||||
|
||||
#if defined(__GNUC__) || __has_attribute(format)
|
||||
#define __printf_args(format_index, first_arg) \
|
||||
__attribute__((format(printf, format_index, first_arg)))
|
||||
#else
|
||||
#define __printf_args(format_index, first_arg)
|
||||
#endif
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
|
||||
#if defined(USE_VALGRIND)
|
||||
|
||||
@@ -48,7 +48,7 @@ static __cold __attribute__((destructor)) void mdbx_global_destructor(void) {
|
||||
#endif
|
||||
#define LCK_WHOLE OFF_T_MAX
|
||||
|
||||
static int mdbx_lck_op(mdbx_filehandle_t fd, int op, int lck, off_t offset,
|
||||
static int mdbx_lck_op(mdbx_filehandle_t fd, int op, short lck, off_t offset,
|
||||
off_t len) {
|
||||
for (;;) {
|
||||
int rc;
|
||||
@@ -94,14 +94,17 @@ static __inline int mdbx_lck_shared(int lfd) {
|
||||
}
|
||||
|
||||
int mdbx_lck_downgrade(MDBX_env *env, bool complete) {
|
||||
assert(env->me_lfd != INVALID_HANDLE_VALUE);
|
||||
return complete ? mdbx_lck_shared(env->me_lfd) : MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
int mdbx_rpid_set(MDBX_env *env) {
|
||||
assert(env->me_lfd != INVALID_HANDLE_VALUE);
|
||||
return mdbx_lck_op(env->me_lfd, F_SETLK, F_WRLCK, env->me_pid, 1);
|
||||
}
|
||||
|
||||
int mdbx_rpid_clear(MDBX_env *env) {
|
||||
assert(env->me_lfd != INVALID_HANDLE_VALUE);
|
||||
return mdbx_lck_op(env->me_lfd, F_SETLKW, F_UNLCK, env->me_pid, 1);
|
||||
}
|
||||
|
||||
@@ -112,6 +115,7 @@ int mdbx_rpid_clear(MDBX_env *env) {
|
||||
* MDBX_RESULT_FALSE, if pid is dead (lock acquired)
|
||||
* or otherwise the errcode. */
|
||||
int mdbx_rpid_check(MDBX_env *env, mdbx_pid_t pid) {
|
||||
assert(env->me_lfd != INVALID_HANDLE_VALUE);
|
||||
int rc = mdbx_lck_op(env->me_lfd, F_GETLK, F_WRLCK, pid, 1);
|
||||
if (rc == 0)
|
||||
return MDBX_RESULT_FALSE;
|
||||
@@ -124,7 +128,7 @@ int mdbx_rpid_check(MDBX_env *env, mdbx_pid_t pid) {
|
||||
|
||||
static int mdbx_mutex_failed(MDBX_env *env, pthread_mutex_t *mutex, int rc);
|
||||
|
||||
int mdbx_lck_init(MDBX_env *env) {
|
||||
int __cold mdbx_lck_init(MDBX_env *env) {
|
||||
pthread_mutexattr_t ma;
|
||||
int rc = pthread_mutexattr_init(&ma);
|
||||
if (rc)
|
||||
@@ -152,6 +156,10 @@ int mdbx_lck_init(MDBX_env *env) {
|
||||
goto bailout;
|
||||
#endif /* PTHREAD_PRIO_INHERIT */
|
||||
|
||||
rc = pthread_mutexattr_settype(&ma, PTHREAD_MUTEX_ERRORCHECK);
|
||||
if (rc)
|
||||
goto bailout;
|
||||
|
||||
rc = pthread_mutex_init(&env->me_lck->mti_rmutex, &ma);
|
||||
if (rc)
|
||||
goto bailout;
|
||||
@@ -162,7 +170,7 @@ bailout:
|
||||
return rc;
|
||||
}
|
||||
|
||||
void mdbx_lck_destroy(MDBX_env *env) {
|
||||
void __cold mdbx_lck_destroy(MDBX_env *env) {
|
||||
if (env->me_lfd != INVALID_HANDLE_VALUE) {
|
||||
/* try get exclusive access */
|
||||
if (env->me_lck && mdbx_lck_exclusive(env->me_lfd, false) == 0) {
|
||||
@@ -172,7 +180,8 @@ void mdbx_lck_destroy(MDBX_env *env) {
|
||||
rc = pthread_mutex_destroy(&env->me_lck->mti_wmutex);
|
||||
assert(rc == 0);
|
||||
(void)rc;
|
||||
/* lock would be released (by kernel) while the me_lfd will be closed */
|
||||
/* file locks would be released (by kernel)
|
||||
* while the me_lfd will be closed */
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -215,21 +224,21 @@ void mdbx_rdt_unlock(MDBX_env *env) {
|
||||
|
||||
int mdbx_txn_lock(MDBX_env *env, bool dontwait) {
|
||||
mdbx_trace(">>");
|
||||
int rc = dontwait ? mdbx_robust_trylock(env, &env->me_lck->mti_wmutex)
|
||||
: mdbx_robust_lock(env, &env->me_lck->mti_wmutex);
|
||||
int rc = dontwait ? mdbx_robust_trylock(env, env->me_wmutex)
|
||||
: mdbx_robust_lock(env, env->me_wmutex);
|
||||
mdbx_trace("<< rc %d", rc);
|
||||
return MDBX_IS_ERROR(rc) ? rc : MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
void mdbx_txn_unlock(MDBX_env *env) {
|
||||
mdbx_trace(">>");
|
||||
int rc = mdbx_robust_unlock(env, &env->me_lck->mti_wmutex);
|
||||
int rc = mdbx_robust_unlock(env, env->me_wmutex);
|
||||
mdbx_trace("<< rc %d", rc);
|
||||
if (unlikely(MDBX_IS_ERROR(rc)))
|
||||
mdbx_panic("%s() failed: errcode %d\n", mdbx_func_, rc);
|
||||
}
|
||||
|
||||
static int internal_seize_lck(int lfd) {
|
||||
static int __cold internal_seize_lck(int lfd) {
|
||||
assert(lfd != INVALID_HANDLE_VALUE);
|
||||
|
||||
/* try exclusive access */
|
||||
@@ -255,17 +264,19 @@ static int internal_seize_lck(int lfd) {
|
||||
return rc;
|
||||
}
|
||||
|
||||
int mdbx_lck_seize(MDBX_env *env) {
|
||||
int __cold mdbx_lck_seize(MDBX_env *env) {
|
||||
assert(env->me_fd != INVALID_HANDLE_VALUE);
|
||||
|
||||
if (env->me_lfd == INVALID_HANDLE_VALUE) {
|
||||
/* LY: without-lck mode (e.g. on read-only filesystem) */
|
||||
int rc = mdbx_lck_op(env->me_fd, F_SETLK, F_RDLCK, 0, LCK_WHOLE);
|
||||
/* LY: without-lck mode (e.g. exclusive or on read-only filesystem) */
|
||||
int rc = mdbx_lck_op(env->me_fd, F_SETLK,
|
||||
(env->me_flags & MDBX_RDONLY) ? F_RDLCK : F_WRLCK, 0,
|
||||
LCK_WHOLE);
|
||||
if (rc != 0) {
|
||||
mdbx_error("%s(%s) failed: errcode %u", mdbx_func_, "without-lck", rc);
|
||||
return rc;
|
||||
}
|
||||
return MDBX_RESULT_FALSE;
|
||||
return MDBX_RESULT_TRUE;
|
||||
}
|
||||
|
||||
if ((env->me_flags & MDBX_RDONLY) == 0) {
|
||||
@@ -291,7 +302,7 @@ static int __cold mdbx_mutex_failed(MDBX_env *env, pthread_mutex_t *mutex,
|
||||
if (rc == EOWNERDEAD) {
|
||||
/* We own the mutex. Clean up after dead previous owner. */
|
||||
|
||||
int rlocked = (mutex == &env->me_lck->mti_rmutex);
|
||||
int rlocked = (env->me_lck && mutex == &env->me_lck->mti_rmutex);
|
||||
rc = MDBX_SUCCESS;
|
||||
if (!rlocked) {
|
||||
if (unlikely(env->me_txn)) {
|
||||
|
||||
@@ -24,13 +24,17 @@
|
||||
* LY
|
||||
*/
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
/* rthc */
|
||||
static void mdbx_winnt_import(void);
|
||||
|
||||
static void NTAPI tls_callback(PVOID module, DWORD reason, PVOID reserved) {
|
||||
#if !MDBX_CONFIG_MANUAL_TLS_CALLBACK
|
||||
static
|
||||
#endif /* !MDBX_CONFIG_MANUAL_TLS_CALLBACK */
|
||||
void NTAPI
|
||||
mdbx_dll_callback(PVOID module, DWORD reason, PVOID reserved) {
|
||||
(void)reserved;
|
||||
switch (reason) {
|
||||
case DLL_PROCESS_ATTACH:
|
||||
mdbx_winnt_import();
|
||||
mdbx_rthc_global_init();
|
||||
break;
|
||||
case DLL_PROCESS_DETACH:
|
||||
@@ -45,6 +49,7 @@ static void NTAPI tls_callback(PVOID module, DWORD reason, PVOID reserved) {
|
||||
}
|
||||
}
|
||||
|
||||
#if !MDBX_CONFIG_MANUAL_TLS_CALLBACK
|
||||
/* *INDENT-OFF* */
|
||||
/* clang-format off */
|
||||
#if defined(_MSC_VER)
|
||||
@@ -55,7 +60,7 @@ static void NTAPI tls_callback(PVOID module, DWORD reason, PVOID reserved) {
|
||||
/* kick a linker to create the TLS directory if not already done */
|
||||
# pragma comment(linker, "/INCLUDE:_tls_used")
|
||||
/* Force some symbol references. */
|
||||
# pragma comment(linker, "/INCLUDE:mdbx_tls_callback")
|
||||
# pragma comment(linker, "/INCLUDE:mdbx_tls_anchor")
|
||||
/* specific const-segment for WIN64 */
|
||||
# pragma const_seg(".CRT$XLB")
|
||||
const
|
||||
@@ -63,12 +68,12 @@ static void NTAPI tls_callback(PVOID module, DWORD reason, PVOID reserved) {
|
||||
/* kick a linker to create the TLS directory if not already done */
|
||||
# pragma comment(linker, "/INCLUDE:__tls_used")
|
||||
/* Force some symbol references. */
|
||||
# pragma comment(linker, "/INCLUDE:_mdbx_tls_callback")
|
||||
# pragma comment(linker, "/INCLUDE:_mdbx_tls_anchor")
|
||||
/* specific data-segment for WIN32 */
|
||||
# pragma data_seg(".CRT$XLB")
|
||||
# endif
|
||||
|
||||
PIMAGE_TLS_CALLBACK mdbx_tls_callback = tls_callback;
|
||||
__declspec(allocate(".CRT$XLB")) PIMAGE_TLS_CALLBACK mdbx_tls_anchor = mdbx_dll_callback;
|
||||
# pragma data_seg(pop)
|
||||
# pragma const_seg(pop)
|
||||
|
||||
@@ -76,13 +81,13 @@ static void NTAPI tls_callback(PVOID module, DWORD reason, PVOID reserved) {
|
||||
# ifdef _WIN64
|
||||
const
|
||||
# endif
|
||||
PIMAGE_TLS_CALLBACK mdbx_tls_callback __attribute__((section(".CRT$XLB"), used))
|
||||
= tls_callback;
|
||||
PIMAGE_TLS_CALLBACK mdbx_tls_anchor __attribute__((section(".CRT$XLB"), used)) = mdbx_dll_callback;
|
||||
#else
|
||||
# error FIXME
|
||||
#endif
|
||||
/* *INDENT-ON* */
|
||||
/* clang-format on */
|
||||
#endif /* !MDBX_CONFIG_MANUAL_TLS_CALLBACK */
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
|
||||
@@ -127,7 +132,8 @@ int mdbx_txn_lock(MDBX_env *env, bool dontwait) {
|
||||
EnterCriticalSection(&env->me_windowsbug_lock);
|
||||
}
|
||||
|
||||
if (flock(env->me_fd,
|
||||
if ((env->me_flags & MDBX_EXCLUSIVE) ||
|
||||
flock(env->me_fd,
|
||||
dontwait ? (LCK_EXCLUSIVE | LCK_DONTWAIT)
|
||||
: (LCK_EXCLUSIVE | LCK_WAITFOR),
|
||||
LCK_BODY))
|
||||
@@ -138,7 +144,8 @@ int mdbx_txn_lock(MDBX_env *env, bool dontwait) {
|
||||
}
|
||||
|
||||
void mdbx_txn_unlock(MDBX_env *env) {
|
||||
int rc = funlock(env->me_fd, LCK_BODY);
|
||||
int rc =
|
||||
(env->me_flags & MDBX_EXCLUSIVE) ? TRUE : funlock(env->me_fd, LCK_BODY);
|
||||
LeaveCriticalSection(&env->me_windowsbug_lock);
|
||||
if (!rc)
|
||||
mdbx_panic("%s failed: errcode %u", mdbx_func_, GetLastError());
|
||||
@@ -156,26 +163,28 @@ void mdbx_txn_unlock(MDBX_env *env) {
|
||||
#define LCK_UPPER LCK_UP_OFFSET, LCK_UP_LEN
|
||||
|
||||
int mdbx_rdt_lock(MDBX_env *env) {
|
||||
AcquireSRWLockShared(&env->me_remap_guard);
|
||||
mdbx_srwlock_AcquireShared(&env->me_remap_guard);
|
||||
if (env->me_lfd == INVALID_HANDLE_VALUE)
|
||||
return MDBX_SUCCESS; /* readonly database in readonly filesystem */
|
||||
|
||||
/* transite from S-? (used) to S-E (locked), e.g. exclusive lock upper-part */
|
||||
if (flock(env->me_lfd, LCK_EXCLUSIVE | LCK_WAITFOR, LCK_UPPER))
|
||||
if ((env->me_flags & MDBX_EXCLUSIVE) ||
|
||||
flock(env->me_lfd, LCK_EXCLUSIVE | LCK_WAITFOR, LCK_UPPER))
|
||||
return MDBX_SUCCESS;
|
||||
|
||||
int rc = GetLastError();
|
||||
ReleaseSRWLockShared(&env->me_remap_guard);
|
||||
mdbx_srwlock_ReleaseShared(&env->me_remap_guard);
|
||||
return rc;
|
||||
}
|
||||
|
||||
void mdbx_rdt_unlock(MDBX_env *env) {
|
||||
if (env->me_lfd != INVALID_HANDLE_VALUE) {
|
||||
/* transite from S-E (locked) to S-? (used), e.g. unlock upper-part */
|
||||
if (!funlock(env->me_lfd, LCK_UPPER))
|
||||
if ((env->me_flags & MDBX_EXCLUSIVE) == 0 &&
|
||||
!funlock(env->me_lfd, LCK_UPPER))
|
||||
mdbx_panic("%s failed: errcode %u", mdbx_func_, GetLastError());
|
||||
}
|
||||
ReleaseSRWLockShared(&env->me_remap_guard);
|
||||
mdbx_srwlock_ReleaseShared(&env->me_remap_guard);
|
||||
}
|
||||
|
||||
static int suspend_and_append(mdbx_handle_array_t **array,
|
||||
@@ -246,7 +255,8 @@ int mdbx_suspend_threads_before_remap(MDBX_env *env,
|
||||
} else {
|
||||
/* Without LCK (i.e. read-only mode).
