The repository now only mirrored on the Github due to illegal discriminatory restrictions for Russian Crimea and for sovereign crimeans.
libmdbx
libmdbx is an extremely fast, compact, powerful, embedded transactional key-value store database, with permissive OpenLDAP Public License. libmdbx has a specific set of properties and capabilities, focused on creating unique lightweight solutions with extraordinary performance.
The next version is under active non-public development and will be
released as MithrilDB and libmithrildb for libraries & packages.
Admittedly mythical Mithril is
resembling silver but being stronger and lighter than steel. Therefore
MithrilDB is rightly relevant name.
MithrilDB will be radically different from libmdbx by the new database format and API based on C++17, as well as the Apache 2.0 License. The goal of this revolution is to provide a clearer and robust API, add more features and new valuable properties of database.
The Future will (be) Positive. Всё будет хорошо.

![]()
Table of Contents
Overview
libmdbx is revised and extended descendant of amazing Lightning Memory-Mapped Database. libmdbx inherits all features and characteristics from LMDB, but resolves some issues and adds several features.
-
libmdbx guarantee data integrity after crash unless this was explicitly neglected in favour of write performance.
-
libmdbx allows multiple processes to read and update several key-value tables concurrently, while being ACID-compliant, with minimal overhead and Olog(N) operation cost.
-
libmdbx enforce serializability for writers by single mutex and affords wait-free for parallel readers without atomic/interlocked operations, while writing and reading transactions do not block each other.
-
libmdbx uses B+Trees and Memory-Mapping, doesn't use WAL which might be a caveat for some workloads.
-
libmdbx implements a simplified variant of the Berkeley DB and/or dbm API.
-
libmdbx supports Linux, Windows, MacOS, FreeBSD, DragonFly, Solaris, OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with POSIX.1-2008.
Comparison with other databases
For now please refer to chapter of "BoltDB comparison with other databases" which is also (mostly) applicable to libmdbx.
History
At first the development was carried out within the ReOpenLDAP project. About a year later libmdbx was separated into standalone project, which was presented at Highload++ 2015 conference.
Since 2017 libmdbx is used in Fast Positive Tables, and development is funded by Positive Technologies.
Acknowledgments
Howard Chu hyc@openldap.org is the author of LMDB, from which originated the MDBX in 2015.
Martin Hedenfalk martin@bzero.se is the author of btree.c code, which
was used for begin development of LMDB.
Description
Key features
-
Key-value pairs are stored in ordered map(s), keys are always sorted, range lookups are supported.
-
Data is memory-mapped into each worker DB process, and could be accessed zero-copy from transactions.
-
Transactions are ACID-compliant, through to MVCC and CoW. Writes are strongly serialized and aren't blocked by reads, transactions can't conflict with each other. Reads are guaranteed to get only commited data (relaxing serializability).
-
Read transactions are non-blocking, don't use atomic operations. Readers don't block each other and aren't blocked by writers. Read performance scales linearly with CPU core count.
Nonetheless, "connect to DB" (starting the first read transaction in a thread) and "disconnect from DB" (closing DB or thread termination) requires a lock acquisition to register/unregister at the "readers table".
-
Keys with multiple values are stored efficiently without key duplication, sorted by value, including integers (valuable for secondary indexes).
-
Efficient operation on short fixed length keys, including 32/64-bit integer types.
-
WAF (Write Amplification Factor) и RAF (Read Amplification Factor) are Olog(N).
-
No WAL and transaction journal. In case of a crash no recovery needed. No need for regular maintenance. Backups can be made on the fly on working DB without freezing writers.
-
No additional memory management, all done by basic OS services.
Improvements over LMDB
libmdbx is superior to legendary LMDB in terms of features and reliability, not inferior in performance. In comparison to LMDB, libmdbx make things "just work" perfectly and out-of-the-box, not silently and catastrophically break down. The list below is pruned down to the improvements most notable and obvious from the user's point of view.
- Automatic on-the-fly database size control by preset parameters, both reduction and increment.
libmdbx manage the database size according to parameters specified by
mdbx_env_set_geometry()function, ones include the growth step and the truncation threshold.
