Выпуск с существенными доработками и новой функциональностью в память о российском борце [Иване Сергеевиче Ярыгине](https://ru.wikipedia.org/wiki/Ярыгин,_Иван_Сергеевич). На Олимпийских играх в Мюнхене в 1972 году Иван Ярыгин уложил всех соперников на лопатки, суммарно затратив менее 9 минут. Этот рекорд никем не побит до сих пор. Новое: ------ - Поддержка всех основных опций при сборке посредством CMake. - Требования к CMake понижены до версии 3.0.2 для возможности сборки для устаревших платформ. - Добавлена возможность профилирования работы GC в сложных и/или нагруженных сценариях (например Ethereum/Erigon). По-умолчанию соответствующий код отключен, а для его активации необходимо указать опцию сборки `MDBX_ENABLE_PROFGC=1`. - Добавлена функция `mdbx_env_warmup()` для "прогрева" БД с возможностью закрепления страниц в памяти. В утилиты `mdbx_chk`, `mdbx_copy` и `mdbx_dump` добавлены опции `-u` и `-U` для активации соответствующего функционала. - Отключение учета «грязных» страниц в не требующих этого режимах (`MDBX_WRITEMAP` при `MDBX_AVOID_MSYNC=0`). Доработка позволяет снизить накладные расходы и была запланирована давно, но откладывалась так как требовала других изменений. - Вытеснение из памяти (спиллинг) «грязных» страниц с учетом размера large/overflow-страниц. Доработка позволяет корректно соблюдать политику задаваемую опциями `MDBX_opt_txn_dp_limit`, `MDBX_opt_spill_max_denominator`, `MDBX_opt_spill_min_denominator` и была запланирована давно, но откладывалась так как требовала других изменений. - Для Windows в API добавлены UNICODE-зависимые определения макросов `MDBX_DATANAME`, `MDBX_LOCKNAME` и `MDBX_LOCK_SUFFIX`. - Переход на преимущественное использование типа `size_t` для уменьшения накладных расходов на платформе Эльбрус. - В API добавлены функции `mdbx_limits_valsize4page_max()` и `mdbx_env_get_valsize4page_max()` возвращающие максимальный размер в байтах значения, которое может быть размещена в одной large/overflow-странице, а не последовательности из двух или более таких страниц. Для таблиц с поддержкой дубликатов вынос значений на large/overflow-страницы не поддерживается, поэтому результат совпадает с `mdbx_limits_valsize_max()`. - В API добавлены функции `mdbx_limits_pairsize4page_max()`и `mdbx_env_get_pairsize4page_max()` возвращающие в байтах максимальный суммарный размер пары ключ-значение для их размещения на одной листовой страницы, без выноса значения на отдельную large/overflow-страницу. Для таблиц с поддержкой дубликатов вынос значений на large/overflow-страницы не поддерживается, поэтому результат определяет максимальный/допустимый суммарный размер пары ключ-значение. - Реализовано использование асинхронной (overlapped) записи в Windows, включая использования небуфферизированного ввода-вывода и `WriteGather()`. Это позволяет сократить накладные расходы и частично обойти проблемы Windows с низкой производительностью ввода-вывода, включая большие задержки `FlushFileBuffers()`. Новый код также обеспечивает консолидацию записываемых регионов на всех платформах, а на Windows использование событий (events) сведено к минимум, одновременно с автоматических использованием `WriteGather()`. Поэтому ожидается существенное снижение накладных расходов взаимодействия с ОС, а в Windows это ускорение, в некоторых сценариях, может быть кратным в сравнении с LMDB. - Добавлена опция сборки `MDBX_AVOID_MSYNC`, которая определяет поведение libmdbx в режиме `MDBX_WRITE_MAP` (когда данные изменяются непосредственно в отображенных в ОЗУ страницах БД): * Если `MDBX_AVOID_MSYNC=0` (по умолчанию на всех системах кроме Windows), то (как прежде) сохранение данных выполняется посредством `msync()`, либо `FlushViewOfFile()` на Windows. На платформах с полноценной подсистемой виртуальной памяти и адекватным файловым вводом-выводом это обеспечивает минимум накладных расходов (один системный вызов) и максимальную производительность. Однако, на Windows приводит к значительной деградации, в том числе из-за того что после `FlushViewOfFile()` требуется также вызов `FlushFileBuffers()` с массой проблем и суеты внутри ядра ОС. * Если `MDBX_AVOID_MSYNC=1` (по умолчанию только на Windows), то сохранение данных выполняется явной записью в файл каждой измененной страницы БД. Это требует дополнительных накладных расходов, как на отслеживание измененных страниц (ведение списков "грязных" страниц), так и на системные вызовы для их записи. Кроме этого, с точки зрения подсистемы виртуальной памяти ядра ОС, страницы БД измененные в ОЗУ и явно записанные в файл, могут либо оставаться "грязными" и быть повторно записаны ядром ОС позже, либо требовать дополнительных накладных расходов для отслеживания PTE (Page Table Entries), их модификации и дополнительного копирования данных. Тем не менее, по имеющейся информации, на Windows такой путь записи данных в целом обеспечивает более высокую производительность. - Улучшение эвристики включения авто-слияния записей GC. - Изменение формата LCK и семантики некоторых внутренних полей. Версии libmdbx использующие разный формат не смогут