|
||||
* Walk thougth a snapshot of all running threads */
|
||||
mdbx_assert(env, env->me_txn0 == NULL);
|
||||
mdbx_assert(env,
|
||||
env->me_txn0 == NULL || (env->me_flags & MDBX_EXCLUSIVE) != 0);
|
||||
const HANDLE hSnapshot = CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, 0);
|
||||
if (hSnapshot == INVALID_HANDLE_VALUE)
|
||||
return GetLastError();
|
||||
@@ -369,6 +379,9 @@ int mdbx_lck_seize(MDBX_env *env) {
|
||||
int rc;
|
||||
|
||||
assert(env->me_fd != INVALID_HANDLE_VALUE);
|
||||
if (env->me_flags & MDBX_EXCLUSIVE)
|
||||
return MDBX_RESULT_TRUE /* files were must be opened non-shareable */;
|
||||
|
||||
if (env->me_lfd == INVALID_HANDLE_VALUE) {
|
||||
/* LY: without-lck mode (e.g. on read-only filesystem) */
|
||||
mdbx_jitter4testing(false);
|
||||
@@ -411,6 +424,9 @@ int mdbx_lck_downgrade(MDBX_env *env, bool complete) {
|
||||
assert(env->me_fd != INVALID_HANDLE_VALUE);
|
||||
assert(env->me_lfd != INVALID_HANDLE_VALUE);
|
||||
|
||||
if (env->me_flags & MDBX_EXCLUSIVE)
|
||||
return MDBX_SUCCESS /* files were must be opened non-shareable */;
|
||||
|
||||
/* 1) must be at E-E (exclusive-write) */
|
||||
if (!complete) {
|
||||
/* transite from E-E to E_? (exclusive-read) */
|
||||
@@ -534,3 +550,122 @@ int mdbx_rpid_check(MDBX_env *env, mdbx_pid_t pid) {
|
||||
return rc;
|
||||
}
|
||||
}
|
||||
|
||||
//----------------------------------------------------------------------------
|
||||
// Stub for slim read-write lock
|
||||
// Copyright (C) 1995-2002 Brad Wilson
|
||||
|
||||
static void WINAPI stub_srwlock_Init(MDBX_srwlock *srwl) {
|
||||
srwl->readerCount = srwl->writerCount = 0;
|
||||
}
|
||||
|
||||
static void WINAPI stub_srwlock_AcquireShared(MDBX_srwlock *srwl) {
|
||||
while (true) {
|
||||
assert(srwl->writerCount >= 0 && srwl->readerCount >= 0);
|
||||
|
||||
// If there's a writer already, spin without unnecessarily
|
||||
// interlocking the CPUs
|
||||
if (srwl->writerCount != 0) {
|
||||
YieldProcessor();
|
||||
continue;
|
||||
}
|
||||
|
||||
// Add to the readers list
|
||||
_InterlockedIncrement(&srwl->readerCount);
|
||||
|
||||
// Check for writers again (we may have been pre-empted). If
|
||||
// there are no writers writing or waiting, then we're done.
|
||||
if (srwl->writerCount == 0)
|
||||
break;
|
||||
|
||||
// Remove from the readers list, spin, try again
|
||||
_InterlockedDecrement(&srwl->readerCount);
|
||||
YieldProcessor();
|
||||
}
|
||||
}
|
||||
|
||||
static void WINAPI stub_srwlock_ReleaseShared(MDBX_srwlock *srwl) {
|
||||
assert(srwl->readerCount > 0);
|
||||
_InterlockedDecrement(&srwl->readerCount);
|
||||
}
|
||||
|
||||
static void WINAPI stub_srwlock_AcquireExclusive(MDBX_srwlock *srwl) {
|
||||
while (true) {
|
||||
assert(srwl->writerCount >= 0 && srwl->readerCount >= 0);
|
||||
|
||||
// If there's a writer already, spin without unnecessarily
|
||||
// interlocking the CPUs
|
||||
if (srwl->writerCount != 0) {
|
||||
YieldProcessor();
|
||||
continue;
|
||||
}
|
||||
|
||||
// See if we can become the writer (expensive, because it inter-
|
||||
// locks the CPUs, so writing should be an infrequent process)
|
||||
if (_InterlockedExchange(&srwl->writerCount, 1) == 0)
|
||||
break;
|
||||
}
|
||||
|
||||
// Now we're the writer, but there may be outstanding readers.
|
||||
// Spin until there aren't any more; new readers will wait now
|
||||
// that we're the writer.
|
||||
while (srwl->readerCount != 0) {
|
||||
assert(srwl->writerCount >= 0 && srwl->readerCount >= 0);
|
||||
YieldProcessor();
|
||||
}
|
||||
}
|
||||
|
||||
static void WINAPI stub_srwlock_ReleaseExclusive(MDBX_srwlock *srwl) {
|
||||
assert(srwl->writerCount == 1 && srwl->readerCount >= 0);
|
||||
srwl->writerCount = 0;
|
||||
}
|
||||
|
||||
MDBX_srwlock_function mdbx_srwlock_Init, mdbx_srwlock_AcquireShared,
|
||||
mdbx_srwlock_ReleaseShared, mdbx_srwlock_AcquireExclusive,
|
||||
mdbx_srwlock_ReleaseExclusive;
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
|
||||
MDBX_GetFileInformationByHandleEx mdbx_GetFileInformationByHandleEx;
|
||||
MDBX_GetVolumeInformationByHandleW mdbx_GetVolumeInformationByHandleW;
|
||||
MDBX_GetFinalPathNameByHandleW mdbx_GetFinalPathNameByHandleW;
|
||||
MDBX_NtFsControlFile mdbx_NtFsControlFile;
|
||||
|
||||
static void mdbx_winnt_import(void) {
|
||||
const HINSTANCE hKernel32dll = GetModuleHandleA("kernel32.dll");
|
||||
const MDBX_srwlock_function init =
|
||||
(MDBX_srwlock_function)GetProcAddress(hKernel32dll, "InitializeSRWLock");
|
||||
if (init != NULL) {
|
||||
mdbx_srwlock_Init = init;
|
||||
mdbx_srwlock_AcquireShared = (MDBX_srwlock_function)GetProcAddress(
|
||||
hKernel32dll, "AcquireSRWLockShared");
|
||||
mdbx_srwlock_ReleaseShared = (MDBX_srwlock_function)GetProcAddress(
|
||||
hKernel32dll, "ReleaseSRWLockShared");
|
||||
mdbx_srwlock_AcquireExclusive = (MDBX_srwlock_function)GetProcAddress(
|
||||
hKernel32dll, "AcquireSRWLockExclusive");
|
||||
mdbx_srwlock_ReleaseExclusive = (MDBX_srwlock_function)GetProcAddress(
|
||||
hKernel32dll, "ReleaseSRWLockExclusive");
|
||||
} else {
|
||||
mdbx_srwlock_Init = stub_srwlock_Init;
|
||||
mdbx_srwlock_AcquireShared = stub_srwlock_AcquireShared;
|
||||
mdbx_srwlock_ReleaseShared = stub_srwlock_ReleaseShared;
|
||||
mdbx_srwlock_AcquireExclusive = stub_srwlock_AcquireExclusive;
|
||||
mdbx_srwlock_ReleaseExclusive = stub_srwlock_ReleaseExclusive;
|
||||
}
|
||||
|
||||
mdbx_GetFileInformationByHandleEx =
|
||||
(MDBX_GetFileInformationByHandleEx)GetProcAddress(
|
||||
hKernel32dll, "GetFileInformationByHandleEx");
|
||||
|
||||
mdbx_GetVolumeInformationByHandleW =
|
||||
(MDBX_GetVolumeInformationByHandleW)GetProcAddress(
|
||||
hKernel32dll, "GetVolumeInformationByHandleW");
|
||||
|
||||
mdbx_GetFinalPathNameByHandleW =
|
||||
(MDBX_GetFinalPathNameByHandleW)GetProcAddress(
|
||||
hKernel32dll, "GetFinalPathNameByHandleW");
|
||||
|
||||
const HINSTANCE hNtdll = GetModuleHandleA("ntdll.dll");
|
||||
mdbx_NtFsControlFile =
|
||||
(MDBX_NtFsControlFile)GetProcAddress(hNtdll, "NtFsControlFile");
|
||||
}
|
||||
|
||||
3644
src/mdbx.c
3644
src/mdbx.c
File diff suppressed because it is too large
Load Diff
228
src/osal.c
228
src/osal.c
@@ -17,7 +17,6 @@
|
||||
#include "./bits.h"
|
||||
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
#include <winternl.h>
|
||||
|
||||
static int waitstatus2errcode(DWORD result) {
|
||||
switch (result) {
|
||||
@@ -105,13 +104,31 @@ extern NTSTATUS NTAPI NtFreeVirtualMemory(IN HANDLE ProcessHandle,
|
||||
IN OUT PSIZE_T RegionSize,
|
||||
IN ULONG FreeType);
|
||||
|
||||
#ifndef WOF_CURRENT_VERSION
|
||||
typedef struct _WOF_EXTERNAL_INFO {
|
||||
DWORD Version;
|
||||
DWORD Provider;
|
||||
} WOF_EXTERNAL_INFO, *PWOF_EXTERNAL_INFO;
|
||||
#endif /* WOF_CURRENT_VERSION */
|
||||
|
||||
#ifndef WIM_PROVIDER_CURRENT_VERSION
|
||||
#define WIM_PROVIDER_HASH_SIZE 20
|
||||
|
||||
typedef struct _WIM_PROVIDER_EXTERNAL_INFO {
|
||||
DWORD Version;
|
||||
DWORD Flags;
|
||||
LARGE_INTEGER DataSourceId;
|
||||
BYTE ResourceHash[WIM_PROVIDER_HASH_SIZE];
|
||||
} WIM_PROVIDER_EXTERNAL_INFO, *PWIM_PROVIDER_EXTERNAL_INFO;
|
||||
#endif /* WIM_PROVIDER_CURRENT_VERSION */
|
||||
|
||||
#ifndef FILE_PROVIDER_CURRENT_VERSION
|
||||
typedef struct _FILE_PROVIDER_EXTERNAL_INFO_V1 {
|
||||
ULONG Version;
|
||||
ULONG Algorithm;
|
||||
ULONG Flags;
|
||||
} FILE_PROVIDER_EXTERNAL_INFO_V1, *PFILE_PROVIDER_EXTERNAL_INFO_V1;
|
||||
#endif
|
||||
#endif /* FILE_PROVIDER_CURRENT_VERSION */
|
||||
|
||||
#ifndef STATUS_OBJECT_NOT_EXTERNALLY_BACKED
|
||||
#define STATUS_OBJECT_NOT_EXTERNALLY_BACKED ((NTSTATUS)0xC000046DL)
|
||||
@@ -120,14 +137,6 @@ typedef struct _FILE_PROVIDER_EXTERNAL_INFO_V1 {
|
||||
#define STATUS_INVALID_DEVICE_REQUEST ((NTSTATUS)0xC0000010L)
|
||||
#endif
|
||||
|
||||
extern NTSTATUS
|
||||
NtFsControlFile(IN HANDLE FileHandle, IN OUT HANDLE Event,
|
||||
IN OUT PVOID /* PIO_APC_ROUTINE */ ApcRoutine,
|
||||
IN OUT PVOID ApcContext, OUT PIO_STATUS_BLOCK IoStatusBlock,
|
||||
IN ULONG FsControlCode, IN OUT PVOID InputBuffer,
|
||||
IN ULONG InputBufferLength, OUT OPTIONAL PVOID OutputBuffer,
|
||||
IN ULONG OutputBufferLength);
|
||||
|
||||
#endif /* _WIN32 || _WIN64 */
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
@@ -399,20 +408,28 @@ int mdbx_fastmutex_release(mdbx_fastmutex_t *fastmutex) {
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
|
||||
int mdbx_removefile(const char *pathname) {
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
return DeleteFileA(pathname) ? MDBX_SUCCESS : GetLastError();
|
||||
#else
|
||||
return unlink(pathname) ? errno : MDBX_SUCCESS;