- Automatic continuous zero-overhead database compactification.
libmdbx logically move as possible a freed pages at end of allocation area into unallocated space, and then release such space if a lot of.
- LIFO policy for recycling a Garbage Collection items. On systems with a disk write-back cache, this can significantly increase write performance, up to several times in a best case scenario.
LIFO means that for reuse pages will be taken which became unused the lastest. Therefore the loop of database pages circulation becomes as short as possible. In other words, the number of pages, that are overwritten in memory and on disk during a series of write transactions, will be as small as possible. Thus creates ideal conditions for the efficient operation of the disk write-back cache.
- Fast estimation of range query result volume, i.e. how many items can
be found between a
KEY1and aKEY2. This is prerequisite for build and/or optimize query execution plans.
libmdbx performs a rough estimate based only on b-tree pages that are common for the both stacks of cursors that were set to corresponing keys.
-
mdbx_chktool for database integrity check. -
Guarantee of database integrity even in asynchronous unordered write-to-disk mode.
libmdbx propose additional trade-off by implementing append-like manner for updates in
NOSYNCandMAPASYNCmodes, that avoid database corruption after a system crash contrary to LMDB. Nevertheless, theMDBX_UTTERLY_NOSYNCmode available to match LMDB behaviour, and for a special use-cases.
-
Automated steady flush to disk upon volume of changes and/or by timeout via cheap polling.
-
Sequence generation and three cheap persistent 64-bit markers with ACID.
-
Support for keys and values of zero length, including multi-values (aka sorted duplicates).
-
The handler of lack-of-space condition with a callback, that allow you to control and resolve such situations.
-
Support for opening a database in the exclusive mode, including on a network share.
-
Extended transaction info, including dirty and leftover space info for a write transaction, reading lag and hold over space for read transactions.
-
Extended whole-database info (aka environment) and reader enumeration.
-
Extended update or delete, at once with getting previous value and addressing the particular item from multi-value with the same key.
-
Support for explicitly updating the existing record, not insertion a new one.
-
All cursors are uniformly, can be reused and should be closed explicitly, regardless ones were opened within write or read transaction.
-
Correct update of current record with
MDBX_CURRENTflag when size of key or data was changed, including sorted duplicated. -
Opening database handles is spared from race conditions and pre-opening is not needed.
-
Ability to determine whether the particular data is on a dirty page or not, that allows to avoid copy-out before updates.
-
Ability to determine whether the cursor is pointed to a key-value pair, to the first, to the last, or not set to anything.
-
Returning
MDBX_EMULTIVALerror in case of ambiguous update or delete. -
On MacOS the
fcntl(F_FULLFSYNC)syscall is used by default to synchronize data with the disk, as this is the only way to guarantee data durability in case of power failure. Unfortunately, in scenarios with high write intensity, the use ofF_FULLFSYNCsignificant degrades performance compared to LMDB, where thefsync()syscall is used. Therefore, libmdbx allows you to override this behavior by defining theMDBX_OSX_SPEED_INSTEADOF_DURABILITY=1option while build the library. -
On Windows the
LockFileEx()syscall is used for locking, since it allows place the database on network drives, and provides protection against incompetent user actions (aka poka-yoke). Therefore libmdbx may be a little lag in performance tests from LMDB where a named mutexes are used.
Gotchas
- There cannot be more than one writer at a time.
On the other hand, this allows serialize an updates and eliminate any possibility of conflicts, deadlocks or logical errors.
- No WAL means relatively big WAF (Write Amplification Factor). Because of this syncing data to disk might be quite resource intensive and be main performance bottleneck during intensive write workload.
As compromise libmdbx allows several modes of lazy and/or periodic syncing, including
MAPASYNCmode, which modificate data in memory and asynchronously syncs data to disk, moment to sync is picked by OS.Although this should be used with care, synchronous transactions in a DB with transaction journal will require 2 IOPS minimum (probably 3-4 in practice) because of filesystem overhead, overhead depends on filesystem, not on record count or record size. In libmdbx IOPS count will grow logarithmically depending on record count in DB (height of B+ tree) and will require at least 2 IOPS per transaction too.
- CoW for
MVCC
is done on memory page level with
B+trees.
