libmdbx
Extended LMDB, aka "Расширенная LMDB".
The Future will Positive. Всё будет хорошо.

![]()
English version by Google and by Yandex.
Кратко
libmdbx - это встраиваемый key-value движок хранения со специфическим набором свойств и возможностей, ориентированный на создание уникальных легковесных решений с предельной производительностью.
libmdbx позволяет множеству процессов совместно читать и обновлять несколько key-value таблиц с соблюдением ACID, при минимальных накладных расходах и амортизационной стоимости любых операций Olog(N).
libmdbx обеспечивает serializability изменений и согласованность данных после аварий. При этом транзакции изменяющие данные никак не мешают операциям чтения и выполняются строго последовательно с использованием единственного мьютекса.
libmdbx позволяет выполнять операции чтения с гарантиями wait-free, параллельно на каждом ядре CPU, без использования атомарных операций и/или примитивов синхронизации.
История
libmdbx является развитием "Lightning Memory-Mapped Database", известной под аббревиатурой LMDB. Изначально доработка производилась в составе проекта ReOpenLDAP. Примерно за год работы внесенные изменения приобрели самостоятельную ценность. Осенью 2015 доработанный движок был выделен в отдельный проект, который был представлен на конференции Highload++ 2015.
В начале 2017 года движок libmdbx получил новый импульс развития, благодаря использованию в Fast Positive Tables, aka "Позитивные Таблицы" by Positive Technologies.
Характеристики и ключевые особенности
libmdbx наследует все ключевые возможности и особенности от своего прародителя LMDB, но с устранением ряда описываемых далее проблем и архитектурных недочетов.
-
Данные хранятся в упорядоченном отображении (ordered map), ключи всегда отсортированы, поддерживается выборка диапазонов (range lookups).
-
Данные отображается в память каждого работающего с БД процесса. К данным и ключам обеспечивается прямой доступ в памяти без необходимости их копирования.
-
Транзакции согласно ACID, посредством MVCC и COW. Изменения строго последовательны и не блокируются чтением, конфликты между транзакциями не возможны. При этом гарантируется чтение только зафиксированных данных, см relaxing serializability.
-
Чтение и поиск без блокировок, без атомарных операций. Читатели не блокируются операциями записи и не конкурируют между собой, чтение масштабируется линейно по ядрам CPU.
Для точности следует отметить, что "подключение к БД" (старт первой читающей транзакции в потоке) и "отключение от БД" (закрытие БД или завершение потока) требуют краткосрочного захвата блокировки для регистрации/дерегистрации текущего потока в "таблице читателей".
-
Эффективное хранение дубликатов (ключей с несколькими значениями), без дублирования ключей, с сортировкой значений, в том числе целочисленных (для вторичных индексов).
-
Эффективная поддержка коротких ключей фиксированной длины, в том числе целочисленных.
-
Амортизационная стоимость любой операции Olog(N), WAF (Write Amplification Factor) и RAF (Read Amplification Factor) также Olog(N).
-
Нет WAL и журнала транзакций, после сбоев не требуется восстановление. Не требуется компактификация или какое-либо периодическое обслуживание. Поддерживается резервное копирование "по горячему", на работающей БД без приостановки изменения данных.
-
Отсутствует какое-либо внутреннее управление памятью или кэшированием. Всё необходимое штатно выполняет ядро ОС!
Сравнение производительности
Все представленные ниже данные получены многократным прогоном тестов на ноутбуке Lenovo Carbon-2, i7-4600U 2.1 ГГц, 8 Гб ОЗУ, с SSD-диском SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Гб.
Исходный код бенчмарка IOArena и сценарии тестирования доступны на github.
Интегральная производительность
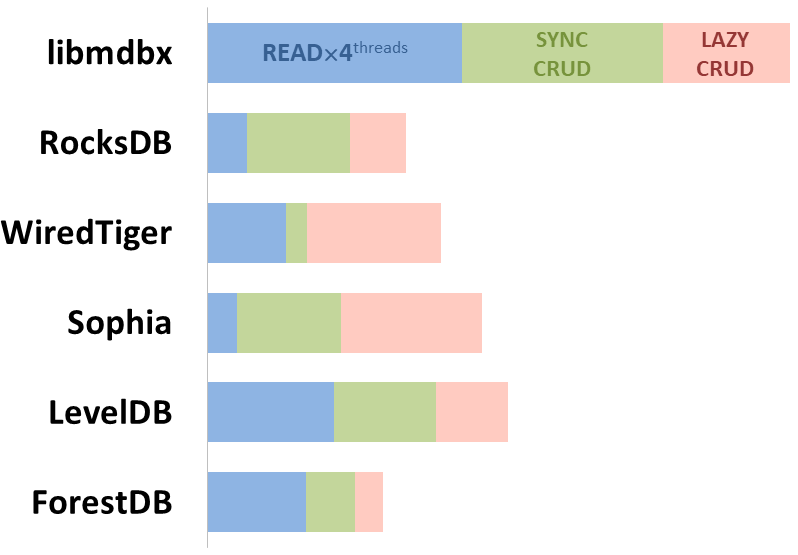
Показана соотнесенная сумма ключевых показателей производительности в трёх бенчмарках:
-
Чтение/Поиск на машине с 4-мя процессорами;
-
Транзакции с CRUD-операциями (вставка, чтение, обновление, удаление) в режиме синхронной фиксации данных (fdatasync при завершении каждой транзакции или аналог);
-
Транзакции с CRUD-операциями (вставка, чтение, обновление, удаление) в режиме отложенной фиксации данных (отложенная запись посредством файловой систем или аналог);
Бенчмарк в режиме асинхронной записи не включен по двум причинам:
-
Такое сравнение не совсем правомочно, его следует делать с движками ориентированными на хранение данных в памяти (Tarantool, Redis).