|
||||
#endif
|
||||
}
|
||||
int mdbx_openfile(const char *pathname, int flags, mode_t mode,
|
||||
mdbx_filehandle_t *fd) {
|
||||
mdbx_filehandle_t *fd, bool exclusive) {
|
||||
*fd = INVALID_HANDLE_VALUE;
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
(void)mode;
|
||||
|
||||
DWORD DesiredAccess;
|
||||
DWORD ShareMode = FILE_SHARE_READ | FILE_SHARE_WRITE;
|
||||
DWORD DesiredAccess, ShareMode;
|
||||
DWORD FlagsAndAttributes = FILE_ATTRIBUTE_NORMAL;
|
||||
switch (flags & (O_RDONLY | O_WRONLY | O_RDWR)) {
|
||||
default:
|
||||
return ERROR_INVALID_PARAMETER;
|
||||
case O_RDONLY:
|
||||
DesiredAccess = GENERIC_READ;
|
||||
ShareMode =
|
||||
exclusive ? FILE_SHARE_READ : (FILE_SHARE_READ | FILE_SHARE_WRITE);
|
||||
break;
|
||||
case O_WRONLY: /* assume for MDBX_env_copy() and friends output */
|
||||
DesiredAccess = GENERIC_WRITE;
|
||||
@@ -421,6 +438,7 @@ int mdbx_openfile(const char *pathname, int flags, mode_t mode,
|
||||
break;
|
||||
case O_RDWR:
|
||||
DesiredAccess = GENERIC_READ | GENERIC_WRITE;
|
||||
ShareMode = exclusive ? 0 : (FILE_SHARE_READ | FILE_SHARE_WRITE);
|
||||
break;
|
||||
}
|
||||
|
||||
@@ -459,7 +477,7 @@ int mdbx_openfile(const char *pathname, int flags, mode_t mode,
|
||||
}
|
||||
}
|
||||
#else
|
||||
|
||||
(void)exclusive;
|
||||
#ifdef O_CLOEXEC
|
||||
flags |= O_CLOEXEC;
|
||||
#endif
|
||||
@@ -735,92 +753,118 @@ int mdbx_msync(mdbx_mmap_t *map, size_t offset, size_t length, int async) {
|
||||
#endif
|
||||
}
|
||||
|
||||
int mdbx_check4nonlocal(mdbx_filehandle_t handle, int flags) {
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
if (GetFileType(handle) != FILE_TYPE_DISK)
|
||||
return ERROR_FILE_OFFLINE;
|
||||
|
||||
if (mdbx_GetFileInformationByHandleEx) {
|
||||
FILE_REMOTE_PROTOCOL_INFO RemoteProtocolInfo;
|
||||
if (mdbx_GetFileInformationByHandleEx(handle, FileRemoteProtocolInfo,
|
||||
&RemoteProtocolInfo,
|
||||
sizeof(RemoteProtocolInfo))) {
|
||||
|
||||
if ((RemoteProtocolInfo.Flags & REMOTE_PROTOCOL_INFO_FLAG_OFFLINE) &&
|
||||
!(flags & MDBX_RDONLY))
|
||||
return ERROR_FILE_OFFLINE;
|
||||
if (!(RemoteProtocolInfo.Flags & REMOTE_PROTOCOL_INFO_FLAG_LOOPBACK) &&
|
||||
!(flags & MDBX_EXCLUSIVE))
|
||||
return ERROR_REMOTE_STORAGE_MEDIA_ERROR;
|
||||
}
|
||||
}
|
||||
|
||||
if (mdbx_NtFsControlFile) {
|
||||
NTSTATUS rc;
|
||||
struct {
|
||||
WOF_EXTERNAL_INFO wof_info;
|
||||
union {
|
||||
WIM_PROVIDER_EXTERNAL_INFO wim_info;
|
||||
FILE_PROVIDER_EXTERNAL_INFO_V1 file_info;
|
||||
};
|
||||
size_t reserved_for_microsoft_madness[42];
|
||||
} GetExternalBacking_OutputBuffer;
|
||||
IO_STATUS_BLOCK StatusBlock;
|
||||
rc = mdbx_NtFsControlFile(handle, NULL, NULL, NULL, &StatusBlock,
|
||||
FSCTL_GET_EXTERNAL_BACKING, NULL, 0,
|
||||
&GetExternalBacking_OutputBuffer,
|
||||
sizeof(GetExternalBacking_OutputBuffer));
|
||||
if (NT_SUCCESS(rc)) {
|
||||
if (!(flags & MDBX_EXCLUSIVE))
|
||||
return ERROR_REMOTE_STORAGE_MEDIA_ERROR;
|
||||
} else if (rc != STATUS_OBJECT_NOT_EXTERNALLY_BACKED &&
|
||||
rc != STATUS_INVALID_DEVICE_REQUEST)
|
||||
return ntstatus2errcode(rc);
|
||||
}
|
||||
|
||||
if (mdbx_GetVolumeInformationByHandleW && mdbx_GetFinalPathNameByHandleW) {
|
||||
WCHAR PathBuffer[INT16_MAX];
|
||||
DWORD VolumeSerialNumber, FileSystemFlags;
|
||||
if (!mdbx_GetVolumeInformationByHandleW(handle, PathBuffer, INT16_MAX,
|
||||
&VolumeSerialNumber, NULL,
|
||||
&FileSystemFlags, NULL, 0))
|
||||
return GetLastError();
|
||||
|
||||
if ((flags & MDBX_RDONLY) == 0) {
|
||||
if (FileSystemFlags & (FILE_SEQUENTIAL_WRITE_ONCE |
|
||||
FILE_READ_ONLY_VOLUME | FILE_VOLUME_IS_COMPRESSED))
|
||||
return ERROR_REMOTE_STORAGE_MEDIA_ERROR;
|
||||
}
|
||||
|
||||
if (!mdbx_GetFinalPathNameByHandleW(handle, PathBuffer, INT16_MAX,
|
||||
FILE_NAME_NORMALIZED | VOLUME_NAME_NT))
|
||||
return GetLastError();
|
||||
|
||||
if (_wcsnicmp(PathBuffer, L"\\Device\\Mup\\", 12) == 0) {
|
||||
if (!(flags & MDBX_EXCLUSIVE))
|
||||
return ERROR_REMOTE_STORAGE_MEDIA_ERROR;
|
||||
} else if (mdbx_GetFinalPathNameByHandleW(handle, PathBuffer, INT16_MAX,
|
||||
FILE_NAME_NORMALIZED |
|
||||
VOLUME_NAME_DOS)) {
|
||||
UINT DriveType = GetDriveTypeW(PathBuffer);
|
||||
if (DriveType == DRIVE_NO_ROOT_DIR &&
|
||||
wcsncmp(PathBuffer, L"\\\\?\\", 4) == 0 &&
|
||||
wcsncmp(PathBuffer + 5, L":\\", 2) == 0) {
|
||||
PathBuffer[7] = 0;
|
||||
DriveType = GetDriveTypeW(PathBuffer + 4);
|
||||
}
|
||||
switch (DriveType) {
|
||||
case DRIVE_CDROM:
|
||||
if (flags & MDBX_RDONLY)
|
||||
break;
|
||||
// fall through
|
||||
case DRIVE_UNKNOWN:
|
||||
case DRIVE_NO_ROOT_DIR:
|
||||
case DRIVE_REMOTE:
|
||||
default:
|
||||
if (!(flags & MDBX_EXCLUSIVE))
|
||||
return ERROR_REMOTE_STORAGE_MEDIA_ERROR;
|
||||
// fall through
|
||||
case DRIVE_REMOVABLE:
|
||||
case DRIVE_FIXED:
|
||||
case DRIVE_RAMDISK:
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
#else
|
||||
(void)handle;
|
||||
/* TODO: check for NFS handle ? */
|
||||
(void)flags;
|
||||
#endif
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
int mdbx_mmap(int flags, mdbx_mmap_t *map, size_t size, size_t limit) {
|
||||
assert(size <= limit);
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
NTSTATUS rc;
|
||||
map->length = 0;
|
||||
map->current = 0;
|
||||
map->section = NULL;
|
||||
map->address = nullptr;
|
||||
|
||||
if (GetFileType(map->fd) != FILE_TYPE_DISK)
|
||||
return ERROR_FILE_OFFLINE;
|
||||
|
||||
FILE_REMOTE_PROTOCOL_INFO RemoteProtocolInfo;
|
||||
if (GetFileInformationByHandleEx(map->fd, FileRemoteProtocolInfo,
|
||||
&RemoteProtocolInfo,
|
||||
sizeof(RemoteProtocolInfo))) {
|
||||
if ((RemoteProtocolInfo.Flags & (REMOTE_PROTOCOL_INFO_FLAG_LOOPBACK |
|
||||
REMOTE_PROTOCOL_INFO_FLAG_OFFLINE)) !=
|
||||
REMOTE_PROTOCOL_INFO_FLAG_LOOPBACK)
|
||||
return ERROR_FILE_OFFLINE;
|
||||
}
|
||||
|
||||
#if defined(_WIN64) && defined(WOF_CURRENT_VERSION)
|
||||
struct {
|
||||
WOF_EXTERNAL_INFO wof_info;
|
||||
union {
|
||||
WIM_PROVIDER_EXTERNAL_INFO wim_info;
|
||||
FILE_PROVIDER_EXTERNAL_INFO_V1 file_info;
|
||||
};
|
||||
size_t reserved_for_microsoft_madness[42];
|
||||
} GetExternalBacking_OutputBuffer;
|
||||
IO_STATUS_BLOCK StatusBlock;
|
||||
rc = NtFsControlFile(map->fd, NULL, NULL, NULL, &StatusBlock,
|
||||
FSCTL_GET_EXTERNAL_BACKING, NULL, 0,
|
||||
&GetExternalBacking_OutputBuffer,
|
||||
sizeof(GetExternalBacking_OutputBuffer));
|
||||
if (rc != STATUS_OBJECT_NOT_EXTERNALLY_BACKED &&
|
||||
rc != STATUS_INVALID_DEVICE_REQUEST)
|
||||
return NT_SUCCESS(rc) ? ERROR_FILE_OFFLINE : ntstatus2errcode(rc);
|
||||
#endif
|
||||
|
||||
WCHAR PathBuffer[INT16_MAX];
|
||||
DWORD VolumeSerialNumber, FileSystemFlags;
|
||||
if (!GetVolumeInformationByHandleW(map->fd, PathBuffer, INT16_MAX,
|
||||
&VolumeSerialNumber, NULL,
|
||||
&FileSystemFlags, NULL, 0))
|
||||
return GetLastError();
|
||||
|
||||
if ((flags & MDBX_RDONLY) == 0) {
|
||||
if (FileSystemFlags & (FILE_SEQUENTIAL_WRITE_ONCE | FILE_READ_ONLY_VOLUME |
|
||||
FILE_VOLUME_IS_COMPRESSED))
|
||||
return ERROR_FILE_OFFLINE;
|
||||
}
|
||||
|
||||
if (!GetFinalPathNameByHandleW(map->fd, PathBuffer, INT16_MAX,
|
||||
FILE_NAME_NORMALIZED | VOLUME_NAME_NT))
|
||||
return GetLastError();
|
||||
|
||||
if (_wcsnicmp(PathBuffer, L"\\Device\\Mup\\", 12) == 0)
|
||||
return ERROR_FILE_OFFLINE;
|
||||
|
||||
if (GetFinalPathNameByHandleW(map->fd, PathBuffer, INT16_MAX,
|
||||
FILE_NAME_NORMALIZED | VOLUME_NAME_DOS)) {
|
||||
UINT DriveType = GetDriveTypeW(PathBuffer);
|
||||
if (DriveType == DRIVE_NO_ROOT_DIR &&
|
||||
wcsncmp(PathBuffer, L"\\\\?\\", 4) == 0 &&
|
||||
wcsncmp(PathBuffer + 5, L":\\", 2) == 0) {
|
||||
PathBuffer[7] = 0;
|
||||
DriveType = GetDriveTypeW(PathBuffer + 4);
|
||||
}
|
||||
switch (DriveType) {
|
||||
case DRIVE_CDROM:
|
||||
if (flags & MDBX_RDONLY)
|
||||
break;
|
||||
// fall through
|
||||
case DRIVE_UNKNOWN:
|
||||
case DRIVE_NO_ROOT_DIR:
|
||||
case DRIVE_REMOTE:
|
||||
default:
|
||||
return ERROR_FILE_OFFLINE;
|
||||
case DRIVE_REMOVABLE:
|
||||
case DRIVE_FIXED:
|
||||
case DRIVE_RAMDISK:
|
||||
break;
|
||||
}
|
||||
}
|
||||
NTSTATUS rc = mdbx_check4nonlocal(map->fd, flags);
|
||||
if (rc != MDBX_SUCCESS)
|
||||
return rc;
|
||||
|
||||
rc = mdbx_filesize(map->fd, &map->filesize);
|
||||
if (rc != MDBX_SUCCESS)
|
||||
|
||||
53
src/osal.h
53
src/osal.h
@@ -65,9 +65,11 @@
|
||||
/* Systems includes */
|
||||
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
#define WIN32_LEAN_AND_MEAN
|
||||
#include <tlhelp32.h>
|
||||
#include <windows.h>
|
||||
#include <winnt.h>
|
||||
#include <winternl.h>
|
||||
#define HAVE_SYS_STAT_H
|
||||
#define HAVE_SYS_TYPES_H
|
||||
typedef HANDLE mdbx_thread_t;
|
||||
@@ -475,8 +477,9 @@ int mdbx_filesize_sync(mdbx_filehandle_t fd);
|
||||
int mdbx_ftruncate(mdbx_filehandle_t fd, uint64_t length);
|
||||
int mdbx_filesize(mdbx_filehandle_t fd, uint64_t *length);
|
||||
int mdbx_openfile(const char *pathname, int flags, mode_t mode,
|
||||
mdbx_filehandle_t *fd);
|
||||
mdbx_filehandle_t *fd, bool exclusive);
|
||||
int mdbx_closefile(mdbx_filehandle_t fd);
|
||||
int mdbx_removefile(const char *pathname);
|
||||
|
||||
typedef struct mdbx_mmap_param {
|
||||
union {
|
||||
@@ -508,6 +511,7 @@ int mdbx_suspend_threads_before_remap(MDBX_env *env,
|
||||
int mdbx_resume_threads_after_remap(mdbx_handle_array_t *array);
|
||||
#endif /* Windows */
|
||||
int mdbx_msync(mdbx_mmap_t *map, size_t offset, size_t length, int async);
|
||||
int mdbx_check4nonlocal(mdbx_filehandle_t handle, int flags);
|
||||
|
||||
static __inline mdbx_pid_t mdbx_getpid(void) {
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
@@ -559,6 +563,53 @@ LIBMDBX_API void mdbx_txn_unlock(MDBX_env *env);
|
||||
int mdbx_rpid_set(MDBX_env *env);
|
||||
int mdbx_rpid_clear(MDBX_env *env);
|
||||
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
typedef struct MDBX_srwlock {
|
||||
union {
|
||||
struct {
|
||||
long volatile readerCount;
|
||||
long volatile writerCount;
|
||||
};
|
||||
RTL_SRWLOCK native;
|
||||
};
|
||||
} MDBX_srwlock;
|
||||
|
||||
typedef void(WINAPI *MDBX_srwlock_function)(MDBX_srwlock *);
|
||||
extern MDBX_srwlock_function mdbx_srwlock_Init, mdbx_srwlock_AcquireShared,
|
||||
mdbx_srwlock_ReleaseShared, mdbx_srwlock_AcquireExclusive,
|
||||
mdbx_srwlock_ReleaseExclusive;
|
||||
|
||||
typedef BOOL(WINAPI *MDBX_GetFileInformationByHandleEx)(
|
||||
_In_ HANDLE hFile, _In_ FILE_INFO_BY_HANDLE_CLASS FileInformationClass,
|
||||
_Out_ LPVOID lpFileInformation, _In_ DWORD dwBufferSize);
|
||||
extern MDBX_GetFileInformationByHandleEx mdbx_GetFileInformationByHandleEx;
|
||||
|
||||
typedef BOOL(WINAPI *MDBX_GetVolumeInformationByHandleW)(
|
||||
_In_ HANDLE hFile, _Out_opt_ LPWSTR lpVolumeNameBuffer,
|
||||
_In_ DWORD nVolumeNameSize, _Out_opt_ LPDWORD lpVolumeSerialNumber,
|
||||
_Out_opt_ LPDWORD lpMaximumComponentLength,
|
||||
_Out_opt_ LPDWORD lpFileSystemFlags,
|
||||
_Out_opt_ LPWSTR lpFileSystemNameBuffer, _In_ DWORD nFileSystemNameSize);
|
||||
|
||||
extern MDBX_GetVolumeInformationByHandleW mdbx_GetVolumeInformationByHandleW;
|
||||
|
||||
typedef DWORD(WINAPI *MDBX_GetFinalPathNameByHandleW)(_In_ HANDLE hFile,
|
||||
_Out_ LPWSTR lpszFilePath,
|
||||
_In_ DWORD cchFilePath,
|
||||
_In_ DWORD dwFlags);
|
||||
extern MDBX_GetFinalPathNameByHandleW mdbx_GetFinalPathNameByHandleW;
|
||||
|
||||
typedef NTSTATUS(NTAPI *MDBX_NtFsControlFile)(
|
||||
IN HANDLE FileHandle, IN OUT HANDLE Event,
|
||||
IN OUT PVOID /* PIO_APC_ROUTINE */ ApcRoutine, IN OUT PVOID ApcContext,
|
||||
OUT PIO_STATUS_BLOCK IoStatusBlock, IN ULONG FsControlCode,
|
||||
IN OUT PVOID InputBuffer, IN ULONG InputBufferLength,
|
||||
OUT OPTIONAL PVOID OutputBuffer, IN ULONG OutputBufferLength);
|
||||
|
||||
extern MDBX_NtFsControlFile mdbx_NtFsControlFile;
|
||||
|
||||
#endif /* Windows */
|
||||
|
||||
/* Checks reader by pid.
|
||||
*
|
||||
* Returns:
|
||||
|
||||
@@ -64,8 +64,9 @@ static void signal_handler(int sig) {
|
||||
typedef struct {
|
||||
const char *name;
|
||||
struct {
|
||||
uint64_t total;
|
||||
uint64_t empty;
|
||||
uint64_t branch, large_count, large_volume, leaf;
|
||||
uint64_t subleaf_dupsort, leaf_dupfixed, subleaf_dupfixed;
|
||||
uint64_t total, empty, other;
|
||||
} pages;
|
||||
uint64_t payload_bytes;
|
||||
uint64_t lost_bytes;
|
||||
@@ -78,16 +79,19 @@ struct {
|
||||
uint64_t pgcount;
|
||||
} walk;
|
||||
|
||||
#define dbi_free walk.dbi[FREE_DBI]
|
||||
#define dbi_main walk.dbi[MAIN_DBI]
|
||||
#define dbi_meta walk.dbi[CORE_DBS]
|
||||
|
||||
uint64_t total_unused_bytes;
|
||||
int exclusive = 2;
|
||||
int envflags = MDBX_RDONLY;
|
||||
int envflags = MDBX_RDONLY | MDBX_EXCLUSIVE;
|
||||
|
||||
MDBX_env *env;
|
||||
MDBX_txn *txn;
|
||||
MDBX_envinfo envinfo;
|
||||
MDBX_stat envstat;
|
||||
size_t maxkeysize, userdb_count, skipped_subdb;
|
||||
uint64_t reclaimable_pages, freedb_pages, lastpgno;
|
||||
uint64_t reclaimable_pages, gc_pages, lastpgno, unused_pages;
|
||||
unsigned verbose, quiet;
|
||||
const char *only_subdb;
|
||||
|
||||
@@ -127,6 +131,7 @@ static void
|
||||
|
||||
fflush(stdout);
|
||||
va_start(args, msg);
|
||||
fputs(" ! ", stderr);
|
||||
vfprintf(stderr, msg, args);
|
||||
va_end(args);
|
||||
fflush(NULL);
|
||||
@@ -134,9 +139,7 @@ static void
|
||||
}
|
||||
|
||||
static void pagemap_cleanup(void) {
|
||||
int i;
|
||||
|
||||
for (i = 1; i < MAX_DBI; ++i) {
|
||||
for (int i = CORE_DBS; ++i < MAX_DBI;) {
|
||||
if (walk.dbi[i].name) {
|
||||
free((void *)walk.dbi[i].name);
|
||||
walk.dbi[i].name = NULL;
|
||||
@@ -147,22 +150,22 @@ static void pagemap_cleanup(void) {
|
||||
walk.pagemap = NULL;
|
||||
}
|
||||
|
||||
static walk_dbi_t *pagemap_lookup_dbi(const char *dbi_name) {
|
||||
static walk_dbi_t *pagemap_lookup_dbi(const char *dbi_name, bool silent) {
|
||||
static walk_dbi_t *last;
|
||||
|
||||
if (last && strcmp(last->name, dbi_name) == 0)
|
||||
return last;
|
||||
|
||||
walk_dbi_t *dbi = walk.dbi + 1;
|
||||
while (dbi->name) {
|
||||
walk_dbi_t *dbi = walk.dbi + CORE_DBS;
|
||||
for (dbi = walk.dbi + CORE_DBS; (++dbi)->name;) {
|
||||
if (strcmp(dbi->name, dbi_name) == 0)
|
||||
return last = dbi;
|
||||
if (++dbi == walk.dbi + MAX_DBI)
|
||||
if (dbi == walk.dbi + MAX_DBI)
|
||||
return NULL;
|
||||
}
|
||||
|
||||
dbi->name = strdup(dbi_name);
|
||||
if (verbose > 1) {
|
||||
if (verbose > 1 && !silent) {
|
||||
print(" - found '%s' area\n", dbi_name);
|
||||
fflush(NULL);
|
||||
}
|
||||
@@ -241,85 +244,140 @@ static uint64_t problems_pop(struct problem *list) {
|
||||
return count;
|
||||
}
|
||||
|
||||
static int pgvisitor(uint64_t pgno, unsigned pgnumber, void *ctx,
|
||||
const char *dbi_name, const char *type, size_t nentries,
|
||||
static int pgvisitor(uint64_t pgno, unsigned pgnumber, void *ctx, int deep,
|
||||
const char *dbi_name, size_t page_size,
|
||||
MDBX_page_type_t pagetype, size_t nentries,
|
||||
size_t payload_bytes, size_t header_bytes,
|
||||
size_t unused_bytes) {
|
||||
(void)ctx;
|
||||
if (pagetype == MDBX_page_void)
|
||||
return MDBX_SUCCESS;
|
||||
|
||||
if (type) {
|
||||
uint64_t page_bytes = payload_bytes + header_bytes + unused_bytes;
|
||||
size_t page_size = (size_t)pgnumber * envstat.ms_psize;
|
||||
walk_dbi_t *dbi = pagemap_lookup_dbi(dbi_name);
|
||||
walk_dbi_t fake, *dbi = &fake;
|
||||
if (deep > 0) {
|
||||
dbi = pagemap_lookup_dbi(dbi_name, false);
|
||||
if (!dbi)
|
||||
return MDBX_ENOMEM;
|
||||
} else if (deep == 0 && strcmp(dbi_name, dbi_main.name) == 0)
|
||||
dbi = &dbi_main;
|
||||
else if (deep == -1 && strcmp(dbi_name, dbi_free.name) == 0)
|
||||
dbi = &dbi_free;
|
||||
else if (deep == -2 && strcmp(dbi_name, dbi_meta.name) == 0)
|
||||
dbi = &dbi_meta;
|
||||
else
|
||||
problem_add("deep", deep, "unknown area", "%s", dbi_name);
|
||||
|
||||
if (verbose > 2 && (!only_subdb || strcmp(only_subdb, dbi_name) == 0)) {
|
||||
const uint64_t page_bytes = payload_bytes + header_bytes + unused_bytes;
|
||||
walk.pgcount += pgnumber;
|
||||
|
||||
const char *pagetype_caption;
|
||||
switch (pagetype) {
|
||||
default:
|
||||
problem_add("page", pgno, "unknown page-type", "%u", (unsigned)pagetype);
|
||||
pagetype_caption = "unknown";
|
||||
dbi->pages.other += pgnumber;
|
||||
break;
|
||||
case MDBX_page_meta:
|
||||
pagetype_caption = "meta";
|
||||
dbi->pages.other += pgnumber;
|
||||
break;
|
||||
case MDBX_page_large:
|
||||
pagetype_caption = "large";
|
||||
dbi->pages.large_volume += pgnumber;
|
||||
dbi->pages.large_count += 1;
|
||||
break;
|
||||
case MDBX_page_branch:
|
||||
pagetype_caption = "branch";
|
||||
dbi->pages.branch += pgnumber;
|
||||
break;
|
||||
case MDBX_page_leaf:
|
||||
pagetype_caption = "leaf";
|
||||
dbi->pages.leaf += pgnumber;
|
||||
break;
|
||||
case MDBX_page_dupfixed_leaf:
|
||||
pagetype_caption = "leaf-dupfixed";
|
||||
dbi->pages.leaf_dupfixed += pgnumber;
|
||||
break;
|
||||
case MDBX_subpage_leaf:
|
||||
pagetype_caption = "subleaf-dupsort";
|
||||
dbi->pages.subleaf_dupsort += 1;
|
||||
break;
|
||||
case MDBX_subpage_dupfixed_leaf:
|
||||
pagetype_caption = "subleaf-dupfixed";
|
||||
dbi->pages.subleaf_dupfixed += 1;
|
||||
break;
|
||||
}
|
||||
|
||||
if (pgnumber) {
|
||||
if (verbose > 3 && (!only_subdb || strcmp(only_subdb, dbi_name) == 0)) {
|
||||
if (pgnumber == 1)
|
||||
print(" %s-page %" PRIu64, type, pgno);
|
||||
print(" %s-page %" PRIu64, pagetype_caption, pgno);
|
||||
else
|
||||
print(" %s-span %" PRIu64 "[%u]", type, pgno, pgnumber);
|
||||
print(" %s-span %" PRIu64 "[%u]", pagetype_caption, pgno, pgnumber);
|
||||
print(" of %s: header %" PRIiPTR ", payload %" PRIiPTR
|
||||
", unused %" PRIiPTR "\n",
|
||||
dbi_name, header_bytes, payload_bytes, unused_bytes);
|
||||
}
|
||||
}
|
||||
|
||||
walk.pgcount += pgnumber;
|
||||
if (unused_bytes > page_size)
|
||||
problem_add("page", pgno, "illegal unused-bytes",
|
||||
"%s-page: %u < %" PRIuPTR " < %u", pagetype_caption, 0,
|
||||
unused_bytes, envstat.ms_psize);
|
||||
|
||||
if (unused_bytes > page_size)
|
||||
problem_add("page", pgno, "illegal unused-bytes",
|
||||
"%u < %" PRIuPTR " < %u", 0, unused_bytes, envstat.ms_psize);
|
||||
|
||||
if (header_bytes < (int)sizeof(long) ||
|
||||
(size_t)header_bytes >= envstat.ms_psize - sizeof(long))
|
||||
problem_add("page", pgno, "illegal header-length",
|
||||
"%" PRIuPTR " < %" PRIuPTR " < %" PRIuPTR, sizeof(long),
|
||||
header_bytes, envstat.ms_psize - sizeof(long));
|
||||
if (payload_bytes < 1) {
|
||||
if (nentries > 1) {
|
||||
problem_add("page", pgno, "zero size-of-entry",
|
||||
"payload %" PRIuPTR " bytes, %" PRIuPTR " entries",
|
||||
payload_bytes, nentries);
|
||||
if ((size_t)header_bytes + unused_bytes < page_size) {
|
||||
/* LY: hush a misuse error */
|
||||
page_bytes = page_size;
|
||||
}
|
||||
} else {
|
||||
problem_add("page", pgno, "empty",
|
||||
"payload %" PRIuPTR " bytes, %" PRIuPTR " entries",
|
||||
payload_bytes, nentries);
|
||||
dbi->pages.empty += 1;
|
||||
}
|
||||
if (header_bytes < (int)sizeof(long) ||
|
||||
(size_t)header_bytes >= envstat.ms_psize - sizeof(long))
|
||||
problem_add("page", pgno, "illegal header-length",
|
||||
"%s-page: %" PRIuPTR " < %" PRIuPTR " < %" PRIuPTR,
|
||||
pagetype_caption, sizeof(long), header_bytes,
|
||||
envstat.ms_psize - sizeof(long));
|
||||
if (payload_bytes < 1) {
|
||||
if (nentries > 1) {
|
||||
problem_add("page", pgno, "zero size-of-entry",
|
||||
"%s-page: payload %" PRIuPTR " bytes, %" PRIuPTR " entries",
|
||||
pagetype_caption, payload_bytes, nentries);
|
||||
/* if ((size_t)header_bytes + unused_bytes < page_size) {
|
||||
// LY: hush a misuse error
|
||||
page_bytes = page_size;
|
||||
} */
|
||||
} else {
|
||||
problem_add("page", pgno, "empty",
|
||||
"%s-page: payload %" PRIuPTR " bytes, %" PRIuPTR " entries",
|
||||
pagetype_caption, payload_bytes, nentries);
|
||||
dbi->pages.empty += 1;
|
||||
}
|
||||
}
|
||||
|
||||
if (pgnumber) {
|
||||
if (page_bytes != page_size) {
|
||||
problem_add("page", pgno, "misused",
|
||||
"%" PRIu64 " != %" PRIu64 " (%" PRIuPTR "h + %" PRIuPTR
|
||||
"p + %" PRIuPTR "u)",
|
||||
page_size, page_bytes, header_bytes, payload_bytes,
|
||||
unused_bytes);
|
||||
"%s-page: %" PRIu64 " != %" PRIu64 " (%" PRIuPTR
|
||||
"h + %" PRIuPTR "p + %" PRIuPTR "u)",
|
||||
pagetype_caption, page_size, page_bytes, header_bytes,
|
||||
payload_bytes, unused_bytes);
|
||||
if (page_size > page_bytes)
|
||||
dbi->lost_bytes += page_size - page_bytes;
|
||||
} else {
|
||||
dbi->payload_bytes += payload_bytes + header_bytes;
|
||||
walk.total_payload_bytes += payload_bytes + header_bytes;
|
||||
}
|
||||
}
|
||||
|
||||
if (pgnumber) {
|
||||
do {
|
||||
if (pgno >= lastpgno)
|
||||
problem_add("page", pgno, "wrong page-no",
|
||||
"%" PRIu64 " > %" PRIu64 "", pgno, lastpgno);
|
||||
else if (walk.pagemap[pgno])
|
||||
problem_add("page", pgno, "already used", "in %s",
|
||||
walk.dbi[walk.pagemap[pgno]].name);
|
||||
else {
|
||||
walk.pagemap[pgno] = (short)(dbi - walk.dbi);
|
||||
dbi->pages.total += 1;
|
||||
}
|
||||
++pgno;
|
||||
} while (--pgnumber);
|
||||
}
|
||||
if (pgnumber) {
|
||||
do {
|
||||
if (pgno >= lastpgno)
|
||||
problem_add("page", pgno, "wrong page-no",
|
||||
"%s-page: %" PRIu64 " > %" PRIu64, pagetype_caption, pgno,
|
||||
lastpgno);
|
||||
else if (walk.pagemap[pgno])
|
||||
problem_add("page", pgno, "already used", "%s-page: by %s",
|
||||
pagetype_caption, walk.dbi[walk.pagemap[pgno] - 1].name);
|
||||
else {
|
||||
walk.pagemap[pgno] = (short)(dbi - walk.dbi + 1);
|
||||
dbi->pages.total += 1;
|
||||
}
|
||||
++pgno;
|
||||
} while (--pgnumber);
|
||||
}
|
||||
|
||||
return user_break ? MDBX_EINTR : MDBX_SUCCESS;
|
||||
@@ -327,7 +385,8 @@ static int pgvisitor(uint64_t pgno, unsigned pgnumber, void *ctx,
|
||||
|
||||
typedef int(visitor)(const uint64_t record_number, const MDBX_val *key,
|
||||
const MDBX_val *data);
|
||||
static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent);
|
||||
static int process_db(MDBX_dbi dbi_handle, char *dbi_name, visitor *handler,
|
||||
bool silent);
|
||||
|
||||
static int handle_userdb(const uint64_t record_number, const MDBX_val *key,
|
||||
const MDBX_val *data) {
|
||||
@@ -345,71 +404,79 @@ static int handle_freedb(const uint64_t record_number, const MDBX_val *key,
|
||||
|
||||
if (key->iov_len != sizeof(txnid_t))
|
||||
problem_add("entry", record_number, "wrong txn-id size",
|
||||
"key-size %" PRIiPTR "", key->iov_len);
|
||||
"key-size %" PRIiPTR, key->iov_len);
|
||||
else if (txnid < 1 || txnid > envinfo.mi_recent_txnid)
|
||||
problem_add("entry", record_number, "wrong txn-id", "%" PRIaTXN "", txnid);
|
||||
|
||||
if (data->iov_len < sizeof(pgno_t) || data->iov_len % sizeof(pgno_t))
|
||||
problem_add("entry", txnid, "wrong idl size", "%" PRIuPTR "",
|
||||
data->iov_len);
|
||||
problem_add("entry", record_number, "wrong txn-id", "%" PRIaTXN, txnid);
|
||||
else {
|
||||
const pgno_t number = *iptr++;
|
||||
if (number < 1 || number >= INT_MAX / 2)
|
||||
problem_add("entry", txnid, "wrong idl length", "%" PRIaPGNO, number);
|
||||
else if ((number + 1) * sizeof(pgno_t) > data->iov_len)
|
||||
if (data->iov_len < sizeof(pgno_t) || data->iov_len % sizeof(pgno_t))
|
||||
problem_add("entry", txnid, "wrong idl size", "%" PRIuPTR, data->iov_len);
|
||||
size_t number = (data->iov_len >= sizeof(pgno_t)) ? *iptr++ : 0;
|
||||
if (number < 1 || number > MDBX_PNL_MAX)
|
||||
problem_add("entry", txnid, "wrong idl length", "%" PRIuPTR, number);
|
||||
else if ((number + 1) * sizeof(pgno_t) > data->iov_len) {
|
||||
problem_add("entry", txnid, "trimmed idl",
|
||||
"%" PRIuSIZE " > %" PRIuSIZE " (corruption)",
|
||||
(number + 1) * sizeof(pgno_t), data->iov_len);
|
||||
else if (data->iov_len - (number + 1) * sizeof(pgno_t) >=
|
||||
/* LY: allow gap upto one page. it is ok
|
||||
* and better than shink-and-retry inside mdbx_update_gc() */
|
||||
envstat.ms_psize)
|
||||
number = data->iov_len / sizeof(pgno_t) - 1;
|
||||
} else if (data->iov_len - (number + 1) * sizeof(pgno_t) >=
|
||||
/* LY: allow gap upto one page. it is ok
|
||||
* and better than shink-and-retry inside mdbx_update_gc() */
|
||||
envstat.ms_psize)
|
||||
problem_add("entry", txnid, "extra idl space",
|
||||
"%" PRIuSIZE " < %" PRIuSIZE " (minor, not a trouble)",
|
||||
(number + 1) * sizeof(pgno_t), data->iov_len);
|
||||
else {
|
||||
freedb_pages += number;
|
||||
if (envinfo.mi_latter_reader_txnid > txnid)
|
||||
reclaimable_pages += number;
|
||||
|
||||
pgno_t prev =
|
||||
MDBX_PNL_ASCENDING ? NUM_METAS - 1 : (pgno_t)envinfo.mi_last_pgno + 1;
|
||||
pgno_t span = 1;
|
||||
for (unsigned i = 0; i < number; ++i) {
|
||||
const pgno_t pg = iptr[i];
|
||||
if (pg < NUM_METAS || pg > envinfo.mi_last_pgno)
|
||||
problem_add("entry", txnid, "wrong idl entry",
|
||||
"%u < %" PRIaPGNO " < %" PRIu64 "", NUM_METAS, pg,
|
||||
envinfo.mi_last_pgno);
|
||||
else if (MDBX_PNL_DISORDERED(prev, pg)) {
|
||||
gc_pages += number;
|
||||
if (envinfo.mi_latter_reader_txnid > txnid)
|
||||
reclaimable_pages += number;
|
||||
|
||||
pgno_t prev =
|
||||
MDBX_PNL_ASCENDING ? NUM_METAS - 1 : (pgno_t)envinfo.mi_last_pgno + 1;
|
||||
pgno_t span = 1;
|
||||
for (unsigned i = 0; i < number; ++i) {
|
||||
const pgno_t pgno = iptr[i];
|
||||
if (pgno < NUM_METAS || pgno > envinfo.mi_last_pgno)
|
||||
problem_add("entry", txnid, "wrong idl entry",
|
||||
"%u < %" PRIaPGNO " < %" PRIu64, NUM_METAS, pgno,
|
||||
envinfo.mi_last_pgno);
|
||||
else {
|
||||
if (MDBX_PNL_DISORDERED(prev, pgno)) {
|
||||
bad = " [bad sequence]";
|
||||
problem_add("entry", txnid, "bad sequence",
|
||||
"%" PRIaPGNO " <> %" PRIaPGNO "", prev, pg);
|
||||
"%" PRIaPGNO " <> %" PRIaPGNO, prev, pgno);
|
||||
}
|
||||
if (walk.pagemap && walk.pagemap[pgno]) {
|
||||
if (walk.pagemap[pgno] > 0)
|
||||
problem_add("page", pgno, "already used", "by %s",
|
||||
walk.dbi[walk.pagemap[pgno] - 1].name);
|
||||
else
|
||||
problem_add("page", pgno, "already listed in GC", nullptr);
|
||||
walk.pagemap[pgno] = -1;
|
||||
}
|
||||
prev = pg;
|
||||
while (i + span < number &&
|
||||
iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pg, span)
|
||||
: pgno_sub(pg, span)))
|
||||
++span;
|
||||
}
|
||||
if (verbose > 2 && !only_subdb) {
|
||||
print(" transaction %" PRIaTXN ", %" PRIaPGNO
|
||||
" pages, maxspan %" PRIaPGNO "%s\n",
|
||||
txnid, number, span, bad);
|
||||
if (verbose > 3) {
|
||||
for (unsigned i = 0; i < number; i += span) {
|
||||
const pgno_t pg = iptr[i];
|
||||
for (span = 1;
|
||||
i + span < number &&
|
||||
iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pg, span)
|
||||
: pgno_sub(pg, span));
|
||||
++span)
|
||||
;
|
||||
if (span > 1) {
|
||||
print(" %9" PRIaPGNO "[%" PRIaPGNO "]\n", pg, span);
|
||||
} else
|
||||
print(" %9" PRIaPGNO "\n", pg);
|
||||
}
|
||||
prev = pgno;
|
||||
while (i + span < number &&
|
||||
iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pgno, span)
|
||||
: pgno_sub(pgno, span)))
|
||||
++span;
|
||||
}
|
||||
if (verbose > 3 && !only_subdb) {
|
||||
print(" transaction %" PRIaTXN ", %" PRIuPTR
|
||||
" pages, maxspan %" PRIaPGNO "%s\n",
|
||||
txnid, number, span, bad);
|
||||
if (verbose > 4) {
|
||||
for (unsigned i = 0; i < number; i += span) {
|
||||
const pgno_t pgno = iptr[i];
|
||||
for (span = 1;
|
||||
i + span < number &&
|
||||
iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pgno, span)
|
||||
: pgno_sub(pgno, span));
|
||||
++span)
|
||||
;
|
||||
if (span > 1) {
|
||||
print(" %9" PRIaPGNO "[%" PRIaPGNO "]\n", pgno, span);
|
||||
} else
|
||||
print(" %9" PRIaPGNO "\n", pgno);
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -443,7 +510,8 @@ static int handle_maindb(const uint64_t record_number, const MDBX_val *key,
|
||||
return handle_userdb(record_number, key, data);
|
||||
}
|
||||
|
||||
static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) {
|
||||
static int process_db(MDBX_dbi dbi_handle, char *dbi_name, visitor *handler,
|
||||
bool silent) {
|
||||
MDBX_cursor *mc;
|
||||
MDBX_stat ms;
|
||||
MDBX_val key, data;
|
||||
@@ -456,22 +524,23 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) {
|
||||
uint64_t record_count = 0, dups = 0;
|
||||
uint64_t key_bytes = 0, data_bytes = 0;
|
||||
|
||||
if (dbi == ~0u) {
|
||||
rc = mdbx_dbi_open(txn, name, 0, &dbi);
|
||||
if (dbi_handle == ~0u) {
|
||||
rc = mdbx_dbi_open(txn, dbi_name, 0, &dbi_handle);
|
||||
if (rc) {
|
||||
if (!name ||
|
||||
if (!dbi_name ||
|
||||
rc !=
|
||||
MDBX_INCOMPATIBLE) /* LY: mainDB's record is not a user's DB. */ {
|
||||
error(" - mdbx_open '%s' failed, error %d %s\n", name ? name : "main",
|
||||
rc, mdbx_strerror(rc));
|
||||
error("mdbx_open '%s' failed, error %d %s\n",
|
||||
dbi_name ? dbi_name : "main", rc, mdbx_strerror(rc));
|
||||
}
|
||||
return rc;
|
||||
}
|
||||
}
|
||||
|
||||
if (dbi >= CORE_DBS && name && only_subdb && strcmp(only_subdb, name)) {
|
||||
if (dbi_handle >= CORE_DBS && dbi_name && only_subdb &&
|
||||
strcmp(only_subdb, dbi_name)) {
|
||||
if (verbose) {
|
||||
print("Skip processing '%s'...\n", name);
|
||||
print("Skip processing '%s'...\n", dbi_name);
|
||||
fflush(NULL);
|
||||
}
|
||||
skipped_subdb++;
|
||||
@@ -479,24 +548,24 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) {
|
||||
}
|
||||
|
||||
if (!silent && verbose) {
|
||||
print("Processing '%s'...\n", name ? name : "main");
|
||||
print("Processing '%s'...\n", dbi_name ? dbi_name : "@MAIN");
|
||||
fflush(NULL);
|
||||
}
|
||||
|
||||
rc = mdbx_dbi_flags(txn, dbi, &flags);
|
||||
rc = mdbx_dbi_flags(txn, dbi_handle, &flags);
|
||||
if (rc) {
|
||||
error(" - mdbx_dbi_flags failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
error("mdbx_dbi_flags failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
return rc;
|
||||
}
|
||||
|
||||
rc = mdbx_dbi_stat(txn, dbi, &ms, sizeof(ms));
|
||||
rc = mdbx_dbi_stat(txn, dbi_handle, &ms, sizeof(ms));
|
||||
if (rc) {
|
||||
error(" - mdbx_dbi_stat failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
error("mdbx_dbi_stat failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
return rc;
|
||||
}
|
||||
|
||||
if (!silent && verbose) {
|
||||
print(" - dbi-id %d, flags:", dbi);
|
||||
print(" - dbi-id %d, flags:", dbi_handle);
|
||||
if (!flags)
|
||||
print(" none");
|
||||
else {
|
||||
@@ -515,9 +584,32 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) {
|
||||
}
|
||||
}
|
||||
|
||||
rc = mdbx_cursor_open(txn, dbi, &mc);
|
||||
walk_dbi_t *dbi = (dbi_handle < CORE_DBS)
|
||||
? &walk.dbi[dbi_handle]
|
||||
: pagemap_lookup_dbi(dbi_name, true);
|
||||
if (!dbi) {
|
||||
error("too many DBIs or out of memory\n");
|
||||
return MDBX_ENOMEM;
|
||||
}
|
||||
const uint64_t subtotal_pages =
|
||||
ms.ms_branch_pages + ms.ms_leaf_pages + ms.ms_overflow_pages;
|
||||
if (subtotal_pages != dbi->pages.total)
|
||||
error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n", "subtotal",
|
||||
subtotal_pages, dbi->pages.total);
|
||||
if (ms.ms_branch_pages != dbi->pages.branch)
|
||||
error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n", "branch",
|
||||
ms.ms_branch_pages, dbi->pages.branch);
|
||||
const uint64_t allleaf_pages = dbi->pages.leaf + dbi->pages.leaf_dupfixed;
|
||||
if (ms.ms_leaf_pages != allleaf_pages)
|
||||
error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n", "all-leaf",
|
||||
ms.ms_leaf_pages, allleaf_pages);
|
||||
if (ms.ms_overflow_pages != dbi->pages.large_volume)
|
||||
error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n",
|
||||
"large/overlow", ms.ms_overflow_pages, dbi->pages.large_volume);
|
||||
|
||||
rc = mdbx_cursor_open(txn, dbi_handle, &mc);
|
||||
if (rc) {
|
||||
error(" - mdbx_cursor_open failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
error("mdbx_cursor_open failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
return rc;
|
||||
}
|
||||
|
||||
@@ -551,11 +643,11 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) {
|
||||
if (prev_key.iov_base) {
|
||||
if ((flags & MDBX_DUPFIXED) && prev_data.iov_len != data.iov_len) {
|
||||
problem_add("entry", record_count, "different data length",
|
||||
"%" PRIuPTR " != %" PRIuPTR "", prev_data.iov_len,
|
||||
"%" PRIuPTR " != %" PRIuPTR, prev_data.iov_len,
|
||||
data.iov_len);
|
||||
}
|
||||
|
||||
int cmp = mdbx_cmp(txn, dbi, &prev_key, &key);
|
||||
int cmp = mdbx_cmp(txn, dbi_handle, &prev_key, &key);
|
||||
if (cmp > 0) {
|
||||
problem_add("entry", record_count, "broken ordering of entries", NULL);
|
||||
} else if (cmp == 0) {
|
||||
@@ -563,7 +655,7 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) {
|
||||
if (!(flags & MDBX_DUPSORT))
|
||||
problem_add("entry", record_count, "duplicated entries", NULL);
|
||||
else if (flags & MDBX_INTEGERDUP) {
|
||||
cmp = mdbx_dcmp(txn, dbi, &prev_data, &data);
|
||||
cmp = mdbx_dcmp(txn, dbi_handle, &prev_data, &data);
|
||||
if (cmp > 0)
|
||||
problem_add("entry", record_count,
|
||||
"broken ordering of multi-values", NULL);
|
||||
@@ -591,13 +683,13 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) {
|
||||
rc = mdbx_cursor_get(mc, &key, &data, MDBX_NEXT);
|
||||
}
|
||||
if (rc != MDBX_NOTFOUND)
|
||||
error(" - mdbx_cursor_get failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
error("mdbx_cursor_get failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
else
|
||||
rc = 0;
|
||||
|
||||
if (record_count != ms.ms_entries)
|
||||
problem_add("entry", record_count, "differentent number of entries",
|
||||
"%" PRIuPTR " != %" PRIuPTR "", record_count, ms.ms_entries);
|
||||
"%" PRIuPTR " != %" PRIuPTR, record_count, ms.ms_entries);
|
||||
bailout:
|
||||
problems_count = problems_pop(saved_list);
|
||||
if (!silent && verbose) {
|
||||
@@ -725,7 +817,7 @@ void verbose_meta(int num, txnid_t txnid, uint64_t sign) {
|
||||
print(", stay");
|
||||
|
||||
if (txnid > envinfo.mi_recent_txnid &&
|
||||
(exclusive || (envflags & MDBX_RDONLY) == 0))
|
||||
(envflags & (MDBX_EXCLUSIVE | MDBX_RDONLY)) == MDBX_EXCLUSIVE)
|
||||
print(", rolled-back %" PRIu64 " (%" PRIu64 " >>> %" PRIu64 ")",
|
||||
txnid - envinfo.mi_recent_txnid, txnid, envinfo.mi_recent_txnid);
|
||||
print("\n");
|
||||
@@ -735,7 +827,7 @@ static int check_meta_head(bool steady) {
|
||||
switch (meta_recent(steady)) {
|
||||
default:
|
||||
assert(false);
|
||||
error(" - unexpected internal error (%s)\n",
|
||||
error("unexpected internal error (%s)\n",
|
||||
steady ? "meta_steady_head" : "meta_weak_head");
|
||||
__fallthrough;
|
||||
case 0:
|
||||