Therefore altering data requires to copy about Olog(N) memory pages,
which uses memory bandwidth and is main
performance bottleneck in
MDBX_MAPASYNCmode.
This is unavoidable, but isn't that bad. Syncing data to disk requires much more similar operations which will be done by OS, therefore this is noticeable only if data sync to persistent storage is fully disabled. libmdbx allows to safely save data to persistent storage with minimal performance overhead. If there is no need to save data to persistent storage then it's much more preferable to use
std::map.
- Massive altering of data during a parallel long read operation will increase the process work set, may exhaust entire free database space and result in subsequent write performance degradation.
libmdbx mostly solve this issue by lack-of-space callback and
MDBX_LIFORECLAIMmode. Seemdbx.hwith API description for details. The "next" version of libmdbx (MithrilDB) will completely solve this.
- There are no built-in checksums or digests to verify database integrity.
The "next" version of libmdbx (MithrilDB) will solve this issue employing Merkle Tree.
Usage
Source code embedding
libmdbx provides two official ways for integration in source code form:
- Using the amalgamated source code.
The amalgamated source code includes all files requires to build and use libmdbx, but not for testing libmdbx itself.
- Adding the complete original source code as a
git submodule.
This allows you to build as libmdbx and testing tool. On the other hand, this way requires you to pull git tags, and use C++11 compiler for test tool.
Please, avoid using any other techniques. Otherwise, at least
don't ask for support and don't name such chimeras libmdbx.
The amalgamated source code could be created from original clone of git
repository on Linux by executing make dist. As a result, the desired
set of files will be formed in the dist subdirectory.
Building
Both amalgamated and original source code provides build through the use
CMake or GNU
Make with
bash. All build ways
are completely traditional and have minimal prerequirements like
build-essential, i.e. the non-obsolete C/C++ compiler and a
SDK for the
target platform. Obviously you need building tools itself, i.e. git,
cmake or GNU make with bash.
So just use CMake or GNU Make in your habitual manner and feel free to fill an issue or make pull request in the case something will be unexpected or broken down.
DSO/DLL unloading and destructors of Thread-Local-Storage objects
When building libmdbx as a shared library or use static libmdbx as a part of another dynamic library, it is advisable to make sure that your system ensures the correctness of the call destructors of Thread-Local-Storage objects when unloading dynamic libraries.
If this is not the case, then unloading a dynamic-link library with libmdbx code inside, can result in either a resource leak or a crash due to calling destructors from an already unloaded DSO/DLL object. The problem can only manifest in a multithreaded application, which makes the unloading of shared dynamic libraries with libmdbx code inside, after using libmdbx. It is known that TLS-destructors are properly maintained in the following cases:
-
On all modern versions of Windows (Windows 7 and later).
-
On systems with the
__cxa_thread_atexit_impl()function in the standard C library, including systems with GNU libc version 2.18 and later. -
On systems with libpthread/ntpl from GNU libc with bug fixes #21031 and #21032, or where there are no similar bugs in the pthreads implementation.
Linux and other platforms with GNU Make
To build the library it is enough to execute make all in the directory
of source code, and make check for execute the basic tests.
If the make installed on the system is not GNU Make, there will be a
lot of errors from make when trying to build. In this case, perhaps you
should use gmake instead of make, or even gnu-make, etc.
FreeBSD and related platforms
As a rule, in such systems, the default is to use Berkeley Make. And GNU Make is called by the gmake command or may be missing. In addition, bash may be absent.
You need to install the required components: GNU Make, bash, C and C++
compilers compatible with GCC or CLANG. After that, to build the
library, it is enough execute gmake all (or make all) in the
directory with source code, and gmake check (or make check) to run
the basic tests.
Windows
For build libmdbx on Windows the original CMake and Microsoft Visual Studio are recommended.
Building by MinGW, MSYS or Cygwin is potentially possible. However, these scripts are not tested and will probably require you to modify the CMakeLists.txt or Makefile respectively.
It should be noted that in libmdbx was efforts to resolve
runtime dependencies from CRT and other libraries Visual Studio.
For this is enough define the MDBX_AVOID_CRT during build.
An example of running a basic test script can be found in the CI-script for AppVeyor. To run the long stochastic test scenario, bash is required, and the such testing is recommended with place the test data on the RAM-disk.