-
Превосходство libmdbx становится еще более подавляющем, что мешает восприятию информации.
Масштабируемость чтения
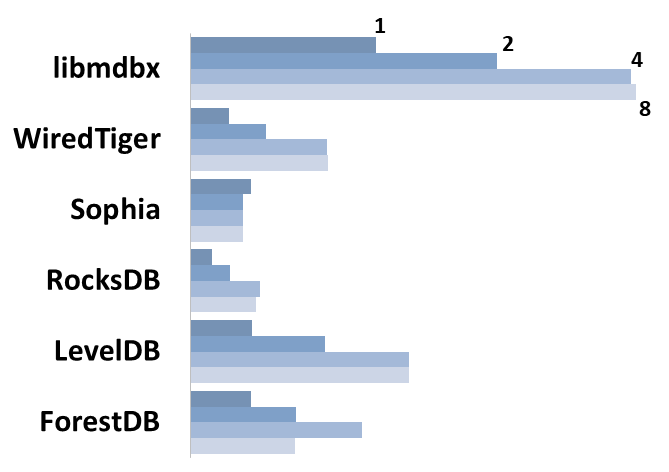
Для каждого движка показана суммарная производительность при одновременном выполнении запросов чтения/поиска в 1-2-4-8 потоков на машине с 4-мя физическими процессорами.
Синхронная фиксация
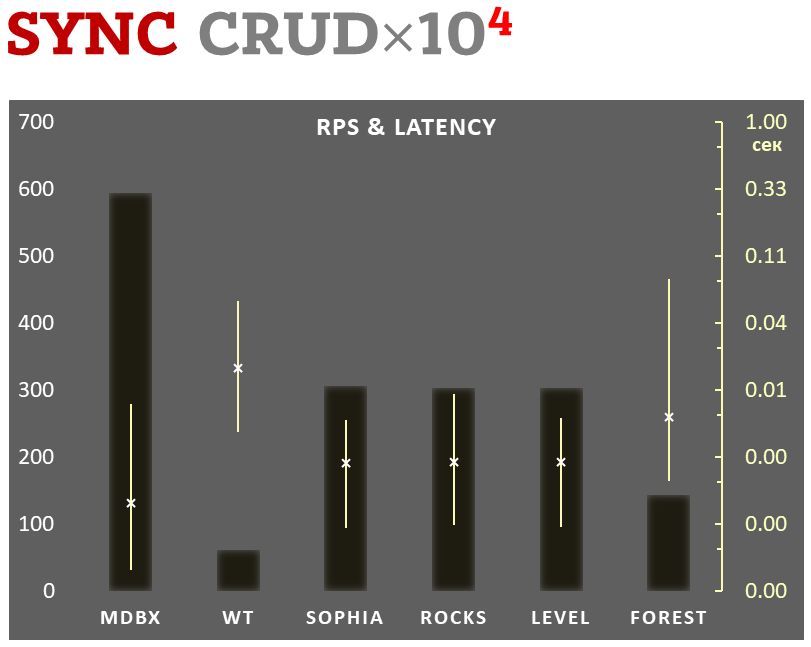
-
Линейная шкала слева и темные прямоугольники соответствуют количеству транзакций в секунду, усредненному за всё время теста.
-
Логарифмическая шкала справа и желтые интервальные отрезки соответствуют времени выполнения транзакций. При этом каждый отрезок показывает минимальное и максимальное время затраченное на выполнение транзакций, а крестиком отмечено среднеквадратичное значение.
Выполняется 10.000 транзакций в режиме синхронной фиксации данных на диске. При этом требуется гарантия, что при аварийном выключении питания (или другом подобном сбое) все данные будут консистентны и полностью соответствовать последней завершенной транзакции. В libmdbx в этом режиме при фиксации каждой транзакции выполняется системный вызов fdatasync.
В каждой транзакции выполняется комбинированная CRUD-операция (две вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует на пустой базе, а при завершении, в результате выполняемых действий, в базе насчитывается 10.000 небольших key-value записей.
Отложенная фиксация
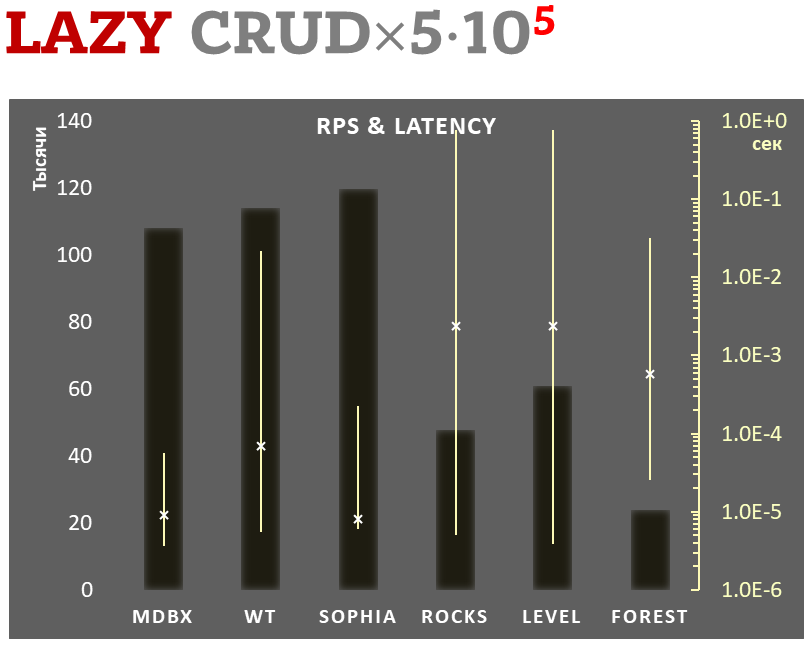
-
Линейная шкала слева и темные прямоугольники соответствуют количеству транзакций в секунду, усредненному за всё время теста.
-
Логарифмическая шкала справа и желтые интервальные отрезки соответствуют времени выполнения транзакций. При этом каждый отрезок показывает минимальное и максимальное время затраченное на выполнение транзакций, а крестиком отмечено среднеквадратичное значение.
Выполняется 100.000 транзакций в режиме отложенной фиксации данных на диске. При этом требуется гарантия, что при аварийном выключении питания (или другом подобном сбое) все данные будут консистентны на момент завершения одной из транзакций, но допускается потеря изменений из некоторого количества последних транзакций, что для многих движков предполагает включение WAL (write-ahead logging) либо журнала транзакций, который в свою очередь опирается на гарантию упорядоченности данных в журналируемой файловой системе. libmdbx при этом не ведет WAL, а передает весь контроль файловой системе и ядру ОС.
В каждой транзакции выполняется комбинированная CRUD-операция (две вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует на пустой базе, а при завершении, в результате выполняемых действий, в базе насчитывается 100.000 небольших key-value записей.
Асинхронная фиксация
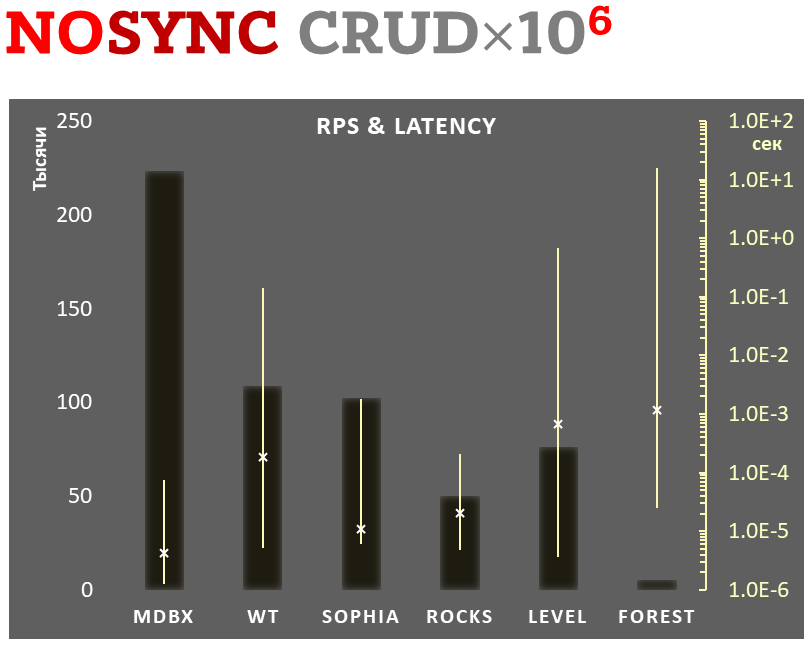
-
Линейная шкала слева и темные прямоугольники соответствуют количеству транзакций в секунду, усредненному за всё время теста.
-
Логарифмическая шкала справа и желтые интервальные отрезки соответствуют времени выполнения транзакций. При этом каждый отрезок показывает минимальное и максимальное время затраченное на выполнение транзакций, а крестиком отмечено среднеквадратичное значение.
Выполняется 1.000.000 транзакций в режиме асинхронной фиксации данных на диске. При этом требуется гарантия, что при аварийном выключении питания (или другом подобном сбое) все данные будут консистентны на момент завершения одной из транзакций, но допускается потеря изменений из значительного количества последних транзакций. Во всех движках при этом включался режим предполагающий минимальную нагрузку на диск по-записи, и соответственно минимальную гарантию сохранности данных. В libmdbx при этом используется режим асинхронной записи измененных страниц на диск посредством ядра ОС и системного вызова msync(MS_ASYNC).
В каждой транзакции выполняется комбинированная CRUD-операция (две вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует на пустой базе, а при завершении, в результате выполняемых действий, в базе насчитывается 10.000 небольших key-value записей.
Стоимость как потребление ресурсов
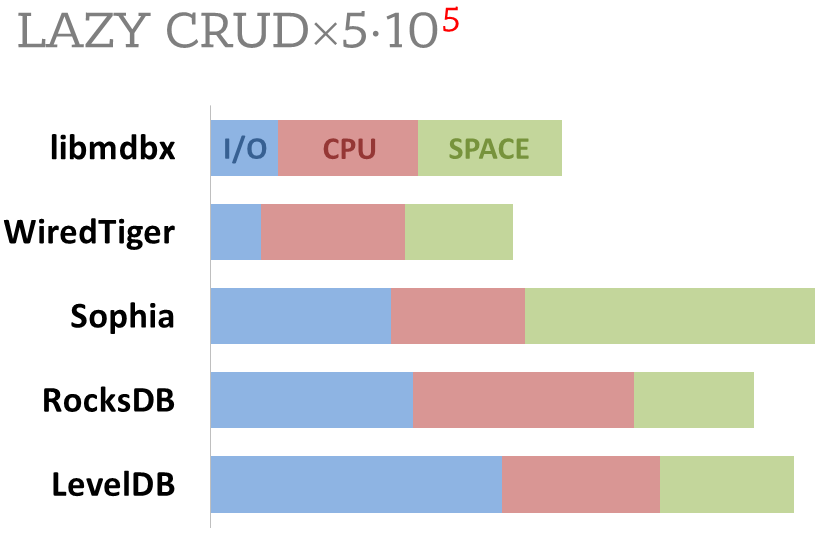
Показана соотнесенная сумма использованных ресурсов в ходе бенчмарка в режиме отложенной фиксации:
-
суммарное количество операций ввода-вывода (IOPS), как записи, так и чтения.
-
суммарное затраченное время процессора, как в режиме пользовательских процессов, так и в режиме ядра ОС.
-
использованное место на диске при завершении теста, после закрытия БД из тестирующего процесса, но без ожидания всех внутренних операций обслуживания (компактификации LSM и т.п.).
Движок ForestDB был исключен при оформлении результатов, так как относительно конкурентов многократно превысил потребление каждого из ресурсов (потратил процессорное время на генерацию IOPS для заполнения диска), что не позволяло наглядно сравнить показатели остальных движков на одной диаграмме.
Все данные собирались посредством системного вызова getrusage() и сканированием директорий с данными.
Недостатки и Компромиссы
-
Единовременно может выполняться не более одной транзакция изменения данных (один писатель). Зато все изменения всегда последовательны, не может быть конфликтов или логических ошибок при откате транзакций.
-
Отсутствие WAL обуславливает относительно большой WAF (Write Amplification Factor). Поэтому фиксация изменений на диске может быть достаточно дорогой и являться главным ограничением производительности при интенсивном изменении данных.
В качестве компромисса libmdbx предлагает несколько режимов ленивой и/или периодической фиксации. В том числе режим
MAPASYNC, при котором изменения происходят только в памяти и асинхронно фиксируются на диске ядром ОС.Однако, следует воспринимать это свойство аккуратно и взвешенно. Например, полная фиксация транзакции в БД с журналом потребует минимум 2 IOPS (скорее всего 3-4) из-за накладных расходов в файловой системе. В libmdbx фиксация транзакции также требует от 2 IOPS. Однако, в БД с журналом кол-во IOPS будет меняться в зависимости от файловой системы, но не от кол-ва записей или их объема. Тогда как в libmdbx кол-во будет расти логарифмически от кол-во записей/строк в БД (по высоте b+tree).
-
COW для реализации MVCC выполняется на уровне страниц в B+ дереве. Поэтому изменение данных амортизационно требует копирования Olog(N) страниц, что расходует пропускную способность оперативной памяти и является основным ограничителем производительности в режиме
MAPASYNC.Этот недостаток неустраним, тем не менее следует дать некоторые пояснения. Дело в том, что фиксация изменений на диске потребует гораздо более значительного копирования данных в памяти и массы других затратных операций. Поэтому обусловленное этим недостатком падение производительности становится заметным только при отказе от фиксации изменений на диске. Соответственно, корректнее сказать что libmdbx позволяет получить персистентность ценой минимального падения производительности. Если же нет необходимости оперативно сохранять данные, то логичнее использовать
std::map. -
В LMDB существует проблема долгих чтений (приостановленных читателей), которая приводит к деградации производительности и переполнению БД.
В libmdbx предложены средства для предотвращения, быстрого выхода из некомфортной ситуации и устранения её последствий. Подробности ниже.
-
В LMDB есть вероятность разрушения БД в режиме
WRITEMAP+MAPASYNC. В libmdbx дляWRITEMAP+MAPASYNCгарантируется как сохранность базы, так и согласованность данных.Дополнительно, в качестве альтернативы, предложен режим
UTTERLY_NOSYNC. Подробности ниже.
Проблема долгих чтений
Следует отметить, что проблема "сборки мусора" так или иначе существует во всех СУБД (Vacuum в PostgreSQL). Однако в случае libmdbx и LMDB она проявляется более остро, прежде всего из-за высокой производительности, а также из-за намеренного упрощения внутренних механизмов ради производительности.
Понимание проблемы требует некоторых пояснений, которые изложены ниже, но могут быть сложны для быстрого восприятия. Поэтому, тезисно:
-
Изменение данных на фоне долгой операции чтения может приводить к исчерпанию места в БД.
-
После чего любая попытка обновить данные будет приводить к ошибке
MAP_FULLдо завершения долгой операции чтения. -
Характерными примерами долгих чтений являются горячее резервное копирования и отладка клиентского приложения при активной транзакции чтения.
-
В оригинальной LMDB после этого будет наблюдаться устойчивая деградация производительности всех механизмов обратной записи на диск (в I/O контроллере, в гипервизоре, в ядре ОС).
-
В libmdbx предусмотрен механизм аварийного прерывания таких операций, а также режим
LIFO RECLAIMустраняющий последующую деградацию производительности.
Операции чтения выполняются в контексте снимка данных (версии БД), который был актуальным на момент старта транзакции чтения. Такой читаемый снимок поддерживается неизменным до завершения операции. В свою очередь, это не позволяет повторно использовать страницы БД в последующих версиях (снимках БД).
Другими словами, если обновление данных выполняется на фоне долгой операции чтения, то вместо повторного использования "старых" ненужных страниц будут выделяться новые, так как "старые" страницы составляют снимок БД, который еще используется долгой операцией чтения.
В результате, при интенсивном изменении данных и достаточно длительной операции чтения, в БД могут быть исчерпаны свободные страницы, что не позволит создавать новые снимки/версии БД. Такая ситуация будет сохраняться до завершения операции чтения, которая использует старый снимок данных и препятствует повторному использованию страниц БД.
Однако, на этом проблемы не заканчиваются. После описанной ситуации, все дополнительные страницы, которые были выделены пока переработка старых была невозможна, будут участвовать в цикле выделения/освобождения до конца жизни экземпляра БД. В оригинальной LMDB этот цикл использования страниц работает по принципу FIFO. Поэтому увеличение количества циркулирующий страниц, с точки зрения механизмов кэширования и/или обратной записи, выглядит как увеличение рабочего набор данных. Проще говоря, однократное попадание в ситуацию "уснувшего читателя" приводит к устойчивому эффекту вымывания I/O кэша при всех последующих изменениях данных.
Для устранения описанных проблемы в libmdbx сделаны существенные доработки, подробности ниже. Иллюстрации к проблеме "долгих чтений" можно найти в слайдах презентации.
Там же приведен пример количественной оценки прироста производительности
за счет эффективной работы BBWC
при включении LIFO RECLAIM в libmdbx.
Вероятность разрушения БД в режиме WRITEMAP+MAPASYNC
При работе в режиме WRITEMAP+MAPSYNC запись измененных страниц
выполняется ядром ОС, что имеет ряд преимуществ. Так например, при крахе
приложения, ядро ОС сохранит все изменения.
Однако, при аварийном отключении питания или сбое в ядре ОС, на диске
будет сохранена только часть измененных страниц БД. При этом с большой
вероятностью может оказаться так, что будут сохранены мета-страницы со
ссылками на страницы с новыми версиями данных, но не сами новые данные.
В этом случае БД будет безвозвратна разрушена, даже если до аварии
производилась полная синхронизация данных (посредством
mdbx_env_sync()).
В libmdbx эта проблема устранена, подробности ниже.
Дополнительные "фичи" libmdbx относительно LMDB
-
Режим
LIFO RECLAIM.Для повторного использования выбираются не самые старые, а самые новые страницы из доступных. За счет этого цикл использования страниц всегда имеет минимальную длину и не зависит от общего числа выделенных страниц.
В результате механизмы кэширования и обратной записи работают с максимально возможной эффективностью. В случае использования контроллера дисков или системы хранения с BBWC возможно многократное увеличение производительности по записи (обновлению данных).
-
Обработчик
OOM-KICK.Посредством
mdbx_env_set_oomfunc()может быть установлен внешний обработчик (callback), который будет вызван при исчерпания свободных страниц из-за долгой операцией чтения. Обработчику будет передан PID и pthread_id виновника. В свою очередь обработчик может предпринять одно из действий:-
нейтрализовать виновника (отправить сигнал kill #9), если долгое чтение выполняется сторонним процессом;
-
отменить или перезапустить проблемную операцию чтения, если операция выполняется одним из потоков текущего процесса;
-
подождать некоторое время, в расчете что проблемная операция чтения будет штатно завершена;
-
прервать текущую операцию изменения данных с возвратом кода ошибки.
-
-
Гарантия сохранности БД в режиме
WRITEMAP+MAPSYNC.При работе в режиме
WRITEMAP+MAPSYNCзапись измененных страниц выполняется ядром ОС, что имеет ряд преимуществ. Так например, при крахе приложения, ядро ОС сохранит все изменения.Однако, при аварийном отключении питания или сбое в ядре ОС, на диске будет сохранена только часть измененных страниц БД. При этом с большой вероятностью может оказаться так, что будут сохранены мета-страницы со ссылками на страницы с новыми версиями данных, но не сами новые данные. В этом случае БД будет безвозвратна разрушена, даже если до аварии производилась полная синхронизация данных (посредством
mdbx_env_sync()).В libmdbx эта проблема устранена путем полной переработки пути записи данных:
-
В режиме
WRITEMAP+MAPSYNClibmdbx не обновляет мета-страницы непосредственно, а поддерживает их теневые копии с переносом изменений после фиксации данных. -
При завершении транзакций, в зависимости от состояния синхронности данных между диском и оперативной память, libmdbx помечает точки фиксации либо как сильные (strong), либо как слабые (weak). Так например, в режиме
WRITEMAP+MAPSYNCзавершаемые транзакции помечаются как слабые, а при явной синхронизации данных как сильные. -
В libmdbx поддерживается не две, а три отдельные мета-страницы. Это позволяет выполнять фиксацию транзакций с формированием как сильной, так и слабой точки фиксации, без потери двух предыдущих точек фиксации (из которых одна может быть сильной, а вторая слабой). В результате, libmdbx позволяет в произвольном порядке чередовать сильные и слабые точки фиксации без нарушения соответствующих гарантий в случае неожиданной системной аварии во время фиксации.
-
При открытии БД выполняется автоматический откат к последней сильной фиксации. Этим обеспечивается гарантия сохранности БД.
К сожалению, такая гарантия надежности не дается бесплатно. Для сохранности данных, страницы формирующие крайний снимок с сильной фиксацией, не должны повторно использоваться (перезаписываться) до формирования следующей сильной точки фиксации. Таким образом, крайняя точка фиксации создает описанный выше эффект "долгого чтения". Разница же здесь в том, что при исчерпании свободных страниц ситуация будет автоматически исправлена, посредством записи изменений на диск и формированием новой сильной точки фиксации.
В последующих версиях libmdbx будут предусмотрены средства для асинхронной записи данных на диск с автоматическим формированием сильных точек фиксации.
-
-
Возможность автоматического формирования контрольных точек (сброса данных на диск) при накоплении заданного объёма изменений, устанавливаемого функцией
mdbx_env_set_syncbytes(). -
Возможность получить отставание текущей транзакции чтения от последней версии данных в БД посредством
mdbx_txn_straggler(). -
Утилита mdbx_chk для проверки БД и функция
mdbx_env_pgwalk()для обхода всех страниц БД. -
Управление отладкой и получение отладочных сообщений посредством
mdbx_setup_debug(). -
Возможность связать с каждой завершаемой транзакцией до 3 дополнительных маркеров посредством
mdbx_canary_put(), и прочитать их в транзакции чтения посредствомmdbx_canary_get(). -
Возможность узнать есть ли за текущей позицией курсора строка данных посредством
mdbx_cursor_eof(). -
Возможность явно запросить обновление существующей записи, без создания новой посредством флажка
MDBX_CURRENTдляmdbx_put(). -
Возможность посредством
mdbx_replace()обновить или удалить запись с получением предыдущего значения данных, а также адресно изменить конкретное multi-значение. -
Поддержка ключей и значений нулевой длины, включая сортированные дубликаты.
-
Исправленный вариант
mdbx_cursor_count(), возвращающий корректное количество дубликатов для всех типов таблиц и любого положения курсора. -
Возможность открыть БД в эксклюзивном режиме посредством
mdbx_env_open_ex(), например в целях её проверки. -
Возможность закрыть БД в "грязном" состоянии (без сброса данных и формирования сильной точки фиксации) посредством
mdbx_env_close_ex(). -
Возможность получить посредством
mdbx_env_info()дополнительную информацию, включая номер самой старой версии БД (снимка данных), который используется одним из читателей. -
Функция
mdbx_del()не игнорирует дополнительный (уточняющий) аргументdataдля таблиц без дубликатов (без флажкаMDBX_DUPSORT), а при его ненулевом значении всегда использует его для сверки с удаляемой записью. -
Возможность открыть dbi-таблицу, одновременно с установкой компараторов для ключей и данных, посредством
mdbx_dbi_open_ex(). -
Возможность посредством
mdbx_is_dirty()определить находятся ли некоторый ключ или данные в "грязной" странице БД. Таким образом, избегая лишнего копирования данных перед выполнением модифицирующих операций (значения в размещенные "грязных" страницах могут быть перезаписаны при изменениях, иначе они будут неизменны). -
Корректное обновление текущей записи, в том числе сортированного дубликата, при использовании режима
MDBX_CURRENTвmdbx_cursor_put(). -
Все курсоры, как в транзакциях только для чтения, так и в пишущих, могут быть переиспользованы посредством
mdbx_cursor_renew()и ДОЛЖНЫ ОСВОБОЖДАТЬСЯ ЯВНО.
ВАЖНО, Обратите внимание!
Это единственное изменение в API, которое значимо меняет семантику управления курсорами и может приводить к утечкам памяти. Следует отметить, что это изменение вынужденно. Так устраняется неоднозначность с массой тяжких последствий:
- обращение к уже освобожденной памяти;
- попытки повторного освобождения памяти;
- memory corruption and segfaults.
-
Дополнительный код ошибки
MDBX_EMULTIVAL, который возвращается изmdbx_put()иmdbx_replace()при попытке выполнить неоднозначное обновление или удаления одного из нескольких значений с одним ключом. -
Возможность посредством
mdbx_get_ex()получить значение по заданному ключу, одновременно с количеством дубликатов. -
Наличие функций
mdbx_cursor_on_first()иmdbx_cursor_on_last(), которые позволяют быстро выяснить стоит ли курсор на первой/последней позиции. -
При завершении читающих транзакций, открытые в них DBI-хендлы не закрываются и не теряются при завершении таких транзакций посредством
mdbx_txn_abort()илиmdbx_txn_reset(). Что позволяет избавится от ряда сложно обнаруживаемых ошибок. -
Генерация последовательностей посредством
mdbx_dbi_sequence(). -
Расширенное динамическое управление размером БД, включая выбор размера страницы посредством
mdbx_env_set_geometry(). -
Три мета-страницы вместо двух, что позволяет гарантированно консистентно обновлять слабые контрольные точки фиксации без риска повредить крайнюю сильную точку фиксации.
-
В libmdbx реализован автоматический возврат освобождающихся страниц в область нераспределенного резерва в конце файла данных. При этом уменьшается количество страниц загруженных в память и участвующих в цикле обновления данных и записи на диск. Фактически libmdbx выполняет постоянную компактификацию данных, но не затрачивая на это дополнительных ресурсов, а только освобождая их. При освобождении места в БД, в случае наличия поддержки со стороны операционной системы и установки соответствующих параметров геометрии базы данных, также будет уменьшаться размер файла на диске.
$ objdump -f -h -j .text libmdbx.so
libmdbx.so: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000150:
HAS_SYMS, DYNAMIC, D_PAGED
start address 0x000030e0
Sections:
Idx Name Size VMA LMA File off Algn
11 .text 00014661 000030e0 000030e0 000030e0 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
$ objdump -C -T libmdbx.so | grep mdbx | sort
00004057 g DF .text 0000003f Base mdbx_strerror_r
00004096 g DF .text 00000031 Base mdbx_strerror
00004207 g DF .text 00000025 Base mdbx_env_get_maxkeysize
0000422c g DF .text 000000b8 Base mdbx_env_create
000042e4 g DF .text 0000001f Base mdbx_env_set_mapsize
00004f9f g DF .text 00000037 Base mdbx_env_set_maxdbs
00004fd6 g DF .text 00000036 Base mdbx_env_set_maxreaders
0000500c g DF .text 00000027 Base mdbx_env_get_maxreaders
00005033 g DF .text 0000066a Base mdbx_env_open_ex
0000569d g DF .text 00000008 Base mdbx_env_open
000056a5 g DF .text 00000096 Base mdbx_env_close_ex
0000573b g DF .text 00000007 Base mdbx_env_close
00005742 g DF .text 00000047 Base mdbx_env_set_flags
00005789 g DF .text 0000001d Base mdbx_env_get_flags
000057a6 g DF .text 00000014 Base mdbx_env_set_userctx
000057ba g DF .text 0000000f Base mdbx_env_get_userctx
000057c9 g DF .text 0000000d Base mdbx_env_set_assert
000057d6 g DF .text 0000001d Base mdbx_env_get_path
000057f3 g DF .text 00000018 Base mdbx_env_get_fd
0000580b g DF .text 00000056 Base mdbx_env_stat
00005861 g DF .text 00000276 Base mdbx_env_info
00005ad7 g DF .text 00000148 Base mdbx_reader_list
0000656a g DF .text 0000012a Base mdbx_dbi_stat
0000693a g DF .text 00000146 Base mdbx_env_copy2fd
00006a80 g DF .text 0000012e Base mdbx_env_copy
00006bae g DF .text 0000002a Base mdbx_reader_check
00006bd8 g DF .text 000000f9 Base mdbx_setup_debug
00006cd1 g DF .text 00000033 Base mdbx_env_set_syncbytes
00006d04 g DF .text 00000023 Base mdbx_env_set_oomfunc
00006d27 g DF .text 00000019 Base mdbx_env_get_oomfunc
00006d40 g DF .text 00000121 Base mdbx_env_pgwalk
0000ac60 g DF .text 00000163 Base mdbx_dkey
0000add0 g DF .text 00000016 Base mdbx_cmp
0000adf0 g DF .text 00000016 Base mdbx_dcmp
0000ae10 g DF .text 00000271 Base mdbx_env_sync
0000b090 g DF .text 0000001b Base mdbx_txn_env
0000b0b0 g DF .text 0000001c Base mdbx_txn_id
0000b0d0 g DF .text 00000077 Base mdbx_txn_reset
0000b150 g DF .text 00000077 Base mdbx_txn_abort
0000b1d0 g DF .text 00000057 Base mdbx_get_maxkeysize
0000b230 g DF .text 000006b7 Base mdbx_env_set_geometry
0000b8f0 g DF .text 000000ef Base mdbx_cursor_count
0000b9e0 g DF .text 000000ad Base mdbx_cursor_close
0000ba90 g DF .text 0000001b Base mdbx_cursor_txn
0000bab0 g DF .text 00000017 Base mdbx_cursor_dbi
0000bad0 g DF .text 0000007d Base mdbx_dbi_close
0000bb50 g DF .text 000000cc Base mdbx_dbi_flags_ex
0000bc20 g DF .text 00000038 Base mdbx_dbi_flags
0000c250 g DF .text 00000077 Base mdbx_txn_renew
0000c2d0 g DF .text 000004e5 Base mdbx_txn_begin
0000dcb0 g DF .text 00000128 Base mdbx_cursor_open
0000dde0 g DF .text 0000011d Base mdbx_cursor_renew
0000e970 g DF .text 000000fc Base mdbx_get
0000ef00 g DF .text 00000489 Base mdbx_cursor_get
000125e0 g DF .text 00000719 Base mdbx_cursor_del
00012e00 g DF .text 000000e4 Base mdbx_del
00012ef0 g DF .text 000002c3 Base mdbx_drop
000131c0 g DF .text 0000129e Base mdbx_cursor_put
000145d0 g DF .text 000000a7 Base mdbx_put
00014b60 g DF .text 000000bf Base mdbx_dbi_open_ex
00014c20 g DF .text 0000000b Base mdbx_dbi_open
00014c30 g DF .text 00001347 Base mdbx_txn_commit
00015f80 g DF .text 00000105 Base mdbx_txn_straggler
00016090 g DF .text 000000e7 Base mdbx_canary_put
00016180 g DF .text 00000078 Base mdbx_canary_get
00016200 g DF .text 0000006e Base mdbx_cursor_on_first
00016270 g DF .text 00000096 Base mdbx_cursor_on_last
00016310 g DF .text 00000066 Base mdbx_cursor_eof
00016380 g DF .text 00000504 Base mdbx_replace
00016890 g DF .text 0000017d Base mdbx_get_ex
00016a10 g DF .text 000000a4 Base mdbx_is_dirty
00016ac0 g DF .text 00000120 Base mdbx_dbi_sequence
00016be0 g DF .text 00000064 Base mdbx_cursor_get_attr
00016c50 g DF .text 00000064 Base mdbx_get_attr
00016cc0 g DF .text 000000c7 Base mdbx_put_attr
00016d90 g DF .text 000000c7 Base mdbx_cursor_put_attr
00016e60 g DF .text 00000244 Base mdbx_set_attr