работать с одной БД одновременно, а только поочередно (LCK-файл переписывается при открытии первым открывающим БД процессом). - В `C++` API добавлены методы фиксации транзакции с получением информации о задержках. - Added `MDBX_HAVE_BUILT IN_CPU_SUPPORTS` build option to control use GCC's `__builtin_cpu_supports()` function, which could be unavailable on a fake OSes (macos, ios, android, etc). Исправления (без корректировок вышеперечисленных новых функций): ---------------------------------------------------------------- - Устранения ряда предупреждений при сборке посредством MinGW. - Устранение ложно-положительных сообщений от Valgrind об использовании не инициализированных данных из-за выравнивающих зазоров в `struct troika`. - Исправлен возврат неожиданной ошибки `MDBX_BUSY` из функций `mdbx_env_set_option()`, `mdbx_env_set_syncbytes()` и `mdbx_env_set_syncperiod()`. - Небольшие исправления для совместимости с CMake 3.8 - Больше контроля и осторожности (паранойи) для страховки от дефектов `mremap()`. - Костыль для починки сборки со старыми версиями `stdatomic.h` из GNU Lib C, где макросы `ATOMIC_*_LOCK_FREE` ошибочно переопределяются через функции. - Использование `fcntl64(F_GETLK64/F_SETLK64/F_SETLKW64)` при наличии. Это решает проблему срабатывания проверочного утверждения при сборке для платформ где тип `off_t` шире соответствующих полей `структуры flock`, используемой для блокировки файлов. - Доработан сбор информации о задержках при фиксации транзакций: * Устранено искажение замеров длительности обновления GC при включении отладочного внутреннего аудита; * Защита от undeflow-нуля только общей задержки в метриках, чтобы исключить ситуации, когда сумма отдельных стадий больше общей длительности. - Ряд исправлений для устранения срабатываний проверочных утверждения в отладочных сборках. - Более осторожное преобразование к типу `mdbx_tid_t` для устранения предупреждений. - Исправление лишнего сброса данных на диск в режиме `MDBX_SAFE_NOSYNC` при обновлении GC. - Fixed an extra check for `MDBX_APPENDDUP` inside `mdbx_cursor_put()` which could result in returning `MDBX_EKEYMISMATCH` for valid cases. - Fixed nasty `clz()` bug (by using `_BitScanReverse()`, only MSVC builds affected). Мелочи: ------- - Исторические ссылки cвязанные с удалённым на ~~github~~ проектом перенаправлены на [web.archive.org](https://web.archive.org/web/https://github.com/erthink/libmdbx). - Синхронизированны конструкции CMake между проектами. - Добавлено предупреждение о небезопасности RISC-V. - Добавлено описание параметров `MDBX_debug_func` и `MDBX_debug_func`. - Добавлено обходное решение для минимизации ложно-положительных конфликтов при использовании файловых блокировок в Windows. - Проверка атомарности C11-операций c 32/64-битными данными. - Уменьшение в 42 раза значения по-умолчанию для `me_options.dp_limit` в отладочных сборках. - Добавление платформы `gcc-riscv64-linux-gnu` в список для цели `cross-gcc`. - Небольшие правки скрипта `long_stochastic.sh` для работы в Windows. - Удаление ненужного вызова `LockFileEx()` внутри `mdbx_env_copy()`. - Добавлено описание использования файловых дескрипторов в различных режимах. - Добавлено использование `_CrtDbgReport()` в отладочных сборках. - Fixed an extra ensure/assertion check of `oldest_reader` inside `txn_end()`. - Removed description of deprecated usage of `MDBX_NODUPDATA`. - Fixed regression ASAN/Valgring-enabled builds. - Fixed minor MingGW warning. 64 files changed, 5573 insertions(+), 2510 deletions(-) Signed-off-by: Леонид Юрьев (Leonid Yuriev) <leo@yuriev.ru> |
||
|---|---|---|
| cmake | ||
| docs | ||
| example | ||
| packages | ||
| src | ||
| test | ||
| .clang-format | ||
| .gitignore | ||
| .le.ini | ||
| AUTHORS | ||
| ChangeLog.md | ||
| CMakeLists.txt | ||
| CMakeSettings.json | ||
| COPYRIGHT | ||
| GNUmakefile | ||
| LICENSE | ||
| Makefile | ||
| mdbx.h | ||
| mdbx.h++ | ||
| README.md | ||
| TODO.md | ||
The origin has been migrated to GitFlic
since on 2022-04-15 the Github administration, without any warning
nor explanation, deleted libmdbx along with a lot of other projects,
simultaneously blocking access for many developers.
For the same reason Github is blacklisted forever.
GitFlic's developers plan to support other languages, including English 和 中文, in the near future.
Основной репозиторий перемещен на GitFlic
так как 15 апреля 2022 администрация Github без предупреждения и
объяснения причин удалила libmdbx вместе с массой других проектов,
одновременно заблокировав доступ многим разработчикам.
По этой же причине Github навсегда занесен в черный список.
The Future will (be) Positive. Всё будет хорошо.
Please refer to the online documentation with
CAPI description and pay attention to theC++API.
Questions, feedback and suggestions are welcome to the Telegram' group.
libmdbx
libmdbx is an extremely fast, compact, powerful, embedded, transactional key-value database, with permissive license. libmdbx has a specific set of properties and capabilities, focused on creating unique lightweight solutions.