MacOS
Current native build tools for
MacOS include GNU Make, CLANG and an outdated version of bash.
Therefore, to build the library, it is enough to run make all in the
directory with source code, and run make check to execute the base
tests. If something goes wrong, it is recommended to install
Homebrew and try again.
To run the long stochastic test scenario, you
will need to install the current (not outdated) version of
bash. To do this, we
recommend that you install Homebrew and then execute
brew install bash.
Bindings
| Runtime | GitHub | Author |
|---|---|---|
| Java | mdbxjni | Castor Technologies |
| .NET | mdbx.NET | Jerry Wang |
Performance comparison
All benchmarks were done by IOArena and multiple scripts runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz, 8 Gb RAM, SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
Integral performance
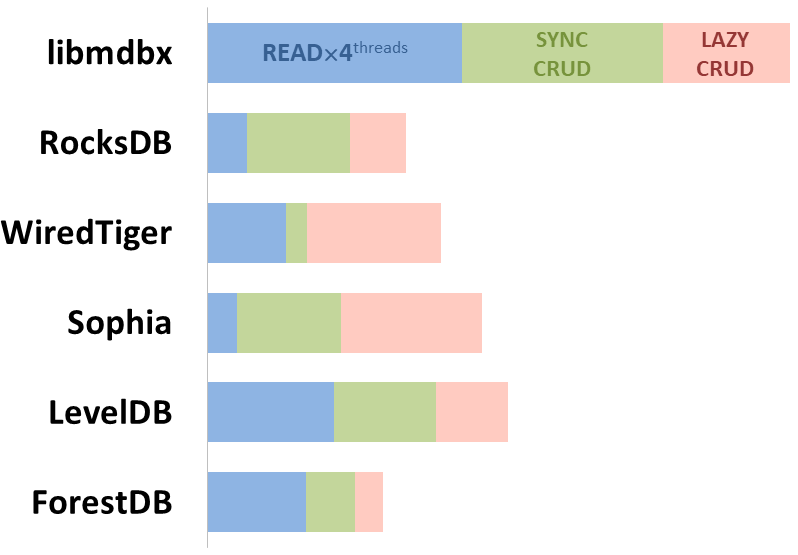
Here showed sum of performance metrics in 3 benchmarks:
-
Read/Search on 4 CPU cores machine;
-
Transactions with CRUD operations in sync-write mode (fdatasync is called after each transaction);
-
Transactions with CRUD operations in lazy-write mode (moment to sync data to persistent storage is decided by OS).
Reasons why asynchronous mode isn't benchmarked here:
-
It doesn't make sense as it has to be done with DB engines, oriented for keeping data in memory e.g. Tarantool, Redis), etc.
-
Performance gap is too high to compare in any meaningful way.
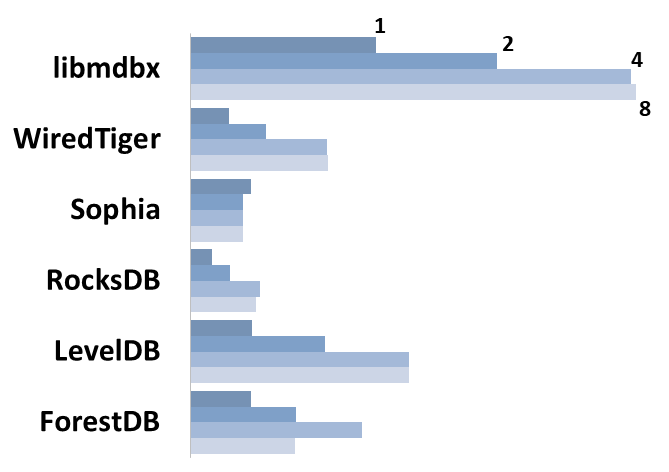
Read Scalability
Summary performance with concurrent read/search queries in 1-2-4-8 threads on 4 CPU cores machine.