@@ -797,7 +889,9 @@ int main(int argc, char *argv[]) {
|
||||
}
|
||||
#endif
|
||||
|
||||
walk.dbi[FREE_DBI].name = "@gc";
|
||||
dbi_meta.name = "@META";
|
||||
dbi_free.name = "@GC";
|
||||
dbi_main.name = "@MAIN";
|
||||
atexit(pagemap_cleanup);
|
||||
|
||||
if (argc < 2) {
|
||||
@@ -824,7 +918,7 @@ int main(int argc, char *argv[]) {
|
||||
envflags &= ~MDBX_RDONLY;
|
||||
break;
|
||||
case 'c':
|
||||
exclusive = 0;
|
||||
envflags &= ~MDBX_EXCLUSIVE;
|
||||
break;
|
||||
case 'd':
|
||||
dont_traversal = 1;
|
||||
@@ -872,7 +966,19 @@ int main(int argc, char *argv[]) {
|
||||
goto bailout;
|
||||
}
|
||||
|
||||
rc = mdbx_env_open_ex(env, envname, envflags, 0664, &exclusive);
|
||||
rc = mdbx_env_open(env, envname, envflags, 0664);
|
||||
if ((envflags & MDBX_EXCLUSIVE) &&
|
||||
(rc == MDBX_BUSY ||
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
rc == ERROR_LOCK_VIOLATION || rc == ERROR_SHARING_VIOLATION
|
||||
#else
|
||||
rc == EBUSY
|
||||
#endif
|
||||
)) {
|
||||
envflags &= ~MDBX_EXCLUSIVE;
|
||||
rc = mdbx_env_open(env, envname, envflags, 0664);
|
||||
}
|
||||
|
||||
if (rc) {
|
||||
error("mdbx_env_open failed, error %d %s\n", rc, mdbx_strerror(rc));
|
||||
if (rc == MDBX_WANNA_RECOVERY && (envflags & MDBX_RDONLY))
|
||||
@@ -880,7 +986,8 @@ int main(int argc, char *argv[]) {
|
||||
goto bailout;
|
||||
}
|
||||
if (verbose)
|
||||
print(" - %s mode\n", exclusive ? "monopolistic" : "cooperative");
|
||||
print(" - %s mode\n",
|
||||
(envflags & MDBX_EXCLUSIVE) ? "monopolistic" : "cooperative");
|
||||
|
||||
if ((envflags & MDBX_RDONLY) == 0) {
|
||||
rc = mdbx_txn_lock(env, false);
|
||||
@@ -965,7 +1072,7 @@ int main(int argc, char *argv[]) {
|
||||
++problems_meta;
|
||||
}
|
||||
|
||||
if (exclusive > 1) {
|
||||
if (envflags & MDBX_EXCLUSIVE) {
|
||||
if (verbose)
|
||||
print(" - performs full check recent-txn-id with meta-pages\n");
|
||||
problems_meta += check_meta_head(true);
|
||||
@@ -1009,25 +1116,44 @@ int main(int argc, char *argv[]) {
|
||||
|
||||
for (uint64_t n = 0; n < lastpgno; ++n)
|
||||
if (!walk.pagemap[n])
|
||||
walk.dbi[FREE_DBI].pages.total += 1;
|
||||
unused_pages += 1;
|
||||
|
||||
empty_pages = lost_bytes = 0;
|
||||
for (walk_dbi_t *dbi = walk.dbi; ++dbi < walk.dbi + MAX_DBI && dbi->name;) {
|
||||
for (walk_dbi_t *dbi = &dbi_main; dbi < walk.dbi + MAX_DBI && dbi->name;
|
||||
++dbi) {
|
||||
empty_pages += dbi->pages.empty;
|
||||
lost_bytes += dbi->lost_bytes;
|
||||
}
|
||||
|
||||
if (verbose) {
|
||||
uint64_t total_page_bytes = walk.pgcount * envstat.ms_psize;
|
||||
print(" - dbi pages: %" PRIu64 " total", walk.pgcount);
|
||||
if (verbose > 1)
|
||||
for (walk_dbi_t *dbi = walk.dbi;
|
||||
++dbi < walk.dbi + MAX_DBI && dbi->name;)
|
||||
print(", %s %" PRIu64, dbi->name, dbi->pages.total);
|
||||
print(", %s %" PRIu64 "\n", walk.dbi[FREE_DBI].name,
|
||||
walk.dbi[FREE_DBI].pages.total);
|
||||
print(" - pages: total %" PRIu64 ", unused %" PRIu64 "\n", walk.pgcount,
|
||||
unused_pages);
|
||||
if (verbose > 1) {
|
||||
print(" - space info: total %" PRIu64 " bytes, payload %" PRIu64
|
||||
for (walk_dbi_t *dbi = walk.dbi; dbi < walk.dbi + MAX_DBI && dbi->name;
|
||||
++dbi) {
|
||||
print(" %s: subtotal %" PRIu64, dbi->name, dbi->pages.total);
|
||||
if (dbi->pages.other && dbi->pages.other != dbi->pages.total)
|
||||
print(", other %" PRIu64, dbi->pages.other);
|
||||
if (dbi->pages.branch)
|
||||
print(", branch %" PRIu64, dbi->pages.branch);
|
||||
if (dbi->pages.large_count)
|
||||
print(", large %" PRIu64, dbi->pages.large_count);
|
||||
uint64_t all_leaf = dbi->pages.leaf + dbi->pages.leaf_dupfixed;
|
||||
if (all_leaf) {
|
||||
print(", leaf %" PRIu64, all_leaf);
|
||||
if (verbose > 2)
|
||||
print(" (usual %" PRIu64 ", sub-dupsort %" PRIu64
|
||||
", dupfixed %" PRIu64 ", sub-dupfixed %" PRIu64 ")",
|
||||
dbi->pages.leaf, dbi->pages.subleaf_dupsort,
|
||||
dbi->pages.leaf_dupfixed, dbi->pages.subleaf_dupfixed);
|
||||
}
|
||||
print("\n");
|
||||
}
|
||||
}
|
||||
|
||||
if (verbose > 1)
|
||||
print(" - usage: total %" PRIu64 " bytes, payload %" PRIu64
|
||||
" (%.1f%%), unused "
|
||||
"%" PRIu64 " (%.1f%%)\n",
|
||||
total_page_bytes, walk.total_payload_bytes,
|
||||
@@ -1035,8 +1161,9 @@ int main(int argc, char *argv[]) {
|
||||
total_page_bytes - walk.total_payload_bytes,
|
||||
(total_page_bytes - walk.total_payload_bytes) * 100.0 /
|
||||
total_page_bytes);
|
||||
for (walk_dbi_t *dbi = walk.dbi;
|
||||
++dbi < walk.dbi + MAX_DBI && dbi->name;) {
|
||||
if (verbose > 2) {
|
||||
for (walk_dbi_t *dbi = walk.dbi; dbi < walk.dbi + MAX_DBI && dbi->name;
|
||||
++dbi) {
|
||||
uint64_t dbi_bytes = dbi->pages.total * envstat.ms_psize;
|
||||
print(" %s: subtotal %" PRIu64 " bytes (%.1f%%),"
|
||||
" payload %" PRIu64 " (%.1f%%), unused %" PRIu64 " (%.1f%%)",
|
||||
@@ -1067,12 +1194,12 @@ int main(int argc, char *argv[]) {
|
||||
if (!verbose)
|
||||
print("Iterating DBIs...\n");
|
||||
problems_maindb = process_db(~0u, /* MAIN_DBI */ NULL, NULL, false);
|
||||
problems_freedb = process_db(FREE_DBI, "free", handle_freedb, false);
|
||||
problems_freedb = process_db(FREE_DBI, "@GC", handle_freedb, false);
|
||||
|
||||
if (verbose) {
|
||||
uint64_t value = envinfo.mi_mapsize / envstat.ms_psize;
|
||||
double percent = value / 100.0;
|
||||
print(" - pages info: %" PRIu64 " total", value);
|
||||
print(" - space: %" PRIu64 " total pages", value);
|
||||
value = envinfo.mi_geo.current / envinfo.mi_dxb_pagesize;
|
||||
print(", backed %" PRIu64 " (%.1f%%)", value, value / percent);
|
||||
print(", allocated %" PRIu64 " (%.1f%%)", lastpgno, lastpgno / percent);
|
||||
@@ -1081,12 +1208,12 @@ int main(int argc, char *argv[]) {
|
||||
value = envinfo.mi_mapsize / envstat.ms_psize - lastpgno;
|
||||
print(", remained %" PRIu64 " (%.1f%%)", value, value / percent);
|
||||
|
||||
value = lastpgno - freedb_pages;
|
||||
value = lastpgno - gc_pages;
|
||||
print(", used %" PRIu64 " (%.1f%%)", value, value / percent);
|
||||
|
||||
print(", gc %" PRIu64 " (%.1f%%)", freedb_pages, freedb_pages / percent);
|
||||
print(", gc %" PRIu64 " (%.1f%%)", gc_pages, gc_pages / percent);
|
||||
|
||||
value = freedb_pages - reclaimable_pages;
|
||||
value = gc_pages - reclaimable_pages;
|
||||
print(", detained %" PRIu64 " (%.1f%%)", value, value / percent);
|
||||
|
||||
print(", reclaimable %" PRIu64 " (%.1f%%)", reclaimable_pages,
|
||||
@@ -1099,14 +1226,15 @@ int main(int argc, char *argv[]) {
|
||||
}
|
||||
|
||||
if (problems_maindb == 0 && problems_freedb == 0) {
|
||||
if (!dont_traversal && (exclusive || (envflags & MDBX_RDONLY) == 0)) {
|
||||
if (walk.pgcount != lastpgno - freedb_pages) {
|
||||
if (!dont_traversal &&
|
||||
(envflags & (MDBX_EXCLUSIVE | MDBX_RDONLY)) != MDBX_RDONLY) {
|
||||
if (walk.pgcount != lastpgno - gc_pages) {
|
||||
error("used pages mismatch (%" PRIu64 " != %" PRIu64 ")\n",
|
||||
walk.pgcount, lastpgno - freedb_pages);
|
||||
walk.pgcount, lastpgno - gc_pages);
|
||||
}
|
||||
if (walk.dbi[FREE_DBI].pages.total != freedb_pages) {
|
||||
error("gc pages mismatch (%" PRIu64 " != %" PRIu64 ")\n",
|
||||
walk.dbi[FREE_DBI].pages.total, freedb_pages);
|
||||
if (unused_pages != gc_pages) {
|
||||
error("gc pages mismatch (%" PRIu64 " != %" PRIu64 ")\n", unused_pages,
|
||||
gc_pages);
|
||||
}
|
||||
} else if (verbose) {
|
||||
print(" - skip check used and gc pages (btree-traversal with "
|
||||
@@ -1148,8 +1276,8 @@ bailout:
|
||||
|
||||
total_problems += problems_meta;
|
||||
if (total_problems || problems_maindb || problems_freedb) {
|
||||
print("Total %" PRIu64 " error(s) is detected, elapsed %.3f seconds.\n",
|
||||
total_problems, elapsed);
|
||||
print("Total %" PRIu64 " error%s detected, elapsed %.3f seconds.\n",
|
||||
total_problems, (total_problems > 1) ? "s are" : " is", elapsed);
|
||||
if (problems_meta || problems_maindb || problems_freedb)
|
||||
return EXIT_FAILURE_CHECK_MAJOR;
|
||||
return EXIT_FAILURE_CHECK_MINOR;
|
||||
|
||||
@@ -136,7 +136,7 @@ static void readhdr(void) {
|
||||
ptr = memchr(dbuf.iov_base, '\n', dbuf.iov_len);
|
||||
if (ptr)
|
||||
*ptr = '\0';
|
||||
i = sscanf((char *)dbuf.iov_base + STRLENOF("mapsize="), "%" PRIu64 "",
|
||||
i = sscanf((char *)dbuf.iov_base + STRLENOF("mapsize="), "%" PRIu64,
|
||||
&envinfo.mi_mapsize);
|
||||
if (i != 1) {
|
||||
fprintf(stderr, "%s: line %" PRIiSIZE ": invalid mapsize %s\n", prog,
|
||||
|
||||
@@ -14,12 +14,12 @@
|
||||
|
||||
#include "./bits.h"
|
||||
|
||||
#if MDBX_VERSION_MAJOR != 0 || MDBX_VERSION_MINOR != 1
|
||||
#if MDBX_VERSION_MAJOR != 0 || MDBX_VERSION_MINOR != 2
|
||||
#error "API version mismatch!"
