mirror of
https://github.com/isar/libmdbx.git
synced 2025-12-16 17:12:23 +08:00
Compare commits
18 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e1e17fd6a4 | ||
|
|
b6e605b8da | ||
|
|
2f983b281d | ||
|
|
efdcbd8c35 | ||
|
|
634efbe34b | ||
|
|
17d3e7190c | ||
|
|
fdc248384e | ||
|
|
38369bd24b | ||
|
|
22d8b0b2e1 | ||
|
|
515adb674b | ||
|
|
f99df1ca35 | ||
|
|
ab4c9c9db0 | ||
|
|
b68ed8600c | ||
|
|
9384d0efa6 | ||
|
|
4214436d4b | ||
|
|
ffafd5be10 | ||
|
|
e86bd88751 | ||
|
|
eb4090c534 |
3
.gitignore
vendored
3
.gitignore
vendored
@@ -16,6 +16,7 @@ Win32/
|
||||
build-*
|
||||
cmake-build-*
|
||||
core
|
||||
example
|
||||
libmdbx.creator.user
|
||||
mdbx-dll.VC.VC.opendb
|
||||
mdbx-dll.VC.db
|
||||
@@ -25,7 +26,7 @@ mdbx_copy
|
||||
mdbx_dump
|
||||
mdbx_load
|
||||
mdbx_stat
|
||||
ootest/test
|
||||
mdbx_test
|
||||
test.log
|
||||
test/test.vcxproj.user
|
||||
test/tmp.db
|
||||
|
||||
62
README-RU.md
62
README-RU.md
@@ -14,28 +14,28 @@ and [by Yandex](https://translate.yandex.ru/translate?url=https%3A%2F%2Fgithub.c
|
||||
|
||||
|
||||
**Сейчас MDBX _активно перерабатывается_** и к середине 2018
|
||||
ожидается большое измените как API, так и формата базы данных.
|
||||
ожидается большое изменение как API, так и формата базы данных.
|
||||
К сожалению, обновление приведет к потере совместимости с
|
||||
предыдущими версиями.
|
||||
|
||||
Цель этой революции в обеспечении более четкого надежного
|
||||
API и добавлении новых функции, а также в наделении базы данных
|
||||
Цель этой революции - обеспечение более четкого надежного
|
||||
API и добавление новых функции, а также наделение базы данных
|
||||
новыми свойствами.
|
||||
|
||||
В настоящее время MDBX предназначена для Linux, а также
|
||||
поддерживает Windows (начиная с Windows Server 2008) в качестве
|
||||
дополнительно платформы. Поддержка других ОС может быть
|
||||
дополнительной платформы. Поддержка других ОС может быть
|
||||
обеспечена на коммерческой основе. Однако такие
|
||||
усовершенствования (т. е. pull-requests) могут быть приняты в
|
||||
мейнстрим только в том случае, если будет доступен
|
||||
соответствующий публичный и бесплатный сервис непрерывной
|
||||
интеграции (aka Countinious Integration).
|
||||
интеграции (aka Continuous Integration).
|
||||
|
||||
## Содержание
|
||||
|
||||
- [Обзор](#Обзор)
|
||||
- [Сравнение с другими СУБД](#Сравнение-с-другими-СУБД)
|
||||
- [История & Acknowledgements](#История)
|
||||
- [История & Acknowledgments](#История)
|
||||
- [Основные свойства](#Основные-свойства)
|
||||
- [Сравнение производительности](#Сравнение-производительности)
|
||||
- [Интегральная производительность](#Интегральная-производительность)
|
||||
@@ -62,8 +62,8 @@ _libmdbx_ позволяет множеству процессов совмес
|
||||
|
||||
_libmdbx_ обеспечивает
|
||||
[serializability](https://en.wikipedia.org/wiki/Serializability)
|
||||
изменений и согласованность данных после аварий. При этом транзакции
|
||||
изменяющие данные никак не мешают операциям чтения и выполняются строго
|
||||
изменений и согласованность данных после аварий. При этом транзакции,
|
||||
изменяющие данные, никак не мешают операциям чтения и выполняются строго
|
||||
последовательно с использованием единственного
|
||||
[мьютекса](https://en.wikipedia.org/wiki/Mutual_exclusion).
|
||||
|
||||
@@ -101,7 +101,7 @@ Tables](https://github.com/leo-yuriev/libfpta), aka ["Позитивные
|
||||
Technologies](https://www.ptsecurity.ru).
|
||||
|
||||
|
||||
#### Acknowledgements
|
||||
#### Acknowledgments
|
||||
|
||||
Howard Chu (Symas Corporation) - the author of LMDB,
|
||||
from which originated the MDBX in 2015.
|
||||
@@ -113,7 +113,7 @@ which was used for begin development of LMDB.
|
||||
Основные свойства
|
||||
=================
|
||||
|
||||
_libmdbx_ наследует все ключевые возможности и особенности от
|
||||
_libmdbx_ наследует все ключевые возможности и особенности
|
||||
своего прародителя [LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database),
|
||||
но с устранением ряда описываемых далее проблем и архитектурных недочетов.
|
||||
|
||||
@@ -129,7 +129,7 @@ _libmdbx_ наследует все ключевые возможности и
|
||||
[MVCC](https://ru.wikipedia.org/wiki/MVCC) и
|
||||
[COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8).
|
||||
Изменения строго последовательны и не блокируются чтением,
|
||||
конфликты между транзакциями не возможны.
|
||||
конфликты между транзакциями невозможны.
|
||||
При этом гарантируется чтение только зафиксированных данных, см [relaxing serializability](https://en.wikipedia.org/wiki/Serializability).
|
||||
|
||||
4. Чтение и поиск [без блокировок](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B1%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B0%D1%8F_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F),
|
||||
@@ -193,7 +193,7 @@ github](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015).
|
||||
1. Такое сравнение не совсем правомочно, его следует делать с движками
|
||||
ориентированными на хранение данных в памяти ([Tarantool](https://tarantool.io/), [Redis](https://redis.io/)).
|
||||
|
||||
2. Превосходство libmdbx становится еще более подавляющем, что мешает
|
||||
2. Превосходство libmdbx становится еще более подавляющим, что мешает
|
||||
восприятию информации.
|
||||
|
||||
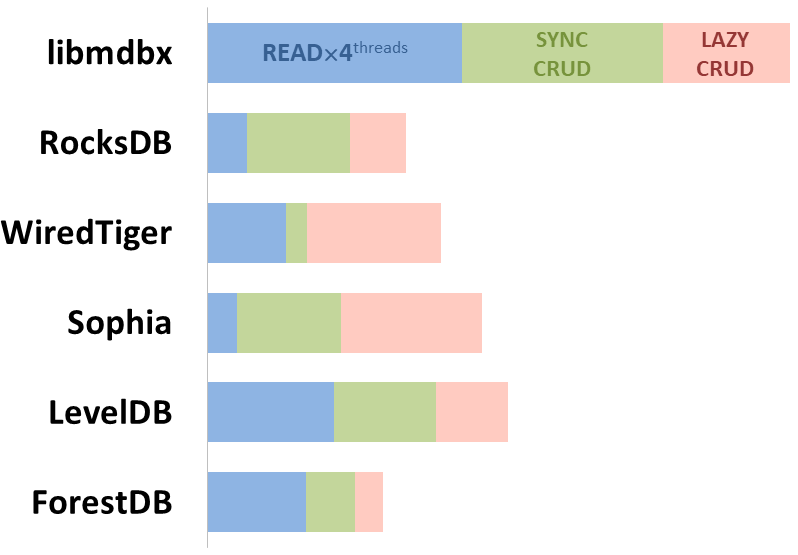
|
||||
@@ -217,7 +217,7 @@ github](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015).
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
показывает минимальное и максимальное время, затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
|
||||
Выполняется **10.000 транзакций в режиме синхронной фиксации данных** на
|
||||
@@ -243,7 +243,7 @@ github](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015).
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
показывает минимальное и максимальное время, затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
|
||||
Выполняется **100.000 транзакций в режиме отложенной фиксации данных**
|
||||
@@ -274,7 +274,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
показывает минимальное и максимальное время, затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
|
||||
Выполняется **1.000.000 транзакций в режиме асинхронной фиксации
|
||||
@@ -283,7 +283,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
консистентны на момент завершения одной из транзакций, но допускается
|
||||
потеря изменений из значительного количества последних транзакций. Во
|
||||
всех движках при этом включался режим предполагающий минимальную
|
||||
нагрузку на диск по-записи, и соответственно минимальную гарантию
|
||||
нагрузку на диск по записи, и соответственно минимальную гарантию
|
||||
сохранности данных. В _libmdbx_ при этом используется режим асинхронной
|
||||
записи измененных страниц на диск посредством ядра ОС и системного
|
||||
вызова [msync(MS_ASYNC)](https://linux.die.net/man/2/msync).
|
||||
@@ -348,7 +348,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
> _libmdbx_ фиксация транзакции также требует от 2 IOPS. Однако, в БД с
|
||||
> журналом кол-во IOPS будет меняться в зависимости от файловой системы,
|
||||
> но не от кол-ва записей или их объема. Тогда как в _libmdbx_ кол-во
|
||||
> будет расти логарифмически от кол-во записей/строк в БД (по высоте
|
||||
> будет расти логарифмически от кол-ва записей/строк в БД (по высоте
|
||||
> b+tree).
|
||||
|
||||
3. [COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8)
|
||||
@@ -364,7 +364,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
> значительного копирования данных в памяти и массы других затратных операций.