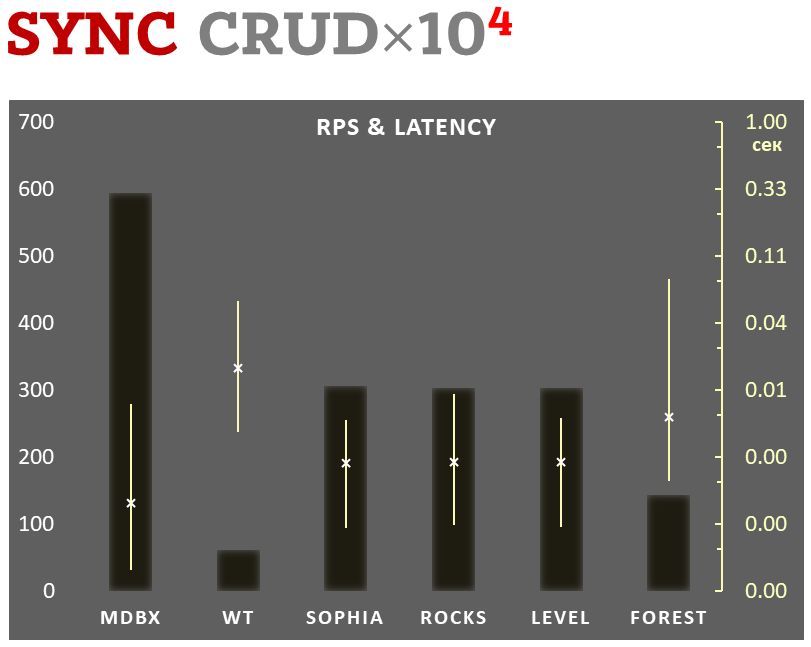
Sync-write mode
-
Linear scale on left and dark rectangles mean arithmetic mean transactions per second;
-
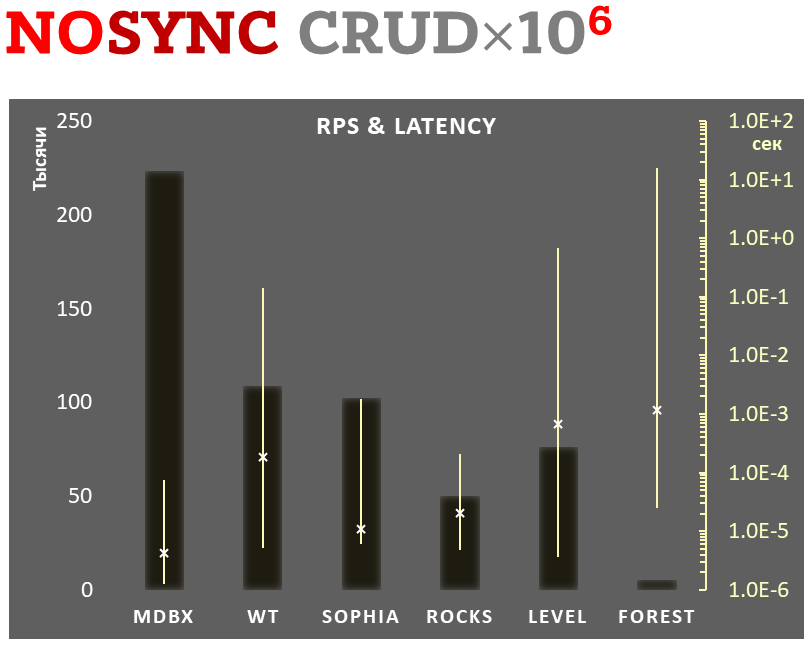
Logarithmic scale on right is in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
10,000 transactions in sync-write mode. In case of a crash all data is consistent and state is right after last successful transaction. fdatasync syscall is used after each write transaction in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
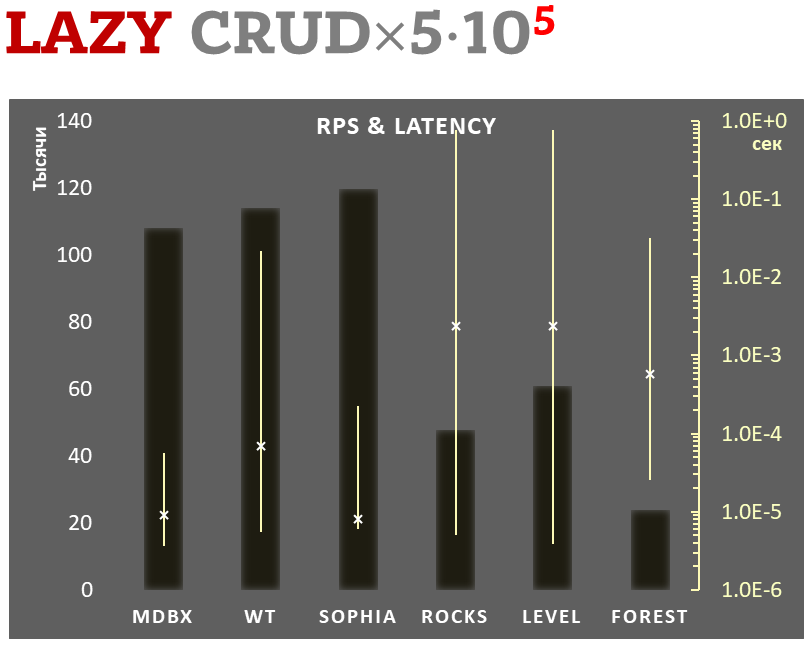
Lazy-write mode
-
Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
-
Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
100,000 transactions in lazy-write mode. In case of a crash all data is consistent and state is right after one of last transactions, but transactions after it will be lost. Other DB engines use WAL or transaction journal for that, which in turn depends on order of operations in journaled filesystem. libmdbx doesn't use WAL and hands I/O operations to filesystem and OS kernel (mmap).
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database and after full run the database contains 100,000 small key-value records.
Async-write mode
-
Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
-
Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
