mirror of
https://github.com/isar/libmdbx.git
synced 2024-10-30 11:29:19 +08:00
714 lines
31 KiB
Markdown
714 lines
31 KiB
Markdown
### The [repository now only mirrored on the Github](https://abf.io/erthink/libmdbx) due to illegal discriminatory restrictions for Russian Crimea and for sovereign crimeans.
|
|
<!-- Required extensions: pymdownx.betterem, pymdownx.tilde, pymdownx.emoji, pymdownx.tasklist, pymdownx.superfences -->
|
|
-----
|
|
|
|
libmdbx
|
|
======================================
|
|
MDBX is compact, fast, powerful, and robust and implements a simplified
|
|
variant of the BerkeleyDB API. In fact _libmdbx_ is revised and extended
|
|
descendant of [Lightning Memory-Mapped
|
|
Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database)
|
|
(aka _LMDB_). Permissive non-copyleft BSD-style [OpenLDAP Public License
|
|
2.8](LICENSE). Русскоязычная версия этого README [здесь](README-RU.md).
|
|
|
|
_libmdbx_ is superior to LMDB in terms of features and reliability, not
|
|
inferior in performance. In comparison to LMDB, _libmdbx_ makes many
|
|
things just work perfectly, not silently and catastrophically break
|
|
down. _libmdbx_ supports Linux, Windows, MacOS, FreeBSD and other
|
|
systems compliant with POSIX.1-2008.
|
|
|
|
The next version is under active non-public development and will be
|
|
released as **_MithrilDB_** and `libmithrildb` for libraries & packages.
|
|
Admittedly mythical [Mithril](https://en.wikipedia.org/wiki/Mithril) is
|
|
resembling silver but being stronger and lighter than steel. Therefore
|
|
_MithrilDB_ is rightly relevant name.
|
|
|
|
_MithrilDB_ will be radically different from _libmdbx_ by the new
|
|
database format and API based on C++17, as well as the [Apache 2.0
|
|
License](https://www.apache.org/licenses/LICENSE-2.0). The goal of this
|
|
revolution is to provide a clearer and robust API, add more features and
|
|
new valuable properties of database.
|
|
|
|
*The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо.*
|
|
|
|
[](https://travis-ci.org/leo-yuriev/libmdbx)
|
|
[](https://ci.appveyor.com/project/leo-yuriev/libmdbx/branch/master)
|
|
[](https://scan.coverity.com/projects/reopen-libmdbx)
|
|
|
|
## Table of Contents
|
|
- [Overview](#overview)
|
|
- [Comparison with other databases](#comparison-with-other-databases)
|
|
- [History & Acknowledgments](#history)
|
|
- [Description](#description)
|
|
- [Key features](#key-features)
|
|
- [Improvements over LMDB](#improvements-over-lmdb)
|
|
- [Gotchas](#gotchas)
|
|
- [Problem of long-time reading](#problem-of-long-time-reading)
|
|
- [Durability in asynchronous writing mode](#durability-in-asynchronous-writing-mode)
|
|
- [Usage](#usage)
|
|
- [Building](#building)
|
|
- [Bindings](#bindings)
|
|
- [Performance comparison](#performance-comparison)
|
|
- [Integral performance](#integral-performance)
|
|
- [Read scalability](#read-scalability)
|
|
- [Sync-write mode](#sync-write-mode)
|
|
- [Lazy-write mode](#lazy-write-mode)
|
|
- [Async-write mode](#async-write-mode)
|
|
- [Cost comparison](#cost-comparison)
|
|
|
|
-----
|
|
|
|
## Overview
|
|
_libmdbx_ is an embedded lightweight key-value database engine oriented
|
|
for performance.
|
|
|
|
_libmdbx_ allows multiple processes to read and update several key-value
|
|
tables concurrently, while being
|
|
[ACID](https://en.wikipedia.org/wiki/ACID)-compliant, with minimal
|
|
overhead and Olog(N) operation cost.
|
|
|
|
_libmdbx_ enforce
|
|
[serializability](https://en.wikipedia.org/wiki/Serializability) for
|
|
writers by single
|
|
[mutex](https://en.wikipedia.org/wiki/Mutual_exclusion) and affords
|
|
[wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom)
|
|
for parallel readers without atomic/interlocked operations, while
|
|
writing and reading transactions do not block each other.
|
|
|
|
_libmdbx_ can guarantee consistency after crash depending of operation
|
|
mode.
|
|
|
|
_libmdbx_ uses [B+Trees](https://en.wikipedia.org/wiki/B%2B_tree) and
|
|
[Memory-Mapping](https://en.wikipedia.org/wiki/Memory-mapped_file),
|
|
doesn't use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging)
|
|
which might be a caveat for some workloads.
|
|
|
|
### Comparison with other databases
|
|
For now please refer to [chapter of "BoltDB comparison with other
|
|
databases"](https://github.com/coreos/bbolt#comparison-with-other-databases)
|
|
which is also (mostly) applicable to MDBX.
|
|
|
|
### History
|
|
The _libmdbx_ design is based on [Lightning Memory-Mapped
|
|
Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
|
Initial development was going in
|
|
[ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project. About a
|
|
year later libmdbx was isolated to separate project, which was
|
|
[presented at Highload++ 2015
|
|
conference](http://www.highload.ru/2015/abstracts/1831.html).
|
|
|
|
Since early 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/leo-yuriev/libfpta),
|
|
and development is funded by [Positive Technologies](https://www.ptsecurity.com).
|
|
|
|
### Acknowledgments
|
|
Howard Chu <hyc@openldap.org> is the author of LMDB, from which
|
|
originated the MDBX in 2015.
|
|
|
|
Martin Hedenfalk <martin@bzero.se> is the author of `btree.c` code, which
|
|
was used for begin development of LMDB.
|
|
|
|
-----
|
|
|
|
Description
|
|
===========
|
|
|
|
## Key features
|
|
|
|
_libmdbx_ inherits all features and characteristics from
|
|
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database):
|
|
|
|
1. Key-value pairs are stored in ordered map(s), keys are always sorted,
|
|
range lookups are supported.
|
|
|
|
2. Data is [memory-mapped](https://en.wikipedia.org/wiki/Memory-mapped_file)
|
|
into each worker DB process, and could be accessed zero-copy from transactions.
|
|
|
|
3. Transactions are
|
|
[ACID](https://en.wikipedia.org/wiki/ACID)-compliant, through to
|
|
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control)
|
|
and [CoW](https://en.wikipedia.org/wiki/Copy-on-write). Writes are
|
|
strongly serialized and aren't blocked by reads, transactions can't
|
|
conflict with each other. Reads are guaranteed to get only commited data
|
|
([relaxing serializability](https://en.wikipedia.org/wiki/Serializability#Relaxing_serializability)).
|
|
|
|
4. Read transactions are
|
|
[non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm),
|
|
don't use [atomic operations](https://en.wikipedia.org/wiki/Linearizability#High-level_atomic_operations).
|
|
Readers don't block each other and aren't blocked by writers. Read
|
|
performance scales linearly with CPU core count.
|
|
> Nonetheless, "connect to DB" (starting the first read transaction in a thread) and
|
|
> "disconnect from DB" (closing DB or thread termination) requires a lock
|
|
> acquisition to register/unregister at the "readers table".
|
|
|
|
5. Keys with multiple values are stored efficiently without key
|
|
duplication, sorted by value, including integers (valuable for
|
|
secondary indexes).
|
|
|
|
6. Efficient operation on short fixed length keys,
|
|
including 32/64-bit integer types.
|
|
|
|
7. [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
|
Amplification Factor) и RAF (Read Amplification Factor) are Olog(N).
|
|
|
|
8. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) and
|
|
transaction journal. In case of a crash no recovery needed. No need for
|
|
regular maintenance. Backups can be made on the fly on working DB
|
|
without freezing writers.
|
|
|
|
9. No additional memory management, all done by basic OS services.
|
|
|
|
|
|
## Improvements over LMDB
|
|
|
|
1. Automatic dynamic DB size management according to the parameters
|
|
specified by `mdbx_env_set_geometry()` function. Including
|
|
growth step and truncation threshold, as well as the choice of page
|
|
size.
|
|
|
|
2. Automatic returning of freed pages into unallocated space at the end
|
|
of database file, with optionally automatic shrinking it. This reduces
|
|
amount of pages resides in RAM and circulated in disk I/O. In fact
|
|
_libmdbx_ constantly performs DB compactification, without spending
|
|
additional resources for that.
|
|
|
|
3. `LIFO RECLAIM` mode:
|
|
|
|
The newest pages are picked for reuse instead of the oldest. This allows
|
|
to minimize reclaim loop and make it execution time independent of total
|
|
page count.
|
|
|
|
This results in OS kernel cache mechanisms working with maximum
|
|
efficiency. In case of using disk controllers or storages with
|
|
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration)
|
|
this may greatly improve write performance.
|
|
|
|
4. Fast estimation of range query result size via functions
|
|
`mdbx_estimate_range()`, `mdbx_estimate_move()` and
|
|
`mdbx_estimate_distance()`. E.g. for selection the optimal query
|
|
execution plan.
|
|
|
|
5. `mdbx_chk` tool for DB integrity check.
|
|
|
|
6. Support for keys and values of zero length, including multi-values
|
|
(aka sorted duplicates).
|
|
|
|
7. Ability to assign up to 3 persistent 64-bit markers to commiting
|
|
transaction with `mdbx_canary_put()` and then get them in read
|
|
transaction by `mdbx_canary_get()`.
|
|
|
|
8. Ability to update or delete record and get previous value via
|
|
`mdbx_replace()`. Also allows update the specific item from multi-value
|
|
with the same key.
|
|
|
|
9. Sequence generation via `mdbx_dbi_sequence()`.
|
|
|
|
10. `OOM-KICK` callback.
|
|
|
|
`mdbx_env_set_oomfunc()` allows to set a callback, which will be called
|
|
in the event of DB space exhausting during long-time read transaction in
|
|
parallel with extensive updating. Callback will be invoked with PID and
|
|
pthread_id of offending thread as parameters. Callback can do any of
|
|
these things to remedy the problem:
|
|
|
|
* wait for read transaction to finish normally;
|
|
|
|
* kill the offending process (signal 9), if separate process is doing
|
|
long-time read;
|
|
|
|
* abort or restart offending read transaction if it's running in sibling
|
|
thread;
|
|
|
|
* abort current write transaction with returning error code.
|
|
|
|
11. Ability to open DB in exclusive mode by `MDBX_EXCLUSIVE` flag.
|
|
|
|
12. Ability to get how far current read-transaction snapshot lags
|
|
from the latest version of the DB by `mdbx_txn_straggler()`.
|
|
|
|
13. Ability to explicitly update the existing record, not insertion
|
|
a new one. Implemented as `MDBX_CURRENT` flag for `mdbx_put()`.
|
|
|
|
14. Fixed `mdbx_cursor_count()`, which returns correct count of
|
|
duplicated (aka multi-value) for all cases and any cursor position.
|
|
|
|
15. `mdbx_env_info()` to getting additional info, including number of
|
|
the oldest snapshot of DB, which is used by someone of the readers.
|
|
|
|
16. `mdbx_del()` doesn't ignore additional argument (specifier) `data`
|
|
for tables without duplicates (without flag `MDBX_DUPSORT`), if `data`
|
|
is not null then always uses it to verify record, which is being
|
|
deleted.
|
|
|
|
17. Ability to open dbi-table with simultaneous with race-free setup
|
|
of comparators for keys and values, via `mdbx_dbi_open_ex()`.
|
|
|
|
18. `mdbx_is_dirty()`to find out if given key or value is on dirty page, that
|
|
useful to avoid copy-out before updates.
|
|
|
|
19. Correct update of current record in `MDBX_CURRENT` mode of
|
|
`mdbx_cursor_put()`, including sorted duplicated.
|
|
|
|
20. Check if there is a row with data after current cursor position via
|
|
`mdbx_cursor_eof()`.
|
|
|
|
21. Additional error code `MDBX_EMULTIVAL`, which is returned by
|
|
`mdbx_put()` and `mdbx_replace()` in case is ambiguous update or delete.
|
|
|
|
22. Ability to get value by key and duplicates count by `mdbx_get_ex()`.
|
|
|
|
23. Functions `mdbx_cursor_on_first()` and `mdbx_cursor_on_last()`,
|
|
which allows to check cursor is currently on first or last position
|
|
respectively.
|
|
|
|
24. Automatic creation of steady commit-points (flushing data to the
|
|
disk) when the volume of changes reaches a threshold, which can be
|
|
set by `mdbx_env_set_syncbytes()`.
|
|
|
|
25. Control over debugging and receiving of debugging messages via
|
|
`mdbx_setup_debug()`.
|
|
|
|
26. Function `mdbx_env_pgwalk()` for page-walking the DB.
|
|
|
|
27. Three meta-pages instead of two, that allows to guarantee
|
|
consistency of data when updating weak commit-points without the
|
|
risk of damaging the last steady commit-point.
|
|
|
|
28. Guarantee of DB integrity in `WRITEMAP+MAPSYNC` mode:
|
|
> Current _libmdbx_ gives a choice of safe async-write mode (default)
|
|
> and `UTTERLY_NOSYNC` mode which may result in full
|
|
> DB corruption during system crash as with LMDB. For details see
|
|
> [Data safety in async-write mode](#data-safety-in-async-write-mode).
|
|
|
|
29. Ability to close DB in "dirty" state (without data flush and
|
|
creation of steady synchronization point) via `mdbx_env_close_ex()`.
|
|
|
|
30. If read transaction is aborted via `mdbx_txn_abort()` or
|
|
`mdbx_txn_reset()` then DBI-handles, which were opened during it,
|
|
will not be closed or deleted. In several cases this allows
|
|
to avoid hard-to-debug errors.
|
|
|
|
31. All cursors in all read and write transactions can be reused by
|
|
`mdbx_cursor_renew()` and MUST be freed explicitly.
|
|
> ## Caution, please pay attention!
|
|
>
|
|
> This is the only change of API, which changes semantics of cursor management
|
|
> and can lead to memory leaks on misuse. This is a needed change as it eliminates ambiguity
|
|
> which helps to avoid such errors as:
|
|
> - use-after-free;
|
|
> - double-free;
|
|
> - memory corruption and segfaults.
|
|
|
|
|
|
32. On **Mac OS X** the `fcntl(F_FULLFSYNC)` syscall is used _by
|
|
default_ to synchronize data with the disk, as this is [the only way to
|
|
guarantee data
|
|
durability](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man2/fsync.2.html)
|
|
in case of power failure. Unfortunately, in scenarios with high write
|
|
intensity, the use of `F_FULLFSYNC` significant degrades performance
|
|
compared to LMDB, where the `fsync()` syscall is used. Therefore,
|
|
_libmdbx_ allows you to override this behavior by defining the
|
|
`MDBX_OSX_SPEED_INSTEADOF_DURABILITY=1` option while build the library.
|
|
|
|
33. On **Windows** the `LockFileEx()` syscall is used for locking, since
|
|
it allows place the database on network drives, and provides protection
|
|
against incompetent user actions (aka
|
|
[poka-yoke](https://en.wikipedia.org/wiki/Poka-yoke)). Therefore
|
|
_libmdbx_ may be a little lag in performance tests from LMDB where a
|
|
named mutexes are used.
|
|
|
|
|
|
## Gotchas
|
|
|
|
1. There cannot be more than one writer at a time. This allows serialize an
|
|
updates and eliminate any possibility of conflicts, deadlocks or logical errors.
|
|
|
|
2. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) means
|
|
relatively big [WAF](https://en.wikipedia.org/wiki/Write_amplification)
|
|
(Write Amplification Factor). Because of this syncing data to disk might
|
|
be quite resource intensive and be main performance bottleneck during
|
|
intensive write workload.
|
|
> As compromise _libmdbx_ allows several modes of lazy and/or periodic
|
|
> syncing, including `MAPASYNC` mode, which modificate data in memory and
|
|
> asynchronously syncs data to disk, moment to sync is picked by OS.
|
|
>
|
|
> Although this should be used with care, synchronous transactions in a DB
|
|
> with transaction journal will require 2 IOPS minimum (probably 3-4 in
|
|
> practice) because of filesystem overhead, overhead depends on
|
|
> filesystem, not on record count or record size. In _libmdbx_ IOPS count
|
|
> will grow logarithmically depending on record count in DB (height of B+
|
|
> tree) and will require at least 2 IOPS per transaction too.
|
|
|
|
3. [CoW](https://en.wikipedia.org/wiki/Copy-on-write) for
|
|
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control)
|
|
is done on memory page level with
|
|
[B+trees](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
|
Therefore altering data requires to copy about Olog(N) memory pages,
|
|
which uses [memory bandwidth](https://en.wikipedia.org/wiki/Memory_bandwidth) and is main
|
|
performance bottleneck in `MAPASYNC` mode.
|
|
> This is unavoidable, but isn't that bad. Syncing data to disk requires
|
|
> much more similar operations which will be done by OS, therefore this is
|
|
> noticeable only if data sync to persistent storage is fully disabled.
|
|
> _libmdbx_ allows to safely save data to persistent storage with minimal
|
|
> performance overhead. If there is no need to save data to persistent
|
|
> storage then it's much more preferable to use `std::map`.
|
|
|
|
|
|
4. _LMDB_ has a problem of long-time readers which degrades performance
|
|
and bloats DB.
|
|
> _libmdbx_ addresses that, details below.
|
|
|
|
5. _LMDB_ is susceptible to DB corruption in `WRITEMAP+MAPASYNC` mode.
|
|
_libmdbx_ in `WRITEMAP+MAPASYNC` guarantees DB integrity and consistency
|
|
of data.
|
|
> Additionally there is an alternative: `UTTERLY_NOSYNC` mode.
|
|
> Details below.
|
|
|
|
|
|
### Problem of long-time reading
|
|
Garbage collection problem exists in all databases one way or another
|
|
(e.g. VACUUM in PostgreSQL). But in _libmdbx_ and LMDB it's even more
|
|
discernible because of high transaction rate and intentional internals
|
|
simplification in favor of performance.
|
|
|
|
Understanding the problem requires some explanation, but can be
|
|
difficult for quick perception. So is is reasonable
|
|
to simplify this as follows:
|
|
|
|
* Massive altering of data during a parallel long read operation may
|
|
exhaust the free DB space.
|
|
|
|
* If the available space is exhausted, any attempt to update the data
|
|
will cause a "MAP_FULL" error until a long read transaction is
|
|
completed.
|
|
|
|
* A good example of long readers is a hot backup or debugging of
|
|
a client application while retaining an active read transaction.
|
|
|
|
* In _LMDB_ this results in degraded performance of all operations of
|
|
writing data to persistent storage.
|
|
|
|
* _libmdbx_ has the `OOM-KICK` mechanism which allow to abort such
|
|
operations and the `LIFO RECLAIM` mode which addresses performance
|
|
degradation.
|
|
|
|
### Durability in asynchronous writing mode
|
|
In `WRITEMAP+MAPSYNC` mode updated (aka dirty) pages are written to
|
|
persistent storage by the OS kernel. This means that if the application
|
|
fails, the OS kernel will finish writing all updated data to disk and
|
|
nothing will be lost. However, in the case of hardware malfunction or OS
|
|
kernel fatal error, only some updated data can be written to disk and
|
|
the database structure is likely to be destroyed. In such situation, DB
|
|
is completely corrupted and can't be repaired.
|
|
|
|
_libmdbx_ addresses this by fully reimplementing write path of data:
|
|
|
|
* In `WRITEMAP+MAPSYNC` mode meta-data pages aren't updated in place,
|
|
instead their shadow copies are used and their updates are synced after
|
|
data is flushed to disk.
|
|
|
|
* During transaction commit _libmdbx_ marks it as a steady or weak
|
|
depending on synchronization status between RAM and persistent storage.
|
|
For instance, in the `WRITEMAP+MAPSYNC` mode committed transactions
|
|
are marked as weak by default, but as steady after explicit data flushes.
|
|
|
|
* _libmdbx_ maintains three separate meta-pages instead of two. This
|
|
allows to commit transaction as steady or weak without losing two
|
|
previous commit points (one of them can be steady, and another
|
|
weak). Thus, after a fatal system failure, it will be possible to
|
|
rollback to the last steady commit point.
|
|
|
|
* During DB open _libmdbx_ rollbacks to the last steady commit point,
|
|
this guarantees database integrity after a crash. However, if the
|
|
database opening in read-only mode, such rollback cannot be performed
|
|
which will cause returning the MDBX_WANNA_RECOVERY error.
|
|
|
|
For data integrity a pages which form database snapshot with steady
|
|
commit point, must not be updated until next steady commit point.
|
|
Therefore the last steady commit point creates an effect analogues to
|
|
"long-time read". The only difference that now in case of space
|
|
exhaustion the problem will be immediately addressed by writing changes
|
|
to disk and forming the new steady commit point.
|
|
|
|
So in async-write mode _libmdbx_ will always use new pages until the
|
|
free DB space will be exhausted or `mdbx_env_sync()` will be invoked,
|
|
and the total write traffic to the disk will be the same as in
|
|
sync-write mode.
|
|
|
|
Currently libmdbx gives a choice between a safe async-write mode
|
|
(default) and `UTTERLY_NOSYNC` mode which may lead to DB corruption
|
|
after a system crash, i.e. like the LMDB.
|
|
|
|
Next version of _libmdbx_ will be automatically create steady commit
|
|
points in async-write mode upon completion transfer data to the disk.
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
Usage
|
|
=====
|
|
|
|
## Building
|
|
|
|
To build on all platforms except Windows the prerequirements are the
|
|
same: non-obsolete versions of GNU Make,
|
|
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)), C and C++
|
|
compilers compatible with GCC or CLANG. On Windows you will need only :
|
|
Microsoft Visual Studio 2015 or later, Windows SDK for Windows 8 or
|
|
later.
|
|
|
|
Historically, the libmdbx builing is based on single
|
|
[Makefile](https://en.wikipedia.org/wiki/Makefile) which assumes
|
|
different recipes depending on target platform. In the next versions, it
|
|
is planned to switch to [CMake](https://en.wikipedia.org/wiki/CMake),
|
|
with the refusal to support other tools.
|
|
|
|
#### DSO/DLL unloading and destructors of Thread-Local-Storage objects
|
|
When building _libmdbx_ as a shared library or use static _libmdbx_ as a
|
|
part of another dynamic library, it is advisable to make sure that your
|
|
system ensures the correctness of the call destructors of
|
|
Thread-Local-Storage objects when unloading dynamic libraries'.
|
|
|
|
If this is not the case, then unloading a dynamic-link library with
|
|
_libmdbx_ code inside, can result in either a resource leak or a crash
|
|
due to calling destructors from an already unloaded DSO/DLL object. The
|
|
problem can only manifest in a multithreaded application, which makes
|
|
the unloading of shared dynamic libraries with _libmdbx_ code inside,
|
|
after using _libmdbx_. It is known that TLS-destructors are properly
|
|
maintained in the following cases:
|
|
|
|
- On all modern versions of Windows (Windows 7 and later).
|
|
|
|
- On systems with the
|
|
[`__cxa_thread_atexit_impl()`](https://sourceware.org/glibc/wiki/Destructor%20support%20for%20thread_local%20variables)
|
|
function in the standard C library, including systems with GNU libc
|
|
version 2.18 and later.
|
|
|
|
- On systems with libpthread/ntpl from GNU libc with bug fixes
|
|
[#21031](https://sourceware.org/bugzilla/show_bug.cgi?id=21031) and
|
|
[#21032](https://sourceware.org/bugzilla/show_bug.cgi?id=21032), or
|
|
where there are no similar bugs in the pthreads implementation.
|
|
|
|
### Linux and other platforms with GNU Make
|
|
To build the library it is enough to execute `make all` in the directory
|
|
of source code, and `make check` for execute the basic tests.
|
|
|
|
If the `make` installed on the system is not GNU Make, there will be a
|
|
lot of errors from make when trying to build. In this case, perhaps you
|
|
should use `gmake` instead of `make`, or even `gnu-make`, etc.
|
|
|
|
### FreeBSD and related platforms
|
|
As a rule, in such systems, the default is to use Berkeley Make. And GNU
|
|
Make is called by the gmake command or may be missing. In addition,
|
|
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) may be absent.
|
|
|
|
You need to install the required components: GNU Make, bash, C and C++
|
|
compilers compatible with GCC or CLANG. After that, to build the
|
|
library, it is enough execute `gmake all` (or `make all`) in the
|
|
directory with source code, and `gmake check` (or `make check`) to run
|
|
the basic tests.
|
|
|
|
### Windows
|
|
For building _libmdbx_ on Windows the [Microsoft Visual
|
|
Studio](https://en.wikipedia.org/wiki/Microsoft_Visual_Studio) is
|
|
recommended, but not tools such as MinGW, MSYS, or Cygwin. To do this,
|
|
the libmdbx source code includes the set of appropriate project files
|
|
that are compatible with Visual Studio 2015, the Windows SDK for Windows
|
|
8.1, and later. Just open `mdbx.sln` in Visual Studio and build the
|
|
library.
|
|
|
|
To build with newer versions of the SDK or Visual Studio, it should be
|
|
sufficient to execute "Retarget solution". To build for older versions
|
|
of Windows (such as Windows XP) or by older compilers, you will need to
|
|
convert or recreate the corresponding project files yourself.
|
|
|
|
Building by MinGW, MSYS or Cygwin is potentially possible. However,
|
|
these scripts are not tested and will probably require you to modify the
|
|
Makefile. It should be noted that in _libmdbx_ was efforts to resolve
|
|
runtime dependencies from CRT and other libraries Visual Studio.
|
|
For this is enough define the `MDBX_AVOID_CRT` during build.
|
|
|
|
An example of running a basic test script can be found in the
|
|
[CI-script](appveyor.yml) for [AppVeyor](https://www.appveyor.com/). To
|
|
run the [long stochastic test scenario](test/long_stochastic.sh),
|
|
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) is required, and
|
|
the such testing is recommended with place the test data on the
|
|
[RAM-disk](https://en.wikipedia.org/wiki/RAM_drive).
|
|
|
|
### MacOS X
|
|
Current [native build tools](https://en.wikipedia.org/wiki/Xcode) for
|
|
MacOS X include GNU Make, CLANG and an outdated version of bash.
|
|
Therefore, to build the library, it is enough to run `make all` in the
|
|
directory with source code, and run `make check` to execute the base
|
|
tests. If something goes wrong, it is recommended to install
|
|
[Homebrew](https://brew.sh/) and try again.
|
|
|
|
To run the [long stochastic test scenario](test/long_stochastic.sh), you
|
|
will need to install the current (not outdated) version of
|
|
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)). To do this, we
|
|
recommend that you install [Homebrew](https://brew.sh/) and then execute
|
|
`brew install bash`.
|
|
|
|
## Bindings
|
|
|
|
| Runtime | GitHub | Author |
|
|
| -------- | ------ | ------ |
|
|
| Java | [mdbxjni](https://github.com/castortech/mdbxjni) | [Castor Technologies](https://castortech.com/) |
|
|
| .NET | [mdbx.NET](https://github.com/wangjia184/mdbx.NET) | [Jerry Wang](https://github.com/wangjia184) |
|
|
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
Performance comparison
|
|
======================
|
|
|
|
All benchmarks were done by [IOArena](https://github.com/pmwkaa/ioarena)
|
|
and multiple [scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015)
|
|
runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz, 8 Gb RAM,
|
|
SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
|
|
|
|
## Integral performance
|
|
|
|
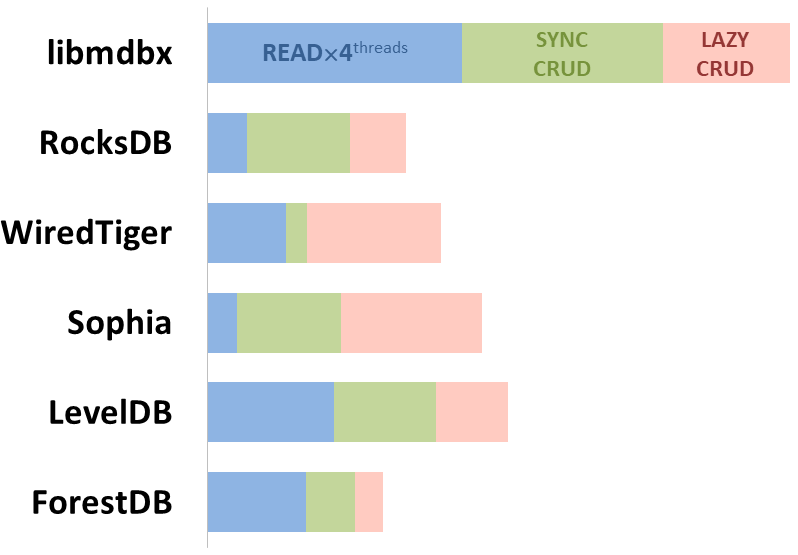
Here showed sum of performance metrics in 3 benchmarks:
|
|
|
|
- Read/Search on 4 CPU cores machine;
|
|
|
|
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD)
|
|
operations in sync-write mode (fdatasync is called after each
|
|
transaction);
|
|
|
|
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD)
|
|
operations in lazy-write mode (moment to sync data to persistent storage
|
|
is decided by OS).
|
|
|
|
*Reasons why asynchronous mode isn't benchmarked here:*
|
|
|
|
1. It doesn't make sense as it has to be done with DB engines, oriented
|
|
for keeping data in memory e.g. [Tarantool](https://tarantool.io/),
|
|
[Redis](https://redis.io/)), etc.
|
|
|
|
2. Performance gap is too high to compare in any meaningful way.
|
|
|
|
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
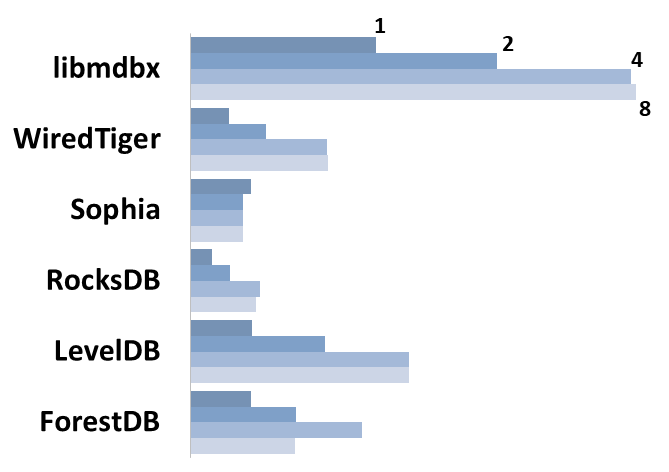
## Read Scalability
|
|
|
|
Summary performance with concurrent read/search queries in 1-2-4-8
|
|
threads on 4 CPU cores machine.