|
||||
> Поэтому обусловленное этим недостатком падение производительности становится
|
||||
> заметным только при отказе от фиксации изменений на диске.
|
||||
> Соответственно, корректнее сказать что _libmdbx_ позволяет
|
||||
> Соответственно, корректнее сказать, что _libmdbx_ позволяет
|
||||
> получить персистентность ценой минимального падения производительности.
|
||||
> Если же нет необходимости оперативно сохранять данные, то логичнее
|
||||
> использовать `std::map`.
|
||||
@@ -457,7 +457,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
|
||||
Однако, при аварийном отключении питания или сбое в ядре ОС, на диске
|
||||
может быть сохранена только часть измененных страниц БД. При этом с большой
|
||||
вероятностью может оказаться так, что будут сохранены мета-страницы со
|
||||
вероятностью может оказаться, что будут сохранены мета-страницы со
|
||||
ссылками на страницы с новыми версиями данных, но не сами новые данные.
|
||||
В этом случае БД будет безвозвратна разрушена, даже если до аварии
|
||||
производилась полная синхронизация данных (посредством
|
||||
@@ -471,11 +471,11 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
с переносом изменений после фиксации данных.
|
||||
|
||||
* При завершении транзакций, в зависимости от состояния
|
||||
синхронности данных между диском и оперативной память,
|
||||
синхронности данных между диском и оперативной памятью,
|
||||
_libmdbx_ помечает точки фиксации либо как сильные (strong),
|
||||
либо как слабые (weak). Так например, в режиме
|
||||
`WRITEMAP+MAPSYNC` завершаемые транзакции помечаются как
|
||||
слабые, а при явной синхронизации данных как сильные.
|
||||
слабые, а при явной синхронизации данных - как сильные.
|
||||
|
||||
* В _libmdbx_ поддерживается не две, а три отдельные мета-страницы.
|
||||
Это позволяет выполнять фиксацию транзакций с формированием как
|
||||
@@ -489,20 +489,20 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
сильной фиксации. Этим обеспечивается гарантия сохранности БД.
|
||||
|
||||
Такая гарантия надежности не дается бесплатно. Для
|
||||
сохранности данных, страницы формирующие крайний снимок с
|
||||
сохранности данных, страницы, формирующие крайний снимок с
|
||||
сильной фиксацией, не должны повторно использоваться
|
||||
(перезаписываться) до формирования следующей сильной точки
|
||||
фиксации. Таким образом, крайняя точка фиксации создает
|
||||
описанный выше эффект "долгого чтения". Разница же здесь в том,
|
||||
что при исчерпании свободных страниц ситуация будет
|
||||
автоматически исправлена, посредством записи изменений на диск
|
||||
и формированием новой сильной точки фиксации.
|
||||
и формирования новой сильной точки фиксации.
|
||||
|
||||
Таким образом, в режиме безопасной асинхронной фиксации _libmdbx_ будет
|
||||
всегда использовать новые страницы до исчерпания места в БД или до явного
|
||||
формирования сильной точки фиксации посредством `mdbx_env_sync()`.
|
||||
При этом суммарный трафик записи на диск будет примерно такой-же,
|
||||
как если бы отдельно фиксировалась каждая транзакций.
|
||||
При этом суммарный трафик записи на диск будет примерно такой же,
|
||||
как если бы отдельно фиксировалась каждая транзакция.
|
||||
|
||||
В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` когда
|
||||
@@ -535,9 +535,9 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
|
||||
Посредством `mdbx_env_set_oomfunc()` может быть установлен
|
||||
внешний обработчик (callback), который будет вызван при
|
||||
исчерпания свободных страниц из-за долгой операцией чтения.
|
||||
исчерпании свободных страниц из-за долгой операцией чтения.
|
||||
Обработчику будет передан PID и pthread_id виновника.
|
||||
В свою очередь обработчик может предпринять одно из действий:
|
||||
В свою очередь обработчик может предпринять одно из действий:
|
||||
|
||||
* нейтрализовать виновника (отправить сигнал kill #9), если
|
||||
долгое чтение выполняется сторонним процессом;
|
||||
@@ -545,7 +545,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
* отменить или перезапустить проблемную операцию чтения, если
|
||||
операция выполняется одним из потоков текущего процесса;
|
||||
|
||||
* подождать некоторое время, в расчете что проблемная операция
|
||||
* подождать некоторое время, в расчете на то, что проблемная операция
|
||||
чтения будет штатно завершена;
|
||||
|
||||
* прервать текущую операцию изменения данных с возвратом кода
|
||||
@@ -612,7 +612,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
19. Возможность посредством `mdbx_is_dirty()` определить находятся ли
|
||||
некоторый ключ или данные в "грязной" странице БД. Таким образом,
|
||||
избегая лишнего копирования данных перед выполнением модифицирующих
|
||||
операций (значения в размещенные "грязных" страницах могут быть
|
||||
операций (значения, размещенные в "грязных" страницах, могут быть
|
||||
перезаписаны при изменениях, иначе они будут неизменны).
|
||||
|
||||
20. Корректное обновление текущей записи, в том числе сортированного
|
||||
@@ -632,7 +632,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
>
|
||||
> - обращение к уже освобожденной памяти;
|
||||
> - попытки повторного освобождения памяти;
|
||||
> - memory corruption and segfaults.
|
||||
> - повреждение памяти и ошибки сегментации.
|
||||
|
||||
22. Дополнительный код ошибки `MDBX_EMULTIVAL`, который возвращается из
|
||||
`mdbx_put()` и `mdbx_replace()` при попытке выполнить неоднозначное
|
||||
@@ -666,7 +666,7 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко
|
||||
цикле обновления данных и записи на диск. Фактически _libmdbx_ выполняет
|
||||
постоянную компактификацию данных, но не затрачивая на это
|
||||
дополнительных ресурсов, а только освобождая их. При освобождении места
|
||||
в БД и установки соответствующих параметров геометрии базы данных, также будет
|
||||
в БД и установке соответствующих параметров геометрии базы данных, также будет
|
||||
уменьшаться размер файла на диске, в том числе в **Windows**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
50
README.md
50
README.md
@@ -7,25 +7,33 @@ libmdbx
|
||||
[](https://ci.appveyor.com/project/leo-yuriev/libmdbx/branch/master)
|
||||
[](https://scan.coverity.com/projects/reopen-libmdbx)
|
||||
|
||||
### Project Status
|
||||
## Project Status for now
|
||||
|
||||
**MDBX is under _active development_**, database format and
|
||||
API aren't stable at least until 2018Q3. New version won't be
|
||||
backwards compatible. Main focus of the rework is to provide
|
||||
clear and robust API and new features.
|
||||
- The stable versions ([_stable/0.0_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.0) and [_stable/0.1_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.1) branches) of _MDBX_ are frozen, i.e. no new features or API changes, but only bug fixes.
|
||||
- The next version ([_devel_](https://github.com/leo-yuriev/libmdbx/tree/devel) branch) **is under active non-public development**, i.e. current API and set of features are extreme volatile.
|
||||
- The immediate goal of development is formation of the stable API and the stable internal database format, which allows realise all PLANNED FEATURES:
|
||||
1. Integrity check by [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree);
|
||||
2. Support for [raw block devices](https://en.wikipedia.org/wiki/Raw_device);
|
||||
3. Separate place (HDD) for large data items;
|
||||
4. Using "[Roaring bitmaps](http://roaringbitmap.org/about/)" inside garbage collector;
|
||||
5. Non-sequential reclaiming, like PostgreSQL's [Vacuum](https://www.postgresql.org/docs/9.1/static/sql-vacuum.html);
|
||||
6. [Asynchronous lazy data flushing](https://sites.fas.harvard.edu/~cs265/papers/kathuria-2008.pdf) to disk(s);
|
||||
7. etc...
|
||||
|
||||
Nowadays MDBX intended for Linux and support Windows (since
|
||||
Windows Server 2008) as complementary platform. Support for
|
||||
-----
|
||||
|
||||
Nowadays MDBX intended for Linux, and support Windows (since
|
||||
Windows Server 2008) as a complementary platform. Support for
|
||||
other OS could be implemented on commercial basis. However such
|
||||
enhancements (i.e. pull requests) could be accepted in
|
||||
mainstream only when corresponding public and free Countinious
|
||||
mainstream only when corresponding public and free Continuous
|
||||
Integration service will be available.
|
||||
|
||||
## Contents
|
||||
|
||||
- [Overview](#overview)
|
||||
- [Comparison with other DBs](#comparison-with-other-dbs)
|
||||
- [History & Acknowledgements](#history)
|
||||
- [History & Acknowledgments](#history)
|
||||
- [Main features](#main-features)
|
||||
- [Performance comparison](#performance-comparison)
|
||||
- [Integral performance](#integral-performance)
|
||||
@@ -65,7 +73,7 @@ Because _libmdbx_ is currently overhauled, I think it's better to just link
|
||||
|
||||
### History
|
||||
|
||||
_libmdbx_ design is based on [Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
The _libmdbx_ design is based on [Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
Initial development was going in [ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project, about a year later it
|
||||
received separate development effort and in autumn 2015 was isolated to separate project, which was
|
||||
[presented at Highload++ 2015 conference](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
@@ -73,7 +81,7 @@ received separate development effort and in autumn 2015 was isolated to separate
|
||||
Since early 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/leo-yuriev/libfpta),
|
||||
by [Positive Technologies](https://www.ptsecurity.com).