-
Allows a swarm of multi-threaded processes to ACIDly read and update several key-value maps and multimaps in a locally-shared database.
-
Provides extraordinary performance, minimal overhead through Memory-Mapping and
Olog(N)operations costs by virtue of B+ tree. -
Requires no maintenance and no crash recovery since it doesn't use WAL, but that might be a caveat for write-intensive workloads with durability requirements.
-
Compact and friendly for fully embedding. Only ≈25KLOC of
C11, ≈64K x86 binary code of core, no internal threads neither server process(es), but implements a simplified variant of the Berkeley DB and dbm API. -
Enforces serializability for writers just by single mutex and affords wait-free for parallel readers without atomic/interlocked operations, while writing and reading transactions do not block each other.
-
Guarantee data integrity after crash unless this was explicitly neglected in favour of write performance.
-
Supports Linux, Windows, MacOS, Android, iOS, FreeBSD, DragonFly, Solaris, OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with POSIX.1-2008.
Historically, libmdbx is a deeply revised and extended descendant of the amazing Lightning Memory-Mapped Database. libmdbx inherits all benefits from LMDB, but resolves some issues and adds a set of improvements.
The next version is under active non-public development from scratch and will be
released as MithrilDB and libmithrildb for libraries & packages.
Admittedly mythical Mithril is
resembling silver but being stronger and lighter than steel. Therefore
MithrilDB is a rightly relevant name.
MithrilDB will be radically different from libmdbx by the new database format and API based on C++17, as well as the Apache 2.0 License. The goal of this revolution is to provide a clearer and robust API, add more features and new valuable properties of the database.
$ objdump -f -h -j .text libmdbx.so
libmdbx.so: формат файла elf64-e2k
архитектура: elbrus-v6:64, флаги 0x00000150:
HAS_SYMS, DYNAMIC, D_PAGED
начальный адрес 0x0000000000021680
Разделы:
Idx Name Разм VMA LMA Фа смещ. Выр.
10 .text 000ddd28 0000000000021680 0000000000021680 00021680 2**3
CONTENTS, ALLOC, LOAD, READONLY, CODE
$ cc --version
lcc:1.26.12:Jun-05-2022:e2k-v6-linux
gcc (GCC) 9.3.0 compatible
Table of Contents
Characteristics
Features
-
Key-value data model, keys are always sorted.
-
Multiple key-value sub-databases within a single datafile.
-
Range lookups, including range query estimation.
-
Efficient support for short fixed length keys, including native 32/64-bit integers.
-
Ultra-efficient support for multimaps. Multi-values sorted, searchable and iterable. Keys stored without duplication.
-
Data is memory-mapped and accessible directly/zero-copy. Traversal of database records is extremely-fast.
-
Transactions for readers and writers, ones do not block others.
-
Writes are strongly serialized. No transaction conflicts nor deadlocks.
-
Readers are non-blocking, notwithstanding snapshot isolation.
-
Nested write transactions.
-
Reads scale linearly across CPUs.
-
Continuous zero-overhead database compactification.
-
Automatic on-the-fly database size adjustment.
-
Customizable database page size.
-
Olog(N)cost of lookup, insert, update, and delete operations by virtue of B+ tree characteristics. -
Online hot backup.
-
Append operation for efficient bulk insertion of pre-sorted data.
-
No WAL nor any transaction journal. No crash recovery needed. No maintenance is required.
-
No internal cache and/or memory management, all done by basic OS services.
Limitations
- Page size: a power of 2, minimum
256(mostly for testing), maximum65536bytes, default4096bytes. - Key size: minimum
0, maximum ≈½ pagesize (2022bytes for default 4K pagesize,32742bytes for 64K pagesize). - Value size: minimum
0, maximum2146435072(0x7FF00000) bytes for maps, ≈½ pagesize for multimaps (2022bytes for default 4K pagesize,32742bytes for 64K pagesize). - Write transaction size: up to
1327217884pages (4.944272TiB for default 4K pagesize,79.108351TiB for 64K pagesize). - Database size: up to
2147483648pages (≈8.0TiB for default 4K pagesize, ≈128.0TiB for 64K pagesize). - Maximum sub-databases:
32765.
Gotchas
-
There cannot be more than one writer at a time, i.e. no more than one write transaction at a time.
-
libmdbx is based on B+ tree, so access to database pages is mostly random. Thus SSDs provide a significant performance boost over spinning disks for large databases.
-
libmdbx uses shadow paging instead of WAL. Thus syncing data to disk might be a bottleneck for write intensive workload.
-
libmdbx uses copy-on-write for snapshot isolation during updates, but read transactions prevents recycling an old retired/freed pages, since it read ones. Thus altering of data during a parallel long-lived read operation will increase the process work set, may exhaust entire free database space, the database can grow quickly, and result in performance degradation. Try to avoid long running read transactions.
-
libmdbx is extraordinarily fast and provides minimal overhead for data access, so you should reconsider using brute force techniques and double check your code. On the one hand, in the case of libmdbx, a simple linear search may be more profitable than complex indexes. On the other hand, if you make something suboptimally, you can notice detrimentally only on sufficiently large data.
Comparison with other databases
For now please refer to chapter of "BoltDB comparison with other databases" which is also (mostly) applicable to libmdbx.
Improvements beyond LMDB
libmdbx is superior to legendary LMDB in terms of features and reliability, not inferior in performance. In comparison to LMDB, libmdbx make things "just work" perfectly and out-of-the-box, not silently and catastrophically break down. The list below is pruned down to the improvements most notable and obvious from the user's point of view.
Added Features
-
Keys could be more than 2 times longer than LMDB.
For DB with default page size libmdbx support keys up to 2022 bytes and up to 32742 bytes for 64K page size. LMDB allows key size up to 511 bytes and may silently loses data with large values.
-
Up to 30% faster than LMDB in CRUD benchmarks.
Benchmarks of the in-tmpfs scenarios, that tests the speed of the engine itself, showned that libmdbx 10-20% faster than LMDB, and up to 30% faster when libmdbx compiled with specific build options which downgrades several runtime checks to be match with LMDB behaviour.
These and other results could be easily reproduced with ioArena just by
make bench-quartetcommand, including comparisons with RockDB and WiredTiger. -
Automatic on-the-fly database size adjustment, both increment and reduction.
libmdbx manages the database size according to parameters specified by
mdbx_env_set_geometry()function, ones include the growth step and the truncation threshold.Unfortunately, on-the-fly database size adjustment doesn't work under Wine due to its internal limitations and unimplemented functions, i.e. the
MDBX_UNABLE_EXTEND_MAPSIZEerror will be returned. -
Automatic continuous zero-overhead database compactification.
During each commit libmdbx merges a freeing pages which adjacent with the unallocated area at the end of file, and then truncates unused space when a lot enough of.
-
The same database format for 32- and 64-bit builds.
libmdbx database format depends only on the endianness but not on the bitness.
-
LIFO policy for Garbage Collection recycling. This can significantly increase write performance due write-back disk cache up to several times in a best case scenario.
LIFO means that for reuse will be taken the latest becomes unused pages. Therefore the loop of database pages circulation becomes as short as possible. In other words, the set of pages, that are (over)written in memory and on disk during a series of write transactions, will be as small as possible. Thus creates ideal conditions for the battery-backed or flash-backed disk cache efficiency.
-
Fast estimation of range query result volume, i.e. how many items can be found between a
KEY1and aKEY2. This is a prerequisite for build and/or optimize query execution plans.libmdbx performs a rough estimate based on common B-tree pages of the paths from root to corresponding keys.
-
mdbx_chkutility for database integrity check. Since version 0.9.1, the utility supports checking the database using any of the three meta pages and the ability to switch to it. -
Support for opening databases in the exclusive mode, including on a network share.
-
Zero-length for keys and values.
-
Ability to determine whether the particular data is on a dirty page or not, that allows to avoid copy-out before updates.
-
Extended information of whole-database, sub-databases, transactions, readers enumeration.
libmdbx provides a lot of information, including dirty and leftover pages for a write transaction, reading lag and holdover space for read transactions.
- Extended update and delete operations.
libmdbx allows one at once with getting previous value and addressing the particular item from multi-value with the same key.
-
Useful runtime options for tuning engine to application's requirements and use cases specific.
-
Automated steady sync-to-disk upon several thresholds and/or timeout via cheap polling.
-
Sequence generation and three persistent 64-bit markers.
-
Handle-Slow-Readers callback to resolve a database full/overflow issues due to long-lived read transaction(s).
-
Ability to determine whether the cursor is pointed to a key-value pair, to the first, to the last, or not set to anything.
Other fixes and specifics
-
Fixed more than 10 significant errors, in particular: page leaks, wrong sub-database statistics, segfault in several conditions, nonoptimal page merge strategy, updating an existing record with a change in data size (including for multimap), etc.
-
All cursors can be reused and should be closed explicitly, regardless ones were opened within a write or read transaction.
-
Opening database handles are spared from race conditions and pre-opening is not needed.
-
Returning
MDBX_EMULTIVALerror in case of ambiguous update or delete. -
Guarantee of database integrity even in asynchronous unordered write-to-disk mode.
libmdbx propose additional trade-off by
MDBX_SAFE_NOSYNCwith append-like manner for updates, that avoids database corruption after a system crash contrary to LMDB. Nevertheless, theMDBX_UTTERLY_NOSYNCmode is available to match LMDB's behaviour forMDB_NOSYNC. -
On MacOS & iOS the
fcntl(F_FULLFSYNC)syscall is used by default to synchronize data with the disk, as this is the only way to guarantee data durability in case of power failure. Unfortunately, in scenarios with high write intensity, the use ofF_FULLFSYNCsignificantly degrades performance compared to LMDB, where thefsync()syscall is used. Therefore, libmdbx allows you to override this behavior by defining theMDBX_OSX_SPEED_INSTEADOF_DURABILITY=1option while build the library. -
On Windows the
LockFileEx()syscall is used for locking, since it allows place the database on network drives, and provides protection against incompetent user actions (aka poka-yoke). Therefore libmdbx may be a little lag in performance tests from LMDB where the named mutexes are used.
History
Historically, libmdbx is a deeply revised and extended descendant of the Lightning Memory-Mapped Database. At first the development was carried out within the ReOpenLDAP project. About a year later libmdbx was separated into a standalone project, which was presented at Highload++ 2015 conference.
Since 2017 libmdbx is used in Fast Positive Tables, and development is funded by Positive Technologies.
On 2022-04-15 the Github administration, without any warning nor
explanation, deleted libmdbx along with a lot of other projects,
simultaneously blocking access for many developers. Therefore on
2022-04-21 we have migrated to a reliable trusted infrastructure.
The origin for now is at GitFlic
with backup at ABF by ROSA Лаб.
For the same reason Github is blacklisted forever.
Acknowledgments
Howard Chu hyc@openldap.org is the author of LMDB, from which originated the libmdbx in 2015.
Martin Hedenfalk martin@bzero.se is the author of btree.c code, which
was used to begin development of LMDB.
Usage
Currently, libmdbx is only available in a source code form. Packages support for common Linux distributions is planned in the future, since release the version 1.0.
Source code embedding
libmdbx provides two official ways for integration in source code form:
-
Using an amalgamated source code which available in the releases section on GitFlic.
An amalgamated source code includes all files required to build and use libmdbx, but not for testing libmdbx itself. Beside the releases an amalgamated sources could be created any time from the original clone of git repository on Linux by executing
make dist. As a result, the desired set of files will be formed in thedistsubdirectory. -
Adding the complete source code as a
git submodulefrom the origin git repository on GitFlic.This allows you to build as libmdbx and testing tool. On the other hand, this way requires you to pull git tags, and use C++11 compiler for test tool.
Please, avoid using any other techniques. Otherwise, at least
don't ask for support and don't name such chimeras libmdbx.
Building and Testing
Both amalgamated and original source code provides build through the use
CMake or GNU
Make with
bash. All build ways
are completely traditional and have minimal prerequirements like
build-essential, i.e. the non-obsolete C/C++ compiler and a
SDK for the
target platform. Obviously you need building tools itself, i.e. git,
cmake or GNU make with bash. For your convenience, make help
and make options are also available for listing existing targets
and build options respectively.
The only significant specificity is that git' tags are required
to build from complete (not amalgamated) source codes.
Executing git fetch --tags --force --prune is enough to get ones,
and --unshallow or --update-shallow is required for shallow cloned case.
So just using CMake or GNU Make in your habitual manner and feel free to fill an issue or make pull request in the case something will be unexpected or broken down.
Testing
The amalgamated source code does not contain any tests for or several reasons. Please read the explanation and don't ask to alter this. So for testing libmdbx itself you need a full source code, i.e. the clone of a git repository, there is no option.
The full source code of libmdbx has a test subdirectory with minimalistic test "framework".
Actually yonder is a source code of the mdbx_test – console utility which has a set of command-line options that allow construct and run a reasonable enough test scenarios.
This test utility is intended for libmdbx's developers for testing library itself, but not for use by users.
Therefore, only basic information is provided:
- There are few CRUD-based test cases (hill, TTL, nested, append, jitter, etc),
which can be combined to test the concurrent operations within shared database in a multi-processes environment.
This is the
basictest scenario. - The
Makefileprovide several self-described targets for testing:smoke,test,check,memcheck,test-valgrind,test-asan,test-leak,test-ubsan,cross-gcc,cross-qemu,gcc-analyzer,smoke-fault,smoke-singleprocess,test-singleprocess, 'long-test'. Please runmake --helpif doubt. - In addition to the
mdbx_testutility, there is the scriptlong_stochastic.sh, which callsmdbx_testby going through set of modes and options, with gradually increasing the number of operations and the size of transactions. This script is used for mostly of all automatic testing, includingMakefiletargets and Continuous Integration. - Brief information of available command-line options is available by
--help. However, you should dive into source code to get all, there is no option.
Anyway, no matter how thoroughly the libmdbx is tested, you should rely only on your own tests for a few reasons:
- Mostly of all use cases are unique. So it is no warranty that your use case was properly tested, even the libmdbx's tests engages stochastic approach.
- If there are problems, then your test on the one hand will help to verify whether you are using libmdbx correctly, on the other hand it will allow to reproduce the problem and insure against regression in a future.
- Actually you should rely on than you checked by yourself or take a risk.
Common important details
Build reproducibility
By default libmdbx track build time via MDBX_BUILD_TIMESTAMP build option and macro.
So for a reproducible builds you should predefine/override it to known fixed string value.
For instance:
- for reproducible build with make:
make MDBX_BUILD_TIMESTAMP=unknown... - or during configure by CMake:
cmake -DMDBX_BUILD_TIMESTAMP:STRING=unknown...
Of course, in addition to this, your toolchain must ensure the reproducibility of builds. For more information please refer to reproducible-builds.org.
Containers
There are no special traits nor quirks if you use libmdbx ONLY inside the single container. But in a cross-container cases or with a host-container(s) mix the two major things MUST be guaranteed:
-
Coherence of memory mapping content and unified page cache inside OS kernel for host and all container(s) operated with a DB. Basically this means must be only a single physical copy of each memory mapped DB' page in the system memory.
-
Uniqueness of PID values and/or a common space for ones:
- for POSIX systems: PID uniqueness for all processes operated with a DB.
I.e. the
--pid=hostis required for run DB-aware processes inside Docker, either without host interaction a--pid=container:<name|id>with the same name/id. - for non-POSIX (i.e. Windows) systems: inter-visibility of processes handles.
I.e. the
OpenProcess(SYNCHRONIZE, ..., PID)must return reasonable error, includingERROR_ACCESS_DENIED, but not theERROR_INVALID_PARAMETERas for an invalid/non-existent PID.
- for POSIX systems: PID uniqueness for all processes operated with a DB.
I.e. the
DSO/DLL unloading and destructors of Thread-Local-Storage objects
When building libmdbx as a shared library or use static libmdbx as a part of another dynamic library, it is advisable to make sure that your system ensures the correctness of the call destructors of Thread-Local-Storage objects when unloading dynamic libraries.
If this is not the case, then unloading a dynamic-link library with libmdbx code inside, can result in either a resource leak or a crash due to calling destructors from an already unloaded DSO/DLL object. The problem can only manifest in a multithreaded application, which makes the unloading of shared dynamic libraries with libmdbx code inside, after using libmdbx. It is known that TLS-destructors are properly maintained in the following cases:
-
On all modern versions of Windows (Windows 7 and later).
-
On systems with the
__cxa_thread_atexit_impl()function in the standard C library, including systems with GNU libc version 2.18 and later. -
On systems with libpthread/ntpl from GNU libc with bug fixes #21031 and #21032, or where there are no similar bugs in the pthreads implementation.
Linux and other platforms with GNU Make
To build the library it is enough to execute make all in the directory
of source code, and make check to execute the basic tests.
If the make installed on the system is not GNU Make, there will be a
lot of errors from make when trying to build. In this case, perhaps you
should use gmake instead of make, or even gnu-make, etc.
FreeBSD and related platforms
As a rule on BSD and it derivatives the default is to use Berkeley Make and Bash is not installed.
So you need to install the required components: GNU Make, Bash, C and C++
compilers compatible with GCC or CLANG. After that, to build the
library, it is enough to execute gmake all (or make all) in the
directory with source code, and gmake check (or make check) to run
the basic tests.
Windows
For build libmdbx on Windows the original CMake and Microsoft Visual
Studio 2019 are
recommended. Please use the recent versions of CMake, Visual Studio and Windows
SDK to avoid troubles with C11 support and alignas() feature.
For build by MinGW the 10.2 or recent version coupled with a modern CMake are required. So it is recommended to use chocolatey to install and/or update the ones.
Another ways to build is potentially possible but not supported and will not.
The CMakeLists.txt or GNUMakefile scripts will probably need to be modified accordingly.
Using other methods do not forget to add the ntdll.lib to linking.
It should be noted that in libmdbx was efforts to avoid
runtime dependencies from CRT and other MSVC libraries.
For this is enough to pass the -DMDBX_WITHOUT_MSVC_CRT:BOOL=ON option
during configure by CMake.
An example of running a basic test script can be found in the CI-script for AppVeyor. To run the long stochastic test scenario, bash is required, and such testing is recommended with placing the test data on the RAM-disk.
Windows Subsystem for Linux
libmdbx could be used in WSL2
but NOT in WSL1 environment.
This is a consequence of the fundamental shortcomings of WSL1 and cannot be fixed.
To avoid data loss, libmdbx returns the ENOLCK (37, "No record locks available")
error when opening the database in a WSL1 environment.
MacOS
Current native build tools for
MacOS include GNU Make, CLANG and an outdated version of Bash.
Therefore, to build the library, it is enough to run make all in the
directory with source code, and run make check to execute the base
tests. If something goes wrong, it is recommended to install
Homebrew and try again.
To run the long stochastic test scenario, you
will need to install the current (not outdated) version of
Bash. To do this, we
recommend that you install Homebrew and then execute
brew install bash.
Android
We recommend using CMake to build libmdbx for Android. Please refer to the official guide.
iOS
To build libmdbx for iOS, we recommend using CMake with the "toolchain file" from the ios-cmake project.
API description
Please refer to the online libmdbx API reference and/or see the mdbx.h++ and mdbx.h headers.
Bindings
| Runtime | Repo | Author |
|---|---|---|
| Scala | mdbx4s | David Bouyssié |
| Haskell | libmdbx-hs | Francisco Vallarino |
| NodeJS, Deno | lmdbx-js | Kris Zyp |
| NodeJS | node-mdbx | Сергей Федотов |
| Ruby | ruby-mdbx | Mahlon E. Smith |
| Go | mdbx-go | Alex Sharov |
| Nim | NimDBX | Jens Alfke |
| Lua | lua-libmdbx | Masatoshi Fukunaga |
| Rust | libmdbx-rs | Artem Vorotnikov |
| Rust | mdbx | gcxfd |
| Java | mdbxjni | Castor Technologies |
| Python (draft) | python-bindings branch | Noel Kuntze |
| .NET (obsolete) | mdbx.NET | Jerry Wang |
Performance comparison
All benchmarks were done in 2015 by IOArena and multiple scripts runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz (2 physical cores, 4 HyperThreading cores), 8 Gb RAM, SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
Integral performance
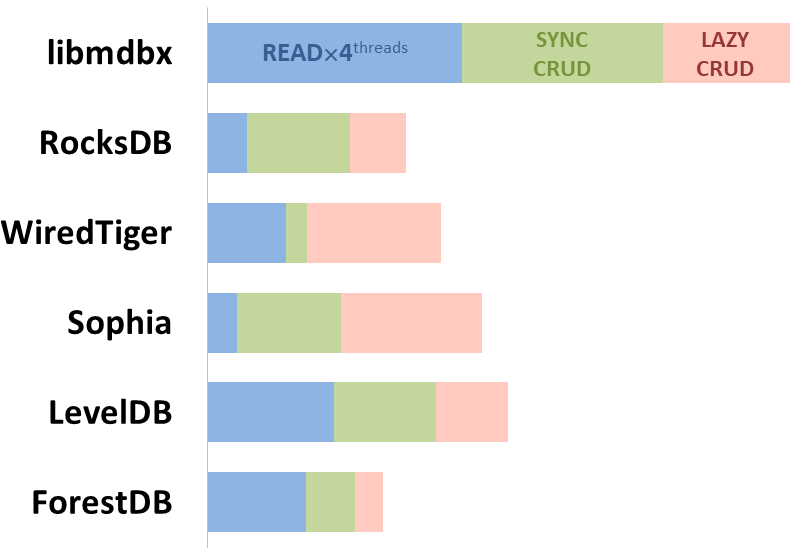
Here showed sum of performance metrics in 3 benchmarks:
-
Read/Search on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores);
-
Transactions with CRUD operations in sync-write mode (fdatasync is called after each transaction);
-
Transactions with CRUD operations in lazy-write mode (moment to sync data to persistent storage is decided by OS).
Reasons why asynchronous mode isn't benchmarked here:
-
It doesn't make sense as it has to be done with DB engines, oriented for keeping data in memory e.g. Tarantool, Redis), etc.
-
Performance gap is too high to compare in any meaningful way.
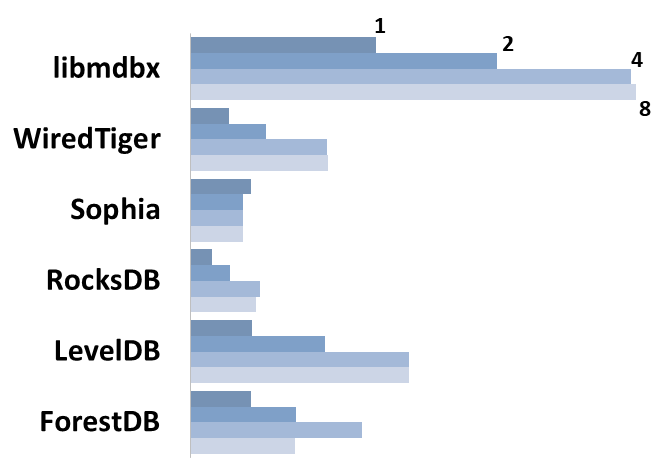
Read Scalability
Summary performance with concurrent read/search queries in 1-2-4-8 threads on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores).
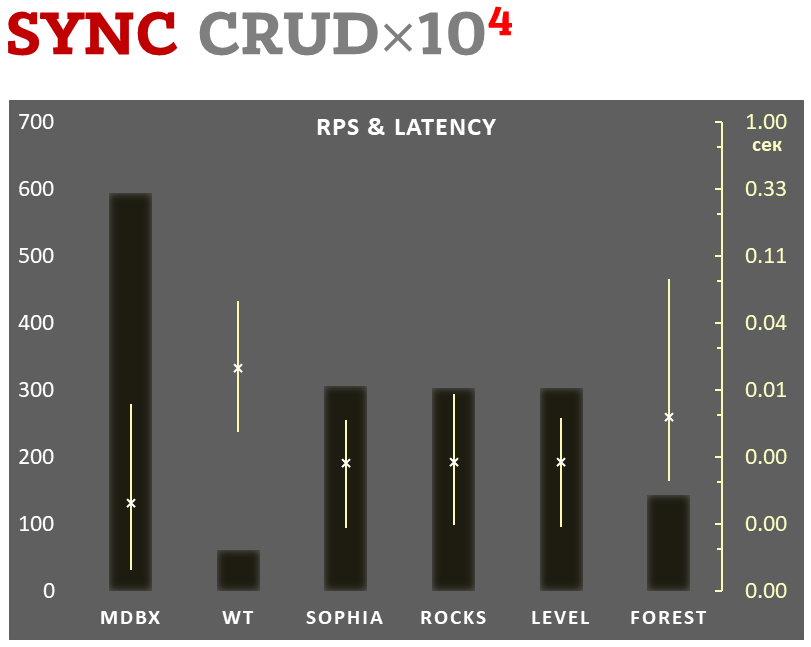
Sync-write mode
-
Linear scale on left and dark rectangles mean arithmetic mean transactions per second;
-
Logarithmic scale on right is in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
10,000 transactions in sync-write mode. In case of a crash all data is consistent and conforms to the last successful transaction. The fdatasync syscall is used after each write transaction in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database and after full run the database contains 10,000 small key-value records.