|
|
|
|
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
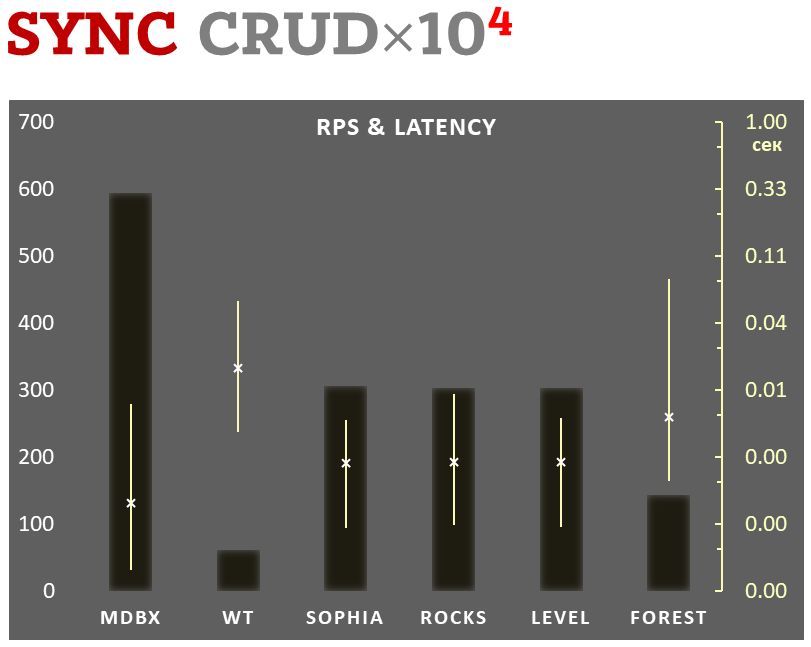
## Sync-write mode
|
|
|
|
- Linear scale on left and dark rectangles mean arithmetic mean
|
|
transactions per second;
|
|
|
|
- Logarithmic scale on right is in seconds and yellow intervals mean
|
|
execution time of transactions. Each interval shows minimal and maximum
|
|
execution time, cross marks standard deviation.
|
|
|
|
**10,000 transactions in sync-write mode**. In case of a crash all data
|
|
is consistent and state is right after last successful transaction.
|
|
[fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after
|
|
each write transaction in this mode.
|
|
|
|
In the benchmark each transaction contains combined CRUD operations (2
|
|
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
|
and after full run the database contains 10,000 small key-value records.
|
|
|
|
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
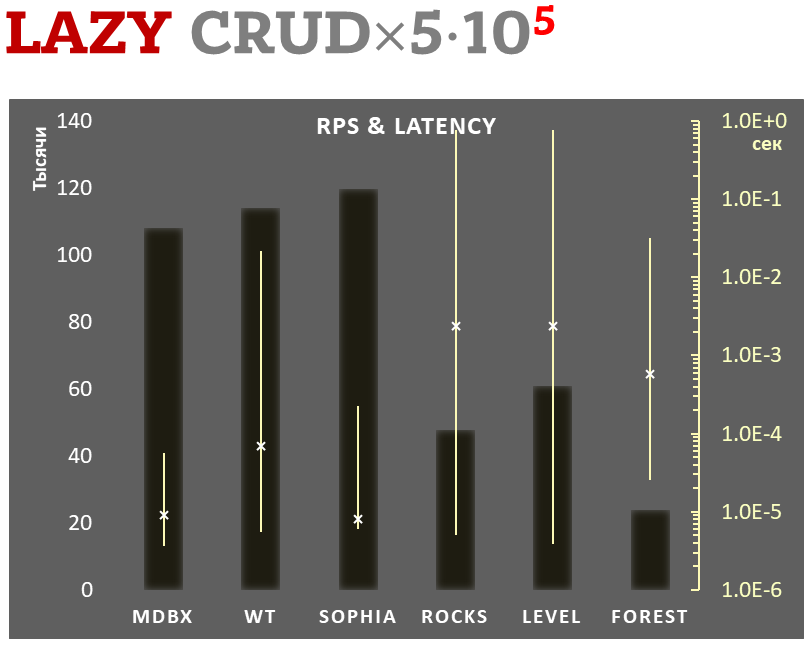
## Lazy-write mode
|
|
|
|
- Linear scale on left and dark rectangles mean arithmetic mean of
|
|
thousands transactions per second;
|
|
|
|
- Logarithmic scale on right in seconds and yellow intervals mean
|
|
execution time of transactions. Each interval shows minimal and maximum
|
|
execution time, cross marks standard deviation.
|
|
|
|
**100,000 transactions in lazy-write mode**. In case of a crash all data
|
|
is consistent and state is right after one of last transactions, but
|
|
transactions after it will be lost. Other DB engines use
|
|
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction
|
|
journal for that, which in turn depends on order of operations in
|
|
journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations
|
|
to filesystem and OS kernel (mmap).
|
|
|
|
In the benchmark each transaction contains combined CRUD operations (2
|
|
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
|
and after full run the database contains 100,000 small key-value
|
|
records.
|
|
|
|
|
|
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
## Async-write mode
|
|
|
|
- Linear scale on left and dark rectangles mean arithmetic mean of
|
|
thousands transactions per second;
|
|
|
|
- Logarithmic scale on right in seconds and yellow intervals mean
|
|
execution time of transactions. Each interval shows minimal and maximum
|
|
execution time, cross marks standard deviation.