|
||||
|
||||
#### Acknowledgements
|
||||
#### Acknowledgments
|
||||
|
||||
Howard Chu (Symas Corporation) - the author of LMDB,
|
||||
from which originated the MDBX in 2015.
|
||||
@@ -269,7 +277,7 @@ scanning data directory.
|
||||
#### Long-time read transactions problem
|
||||
|
||||
Garbage collection problem exists in all databases one way or another (e.g. VACUUM in PostgreSQL).
|
||||
But in _libmbdx_ and LMDB it's even more important because of high performance and deliberate
|
||||
But in _libmdbx_ and LMDB it's even more important because of high performance and deliberate
|
||||
simplification of internals with emphasis on performance.
|
||||
|
||||
* Altering data during long read operation may exhaust available space on persistent storage.
|
||||
@@ -305,7 +313,7 @@ _libmdbx_ addresses the problem, details below. Illustrations to this problem ca
|
||||
In `WRITEMAP+MAPSYNC` mode dirty pages are written to persistent storage by kernel. This means that in case of application
|
||||
crash OS kernel will write all dirty data to disk and nothing will be lost. But in case of hardware malfunction or OS kernel
|
||||
fatal error only some dirty data might be synced to disk, and there is high probability that pages with metadata saved,
|
||||
will point to non-saved, hence non-existent, data pages. In such situation DB is completely corrupted and can't be
|
||||
will point to non-saved, hence non-existent, data pages. In such situation, DB is completely corrupted and can't be
|
||||
repaired even if there was full sync before the crash via `mdbx_env_sync().
|
||||
|
||||
_libmdbx_ addresses this by fully reimplementing write path of data:
|
||||
@@ -328,7 +336,7 @@ synchronization point. So last steady synchronization point creates "long-time r
|
||||
of memory exhaustion the problem will be immediately addressed by flushing changes to persistent storage and forming new steady
|
||||
synchronization point.
|
||||
|
||||
So in async-write mode _libmdbx_ will always use new pages until memory is exhausted or `mdbx_env_sync()`is invoked. Total
|
||||
So in async-write mode _libmdbx_ will always use new pages until memory is exhausted or `mdbx_env_sync()` is invoked. Total
|
||||
disk usage will be almost the same as in sync-write mode.
|
||||
|
||||
Current _libmdbx_ gives a choice of safe async-write mode (default) and `UTTERLY_NOSYNC` mode which may result in full DB
|
||||
@@ -344,7 +352,7 @@ Improvements over LMDB
|
||||
1. `LIFO RECLAIM` mode:
|
||||
|
||||
The newest pages are picked for reuse instead of the oldest.
|
||||
This allows to minimize reclaim loop and make it execution time independent from total page count.
|
||||
This allows to minimize reclaim loop and make it execution time independent of total page count.
|
||||
|
||||
This results in OS kernel cache mechanisms working with maximum efficiency.
|
||||
In case of using disk controllers or storages with
|
||||
@@ -356,7 +364,7 @@ Improvements over LMDB
|
||||
`mdbx_env_set_oomfunc()` allows to set a callback, which will be called
|
||||
in the event of memory exhausting during long-time read transaction.
|
||||
Callback will be invoked with PID and pthread_id of offending thread as parameters.
|
||||
Callback can do any of this things to remedy the problem:
|
||||
Callback can do any of these things to remedy the problem:
|
||||
|
||||
* wait for read transaction to finish normally;
|
||||
|
||||
@@ -400,7 +408,7 @@ Improvements over LMDB
|
||||
15. Ability to close DB in "dirty" state (without data flush and creation of steady synchronization point)
|
||||
via `mdbx_env_close_ex()`.
|
||||
|
||||
16. Ability to get addition info, including number of the oldest snapshot of DB, which is used by one of the readers.
|
||||
16. Ability to get additional info, including number of the oldest snapshot of DB, which is used by one of the readers.
|
||||
Implemented via `mdbx_env_info()`.
|
||||
|
||||
17. `mdbx_del()` doesn't ignore additional argument (specifier) `data`
|
||||
@@ -409,7 +417,7 @@ Improvements over LMDB
|
||||
|
||||
18. Ability to open dbi-table with simultaneous setup of comparators for keys and values, via `mdbx_dbi_open_ex()`.
|
||||
|
||||
19. Ability to find out if key or value are in dirty page. This may be useful to make a decision to avoid
|
||||
19. Ability to find out if key or value is in dirty page. This may be useful to make a decision to avoid
|
||||
excessive CoW before updates. Implemented via `mdbx_is_dirty()`.
|
||||
|
||||
20. Correct update of current record in `MDBX_CURRENT` mode of `mdbx_cursor_put()`, including sorted duplicated.
|
||||
@@ -440,12 +448,12 @@ Improvements over LMDB
|
||||
27. Advanced dynamic control over DB size, including ability to choose page size via `mdbx_env_set_geometry()`,
|
||||
including on Windows.
|
||||
|
||||
28. Three meta-pages instead two, this allows to guarantee consistently update weak sync-points without risking to
|
||||
28. Three meta-pages instead of two, this allows to guarantee consistently update weak sync-points without risking to
|
||||
corrupt last steady sync-point.
|
||||
|
||||
29. Automatic reclaim of freed pages to specific reserved space in the end of database file. This lowers amount of pages,
|
||||
29. Automatic reclaim of freed pages to specific reserved space at the end of database file. This lowers amount of pages,
|
||||
loaded to memory, used in update/flush loop. In fact _libmdbx_ constantly performs compactification of data,
|
||||
but doesn't use addition resources for that. Space reclaim of DB and setup of database geometry parameters also decreases
|
||||
but doesn't use additional resources for that. Space reclaim of DB and setup of database geometry parameters also decreases
|
||||
size of the database on disk, including on Windows.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
2
TODO.md
2
TODO.md
@@ -70,7 +70,7 @@
|
||||
- [x] Привести в порядок volatile.
|
||||
- [x] контроль meta.mapsize.
|
||||
- [x] переработка формата: заголовки страниц, meta, clk...
|
||||
- [x] зачистка Doxygen и бесполезных коментариев.
|
||||
- [x] зачистка Doxygen и бесполезных комментариев.
|
||||
- [x] Добавить поле типа контрольной суммы.
|
||||
- [x] Добавить поле/флаг размера pgno_t.
|
||||
- [x] Поменять сигнатуры.
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
version: 0.1.4.{build}
|
||||
version: 0.1.5.{build}
|
||||
|
||||
environment:
|
||||
matrix:
|
||||
|
||||
16
src/bits.h
16
src/bits.h
@@ -23,11 +23,6 @@
|
||||
# undef NDEBUG
|
||||
#endif
|
||||
|
||||
/* Features under development */
|
||||
#ifndef MDBX_DEVEL
|
||||
# define MDBX_DEVEL 0
|
||||
#endif
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
|
||||
/* Should be defined before any includes */
|
||||
@@ -45,6 +40,9 @@
|
||||
#if _MSC_VER > 1800
|
||||
# pragma warning(disable : 4464) /* relative include path contains '..' */
|
||||
#endif
|
||||
#if _MSC_VER > 1913
|
||||
# pragma warning(disable : 5045) /* Compiler will insert Spectre mitigation... */
|
||||
#endif
|
||||
#pragma warning(disable : 4710) /* 'xyz': function not inlined */
|
||||
#pragma warning(disable : 4711) /* function 'xyz' selected for automatic inline expansion */
|
||||
#pragma warning(disable : 4201) /* nonstandard extension used : nameless struct / union */
|
||||
@@ -141,9 +139,9 @@
|
||||