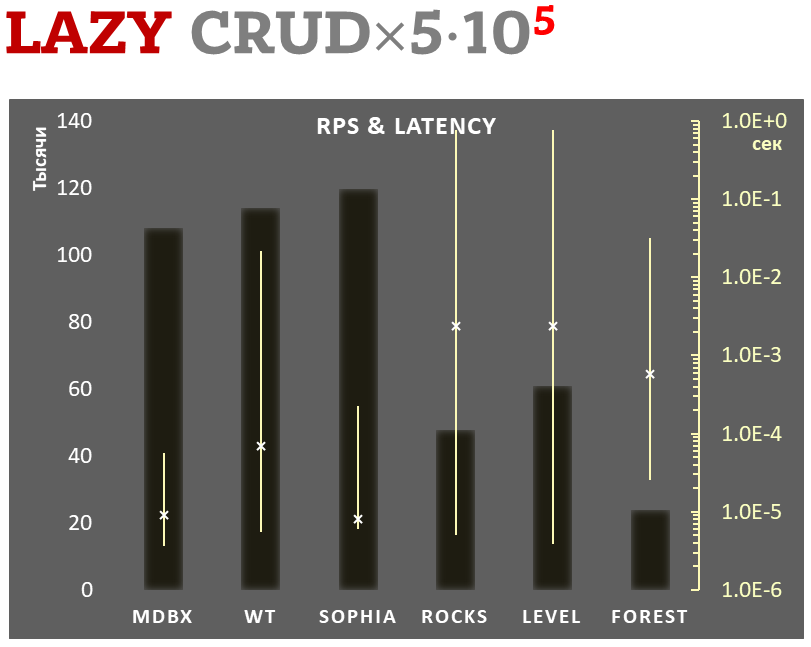
Lazy-write mode
-
Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
-
Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
100,000 transactions in lazy-write mode. In case of a crash all data is consistent and conforms to the one of last successful transactions, but transactions after it will be lost. Other DB engines use WAL or transaction journal for that, which in turn depends on order of operations in the journaled filesystem. libmdbx doesn't use WAL and hands I/O operations to filesystem and OS kernel (mmap).
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database and after full run the database contains 100,000 small key-value records.
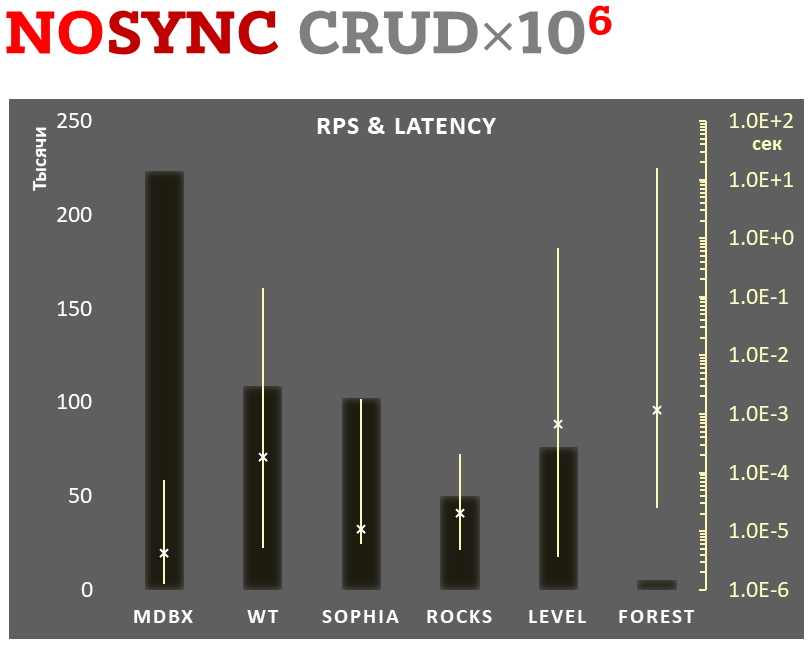
Async-write mode
-
Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
-
Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
1,000,000 transactions in async-write mode. In case of a crash all data is consistent and conforms to the one of last successful transactions, but lost transaction count is much higher than in lazy-write mode. All DB engines in this mode do as little writes as possible on persistent storage. libmdbx uses msync(MS_ASYNC) in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database and after full run the database contains 10,000 small key-value records.
Cost comparison
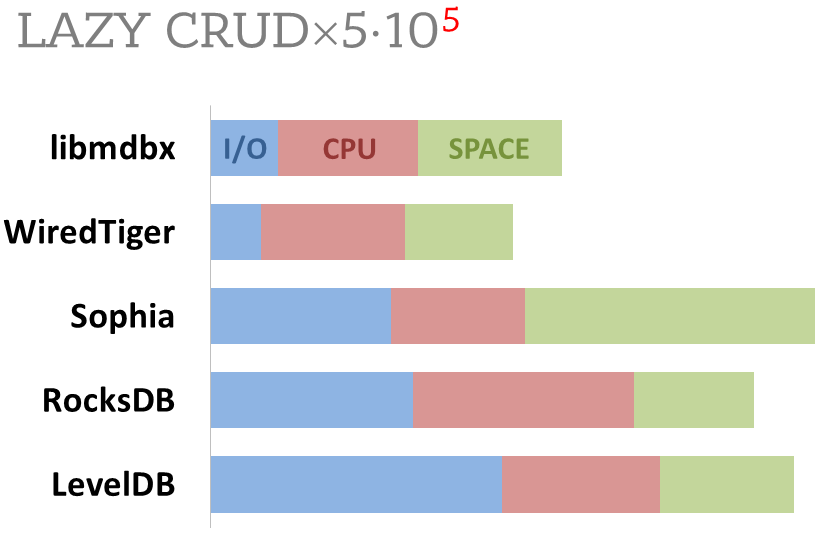
Summary of used resources during lazy-write mode benchmarks:
-
Read and write IOPs;
-
Sum of user CPU time and sys CPU time;
-
Used space on persistent storage after the test and closed DB, but not waiting for the end of all internal housekeeping operations (LSM compactification, etc).
ForestDB is excluded because benchmark showed it's resource consumption for each resource (CPU, IOPs) much higher than other engines which prevents to meaningfully compare it with them.
All benchmark data is gathered by getrusage() syscall and by scanning the data directory.