|
|
|
|
**1,000,000 transactions in async-write mode**. In case of a crash all
|
|
data will be consistent and state will be right after one of last
|
|
transactions, but lost transaction count is much higher than in
|
|
lazy-write mode. All DB engines in this mode do as little writes as
|
|
possible on persistent storage. _libmdbx_ uses
|
|
[msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode.
|
|
|
|
In the benchmark each transaction contains combined CRUD operations (2
|
|
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
|
and after full run the database contains 10,000 small key-value records.
|
|
|
|
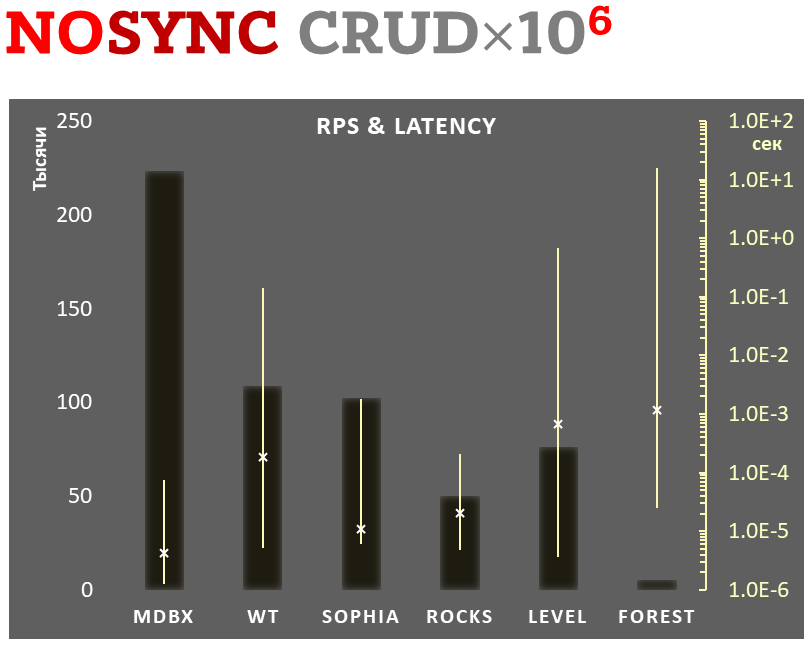
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
## Cost comparison
|
|
|
|
Summary of used resources during lazy-write mode benchmarks:
|
|
|
|
- Read and write IOPS;
|
|
|
|
- Sum of user CPU time and sys CPU time;
|
|
|
|
- Used space on persistent storage after the test and closed DB, but not
|
|
waiting for the end of all internal housekeeping operations (LSM
|
|
compactification, etc).
|
|
|
|
_ForestDB_ is excluded because benchmark showed it's resource
|
|
consumption for each resource (CPU, IOPS) much higher than other engines
|
|
which prevents to meaningfully compare it with them.
|
|
|
|
All benchmark data is gathered by
|
|
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html)
|
|
syscall and by scanning data directory.
|
|
|
|
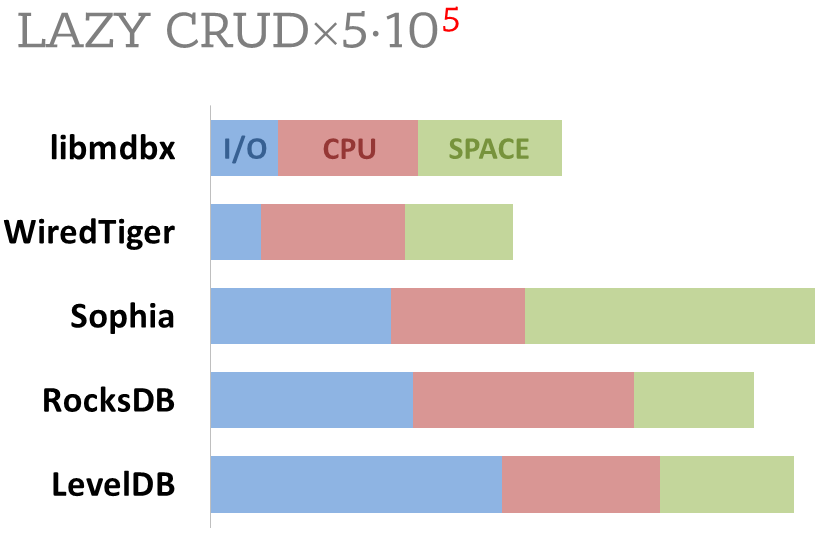
|
|
|
|
--------------------------------------------------------------------------------
|
|
|
|
```
|
|
$ objdump -f -h -j .text libmdbx.so
|
|
|
|
libmdbx.so: file format elf64-x86-64
|
|
architecture: i386:x86-64, flags 0x00000150:
|
|
HAS_SYMS, DYNAMIC, D_PAGED
|
|
start address 0x0000000000003870
|
|
|
|
Sections:
|
|
Idx Name Size VMA LMA File off Algn
|
|
11 .text 000173d4 0000000000003870 0000000000003870 00003870 2**4
|
|
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
|
|
|
```
|