#define MDBX_MAGIC UINT64_C(/* 56-bit prime */ 0x59659DBDEF4C11)
|
||||
|
||||
/* The version number for a database's datafile format. */
|
||||
#define MDBX_DATA_VERSION ((MDBX_DEVEL) ? 255 : 2)
|
||||
#define MDBX_DATA_VERSION 2
|
||||
/* The version number for a database's lockfile format. */
|
||||
#define MDBX_LOCK_VERSION ((MDBX_DEVEL) ? 255 : 2)
|
||||
#define MDBX_LOCK_VERSION 2
|
||||
|
||||
/* handle for the DB used to track free pages. */
|
||||
#define FREE_DBI 0
|
||||
@@ -168,9 +166,7 @@ typedef uint32_t pgno_t;
|
||||
/* A transaction ID. */
|
||||
typedef uint64_t txnid_t;
|
||||
#define PRIaTXN PRIi64
|
||||
#if MDBX_DEVEL
|
||||
#define MIN_TXNID (UINT64_MAX - UINT32_MAX)
|
||||
#elif MDBX_DEBUG
|
||||
#if MDBX_DEBUG
|
||||
#define MIN_TXNID UINT64_C(0x100000000)
|
||||
#else
|
||||
#define MIN_TXNID UINT64_C(1)
|
||||
|
||||
384
src/mdbx.c
384
src/mdbx.c
@@ -962,63 +962,81 @@ enum {
|
||||
#define MDBX_END_SLOT 0x80 /* release any reader slot if MDBX_NOTLS */
|
||||
static int mdbx_txn_end(MDBX_txn *txn, unsigned mode);
|
||||
|
||||
static int mdbx_page_get(MDBX_cursor *mc, pgno_t pgno, MDBX_page **mp,
|
||||
int *lvl);
|
||||
static int mdbx_page_search_root(MDBX_cursor *mc, MDBX_val *key, int modify);
|
||||
static int __must_check_result mdbx_page_get(MDBX_cursor *mc, pgno_t pgno,
|
||||
MDBX_page **mp, int *lvl);
|
||||
static int __must_check_result mdbx_page_search_root(MDBX_cursor *mc,
|
||||
MDBX_val *key, int modify);
|
||||
|
||||
#define MDBX_PS_MODIFY 1
|
||||
#define MDBX_PS_ROOTONLY 2
|
||||
#define MDBX_PS_FIRST 4
|
||||
#define MDBX_PS_LAST 8
|
||||
static int mdbx_page_search(MDBX_cursor *mc, MDBX_val *key, int flags);
|
||||
static int mdbx_page_merge(MDBX_cursor *csrc, MDBX_cursor *cdst);
|
||||
static int __must_check_result mdbx_page_search(MDBX_cursor *mc, MDBX_val *key,
|
||||
int flags);
|
||||
static int __must_check_result mdbx_page_merge(MDBX_cursor *csrc,
|
||||
MDBX_cursor *cdst);
|
||||
|
||||
#define MDBX_SPLIT_REPLACE MDBX_APPENDDUP /* newkey is not new */
|
||||
static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata,
|
||||
pgno_t newpgno, unsigned nflags);
|
||||
static int __must_check_result mdbx_page_split(MDBX_cursor *mc,
|
||||
MDBX_val *newkey,
|
||||
MDBX_val *newdata,
|
||||
pgno_t newpgno, unsigned nflags);
|
||||
|
||||
static int mdbx_read_header(MDBX_env *env, MDBX_meta *meta);
|
||||
static int mdbx_sync_locked(MDBX_env *env, unsigned flags,
|
||||
MDBX_meta *const pending);
|
||||
static int __must_check_result mdbx_read_header(MDBX_env *env, MDBX_meta *meta,
|
||||
uint64_t *filesize);
|
||||
static int __must_check_result mdbx_sync_locked(MDBX_env *env, unsigned flags,
|
||||
MDBX_meta *const pending);
|
||||
static void mdbx_env_close0(MDBX_env *env);
|
||||
|
||||
static MDBX_node *mdbx_node_search(MDBX_cursor *mc, MDBX_val *key, int *exactp);
|
||||
static int mdbx_node_add(MDBX_cursor *mc, unsigned indx, MDBX_val *key,
|
||||
MDBX_val *data, pgno_t pgno, unsigned flags);
|
||||
static int __must_check_result mdbx_node_add(MDBX_cursor *mc, unsigned indx,
|
||||
MDBX_val *key, MDBX_val *data,
|
||||
pgno_t pgno, unsigned flags);
|
||||
static void mdbx_node_del(MDBX_cursor *mc, size_t ksize);
|
||||
static void mdbx_node_shrink(MDBX_page *mp, unsigned indx);
|
||||
static int mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft);
|
||||
static int mdbx_node_read(MDBX_cursor *mc, MDBX_node *leaf, MDBX_val *data);
|
||||
static int __must_check_result mdbx_node_move(MDBX_cursor *csrc,
|
||||
MDBX_cursor *cdst, int fromleft);
|
||||
static int __must_check_result mdbx_node_read(MDBX_cursor *mc, MDBX_node *leaf,
|
||||
MDBX_val *data);
|
||||
static size_t mdbx_leaf_size(MDBX_env *env, MDBX_val *key, MDBX_val *data);
|
||||
static size_t mdbx_branch_size(MDBX_env *env, MDBX_val *key);
|
||||
|
||||
static int mdbx_rebalance(MDBX_cursor *mc);
|
||||
static int mdbx_update_key(MDBX_cursor *mc, MDBX_val *key);
|
||||
static int __must_check_result mdbx_rebalance(MDBX_cursor *mc);
|
||||
static int __must_check_result mdbx_update_key(MDBX_cursor *mc, MDBX_val *key);
|
||||
|
||||
static void mdbx_cursor_pop(MDBX_cursor *mc);
|
||||
static int mdbx_cursor_push(MDBX_cursor *mc, MDBX_page *mp);
|
||||
static int __must_check_result mdbx_cursor_push(MDBX_cursor *mc, MDBX_page *mp);
|
||||
|
||||
static int mdbx_cursor_del0(MDBX_cursor *mc);
|
||||
static int mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data,
|
||||
unsigned flags);
|
||||
static int mdbx_cursor_sibling(MDBX_cursor *mc, int move_right);
|
||||
static int mdbx_cursor_next(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data,
|
||||
MDBX_cursor_op op);
|
||||
static int mdbx_cursor_prev(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data,
|
||||
MDBX_cursor_op op);
|
||||
static int mdbx_cursor_set(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data,
|
||||
MDBX_cursor_op op, int *exactp);
|
||||
static int mdbx_cursor_first(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data);
|
||||
static int mdbx_cursor_last(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data);
|
||||
static int __must_check_result mdbx_cursor_del0(MDBX_cursor *mc);
|
||||
static int __must_check_result mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi,
|
||||
MDBX_val *key, MDBX_val *data,
|
||||
unsigned flags);
|
||||
static int __must_check_result mdbx_cursor_sibling(MDBX_cursor *mc,
|
||||
int move_right);
|
||||
static int __must_check_result mdbx_cursor_next(MDBX_cursor *mc, MDBX_val *key,
|
||||
MDBX_val *data,
|
||||
MDBX_cursor_op op);
|
||||
static int __must_check_result mdbx_cursor_prev(MDBX_cursor *mc, MDBX_val *key,
|
||||
MDBX_val *data,
|
||||
MDBX_cursor_op op);
|
||||
static int __must_check_result mdbx_cursor_set(MDBX_cursor *mc, MDBX_val *key,
|
||||
MDBX_val *data,
|
||||
MDBX_cursor_op op, int *exactp);
|
||||
static int __must_check_result mdbx_cursor_first(MDBX_cursor *mc, MDBX_val *key,
|
||||
MDBX_val *data);
|
||||
static int __must_check_result mdbx_cursor_last(MDBX_cursor *mc, MDBX_val *key,
|
||||
MDBX_val *data);
|
||||
|
||||
static void mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi,
|
||||
MDBX_xcursor *mx);
|
||||
static void mdbx_xcursor_init0(MDBX_cursor *mc);
|
||||
static void mdbx_xcursor_init1(MDBX_cursor *mc, MDBX_node *node);
|
||||
static void mdbx_xcursor_init2(MDBX_cursor *mc, MDBX_xcursor *src_mx,
|
||||
int force);
|
||||
static int __must_check_result mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn,
|
||||
MDBX_dbi dbi, MDBX_xcursor *mx);
|
||||
static int __must_check_result mdbx_xcursor_init0(MDBX_cursor *mc);
|
||||
static int __must_check_result mdbx_xcursor_init1(MDBX_cursor *mc,
|
||||
MDBX_node *node);
|
||||
static int __must_check_result mdbx_xcursor_init2(MDBX_cursor *mc,
|
||||
MDBX_xcursor *src_mx,
|
||||
int force);
|
||||
|
||||
static int mdbx_drop0(MDBX_cursor *mc, int subs);
|
||||
static int __must_check_result mdbx_drop0(MDBX_cursor *mc, int subs);
|
||||
|
||||
static MDBX_cmp_func mdbx_cmp_memn, mdbx_cmp_memnr, mdbx_cmp_int_ai,
|
||||
mdbx_cmp_int_a2, mdbx_cmp_int_ua;
|
||||
@@ -1305,13 +1323,15 @@ static void mdbx_cursor_chk(MDBX_cursor *mc) {
|
||||
/* Count all the pages in each DB and in the freelist and make sure
|
||||
* it matches the actual number of pages being used.