1,000,000 transactions in async-write mode. In case of a crash all data will be consistent and state will be right after one of last transactions, but lost transaction count is much higher than in lazy-write mode. All DB engines in this mode do as little writes as possible on persistent storage. libmdbx uses msync(MS_ASYNC) in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
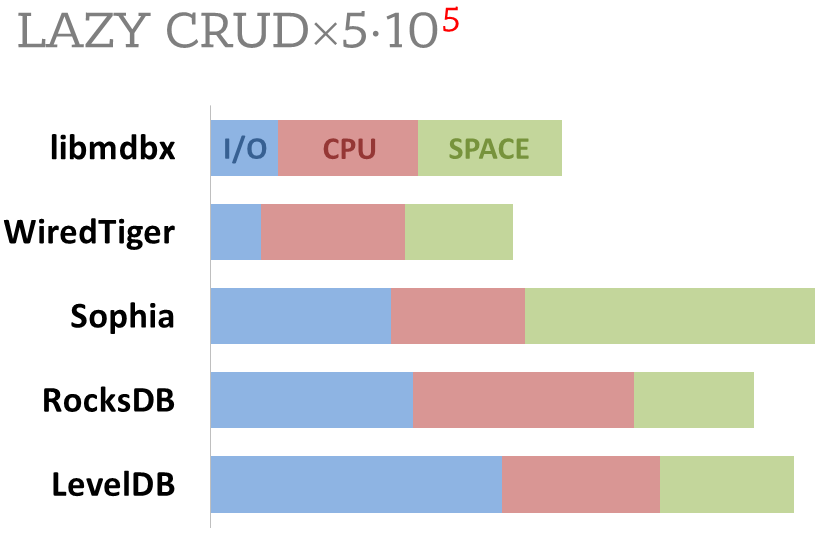
Cost comparison
Summary of used resources during lazy-write mode benchmarks:
-
Read and write IOPS;
-
Sum of user CPU time and sys CPU time;
-
Used space on persistent storage after the test and closed DB, but not waiting for the end of all internal housekeeping operations (LSM compactification, etc).
ForestDB is excluded because benchmark showed it's resource consumption for each resource (CPU, IOPS) much higher than other engines which prevents to meaningfully compare it with them.
All benchmark data is gathered by getrusage() syscall and by scanning data directory.
$ objdump -f -h -j .text libmdbx.so
libmdbx.so: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000150:
HAS_SYMS, DYNAMIC, D_PAGED
start address 0x0000000000003710
Sections:
Idx Name Size VMA LMA File off Algn
11 .text 00015eff 0000000000003710 0000000000003710 00003710 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE