mirror of
https://github.com/isar/libmdbx.git
synced 2026-02-03 09:42:21 +08:00
Translate README.md to English. Move original one to README-RU.md
Signed-off-by: Dmitrii Tcvetkov <demfloro@demfloro.ru>
This commit is contained in:
690
README-RU.md
Normal file
690
README-RU.md
Normal file
@@ -0,0 +1,690 @@
|
||||
libmdbx
|
||||
======================================
|
||||
**The revised and extended descendant of [Symas LMDB](https://symas.com/lmdb/).**
|
||||
|
||||
*The Future will Positive. Всё будет хорошо.*
|
||||
[](https://travis-ci.org/leo-yuriev/libmdbx)
|
||||
[](https://ci.appveyor.com/project/leo-yuriev/libmdbx/branch/master)
|
||||
[](https://scan.coverity.com/projects/reopen-libmdbx)
|
||||
|
||||
English version [by Google](https://translate.googleusercontent.com/translate_c?act=url&ie=UTF8&sl=ru&tl=en&u=https://github.com/leo-yuriev/libmdbx/tree/master)
|
||||
and [by Yandex](https://translate.yandex.ru/translate?url=https%3A%2F%2Fgithub.com%2FReOpen%2Flibmdbx%2Ftree%2Fmaster&lang=ru-en).
|
||||
|
||||
### Project Status
|
||||
|
||||
**Now MDBX is under _active development_** and until 2018Q2 is expected a big
|
||||
change both of API and database format. Unfortunately those update will lead to
|
||||
loss of compatibility with previous versions.
|
||||
|
||||
The aim of this revolution in providing a clearer robust API and adding new
|
||||
features, including the database properties.
|
||||
|
||||
|
||||
## Содержание
|
||||
|
||||
- [Обзор](#Обзор)
|
||||
- [Сравнение с другими СУБД](#Сравнение-с-другими-СУБД)
|
||||
- [История & Acknowledgements](#История)
|
||||
- [Основные свойства](#Основные-свойства)
|
||||
- [Сравнение производительности](#Сравнение-производительности)
|
||||
- [Интегральная производительность](#Интегральная-производительность)
|
||||
- [Масштабируемость чтения](#Масштабируемость-чтения)
|
||||
- [Синхронная фиксация](#Синхронная-фиксация)
|
||||
- [Отложенная фиксация](#Отложенная-фиксация)
|
||||
- [Асинхронная фиксация](#Асинхронная-фиксация)
|
||||
- [Потребление ресурсов](#Потребление-ресурсов)
|
||||
- [Недостатки и Компромиссы](#Недостатки-и-Компромиссы)
|
||||
- [Проблема долгих чтений](#Проблема-долгих-чтений)
|
||||
- [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации)
|
||||
- [Доработки и усовершенствования относительно LMDB](#Доработки-и-усовершенствования-относительно-lmdb)
|
||||
|
||||
|
||||
## Обзор
|
||||
|
||||
_libmdbx_ - это встраиваемый key-value движок хранения со специфическим
|
||||
набором свойств и возможностей, ориентированный на создание уникальных
|
||||
легковесных решений с предельной производительностью.
|
||||
|
||||
_libmdbx_ позволяет множеству процессов совместно читать и обновлять
|
||||
несколько key-value таблиц с соблюдением [ACID](https://ru.wikipedia.org/wiki/ACID),
|
||||
при минимальных накладных расходах и амортизационной стоимости любых операций Olog(N).
|
||||
|
||||
_libmdbx_ обеспечивает
|
||||
[serializability](https://en.wikipedia.org/wiki/Serializability)
|
||||
изменений и согласованность данных после аварий. При этом транзакции
|
||||
изменяющие данные никак не мешают операциям чтения и выполняются строго
|
||||
последовательно с использованием единственного
|
||||
[мьютекса](https://en.wikipedia.org/wiki/Mutual_exclusion).
|
||||
|
||||
_libmdbx_ позволяет выполнять операции чтения с гарантиями
|
||||
[wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom),
|
||||
параллельно на каждом ядре CPU, без использования атомарных операций
|
||||
и/или примитивов синхронизации.
|
||||
|
||||
_libmdbx_ не использует [LSM](https://en.wikipedia.org/wiki/Log-structured_merge-tree), а основан на [B+Tree](https://en.wikipedia.org/wiki/B%2B_tree) с [отображением](https://en.wikipedia.org/wiki/Memory-mapped_file) всех данных в память,
|
||||
при этом текущая версия не использует [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging).
|
||||
Это предопределяет многие свойства, в том числе удачные и противопоказанные сценарии использования.
|
||||
|
||||
### Сравнение с другими СУБД
|
||||
|
||||
Ввиду того, что в _libmdbx_ сейчас происходит революция, я посчитал лучшим решением
|
||||
ограничится здесь ссылкой на [главу Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) в описании _BoltDB_.
|
||||
|
||||
|
||||
### История
|
||||
|
||||
_libmdbx_ является результатом переработки и развития "Lightning Memory-Mapped Database",
|
||||
известной под аббревиатурой
|
||||
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
Изначально доработка производилась в составе проекта
|
||||
[ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP). Примерно за год
|
||||
работы внесенные изменения приобрели самостоятельную ценность. Осенью
|
||||
2015 доработанный движок был выделен в отдельный проект, который был
|
||||
[представлен на конференции Highload++
|
||||
2015](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
|
||||
В начале 2017 года движок _libmdbx_ получил новый импульс развития,
|
||||
благодаря использованию в [Fast Positive
|
||||
Tables](https://github.com/leo-yuriev/libfpta), aka ["Позитивные
|
||||
Таблицы"](https://github.com/leo-yuriev/libfpta) by [Positive
|
||||
Technologies](https://www.ptsecurity.ru).
|
||||
|
||||
|
||||
#### Acknowledgements
|
||||
|
||||
Howard Chu (Symas Corporation) - the author of LMDB,
|
||||
from which originated the MDBX in 2015.
|
||||
|
||||
Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code,
|
||||
which was used for begin development of LMDB.
|
||||
|
||||
|
||||
Основные свойства
|
||||
=================
|
||||
|
||||
_libmdbx_ наследует все ключевые возможности и особенности от
|
||||
своего прародителя [LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database),
|
||||
но с устранением ряда описываемых далее проблем и архитектурных недочетов.