|
||||
* All named DBs must be open for a correct count. */
|
||||
static void mdbx_audit(MDBX_txn *txn) {
|
||||
static int mdbx_audit(MDBX_txn *txn) {
|
||||
MDBX_cursor mc;
|
||||
MDBX_val key, data;
|
||||
int rc;
|
||||
|
||||
pgno_t freecount = 0;
|
||||
mdbx_cursor_init(&mc, txn, FREE_DBI, NULL);
|
||||
rc = mdbx_cursor_init(&mc, txn, FREE_DBI, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
while ((rc = mdbx_cursor_get(&mc, &key, &data, MDBX_NEXT)) == 0)
|
||||
freecount += *(pgno_t *)data.iov_base;
|
||||
mdbx_tassert(txn, rc == MDBX_NOTFOUND);
|
||||
@@ -1321,7 +1341,9 @@ static void mdbx_audit(MDBX_txn *txn) {
|
||||
MDBX_xcursor mx;
|
||||
if (!(txn->mt_dbflags[i] & DB_VALID))
|
||||
continue;
|
||||
mdbx_cursor_init(&mc, txn, i, &mx);
|
||||
rc = mdbx_cursor_init(&mc, txn, i, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
if (txn->mt_dbs[i].md_root == P_INVALID)
|
||||
continue;
|
||||
count += txn->mt_dbs[i].md_branch_pages + txn->mt_dbs[i].md_leaf_pages +
|
||||
@@ -1348,7 +1370,9 @@ static void mdbx_audit(MDBX_txn *txn) {
|
||||
" total: %" PRIaPGNO " next_pgno: %" PRIaPGNO "\n",
|
||||
txn->mt_txnid, freecount, count + NUM_METAS,
|
||||
freecount + count + NUM_METAS, txn->mt_next_pgno);
|
||||
return MDBX_CORRUPTED;
|
||||
}
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
int mdbx_cmp(MDBX_txn *txn, MDBX_dbi dbi, const MDBX_val *a,
|
||||
@@ -2179,7 +2203,9 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp,
|
||||
/* Prepare to fetch more and coalesce */
|
||||
oldest = (flags & MDBX_LIFORECLAIM) ? mdbx_find_oldest(txn)
|
||||
: env->me_oldest[0];
|
||||
mdbx_cursor_init(&recur, txn, FREE_DBI, NULL);
|
||||
rc = mdbx_cursor_init(&recur, txn, FREE_DBI, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
goto fail;
|
||||
if (flags & MDBX_LIFORECLAIM) {
|
||||
/* Begin from oldest reader if any */
|
||||
if (oldest > 2) {
|
||||
@@ -2685,7 +2711,7 @@ fail:
|
||||
return rc;
|
||||
}
|
||||
|
||||
int mdbx_env_sync(MDBX_env *env, int force) {
|
||||
static int mdbx_env_sync_ex(MDBX_env *env, int force, int nonblock) {
|
||||
if (unlikely(!env))
|
||||
return MDBX_EINVAL;
|
||||
|
||||
@@ -2703,7 +2729,7 @@ int mdbx_env_sync(MDBX_env *env, int force) {
|
||||
(!env->me_txn0 || env->me_txn0->mt_owner != mdbx_thread_self());
|
||||
|
||||
if (outside_txn) {
|
||||
int rc = mdbx_txn_lock(env, false);
|
||||
int rc = mdbx_txn_lock(env, nonblock);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
}
|
||||
@@ -2732,7 +2758,7 @@ int mdbx_env_sync(MDBX_env *env, int force) {
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
|
||||
rc = mdbx_txn_lock(env, false);
|
||||
rc = mdbx_txn_lock(env, nonblock);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
|
||||
@@ -2759,6 +2785,10 @@ int mdbx_env_sync(MDBX_env *env, int force) {
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
int mdbx_env_sync(MDBX_env *env, int force) {
|
||||
return mdbx_env_sync_ex(env, force, false);
|
||||
}
|
||||
|
||||
/* Back up parent txn's cursors, then grab the originals for tracking */
|
||||
static int mdbx_cursor_shadow(MDBX_txn *src, MDBX_txn *dst) {
|
||||
MDBX_cursor *mc, *bk;
|
||||
@@ -3458,7 +3488,9 @@ static int mdbx_freelist_save(MDBX_txn *txn) {
|
||||
unsigned cleanup_reclaimed_pos = 0, refill_reclaimed_pos = 0;
|
||||
const bool lifo = (env->me_flags & MDBX_LIFORECLAIM) != 0;
|
||||
|
||||
mdbx_cursor_init(&mc, txn, FREE_DBI, NULL);
|
||||
rc = mdbx_cursor_init(&mc, txn, FREE_DBI, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
|
||||
/* MDBX_RESERVE cancels meminit in ovpage malloc (when no WRITEMAP) */
|
||||
const intptr_t clean_limit =
|
||||
@@ -4180,7 +4212,9 @@ int mdbx_txn_commit(MDBX_txn *txn) {
|
||||
MDBX_val data;
|
||||
data.iov_len = sizeof(MDBX_db);
|
||||
|
||||
mdbx_cursor_init(&mc, txn, MAIN_DBI, NULL);
|
||||
rc = mdbx_cursor_init(&mc, txn, MAIN_DBI, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
goto fail;
|
||||
for (i = CORE_DBS; i < txn->mt_numdbs; i++) {
|
||||
if (txn->mt_dbflags[i] & DB_DIRTY) {
|
||||
if (unlikely(TXN_DBI_CHANGED(txn, i))) {
|
||||
@@ -4241,11 +4275,17 @@ fail:
|
||||
|
||||
/* Read the environment parameters of a DB environment
|
||||
* before mapping it into memory. */
|
||||
static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta) {
|
||||
static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta,
|
||||
uint64_t *filesize) {
|
||||
assert(offsetof(MDBX_page, mp_meta) == PAGEHDRSZ);
|
||||
|
||||
int rc = mdbx_filesize(env->me_fd, filesize);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
|
||||
memset(meta, 0, sizeof(MDBX_meta));
|
||||
meta->mm_datasync_sign = MDBX_DATASIGN_WEAK;
|
||||
int rc = MDBX_CORRUPTED;
|
||||
rc = MDBX_CORRUPTED;
|
||||
|
||||
/* Read twice all meta pages so we can find the latest one. */
|
||||
unsigned loop_limit = NUM_METAS * 2;
|
||||
@@ -4302,8 +4342,8 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta) {
|
||||
}
|
||||
|
||||
if (page.mp_meta.mm_magic_and_version != MDBX_DATA_MAGIC) {
|
||||
mdbx_error("meta[%u] has invalid magic/version MDBX_DEVEL=%d",
|
||||
meta_number, MDBX_DEVEL);
|
||||
mdbx_error("meta[%u] has invalid magic/version %" PRIx64, meta_number,
|
||||
page.mp_meta.mm_magic_and_version);
|
||||
return ((page.mp_meta.mm_magic_and_version >> 8) != MDBX_MAGIC)
|
||||
? MDBX_INVALID
|
||||
: MDBX_VERSION_MISMATCH;
|
||||
@@ -4381,6 +4421,17 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta) {
|
||||
continue;
|
||||
}
|
||||
|
||||
/* LY: check filesize & used_bytes */
|
||||
const uint64_t used_bytes =
|
||||
page.mp_meta.mm_geo.next * (uint64_t)page.mp_meta.mm_psize;
|
||||
if (used_bytes > *filesize) {
|
||||
mdbx_notice("meta[%u] used-bytes (%" PRIu64 ") beyond filesize (%" PRIu64
|
||||
"), skip it",
|
||||
meta_number, used_bytes, *filesize);
|
||||
rc = MDBX_CORRUPTED;
|
||||
continue;
|
||||
}
|
||||
|
||||
/* LY: check mapsize limits */
|
||||
const uint64_t mapsize_min =
|
||||
page.mp_meta.mm_geo.lower * (uint64_t)page.mp_meta.mm_psize;
|
||||
@@ -4399,8 +4450,6 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta) {
|
||||
if (mapsize_max > MAX_MAPSIZE ||
|
||||
MAX_PAGENO < mdbx_roundup2((size_t)mapsize_max, env->me_os_psize) /
|
||||
(size_t)page.mp_meta.mm_psize) {
|
||||
const uint64_t used_bytes =
|
||||
page.mp_meta.mm_geo.next * (uint64_t)page.mp_meta.mm_psize;
|
||||
if (page.mp_meta.mm_geo.next - 1 > MAX_PAGENO ||
|
||||
used_bytes > MAX_MAPSIZE) {
|
||||
mdbx_notice("meta[%u] has too large max-mapsize (%" PRIu64 "), skip it",
|
||||
@@ -4563,7 +4612,30 @@ static int mdbx_sync_locked(MDBX_env *env, unsigned flags,
|
||||
|
||||
const size_t usedbytes = pgno_align2os_bytes(env, pending->mm_geo.next);
|
||||
if (env->me_sync_threshold && env->me_sync_pending >= env->me_sync_threshold)
|
||||
flags &= MDBX_WRITEMAP | MDBX_SHRINK_ALLOWED;
|
||||
flags &= MDBX_WRITEMAP | MDBX_SHRINK_ALLOWED; /* force steady */
|
||||
|
||||
/* LY: check conditions to shrink datafile */
|
||||
const pgno_t backlog_gap =
|
||||
pending->mm_dbs[FREE_DBI].md_depth + mdbx_backlog_extragap(env);
|
||||
pgno_t shrink = 0;
|
||||
if ((flags & MDBX_SHRINK_ALLOWED) && pending->mm_geo.shrink &&
|
||||
pending->mm_geo.now - pending->mm_geo.next >
|
||||
pending->mm_geo.shrink + backlog_gap) {
|
||||
const pgno_t aligner =
|
||||
pending->mm_geo.grow ? pending->mm_geo.grow : pending->mm_geo.shrink;
|
||||
const pgno_t with_backlog_gap = pending->mm_geo.next + backlog_gap;
|
||||
const pgno_t aligned = pgno_align2os_pgno(
|
||||
env, with_backlog_gap + aligner - with_backlog_gap % aligner);
|
||||
const pgno_t bottom =
|
||||
(aligned > pending->mm_geo.lower) ? aligned : pending->mm_geo.lower;
|
||||
if (pending->mm_geo.now > bottom) {
|
||||
flags &= MDBX_WRITEMAP | MDBX_SHRINK_ALLOWED; /* force steady */
|
||||
shrink = pending->mm_geo.now - bottom;
|
||||
pending->mm_geo.now = bottom;
|
||||
if (mdbx_meta_txnid_stable(env, head) == pending->mm_txnid_a)
|
||||
mdbx_meta_set_txnid(env, pending, pending->mm_txnid_a + 1);
|
||||
}
|
||||
}
|
||||
|
||||
/* LY: step#1 - sync previously written/updated data-pages */
|
||||
int rc = MDBX_RESULT_TRUE;
|
||||
@@ -4590,28 +4662,6 @@ static int mdbx_sync_locked(MDBX_env *env, unsigned flags,
|
||||
}
|
||||
}
|
||||
|
||||
/* LY: check conditions to shrink datafile */
|
||||
const pgno_t backlog_gap =
|
||||
pending->mm_dbs[FREE_DBI].md_depth + mdbx_backlog_extragap(env);
|
||||
pgno_t shrink = 0;
|
||||
if ((flags & MDBX_SHRINK_ALLOWED) && pending->mm_geo.shrink &&
|
||||
pending->mm_geo.now - pending->mm_geo.next >
|
||||
pending->mm_geo.shrink + backlog_gap) {
|
||||
const pgno_t aligner =
|
||||
pending->mm_geo.grow ? pending->mm_geo.grow : pending->mm_geo.shrink;
|
||||
const pgno_t with_backlog_gap = pending->mm_geo.next + backlog_gap;
|
||||
const pgno_t aligned = pgno_align2os_pgno(
|
||||
env, with_backlog_gap + aligner - with_backlog_gap % aligner);
|
||||
const pgno_t bottom =
|
||||
(aligned > pending->mm_geo.lower) ? aligned : pending->mm_geo.lower;
|
||||
if (pending->mm_geo.now > bottom) {
|
||||
shrink = pending->mm_geo.now - bottom;
|
||||
pending->mm_geo.now = bottom;
|
||||
if (mdbx_meta_txnid_stable(env, head) == pending->mm_txnid_a)
|
||||
mdbx_meta_set_txnid(env, pending, pending->mm_txnid_a + 1);
|
||||
}
|
||||
}
|
||||
|
||||
/* Steady or Weak */
|
||||
if (env->me_sync_pending == 0) {
|
||||
pending->mm_datasync_sign = mdbx_meta_sign(pending);
|
||||
@@ -5209,9 +5259,10 @@ int __cold mdbx_env_get_maxreaders(MDBX_env *env, unsigned *readers) {
|
||||
|
||||
/* Further setup required for opening an MDBX environment */
|
||||
static int __cold mdbx_setup_dxb(MDBX_env *env, int lck_rc) {
|
||||
uint64_t filesize_before_mmap;
|
||||
MDBX_meta meta;
|
||||
int rc = MDBX_RESULT_FALSE;
|
||||
int err = mdbx_read_header(env, &meta);
|
||||
int err = mdbx_read_header(env, &meta, &filesize_before_mmap);
|
||||
if (unlikely(err != MDBX_SUCCESS)) {
|
||||
if (lck_rc != /* lck exclusive */ MDBX_RESULT_TRUE || err != MDBX_ENODATA ||
|
||||
(env->me_flags & MDBX_RDONLY) != 0)
|
||||
@@ -5237,12 +5288,12 @@ static int __cold mdbx_setup_dxb(MDBX_env *env, int lck_rc) {
|
||||
if (unlikely(err != MDBX_SUCCESS))
|
||||
return err;
|
||||
|
||||
err = mdbx_ftruncate(env->me_fd, env->me_dbgeo.now);
|
||||
err = mdbx_ftruncate(env->me_fd, filesize_before_mmap = env->me_dbgeo.now);
|
||||
if (unlikely(err != MDBX_SUCCESS))
|
||||
return err;
|
||||
|
||||
#ifndef NDEBUG /* just for checking */
|
||||
err = mdbx_read_header(env, &meta);
|
||||
err = mdbx_read_header(env, &meta, &filesize_before_mmap);
|
||||
if (unlikely(err != MDBX_SUCCESS))
|
||||
return err;
|
||||
#endif
|
||||
@@ -5330,11 +5381,6 @@ static int __cold mdbx_setup_dxb(MDBX_env *env, int lck_rc) {
|
||||
env->me_dbgeo.shrink = pgno2bytes(env, meta.mm_geo.shrink);
|
||||
}
|
||||
|
||||
uint64_t filesize_before_mmap;
|
||||
err = mdbx_filesize(env->me_fd, &filesize_before_mmap);
|
||||
if (unlikely(err != MDBX_SUCCESS))
|
||||
return err;
|
||||
|
||||
const size_t expected_bytes =
|
||||
mdbx_roundup2(pgno2bytes(env, meta.mm_geo.now), env->me_os_psize);
|
||||
mdbx_ensure(env, expected_bytes >= used_bytes);
|
||||
@@ -5898,8 +5944,21 @@ int __cold mdbx_env_close_ex(MDBX_env *env, int dont_sync) {
|
||||
if (env->me_txn0 && env->me_txn0->mt_owner &&
|
||||
env->me_txn0->mt_owner != mdbx_thread_self())
|
||||
return MDBX_BUSY;
|
||||
if (!dont_sync)
|
||||
rc = mdbx_env_sync(env, true);
|
||||
if (!dont_sync) {
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
/* On windows, without blocking is impossible to determine whether another
|
||||
* process is running a writing transaction or not.
|
||||
* Because in the "owner died" condition kernel don't release
|
||||
* file lock immediately. */
|
||||
rc = mdbx_env_sync_ex(env, true, false);
|
||||
#else
|
||||
rc = mdbx_env_sync_ex(env, true, true);
|
||||
rc = (rc == MDBX_BUSY || rc == EAGAIN || rc == EACCES || rc == EBUSY ||
|
||||
rc == EWOULDBLOCK)
|
||||
? MDBX_SUCCESS
|
||||
: rc;
|
||||
#endif
|
||||
}
|
||||
}
|
||||
|
||||
VALGRIND_DESTROY_MEMPOOL(env);
|
||||
@@ -5926,7 +5985,7 @@ int __cold mdbx_env_close_ex(MDBX_env *env, int dont_sync) {
|
||||
return rc;
|
||||
}
|
||||
|
||||
int mdbx_env_close(MDBX_env *env) { return mdbx_env_close_ex(env, 0); }
|
||||
int mdbx_env_close(MDBX_env *env) { return mdbx_env_close_ex(env, false); }
|
||||
|
||||
/* Compare two items pointing at aligned unsigned int's. */
|
||||
static int __hot mdbx_cmp_int_ai(const MDBX_val *a, const MDBX_val *b) {
|
||||
@@ -6390,9 +6449,11 @@ static int mdbx_page_search(MDBX_cursor *mc, MDBX_val *key, int flags) {
|
||||
MDBX_cursor mc2;
|
||||
if (unlikely(TXN_DBI_CHANGED(mc->mc_txn, mc->mc_dbi)))
|
||||
return MDBX_BAD_DBI;
|
||||
mdbx_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, NULL);
|
||||
rc = mdbx_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
rc = mdbx_page_search(&mc2, &mc->mc_dbx->md_name, 0);
|
||||
if (rc)
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
{
|
||||
MDBX_val data;
|
||||
@@ -6576,7 +6637,9 @@ int mdbx_get(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data) {
|
||||
if (unlikely(txn->mt_flags & MDBX_TXN_BLOCKED))
|
||||
return MDBX_BAD_TXN;
|
||||
|
||||
mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
int rc = mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
return mdbx_cursor_set(&mc, key, data, MDBX_SET, &exact);
|
||||
}
|
||||
|
||||
@@ -6631,7 +6694,9 @@ static int mdbx_cursor_sibling(MDBX_cursor *mc, int move_right) {
|
||||
return rc;
|
||||
}
|
||||
|
||||
mdbx_cursor_push(mc, mp);
|
||||
rc = mdbx_cursor_push(mc, mp);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
if (!move_right)
|
||||
mc->mc_ki[mc->mc_top] = NUMKEYS(mp) - 1;
|
||||
|
||||
@@ -6711,7 +6776,9 @@ skip:
|
||||
leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
||||
|
||||
if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
||||
mdbx_xcursor_init1(mc, leaf);
|
||||
rc = mdbx_xcursor_init1(mc, leaf);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
}
|
||||
if (data) {
|
||||
if (unlikely((rc = mdbx_node_read(mc, leaf, data)) != MDBX_SUCCESS))
|
||||
@@ -6799,7 +6866,9 @@ static int mdbx_cursor_prev(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data,
|
||||
leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
||||
|
||||
if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
||||
mdbx_xcursor_init1(mc, leaf);
|
||||
rc = mdbx_xcursor_init1(mc, leaf);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
}
|
||||
if (data) {
|
||||
if (unlikely((rc = mdbx_node_read(mc, leaf, data)) != MDBX_SUCCESS))
|
||||
@@ -6966,7 +7035,9 @@ set1:
|
||||
}
|
||||
|
||||
if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
||||
mdbx_xcursor_init1(mc, leaf);
|
||||
rc = mdbx_xcursor_init1(mc, leaf);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
}
|
||||
if (likely(data)) {
|
||||
if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
||||
@@ -7041,8 +7112,9 @@ static int mdbx_cursor_first(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data) {
|
||||
|
||||
if (likely(data)) {
|
||||
if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
||||
mdbx_cassert(mc, mc->mc_xcursor != nullptr);
|
||||
mdbx_xcursor_init1(mc, leaf);
|
||||
rc = mdbx_xcursor_init1(mc, leaf);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
rc = mdbx_cursor_first(&mc->mc_xcursor->mx_cursor, data, NULL);
|
||||
if (unlikely(rc))
|
||||
return rc;
|
||||
@@ -7085,8 +7157,9 @@ static int mdbx_cursor_last(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data) {
|
||||
|
||||
if (likely(data)) {
|
||||
if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
||||
mdbx_cassert(mc, mc->mc_xcursor != nullptr);
|
||||
mdbx_xcursor_init1(mc, leaf);
|
||||
rc = mdbx_xcursor_init1(mc, leaf);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
rc = mdbx_cursor_last(&mc->mc_xcursor->mx_cursor, data, NULL);
|
||||
if (unlikely(rc))
|
||||
return rc;
|
||||
@@ -7139,7 +7212,9 @@ int mdbx_cursor_get(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data,
|
||||
if (data) {
|
||||
if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
||||
if (unlikely(!(mc->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED))) {
|
||||
mdbx_xcursor_init1(mc, leaf);
|
||||
rc = mdbx_xcursor_init1(mc, leaf);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
rc = mdbx_cursor_first(&mc->mc_xcursor->mx_cursor, data, NULL);
|
||||
if (unlikely(rc))
|
||||
return rc;
|
||||
@@ -7275,13 +7350,16 @@ int mdbx_cursor_get(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data,
|
||||
static int mdbx_cursor_touch(MDBX_cursor *mc) {
|
||||
int rc = MDBX_SUCCESS;
|
||||
|
||||
if (mc->mc_dbi >= CORE_DBS && !(*mc->mc_dbflag & (DB_DIRTY | DB_DUPDATA))) {
|
||||
if (mc->mc_dbi >= CORE_DBS &&
|
||||
(*mc->mc_dbflag & (DB_DIRTY | DB_DUPDATA)) == 0) {
|
||||
/* Touch DB record of named DB */
|
||||
MDBX_cursor mc2;
|
||||
MDBX_xcursor mcx;
|
||||
if (TXN_DBI_CHANGED(mc->mc_txn, mc->mc_dbi))
|
||||
return MDBX_BAD_DBI;
|
||||
mdbx_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, &mcx);
|
||||
rc = mdbx_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, &mcx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
rc = mdbx_page_search(&mc2, &mc->mc_dbx->md_name, MDBX_PS_MODIFY);
|
||||
if (unlikely(rc))
|
||||
return rc;
|
||||
@@ -7462,7 +7540,9 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data,
|
||||
return rc2;
|
||||
}
|
||||
assert(np->mp_flags & P_LEAF);
|
||||
mdbx_cursor_push(mc, np);
|
||||
rc2 = mdbx_cursor_push(mc, np);
|
||||
if (unlikely(rc2 != MDBX_SUCCESS))
|
||||
return rc2;
|
||||
mc->mc_db->md_root = np->mp_pgno;
|
||||
mc->mc_db->md_depth++;
|
||||
*mc->mc_dbflag |= DB_DIRTY;
|
||||
@@ -7810,7 +7890,9 @@ new_sub:
|
||||
? MDBX_CURRENT | MDBX_NOOVERWRITE | MDBX_NOSPILL
|
||||
: MDBX_CURRENT | MDBX_NOSPILL;
|
||||
} else {
|
||||
mdbx_xcursor_init1(mc, leaf);
|
||||
rc2 = mdbx_xcursor_init1(mc, leaf);
|
||||
if (unlikely(rc2 != MDBX_SUCCESS))
|
||||
return rc2;
|
||||
xflags = (flags & MDBX_NODUPDATA) ? MDBX_NOOVERWRITE | MDBX_NOSPILL
|
||||
: MDBX_NOSPILL;
|
||||
}
|
||||
@@ -7839,7 +7921,9 @@ new_sub:
|
||||
continue;
|
||||
if (m2->mc_pg[i] == mp) {
|
||||
if (m2->mc_ki[i] == mc->mc_ki[i]) {
|
||||
mdbx_xcursor_init2(m2, mx, dupdata_flag);
|
||||
rc2 = mdbx_xcursor_init2(m2, mx, dupdata_flag);
|
||||
if (unlikely(rc2 != MDBX_SUCCESS))
|
||||
return rc2;
|
||||
} else if (!insert_key && m2->mc_ki[i] < nkeys) {
|
||||
XCURSOR_REFRESH(m2, mp, m2->mc_ki[i]);
|
||||
}
|
||||
@@ -8359,8 +8443,10 @@ static void mdbx_node_shrink(MDBX_page *mp, unsigned indx) {
|
||||
* depend only on the parent DB.
|
||||
*
|
||||
* [in] mc The main cursor whose sorted-dups cursor is to be initialized. */
|
||||
static void mdbx_xcursor_init0(MDBX_cursor *mc) {
|
||||
static int mdbx_xcursor_init0(MDBX_cursor *mc) {
|
||||
MDBX_xcursor *mx = mc->mc_xcursor;
|
||||
if (unlikely(mx == nullptr))
|
||||
return MDBX_CORRUPTED;
|
||||
|
||||
mx->mx_cursor.mc_xcursor = NULL;
|
||||
mx->mx_cursor.mc_txn = mc->mc_txn;
|
||||
@@ -8375,6 +8461,7 @@ static void mdbx_xcursor_init0(MDBX_cursor *mc) {
|
||||
mx->mx_dbx.md_name.iov_base = NULL;
|
||||
mx->mx_dbx.md_cmp = mc->mc_dbx->md_dcmp;
|
||||
mx->mx_dbx.md_dcmp = NULL;
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
/* Final setup of a sorted-dups cursor.
|
||||
@@ -8382,8 +8469,10 @@ static void mdbx_xcursor_init0(MDBX_cursor *mc) {
|
||||
* [in] mc The main cursor whose sorted-dups cursor is to be initialized.
|
||||
* [in] node The data containing the MDBX_db record for the sorted-dup database.
|
||||
*/
|
||||
static void mdbx_xcursor_init1(MDBX_cursor *mc, MDBX_node *node) {
|
||||
static int mdbx_xcursor_init1(MDBX_cursor *mc, MDBX_node *node) {
|
||||
MDBX_xcursor *mx = mc->mc_xcursor;
|
||||
if (unlikely(mx == nullptr))
|
||||
return MDBX_CORRUPTED;
|
||||
|
||||
mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]);
|
||||
if (node->mn_flags & F_SUBDATA) {
|
||||
@@ -8422,6 +8511,8 @@ static void mdbx_xcursor_init1(MDBX_cursor *mc, MDBX_node *node) {
|
||||
sizeof(size_t))
|
||||
mx->mx_dbx.md_cmp = mdbx_cmp_clong;
|
||||
#endif */
|
||||
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
/* Fixup a sorted-dups cursor due to underlying update.
|
||||
@@ -8431,9 +8522,11 @@ static void mdbx_xcursor_init1(MDBX_cursor *mc, MDBX_node *node) {
|
||||
* [in] mc The main cursor whose sorted-dups cursor is to be fixed up.
|
||||
* [in] src_mx The xcursor of an up-to-date cursor.
|
||||
* [in] new_dupdata True if converting from a non-F_DUPDATA item. */
|
||||
static void mdbx_xcursor_init2(MDBX_cursor *mc, MDBX_xcursor *src_mx,
|
||||
int new_dupdata) {
|
||||
static int mdbx_xcursor_init2(MDBX_cursor *mc, MDBX_xcursor *src_mx,
|
||||
int new_dupdata) {
|
||||
MDBX_xcursor *mx = mc->mc_xcursor;
|
||||
if (unlikely(mx == nullptr))
|
||||
return MDBX_CORRUPTED;
|
||||
|
||||
mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]);
|
||||
if (new_dupdata) {
|
||||
@@ -8444,17 +8537,18 @@ static void mdbx_xcursor_init2(MDBX_cursor *mc, MDBX_xcursor *src_mx,
|
||||
mx->mx_dbflag = DB_VALID | DB_USRVALID | DB_DUPDATA;
|
||||
mx->mx_dbx.md_cmp = src_mx->mx_dbx.md_cmp;
|
||||
} else if (!(mx->mx_cursor.mc_flags & C_INITIALIZED)) {
|
||||
return;
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
mx->mx_db = src_mx->mx_db;
|
||||
mx->mx_cursor.mc_pg[0] = src_mx->mx_cursor.mc_pg[0];
|
||||
mdbx_debug("Sub-db -%u root page %" PRIaPGNO "", mx->mx_cursor.mc_dbi,
|
||||
mx->mx_db.md_root);
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
/* Initialize a cursor for a given transaction and database. */
|
||||
static void mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi,
|
||||
MDBX_xcursor *mx) {
|
||||
static int mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi,
|
||||
MDBX_xcursor *mx) {
|
||||
mc->mc_signature = MDBX_MC_SIGNATURE;
|
||||
mc->mc_next = NULL;
|
||||
mc->mc_backup = NULL;
|
||||
@@ -8469,16 +8563,23 @@ static void mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi,
|
||||
mc->mc_flags = 0;
|
||||
mc->mc_ki[0] = 0;
|
||||
mc->mc_xcursor = NULL;
|
||||
|
||||
if (txn->mt_dbs[dbi].md_flags & MDBX_DUPSORT) {
|
||||
mdbx_tassert(txn, mx != NULL);
|
||||
mx->mx_cursor.mc_signature = MDBX_MC_SIGNATURE;
|
||||
mc->mc_xcursor = mx;
|
||||
mdbx_xcursor_init0(mc);
|
||||
int rc = mdbx_xcursor_init0(mc);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