|
||||
#endif
|
||||
|
||||
#define MDBX_VERSION_RELEASE 6
|
||||
#define MDBX_VERSION_REVISION 1
|
||||
#define MDBX_VERSION_RELEASE 0
|
||||
#define MDBX_VERSION_REVISION 2
|
||||
|
||||
/*LIBMDBX_EXPORTS*/ const mdbx_version_info mdbx_version = {
|
||||
MDBX_VERSION_MAJOR,
|
||||
|
||||
@@ -80,6 +80,10 @@
|
||||
#include "../src/defs.h"
|
||||
#include "../src/osal.h"
|
||||
|
||||
#if !defined(__thread) && (defined(_MSC_VER) || defined(__DMC__))
|
||||
#define __thread __declspec(thread)
|
||||
#endif /* __thread */
|
||||
|
||||
#ifdef _MSC_VER
|
||||
#pragma warning(pop)
|
||||
#pragma warning(disable : 4201) /* nonstandard extension used : \
|
||||
|
||||
@@ -556,7 +556,7 @@ unsigned actor_params::mdbx_keylen_min() const {
|
||||
unsigned actor_params::mdbx_keylen_max() const {
|
||||
return (table_flags & MDBX_INTEGERKEY)
|
||||
? 8
|
||||
: std::min((unsigned)mdbx_get_maxkeysize(pagesize),
|
||||
: std::min((unsigned)mdbx_limits_keysize_max(pagesize),
|
||||
(unsigned)UINT16_MAX);
|
||||
}
|
||||
|
||||
@@ -568,7 +568,7 @@ unsigned actor_params::mdbx_datalen_max() const {
|
||||
return (table_flags & MDBX_INTEGERDUP)
|
||||
? 8
|
||||
: std::min((table_flags & MDBX_DUPSORT)
|
||||
? (unsigned)mdbx_get_maxkeysize(pagesize)
|
||||
? (unsigned)mdbx_limits_keysize_max(pagesize)
|
||||
: (unsigned)MDBX_MAXDATASIZE,
|
||||
(unsigned)UINT16_MAX);
|
||||
}
|
||||
|
||||
@@ -24,7 +24,7 @@ function probe {
|
||||
echo "${caption}: $*"
|
||||
rm -f ${TESTDB_PREFIX}* \
|
||||
&& ./mdbx_test --pathname=${TESTDB_PREFIX}db "$@" | lz4 > ${TESTDB_PREFIX}log.lz4 \
|
||||
&& ./mdbx_chk -nvv ${TESTDB_PREFIX}db | tee ${TESTDB_PREFIX}chk \
|
||||
&& ./mdbx_chk -nvvv ${TESTDB_PREFIX}db | tee ${TESTDB_PREFIX}chk \
|
||||
|| (echo "FAILED"; exit 1)
|
||||
}
|
||||
|
||||
@@ -52,11 +52,11 @@ for nops in {2..7}; do
|
||||
caption="Probe #$((++count)) w/o-dups, repeat ${rep} of ${loops}" probe \
|
||||
--pagesize=min --size=6G --table=-data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=1111 \
|
||||
--nops=$( rep9 $nops ) --batch.write=$( rep9 $wbatch ) --mode=$(bits2list options $bits) \
|
||||
--keygen.seed=${seed} --hill
|
||||
--keygen.seed=${seed} basic
|
||||
caption="Probe #$((++count)) with-dups, repeat ${rep} of ${loops}" probe \
|
||||
--pagesize=min --size=6G --table=+data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=max \
|
||||
--nops=$( rep9 $nops ) --batch.write=$( rep9 $wbatch ) --mode=$(bits2list options $bits) \
|
||||
--keygen.seed=${seed} --hill
|
||||
--keygen.seed=${seed} basic
|
||||
done
|
||||
done
|
||||
done
|
||||
|
||||
@@ -114,6 +114,7 @@ bool testcase_hill::run() {
|
||||
log_trace("uphill: update-a (age %" PRIu64 "->0) %" PRIu64, age_shift,
|
||||
a_serial);
|
||||
generate_pair(a_serial, a_key, a_data_0, 0);
|
||||
checkdata("uphill: update-a", dbi, a_key->value, a_data_1->value);
|
||||
rc = mdbx_replace(txn_guard.get(), dbi, &a_key->value, &a_data_0->value,
|
||||
&a_data_1->value, update_flags);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
@@ -126,6 +127,7 @@ bool testcase_hill::run() {
|
||||
|
||||
// удаляем вторую запись
|
||||
log_trace("uphill: delete-b %" PRIu64, b_serial);
|
||||
checkdata("uphill: delete-b", dbi, b_key->value, b_data->value);
|
||||
rc = mdbx_del(txn_guard.get(), dbi, &b_key->value, &b_data->value);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
failure_perror("mdbx_del(b)", rc);
|
||||
@@ -158,6 +160,7 @@ bool testcase_hill::run() {
|
||||
a_serial);
|
||||
generate_pair(a_serial, a_key, a_data_0, 0);
|
||||
generate_pair(a_serial, a_key, a_data_1, age_shift);
|
||||
checkdata("downhill: update-a", dbi, a_key->value, a_data_0->value);
|
||||
int rc = mdbx_replace(txn_guard.get(), dbi, &a_key->value, &a_data_1->value,
|
||||
&a_data_0->value, update_flags);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
@@ -184,6 +187,7 @@ bool testcase_hill::run() {
|
||||
// удаляем первую запись
|
||||
log_trace("downhill: delete-a (age %" PRIu64 ") %" PRIu64, age_shift,
|
||||
a_serial);
|
||||
checkdata("downhill: delete-a", dbi, a_key->value, a_data_1->value);
|
||||
rc = mdbx_del(txn_guard.get(), dbi, &a_key->value, &a_data_1->value);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
failure_perror("mdbx_del(a)", rc);
|
||||
@@ -195,6 +199,7 @@ bool testcase_hill::run() {
|
||||
|
||||
// удаляем вторую запись
|
||||
log_trace("downhill: delete-b %" PRIu64, b_serial);
|
||||
checkdata("downhill: delete-b", dbi, b_key->value, b_data->value);
|
||||
rc = mdbx_del(txn_guard.get(), dbi, &b_key->value, &b_data->value);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
failure_perror("mdbx_del(b)", rc);
|
||||
|
||||
@@ -17,16 +17,7 @@
|
||||
#include "base.h"
|
||||
|
||||
void __noreturn usage(void);
|
||||
|
||||
#ifdef __GNUC__
|
||||
#define __printf_args(format_index, first_arg) \
|
||||
__attribute__((format(printf, format_index, first_arg)))
|
||||
#else
|
||||
#define __printf_args(format_index, first_arg)
|
||||
#endif
|
||||
|
||||
void __noreturn __printf_args(1, 2) failure(const char *fmt, ...);
|
||||
|
||||
void __noreturn failure_perror(const char *what, int errnum);
|
||||
const char *test_strerror(int errnum);
|
||||
|
||||
|
||||
15
test/loop.bat
Executable file
15
test/loop.bat
Executable file
@@ -0,0 +1,15 @@
|
||||
@echo off
|
||||
|
||||
del test.db test.db-lck
|
||||
|
||||
:loop
|
||||
|
||||
mdbx_test.exe --pathname=test.db --dont-cleanup-after basic > test.log
|
||||
if errorlevel 1 goto fail
|
||||
|
||||
mdbx_chk.exe -nvvv test.db > chk.log
|
||||
if errorlevel 1 goto fail
|
||||
goto loop
|
||||
|
||||
:fail
|
||||
echo FAILED
|
||||
10
test/test.cc
10
test/test.cc
@@ -410,6 +410,16 @@ void testcase::db_table_close(MDBX_dbi handle) {
|
||||
log_trace("<< testcase::db_table_close");
|
||||
}
|
||||
|
||||
void testcase::checkdata(const char *step, MDBX_dbi handle, MDBX_val key2check,
|
||||
MDBX_val expected_valued) {
|
||||
MDBX_val actual_value = expected_valued;
|
||||
int rc = mdbx_get2(txn_guard.get(), handle, &key2check, &actual_value);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
failure_perror(step, rc);
|
||||
if (!is_samedata(&actual_value, &expected_valued))
|
||||
failure("%s data mismatch", step);
|
||||
}
|
||||
|
||||
//-----------------------------------------------------------------------------
|
||||
|
||||
bool test_execute(const actor_config &config) {
|
||||
|
||||
@@ -112,6 +112,8 @@ protected:
|
||||
void fetch_canary();
|
||||
void update_canary(uint64_t increment);
|
||||
void kick_progress(bool active) const;
|
||||
void checkdata(const char *step, MDBX_dbi handle, MDBX_val key2check,
|
||||
MDBX_val expected_valued);
|
||||
|
||||
MDBX_dbi db_table_open(bool create);
|
||||
void db_table_drop(MDBX_dbi handle);
|
||||
|
||||
@@ -91,6 +91,11 @@ bool hex2data(const char *hex_begin, const char *hex_end, void *ptr,
|
||||
return true;
|
||||
}
|
||||
|
||||
bool is_samedata(const MDBX_val *a, const MDBX_val *b) {
|
||||
return a->iov_len == b->iov_len &&
|
||||
memcmp(a->iov_base, b->iov_base, a->iov_len) == 0;
|
||||
}
|
||||
|
||||
//-----------------------------------------------------------------------------
|
||||
|
||||
/* TODO: replace my 'libmera' from t1ha. */
|
||||
|
||||
@@ -317,7 +317,7 @@ struct simple_checksum {
|
||||
std::string data2hex(const void *ptr, size_t bytes, simple_checksum &checksum);
|
||||
bool hex2data(const char *hex_begin, const char *hex_end, void *ptr,
|
||||
size_t bytes, simple_checksum &checksum);
|
||||
|
||||
bool is_samedata(const MDBX_val *a, const MDBX_val *b);
|
||||
std::string format(const char *fmt, ...);
|
||||
|
||||
uint64_t entropy_ticks(void);
|
||||
|
||||
Reference in New Issue
Block a user