|
||||
|
||||
1. Данные хранятся в упорядоченном отображении (ordered map), ключи всегда
|
||||
отсортированы, поддерживается выборка диапазонов (range lookups).
|
||||
|
||||
2. Данные отображается в память каждого работающего с БД процесса.
|
||||
К данным и ключам обеспечивается прямой доступ в памяти без необходимости их
|
||||
копирования.
|
||||
|
||||
3. Транзакции согласно
|
||||
[ACID](https://ru.wikipedia.org/wiki/ACID), посредством
|
||||
[MVCC](https://ru.wikipedia.org/wiki/MVCC) и
|
||||
[COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8).
|
||||
Изменения строго последовательны и не блокируются чтением,
|
||||
конфликты между транзакциями не возможны.
|
||||
При этом гарантируется чтение только зафиксированных данных, см [relaxing serializability](https://en.wikipedia.org/wiki/Serializability).
|
||||
|
||||
4. Чтение и поиск [без блокировок](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B1%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B0%D1%8F_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F),
|
||||
без [атомарных операций](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F).
|
||||
Читатели не блокируются операциями записи и не конкурируют
|
||||
между собой, чтение масштабируется линейно по ядрам CPU.
|
||||
> Для точности следует отметить, что "подключение к БД" (старт первой
|
||||
> читающей транзакции в потоке) и "отключение от БД" (закрытие БД или
|
||||
> завершение потока) требуют краткосрочного захвата блокировки для
|
||||
> регистрации/дерегистрации текущего потока в "таблице читателей".
|
||||
|
||||
5. Эффективное хранение дубликатов (ключей с несколькими
|
||||
значениями), без дублирования ключей, с сортировкой значений, в
|
||||
том числе целочисленных (для вторичных индексов).
|
||||
|
||||
6. Эффективная поддержка коротких ключей фиксированной длины, в том числе целочисленных.
|
||||
|
||||
7. Амортизационная стоимость любой операции Olog(N),
|
||||
[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor) и RAF (Read Amplification Factor) также Olog(N).
|
||||
|
||||
8. Нет [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) и журнала
|
||||
транзакций, после сбоев не требуется восстановление. Не требуется компактификация
|
||||
или какое-либо периодическое обслуживание. Поддерживается резервное копирование
|
||||
"по горячему", на работающей БД без приостановки изменения данных.
|
||||
|
||||
9. Отсутствует какое-либо внутреннее управление памятью или кэшированием. Всё
|
||||
необходимое штатно выполняет ядро ОС!
|
||||
|
||||
|
||||
Сравнение производительности
|
||||
============================
|
||||
|
||||
Все представленные ниже данные получены многократным прогоном тестов на
|
||||
ноутбуке Lenovo Carbon-2, i7-4600U 2.1 ГГц, 8 Гб ОЗУ, с SSD-диском
|
||||
SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Гб.
|
||||
|
||||
Исходный код бенчмарка [_IOArena_](https://github.com/pmwkaa/ioarena) и
|
||||
сценарии тестирования [доступны на
|
||||
github](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
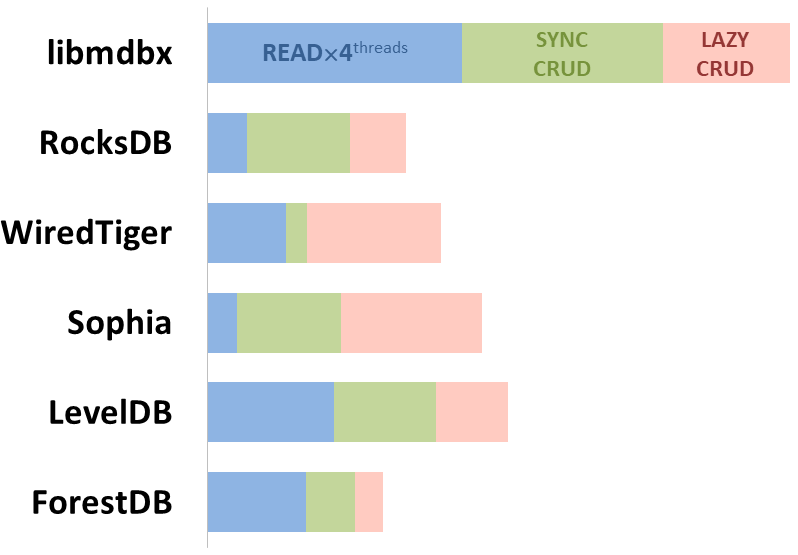
### Интегральная производительность
|
||||
|
||||
Показана соотнесенная сумма ключевых показателей производительности в трёх
|
||||
бенчмарках:
|
||||
|
||||
- Чтение/Поиск на машине с 4-мя процессорами;
|
||||
|
||||
- Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями
|
||||
(вставка, чтение, обновление, удаление) в режиме **синхронной фиксации**
|
||||
данных (fdatasync при завершении каждой транзакции или аналог);
|
||||
|
||||
- Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями
|
||||
(вставка, чтение, обновление, удаление) в режиме **отложенной фиксации**
|
||||
данных (отложенная запись посредством файловой систем или аналог);
|
||||
|
||||
*Бенчмарк в режиме асинхронной записи не включен по двум причинам:*
|
||||
|
||||
1. Такое сравнение не совсем правомочно, его следует делать с движками
|
||||
ориентированными на хранение данных в памяти ([Tarantool](https://tarantool.io/), [Redis](https://redis.io/)).
|
||||
|
||||
2. Превосходство libmdbx становится еще более подавляющем, что мешает
|
||||
восприятию информации.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
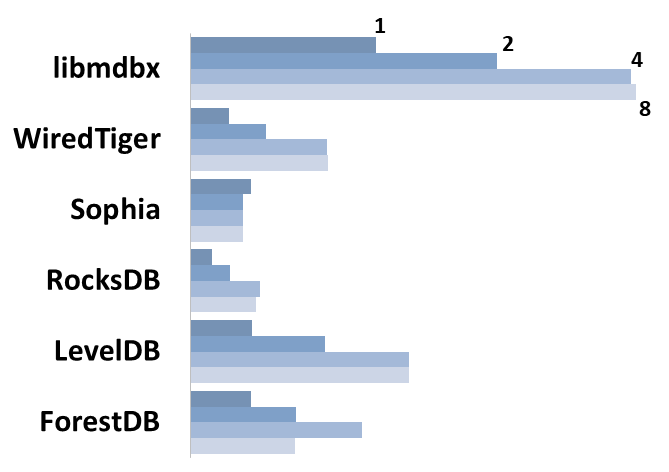
### Масштабируемость чтения
|
||||
|
||||
Для каждого движка показана суммарная производительность при
|
||||
одновременном выполнении запросов чтения/поиска в 1-2-4-8 потоков на
|
||||
машине с 4-мя физическими процессорами.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
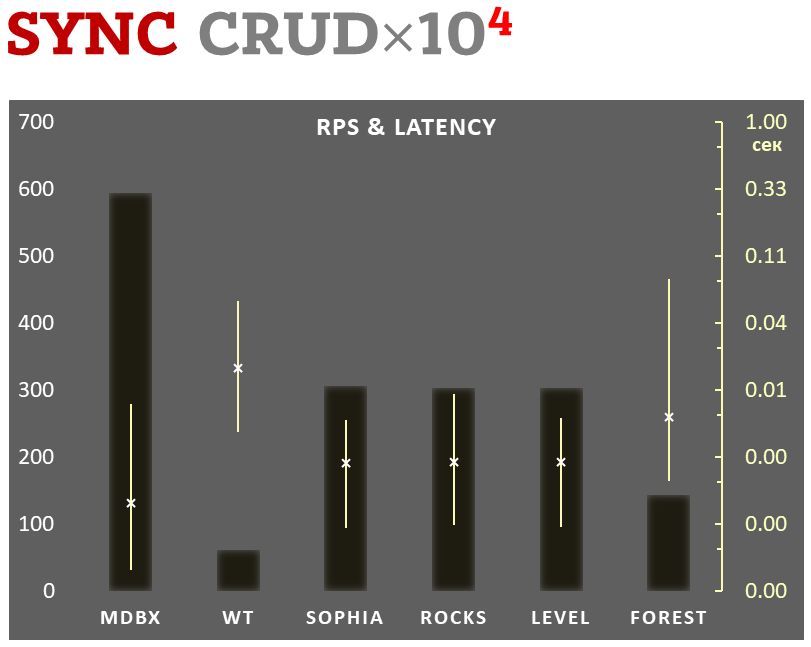
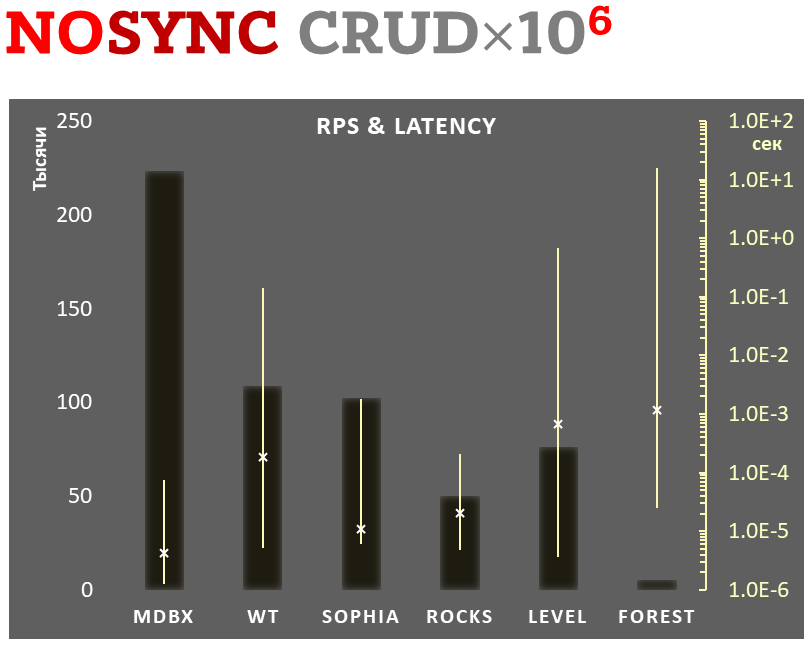
### Синхронная фиксация
|
||||
|
||||
- Линейная шкала слева и темные прямоугольники соответствуют количеству
|
||||
транзакций в секунду, усредненному за всё время теста.
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
|
||||
Выполняется **10.000 транзакций в режиме синхронной фиксации данных** на
|
||||
диске. При этом требуется гарантия, что при аварийном выключении питания
|
||||
(или другом подобном сбое) все данные будут консистентны и полностью
|
||||
соответствовать последней завершенной транзакции. В _libmdbx_ в этом
|
||||
режиме при фиксации каждой транзакции выполняется системный вызов
|
||||
[fdatasync](https://linux.die.net/man/2/fdatasync).
|
||||
|
||||
В каждой транзакции выполняется комбинированная CRUD-операция (две
|
||||
вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует
|
||||
на пустой базе, а при завершении, в результате выполняемых действий, в
|
||||
базе насчитывается 10.000 небольших key-value записей.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
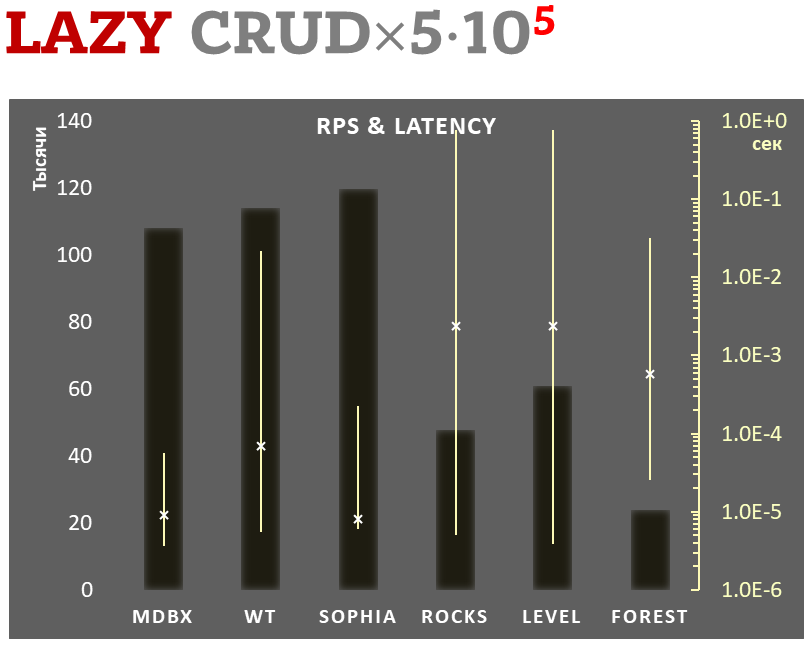
### Отложенная фиксация
|
||||
|
||||
- Линейная шкала слева и темные прямоугольники соответствуют количеству
|
||||
транзакций в секунду, усредненному за всё время теста.
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
|
||||
Выполняется **100.000 транзакций в режиме отложенной фиксации данных**
|
||||
на диске. При этом требуется гарантия, что при аварийном выключении
|
||||
питания (или другом подобном сбое) все данные будут консистентны на
|
||||
момент завершения одной из транзакций, но допускается потеря изменений
|
||||
из некоторого количества последних транзакций, что для многих движков
|
||||
предполагает включение
|
||||
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) (write-ahead
|
||||
logging) либо журнала транзакций, который в свою очередь опирается на
|
||||
гарантию упорядоченности данных в журналируемой файловой системе.
|
||||
_libmdbx_ при этом не ведет WAL, а передает весь контроль файловой
|
||||
системе и ядру ОС.
|
||||
|
||||
В каждой транзакции выполняется комбинированная CRUD-операция (две
|
||||
вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует
|
||||
на пустой базе, а при завершении, в результате выполняемых действий, в
|
||||
базе насчитывается 100.000 небольших key-value записей.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
### Асинхронная фиксация
|
||||
|
||||
- Линейная шкала слева и темные прямоугольники соответствуют количеству
|
||||
транзакций в секунду, усредненному за всё время теста.
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
|
||||
Выполняется **1.000.000 транзакций в режиме асинхронной фиксации
|
||||
данных** на диске. При этом требуется гарантия, что при аварийном
|
||||
выключении питания (или другом подобном сбое) все данные будут
|
||||
консистентны на момент завершения одной из транзакций, но допускается
|
||||
потеря изменений из значительного количества последних транзакций. Во
|
||||
всех движках при этом включался режим предполагающий минимальную
|
||||
нагрузку на диск по-записи, и соответственно минимальную гарантию
|
||||
сохранности данных. В _libmdbx_ при этом используется режим асинхронной
|
||||
записи измененных страниц на диск посредством ядра ОС и системного
|
||||
вызова [msync(MS_ASYNC)](https://linux.die.net/man/2/msync).
|
||||
|
||||
В каждой транзакции выполняется комбинированная CRUD-операция (две
|
||||
вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует
|
||||
на пустой базе, а при завершении, в результате выполняемых действий, в
|
||||
базе насчитывается 10.000 небольших key-value записей.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
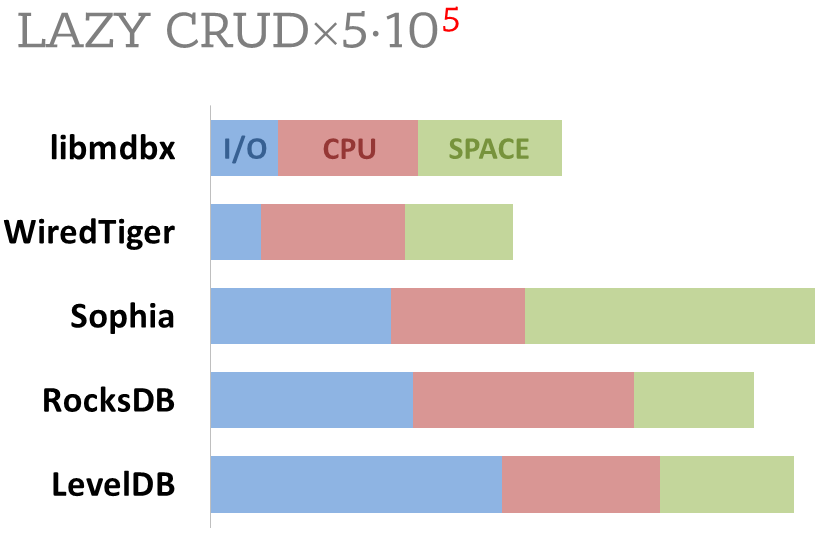
### Потребление ресурсов
|
||||
|
||||
Показана соотнесенная сумма использованных ресурсов в ходе бенчмарка в
|
||||
режиме отложенной фиксации:
|
||||
|
||||
- суммарное количество операций ввода-вывода (IOPS), как записи, так и
|
||||
чтения.
|
||||
|
||||
- суммарное затраченное время процессора, как в режиме пользовательских процессов,
|
||||
так и в режиме ядра ОС.
|
||||
|
||||
- использованное место на диске при завершении теста, после закрытия БД из тестирующего процесса,
|
||||
но без ожидания всех внутренних операций обслуживания (компактификации LSM и т.п.).
|
||||
|
||||
Движок _ForestDB_ был исключен при оформлении результатов, так как
|
||||
относительно конкурентов многократно превысил потребление каждого из
|
||||
ресурсов (потратил процессорное время на генерацию IOPS для заполнения
|
||||
диска), что не позволяло наглядно сравнить показатели остальных движков
|
||||
на одной диаграмме.
|
||||
|
||||
Все данные собирались посредством системного вызова
|
||||
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) и
|
||||
сканированием директорий с данными.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
## Недостатки и Компромиссы
|
||||
|
||||
1. Единовременно может выполняться не более одной транзакция изменения данных
|
||||
(один писатель). Зато все изменения всегда последовательны, не может быть
|
||||
конфликтов или логических ошибок при откате транзакций.
|
||||
|
||||
2. Отсутствие [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging)
|
||||
обуславливает относительно большой
|
||||
[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor). Поэтому фиксация изменений на диске может быть
|
||||
достаточно дорогой и являться главным ограничением производительности
|
||||
при интенсивном изменении данных.
|
||||
> В качестве компромисса _libmdbx_ предлагает несколько режимов ленивой
|
||||
> и/или периодической фиксации. В том числе режим `MAPASYNC`, при котором
|
||||
> изменения происходят только в памяти и асинхронно фиксируются на диске
|
||||
> ядром ОС.
|
||||
>
|
||||
> Однако, следует воспринимать это свойство аккуратно и взвешенно.
|
||||
> Например, полная фиксация транзакции в БД с журналом потребует минимум 2
|
||||
> IOPS (скорее всего 3-4) из-за накладных расходов в файловой системе. В
|
||||
> _libmdbx_ фиксация транзакции также требует от 2 IOPS. Однако, в БД с
|
||||
> журналом кол-во IOPS будет меняться в зависимости от файловой системы,
|
||||
> но не от кол-ва записей или их объема. Тогда как в _libmdbx_ кол-во
|
||||
> будет расти логарифмически от кол-во записей/строк в БД (по высоте
|
||||
> b+tree).
|
||||
|
||||
3. [COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8)
|
||||
для реализации [MVCC](https://ru.wikipedia.org/wiki/MVCC) выполняется на
|
||||
уровне страниц в [B+
|
||||
дереве](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
||||
Поэтому изменение данных амортизационно требует копирования Olog(N)
|
||||
страниц, что расходует [пропускную способность оперативной
|
||||
памяти](https://en.wikipedia.org/wiki/Memory_bandwidth) и является
|
||||
основным ограничителем производительности в режиме `MAPASYNC`.
|
||||
> Этот недостаток неустраним, тем не менее следует дать некоторые пояснения.
|
||||
> Дело в том, что фиксация изменений на диске потребует гораздо более
|
||||
> значительного копирования данных в памяти и массы других затратных операций.
|
||||
> Поэтому обусловленное этим недостатком падение производительности становится
|
||||
> заметным только при отказе от фиксации изменений на диске.
|
||||
> Соответственно, корректнее сказать что _libmdbx_ позволяет
|
||||
> получить персистентность ценой минимального падения производительности.
|
||||
> Если же нет необходимости оперативно сохранять данные, то логичнее
|
||||
> использовать `std::map`.
|
||||
|
||||
4. В _LMDB_ существует проблема долгих чтений (приостановленных читателей),
|
||||
которая приводит к деградации производительности и переполнению БД.
|
||||
> В _libmdbx_ предложены средства для предотвращения, быстрого выхода из
|
||||
> некомфортной ситуации и устранения её последствий. Подробности ниже.
|
||||
|
||||
5. В _LMDB_ есть вероятность разрушения БД в режиме `WRITEMAP+MAPASYNC`.
|
||||
В _libmdbx_ для `WRITEMAP+MAPASYNC` гарантируется как сохранность базы,
|
||||
так и согласованность данных.
|
||||
> Дополнительно, в качестве альтернативы, предложен режим `UTTERLY_NOSYNC`.
|
||||
> Подробности ниже.
|
||||
|
||||
|
||||
#### Проблема долгих чтений
|
||||
|
||||
*Следует отметить*, что проблема "сборки мусора" так или иначе
|
||||
существует во всех СУБД (Vacuum в PostgreSQL). Однако в случае _libmdbx_
|
||||
и LMDB она проявляется более остро, прежде всего из-за высокой
|
||||
производительности, а также из-за намеренного упрощения внутренних
|
||||
механизмов ради производительности.
|
||||
|
||||
Понимание проблемы требует некоторых пояснений, которые
|
||||
изложены ниже, но могут быть сложны для быстрого восприятия.
|
||||
Поэтому, тезисно:
|
||||
|
||||
* Изменение данных на фоне долгой операции чтения может
|
||||
приводить к исчерпанию места в БД.
|
||||
|
||||
* После чего любая попытка обновить данные будет приводить к
|
||||
ошибке `MAP_FULL` до завершения долгой операции чтения.
|
||||
|
||||
* Характерными примерами долгих чтений являются горячее
|
||||
резервное копирования и отладка клиентского приложения при
|
||||
активной транзакции чтения.
|
||||
|
||||
* В оригинальной _LMDB_ после этого будет наблюдаться
|
||||
устойчивая деградация производительности всех механизмов
|
||||
обратной записи на диск (в I/O контроллере, в гипервизоре,
|
||||
в ядре ОС).
|
||||
|
||||
* В _libmdbx_ предусмотрен механизм аварийного прерывания таких
|
||||
операций, а также режим `LIFO RECLAIM` устраняющий последующую
|
||||
деградацию производительности.
|
||||
|
||||
Операции чтения выполняются в контексте снимка данных (версии
|
||||
БД), который был актуальным на момент старта транзакции чтения. Такой
|
||||
читаемый снимок поддерживается неизменным до завершения операции. В свою
|
||||
очередь, это не позволяет повторно использовать страницы БД в
|
||||
последующих версиях (снимках БД).
|
||||
|
||||
Другими словами, если обновление данных выполняется на фоне долгой
|
||||
операции чтения, то вместо повторного использования "старых" ненужных
|
||||
страниц будут выделяться новые, так как "старые" страницы составляют
|
||||
снимок БД, который еще используется долгой операцией чтения.
|
||||
|
||||
В результате, при интенсивном изменении данных и достаточно длительной
|
||||
операции чтения, в БД могут быть исчерпаны свободные страницы, что не
|
||||
позволит создавать новые снимки/версии БД. Такая ситуация будет
|
||||
сохраняться до завершения операции чтения, которая использует старый
|
||||
снимок данных и препятствует повторному использованию страниц БД.
|
||||
|
||||
Однако, на этом проблемы не заканчиваются. После описанной ситуации, все
|
||||
дополнительные страницы, которые были выделены пока переработка старых
|
||||
была невозможна, будут участвовать в цикле выделения/освобождения до
|
||||
конца жизни экземпляра БД. В оригинальной _LMDB_ этот цикл использования
|
||||
страниц работает по принципу [FIFO](https://ru.wikipedia.org/wiki/FIFO).
|
||||
Поэтому увеличение количества циркулирующий страниц, с точки зрения
|
||||
механизмов кэширования и/или обратной записи, выглядит как увеличение
|
||||
рабочего набор данных. Проще говоря, однократное попадание в ситуацию
|
||||
"уснувшего читателя" приводит к устойчивому эффекту вымывания I/O кэша
|
||||
при всех последующих изменениях данных.
|
||||
|
||||
Для устранения описанных проблемы в _libmdbx_ сделаны существенные
|
||||
доработки, подробности ниже. Иллюстрации к проблеме "долгих чтений"
|
||||
можно найти в [слайдах презентации](http://www.slideshare.net/leoyuriev/lmdb).
|
||||
|
||||
Там же приведен пример количественной оценки прироста производительности
|
||||
за счет эффективной работы [BBWC](https://en.wikipedia.org/wiki/BBWC)
|
||||
при включении `LIFO RECLAIM` в _libmdbx_.
|
||||
|
||||
|
||||
#### Сохранность данных в режиме асинхронной фиксации
|
||||
|
||||
При работе в режиме `WRITEMAP+MAPSYNC` запись измененных страниц
|
||||
выполняется ядром ОС, что имеет ряд преимуществ. Так например, при крахе
|
||||
приложения, ядро ОС сохранит все изменения.
|
||||
|
||||
Однако, при аварийном отключении питания или сбое в ядре ОС, на диске
|
||||
может быть сохранена только часть измененных страниц БД. При этом с большой
|
||||
вероятностью может оказаться так, что будут сохранены мета-страницы со
|
||||
ссылками на страницы с новыми версиями данных, но не сами новые данные.
|
||||
В этом случае БД будет безвозвратна разрушена, даже если до аварии
|
||||
производилась полная синхронизация данных (посредством
|
||||
`mdbx_env_sync()`).
|
||||
|
||||
В _libmdbx_ эта проблема устранена путем полной переработки
|
||||
пути записи данных:
|
||||
|
||||
* В режиме `WRITEMAP+MAPSYNC` _libmdbx_ не обновляет
|
||||
мета-страницы непосредственно, а поддерживает их теневые копии
|
||||
с переносом изменений после фиксации данных.
|
||||
|
||||
* При завершении транзакций, в зависимости от состояния
|
||||
синхронности данных между диском и оперативной память,
|
||||
_libmdbx_ помечает точки фиксации либо как сильные (strong),
|
||||
либо как слабые (weak). Так например, в режиме
|
||||
`WRITEMAP+MAPSYNC` завершаемые транзакции помечаются как
|
||||
слабые, а при явной синхронизации данных как сильные.
|
||||
|
||||
* В _libmdbx_ поддерживается не две, а три отдельные мета-страницы.
|
||||
Это позволяет выполнять фиксацию транзакций с формированием как
|
||||
сильной, так и слабой точки фиксации, без потери двух предыдущих
|
||||
точек фиксации (из которых одна может быть сильной, а вторая слабой).
|
||||
В результате, _libmdbx_ позволяет в произвольном порядке чередовать
|
||||
сильные и слабые точки фиксации без нарушения соответствующих
|
||||
гарантий в случае неожиданной системной аварии во время фиксации.
|
||||
|
||||
* При открытии БД выполняется автоматический откат к последней
|
||||
сильной фиксации. Этим обеспечивается гарантия сохранности БД.
|
||||
|
||||
Такая гарантия надежности не дается бесплатно. Для
|
||||
сохранности данных, страницы формирующие крайний снимок с
|
||||
сильной фиксацией, не должны повторно использоваться
|
||||
(перезаписываться) до формирования следующей сильной точки
|
||||
фиксации. Таким образом, крайняя точка фиксации создает
|
||||
описанный выше эффект "долгого чтения". Разница же здесь в том,
|
||||
что при исчерпании свободных страниц ситуация будет
|
||||
автоматически исправлена, посредством записи изменений на диск
|
||||
и формированием новой сильной точки фиксации.
|
||||
|
||||
Таким образом, в режиме безопасной асинхронной фиксации _libmdbx_ будет
|
||||
всегда использовать новые страницы до исчерпания места в БД или до явного
|
||||
формирования сильной точки фиксации посредством `mdbx_env_sync()`.
|
||||
При этом суммарный трафик записи на диск будет примерно такой-же,
|
||||
как если бы отдельно фиксировалась каждая транзакций.
|
||||
|
||||
В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` когда
|
||||
при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
|
||||
В последующих версиях _libmdbx_ будут предусмотрены средства
|
||||
для асинхронной записи данных на диск с автоматическим
|
||||
формированием сильных точек фиксации.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Доработки и усовершенствования относительно LMDB
|
||||
================================================
|
||||
|
||||
1. Режим `LIFO RECLAIM`.
|
||||
|
||||
Для повторного использования выбираются не самые старые, а
|
||||
самые новые страницы из доступных. За счет этого цикл
|
||||
использования страниц всегда имеет минимальную длину и не
|
||||
зависит от общего числа выделенных страниц.
|
||||
|
||||
В результате механизмы кэширования и обратной записи работают с
|
||||
максимально возможной эффективностью. В случае использования
|
||||
контроллера дисков или системы хранения с
|
||||
[BBWC](https://en.wikipedia.org/wiki/BBWC) возможно
|
||||
многократное увеличение производительности по записи
|
||||
(обновлению данных).
|
||||
|
||||
2. Обработчик `OOM-KICK`.
|
||||
|
||||
Посредством `mdbx_env_set_oomfunc()` может быть установлен
|
||||
внешний обработчик (callback), который будет вызван при
|
||||
исчерпания свободных страниц из-за долгой операцией чтения.
|
||||
Обработчику будет передан PID и pthread_id виновника.
|
||||
В свою очередь обработчик может предпринять одно из действий:
|
||||
|
||||
* нейтрализовать виновника (отправить сигнал kill #9), если
|
||||
долгое чтение выполняется сторонним процессом;
|
||||
|
||||
* отменить или перезапустить проблемную операцию чтения, если
|
||||
операция выполняется одним из потоков текущего процесса;
|
||||
|
||||
* подождать некоторое время, в расчете что проблемная операция
|
||||
чтения будет штатно завершена;
|
||||
|
||||
* прервать текущую операцию изменения данных с возвратом кода
|
||||
ошибки.
|
||||
|
||||
3. Гарантия сохранности БД в режиме `WRITEMAP+MAPSYNC`.
|
||||
|
||||
В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC`
|
||||
когда при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
Для подробностей смотрите раздел
|
||||
[Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации).
|
||||
|
||||
4. Возможность автоматического формирования контрольных точек
|
||||
(сброса данных на диск) при накоплении заданного объёма изменений,
|
||||
устанавливаемого функцией `mdbx_env_set_syncbytes()`.
|
||||
|
||||
5. Возможность получить отставание текущей транзакции чтения от
|
||||
последней версии данных в БД посредством `mdbx_txn_straggler()`.
|
||||
|
||||
6. Утилита mdbx_chk для проверки БД и функция `mdbx_env_pgwalk()` для
|
||||
обхода всех страниц БД.
|
||||
|
||||
7. Управление отладкой и получение отладочных сообщений посредством
|
||||
`mdbx_setup_debug()`.
|
||||
|
||||
8. Возможность связать с каждой завершаемой транзакцией до 3
|
||||
дополнительных маркеров посредством `mdbx_canary_put()`, и прочитать их
|
||||
в транзакции чтения посредством `mdbx_canary_get()`.
|
||||
|
||||
9. Возможность узнать есть ли за текущей позицией курсора строка данных
|
||||
посредством `mdbx_cursor_eof()`.
|
||||
|
||||
10. Возможность явно запросить обновление существующей записи, без
|
||||
создания новой посредством флажка `MDBX_CURRENT` для `mdbx_put()`.
|
||||
|
||||
11. Возможность посредством `mdbx_replace()` обновить или удалить запись
|
||||
с получением предыдущего значения данных, а также адресно изменить
|
||||
конкретное multi-значение.
|
||||
|
||||
12. Поддержка ключей и значений нулевой длины, включая сортированные
|
||||
дубликаты.
|
||||
|
||||
13. Исправленный вариант `mdbx_cursor_count()`, возвращающий корректное
|
||||
количество дубликатов для всех типов таблиц и любого положения курсора.
|
||||
|
||||
14. Возможность открыть БД в эксклюзивном режиме посредством
|
||||
`mdbx_env_open_ex()`, например в целях её проверки.
|
||||
|
||||
15. Возможность закрыть БД в "грязном" состоянии (без сброса данных и
|
||||
формирования сильной точки фиксации) посредством `mdbx_env_close_ex()`.
|
||||
|
||||
16. Возможность получить посредством `mdbx_env_info()` дополнительную
|
||||
информацию, включая номер самой старой версии БД (снимка данных),
|
||||
который используется одним из читателей.
|
||||
|
||||
17. Функция `mdbx_del()` не игнорирует дополнительный (уточняющий)
|
||||
аргумент `data` для таблиц без дубликатов (без флажка `MDBX_DUPSORT`), а
|
||||
при его ненулевом значении всегда использует его для сверки с удаляемой
|
||||
записью.
|
||||
|
||||
18. Возможность открыть dbi-таблицу, одновременно с установкой
|
||||
компараторов для ключей и данных, посредством `mdbx_dbi_open_ex()`.
|
||||
|
||||
19. Возможность посредством `mdbx_is_dirty()` определить находятся ли
|
||||
некоторый ключ или данные в "грязной" странице БД. Таким образом,
|
||||
избегая лишнего копирования данных перед выполнением модифицирующих
|
||||
операций (значения в размещенные "грязных" страницах могут быть
|
||||
перезаписаны при изменениях, иначе они будут неизменны).
|
||||
|
||||
20. Корректное обновление текущей записи, в том числе сортированного
|
||||
дубликата, при использовании режима `MDBX_CURRENT` в
|
||||
`mdbx_cursor_put()`.
|
||||
|
||||
21. Все курсоры, как в транзакциях только для чтения, так и в пишущих,
|
||||
могут быть переиспользованы посредством `mdbx_cursor_renew()` и ДОЛЖНЫ
|
||||
ОСВОБОЖДАТЬСЯ ЯВНО.
|
||||
>
|
||||
> ## _ВАЖНО_, Обратите внимание!
|
||||
>
|
||||
> Это единственное изменение в API, которое значимо меняет
|
||||
> семантику управления курсорами и может приводить к утечкам
|
||||
> памяти. Следует отметить, что это изменение вынужденно.
|
||||
> Так устраняется неоднозначность с массой тяжких последствий:
|
||||
>
|
||||
> - обращение к уже освобожденной памяти;
|
||||
> - попытки повторного освобождения памяти;
|
||||
> - memory corruption and segfaults.
|
||||
|
||||
22. Дополнительный код ошибки `MDBX_EMULTIVAL`, который возвращается из
|
||||
`mdbx_put()` и `mdbx_replace()` при попытке выполнить неоднозначное
|
||||
обновление или удаления одного из нескольких значений с одним ключом.
|
||||
|
||||
23. Возможность посредством `mdbx_get_ex()` получить значение по
|
||||
заданному ключу, одновременно с количеством дубликатов.
|
||||
|
||||
24. Наличие функций `mdbx_cursor_on_first()` и `mdbx_cursor_on_last()`,
|
||||
которые позволяют быстро выяснить стоит ли курсор на первой/последней
|
||||
позиции.
|
||||
|
||||
25. При завершении читающих транзакций, открытые в них DBI-хендлы не
|
||||
закрываются и не теряются при завершении таких транзакций посредством
|
||||
`mdbx_txn_abort()` или `mdbx_txn_reset()`. Что позволяет избавится от ряда
|
||||
сложно обнаруживаемых ошибок.
|
||||
|
||||
26. Генерация последовательностей посредством `mdbx_dbi_sequence()`.
|
||||
|
||||
27. Расширенное динамическое управление размером БД, включая выбор
|
||||
размера страницы посредством `mdbx_env_set_geometry()`,
|
||||
в том числе в **Windows**
|
||||
|
||||
28. Три мета-страницы вместо двух, что позволяет гарантированно
|
||||
консистентно обновлять слабые контрольные точки фиксации без риска
|
||||
повредить крайнюю сильную точку фиксации.