}
|
||||
|
||||
mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]);
|
||||
int rc = MDBX_SUCCESS;
|
||||
if (unlikely(*mc->mc_dbflag & DB_STALE)) {
|
||||
mdbx_page_search(mc, NULL, MDBX_PS_ROOTONLY);
|
||||
rc = mdbx_page_search(mc, NULL, MDBX_PS_ROOTONLY);
|
||||
rc = (rc != MDBX_NOTFOUND) ? rc : MDBX_SUCCESS;
|
||||
}
|
||||
return rc;
|
||||
}
|
||||
|
||||
int mdbx_cursor_open(MDBX_txn *txn, MDBX_dbi dbi, MDBX_cursor **ret) {
|
||||
@@ -8507,7 +8608,11 @@ int mdbx_cursor_open(MDBX_txn *txn, MDBX_dbi dbi, MDBX_cursor **ret) {
|
||||
size += sizeof(MDBX_xcursor);
|
||||
|
||||
if (likely((mc = malloc(size)) != NULL)) {
|
||||
mdbx_cursor_init(mc, txn, dbi, (MDBX_xcursor *)(mc + 1));
|
||||
int rc = mdbx_cursor_init(mc, txn, dbi, (MDBX_xcursor *)(mc + 1));
|
||||
if (unlikely(rc != MDBX_SUCCESS)) {
|
||||
free(mc);
|
||||
return rc;
|
||||
}
|
||||
if (txn->mt_cursors) {
|
||||
mc->mc_next = txn->mt_cursors[dbi];
|
||||
txn->mt_cursors[dbi] = mc;
|
||||
@@ -8518,7 +8623,6 @@ int mdbx_cursor_open(MDBX_txn *txn, MDBX_dbi dbi, MDBX_cursor **ret) {
|
||||
}
|
||||
|
||||
*ret = mc;
|
||||
|
||||
return MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
@@ -8557,8 +8661,7 @@ int mdbx_cursor_renew(MDBX_txn *txn, MDBX_cursor *mc) {
|
||||
if (unlikely(txn->mt_flags & MDBX_TXN_BLOCKED))
|
||||
return MDBX_BAD_TXN;
|
||||
|
||||
mdbx_cursor_init(mc, txn, mc->mc_dbi, mc->mc_xcursor);
|
||||
return MDBX_SUCCESS;
|
||||
return mdbx_cursor_init(mc, txn, mc->mc_dbi, mc->mc_xcursor);
|
||||
}
|
||||
|
||||
/* Return the count of duplicate data items for the current key */
|
||||
@@ -9399,8 +9502,9 @@ static int mdbx_cursor_del0(MDBX_cursor *mc) {
|
||||
if (!(node->mn_flags & F_SUBDATA))
|
||||
m3->mc_xcursor->mx_cursor.mc_pg[0] = NODEDATA(node);
|
||||
} else {
|
||||
mdbx_xcursor_init1(m3, node);
|
||||
m3->mc_xcursor->mx_cursor.mc_flags |= C_DEL;
|
||||
rc = mdbx_xcursor_init1(m3, node);
|
||||
if (likely(rc == MDBX_SUCCESS))
|
||||
m3->mc_xcursor->mx_cursor.mc_flags |= C_DEL;
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -9446,7 +9550,9 @@ static int mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data,
|
||||
mdbx_debug("====> delete db %u key [%s], data [%s]", dbi, DKEY(key),
|
||||
DVAL(data));
|
||||
|
||||
mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
rc = mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
|
||||
if (data) {
|
||||
op = MDBX_GET_BOTH;
|
||||
@@ -9935,11 +10041,12 @@ int mdbx_put(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data,
|
||||
if (unlikely(txn->mt_flags & (MDBX_TXN_RDONLY | MDBX_TXN_BLOCKED)))
|
||||
return (txn->mt_flags & MDBX_TXN_RDONLY) ? MDBX_EACCESS : MDBX_BAD_TXN;
|
||||
|
||||
mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
int rc = mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
mc.mc_next = txn->mt_cursors[dbi];
|
||||
txn->mt_cursors[dbi] = &mc;
|
||||
|
||||
int rc = MDBX_SUCCESS;
|
||||
/* LY: support for update (explicit overwrite) */
|
||||
if (flags & MDBX_CURRENT) {
|
||||
rc = mdbx_cursor_get(&mc, key, NULL, MDBX_SET);
|
||||
@@ -10264,7 +10371,9 @@ static int __cold mdbx_env_compact(MDBX_env *env, mdbx_filehandle_t fd) {
|
||||
MDBX_cursor mc;
|
||||
MDBX_val key, data;
|
||||
|
||||
mdbx_cursor_init(&mc, txn, FREE_DBI, NULL);
|
||||
rc = mdbx_cursor_init(&mc, txn, FREE_DBI, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
while ((rc = mdbx_cursor_get(&mc, &key, &data, MDBX_NEXT)) == 0)
|
||||
freecount += *(pgno_t *)data.iov_base;
|
||||
if (unlikely(rc != MDBX_NOTFOUND))
|
||||
@@ -10685,8 +10794,10 @@ int mdbx_dbi_open_ex(MDBX_txn *txn, const char *table_name, unsigned user_flags,
|
||||
key.iov_len = len;
|
||||
key.iov_base = (void *)table_name;
|
||||
MDBX_cursor mc;
|
||||
mdbx_cursor_init(&mc, txn, MAIN_DBI, NULL);
|
||||
int rc = mdbx_cursor_set(&mc, &key, &data, MDBX_SET, &exact);
|
||||
int rc = mdbx_cursor_init(&mc, txn, MAIN_DBI, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
rc = mdbx_cursor_set(&mc, &key, &data, MDBX_SET, &exact);
|
||||
if (unlikely(rc != MDBX_SUCCESS)) {
|
||||
if (rc != MDBX_NOTFOUND || !(user_flags & MDBX_CREATE))
|
||||
return rc;
|
||||
@@ -10822,7 +10933,9 @@ int __cold mdbx_dbi_stat(MDBX_txn *txn, MDBX_dbi dbi, MDBX_stat *arg,
|
||||
MDBX_cursor mc;
|
||||
MDBX_xcursor mx;
|
||||
/* Stale, must read the DB's root. cursor_init does it for us. */
|
||||
mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
int rc = mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
}
|
||||
return mdbx_stat0(txn->mt_env, &txn->mt_dbs[dbi], arg);
|
||||
}
|
||||
@@ -10926,7 +11039,9 @@ static int mdbx_drop0(MDBX_cursor *mc, int subs) {
|
||||
if (!mc->mc_db->md_overflow_pages && !subs)
|
||||
break;
|
||||
} else if (subs && (ni->mn_flags & F_SUBDATA)) {
|
||||
mdbx_xcursor_init1(mc, ni);
|
||||
rc = mdbx_xcursor_init1(mc, ni);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
goto done;
|
||||
rc = mdbx_drop0(&mc->mc_xcursor->mx_cursor, 0);
|
||||
if (unlikely(rc))
|
||||
goto done;
|
||||
@@ -11375,7 +11490,7 @@ int __cold mdbx_env_set_syncbytes(MDBX_env *env, size_t bytes) {
|
||||
return MDBX_EBADSIGN;
|
||||
|
||||
env->me_sync_threshold = bytes;
|
||||
return env->me_map ? mdbx_env_sync(env, 0) : MDBX_SUCCESS;
|
||||
return env->me_map ? mdbx_env_sync(env, false) : MDBX_SUCCESS;
|
||||
}
|
||||
|
||||
int __cold mdbx_env_set_oomfunc(MDBX_env *env, MDBX_oom_func *oomfunc) {
|
||||
@@ -11762,11 +11877,12 @@ int mdbx_replace(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *new_data,
|
||||
|
||||
MDBX_cursor mc;
|
||||
MDBX_xcursor mx;
|
||||
mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
int rc = mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
mc.mc_next = txn->mt_cursors[dbi];
|
||||
txn->mt_cursors[dbi] = &mc;
|
||||
|
||||
int rc;
|
||||
MDBX_val present_key = *key;
|
||||
if (F_ISSET(flags, MDBX_CURRENT | MDBX_NOOVERWRITE)) {
|
||||
/* в old_data значение для выбора конкретного дубликата */
|
||||
@@ -11889,10 +12005,12 @@ int mdbx_get_ex(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data,
|
||||
|
||||
MDBX_cursor mc;
|
||||
MDBX_xcursor mx;
|
||||
mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
int rc = mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
|
||||
int exact = 0;
|
||||
int rc = mdbx_cursor_set(&mc, key, data, MDBX_SET_KEY, &exact);
|
||||
rc = mdbx_cursor_set(&mc, key, data, MDBX_SET_KEY, &exact);
|
||||
if (unlikely(rc != MDBX_SUCCESS)) {
|
||||
if (rc == MDBX_NOTFOUND && values_count)
|
||||
*values_count = 0;
|
||||
@@ -12136,8 +12254,10 @@ int mdbx_set_attr(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data,
|
||||
MDBX_cursor mc;
|
||||
MDBX_xcursor mx;
|
||||
MDBX_val old_data;
|
||||
mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
int rc = mdbx_cursor_set(&mc, key, &old_data, MDBX_SET, NULL);
|
||||
int rc = mdbx_cursor_init(&mc, txn, dbi, &mx);
|
||||
if (unlikely(rc != MDBX_SUCCESS))
|
||||
return rc;
|
||||
rc = mdbx_cursor_set(&mc, key, &old_data, MDBX_SET, NULL);
|
||||
if (unlikely(rc != MDBX_SUCCESS)) {
|
||||
if (rc == MDBX_NOTFOUND && data) {
|
||||
mc.mc_next = txn->mt_cursors[dbi];
|
||||
|
||||
@@ -18,7 +18,7 @@
|
||||
#error "API version mismatch!"
|
||||
#endif
|
||||
|
||||
#define MDBX_VERSION_RELEASE 4
|
||||
#define MDBX_VERSION_RELEASE 5
|
||||
#define MDBX_VERSION_REVISION 1
|
||||
|
||||
/*LIBMDBX_EXPORTS*/ const mdbx_version_info mdbx_version = {
|
||||
|
||||
Reference in New Issue
Block a user