|
||||
|
||||
29. В _libmdbx_ реализован автоматический возврат освобождающихся
|
||||
страниц в область нераспределенного резерва в конце файла данных. При
|
||||
этом уменьшается количество страниц загруженных в память и участвующих в
|
||||
цикле обновления данных и записи на диск. Фактически _libmdbx_ выполняет
|
||||
постоянную компактификацию данных, но не затрачивая на это
|
||||
дополнительных ресурсов, а только освобождая их. При освобождении места
|
||||
в БД и установки соответствующих параметров геометрии базы данных, также будет
|
||||
уменьшаться размер файла на диске, в том числе в **Windows**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
$ objdump -f -h -j .text libmdbx.so
|
||||
|
||||
libmdbx.so: file format elf64-x86-64
|
||||
architecture: i386:x86-64, flags 0x00000150:
|
||||
HAS_SYMS, DYNAMIC, D_PAGED
|
||||
start address 0x000030e0
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
11 .text 00014d84 00000000000030e0 00000000000030e0 000030e0 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
$ gcc -v
|
||||
Using built-in specs.
|
||||
COLLECT_GCC=gcc
|
||||
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/7/lto-wrapper
|
||||
OFFLOAD_TARGET_NAMES=nvptx-none
|
||||
OFFLOAD_TARGET_DEFAULT=1
|
||||
Target: x86_64-linux-gnu
|
||||
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 7.2.0-8ubuntu3' --with-bugurl=file:///usr/share/doc/gcc-7/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-7 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
|
||||
Thread model: posix
|
||||
gcc version 7.2.0 (Ubuntu 7.2.0-8ubuntu3)
|
||||
```
|
||||
767
README.md
767
README.md
@@ -1,94 +1,69 @@
|
||||
libmdbx
|
||||
======================================
|
||||
**The revised and extended descendant of [Symas LMDB](https://symas.com/lmdb/).**
|
||||
**Revised and extended descendant of [Symas LMDB](https://symas.com/lmdb/).**
|
||||
|
||||
*The Future will Positive. Всё будет хорошо.*
|
||||
*The Future will be positive.*
|
||||
[](https://travis-ci.org/leo-yuriev/libmdbx)
|
||||
[](https://ci.appveyor.com/project/leo-yuriev/libmdbx/branch/master)
|
||||
[](https://scan.coverity.com/projects/reopen-libmdbx)
|
||||
|
||||
English version [by Google](https://translate.googleusercontent.com/translate_c?act=url&ie=UTF8&sl=ru&tl=en&u=https://github.com/leo-yuriev/libmdbx/tree/master)
|
||||
and [by Yandex](https://translate.yandex.ru/translate?url=https%3A%2F%2Fgithub.com%2FReOpen%2Flibmdbx%2Ftree%2Fmaster&lang=ru-en).
|
||||
|
||||
### Project Status
|
||||
|
||||
**Now MDBX is under _active development_** and until 2018Q2 is expected a big
|
||||
change both of API and database format. Unfortunately those update will lead to
|
||||
loss of compatibility with previous versions.
|
||||
**MDBX is under _active development_**, database format and API aren't stable
|
||||
at least until 2018Q2. New version won't be backwards compatible. Main focus of the rework is to provide
|
||||
clear and robust API and new features.
|
||||
|
||||
The aim of this revolution in providing a clearer robust API and adding new
|
||||
features, including the database properties.
|
||||
## Contents
|
||||
|
||||
- [Overview](#overview)
|
||||
- [Comparison with other DBs](#comparison-with-other-dbs)
|
||||
- [History & Acknowledgements](#history)
|
||||
- [Main features](#main-features)
|
||||
- [Perfomance comparison](#perfomance-comparison)
|
||||
- [Integral perfomance](#integral-perfomance)
|
||||
- [Read scalability](#read-scalability)
|
||||
- [Sync-write mode](#sync-write-mode)
|
||||
- [Lazy-write mode](#lazy-write-mode)
|
||||
- [Async-write mode](#async-write-mode)
|
||||
- [Cost comparison](#cost-comparison)
|
||||
- [Gotchas](#gotchas)
|
||||
- [Long-time read transactions problem](#long-time-read-transactions-problem)
|
||||
- [Data safety in async-write-mode](#data-safety-in-async-write-mode)
|
||||
- [Improvements over LMDB](#improvements-over-lmdb)
|
||||
|
||||
|
||||
## Содержание
|
||||
## Overview
|
||||
|
||||
- [Обзор](#Обзор)
|
||||
- [Сравнение с другими СУБД](#Сравнение-с-другими-СУБД)
|
||||
- [История & Acknowledgements](#История)
|
||||
- [Основные свойства](#Основные-свойства)
|
||||
- [Сравнение производительности](#Сравнение-производительности)
|
||||
- [Интегральная производительность](#Интегральная-производительность)
|
||||
- [Масштабируемость чтения](#Масштабируемость-чтения)
|
||||
- [Синхронная фиксация](#Синхронная-фиксация)
|
||||
- [Отложенная фиксация](#Отложенная-фиксация)
|
||||
- [Асинхронная фиксация](#Асинхронная-фиксация)
|
||||
- [Потребление ресурсов](#Потребление-ресурсов)
|
||||
- [Недостатки и Компромиссы](#Недостатки-и-Компромиссы)
|
||||
- [Проблема долгих чтений](#Проблема-долгих-чтений)
|
||||
- [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации)
|
||||
- [Доработки и усовершенствования относительно LMDB](#Доработки-и-усовершенствования-относительно-lmdb)
|
||||
_libmdbx_ is an embedded lightweight key-value database engine oriented for perfomance.
|
||||
|
||||
_libmdbx_ allows multiple processes to read and update several key-value tables concurrently,
|
||||
while being [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, with minimal overhead and operation cost of Olog(N).
|
||||
|
||||
## Обзор
|
||||
_libmdbx_ provides
|
||||
[serializability](https://en.wikipedia.org/wiki/Serializability) and consistency of data after crash.
|
||||
Read-write transactions don't block read-only transactions and are
|
||||
[serialized](https://en.wikipedia.org/wiki/Serializability) by [mutex](https://en.wikipedia.org/wiki/Mutual_exclusion).
|
||||
|
||||
_libmdbx_ - это встраиваемый key-value движок хранения со специфическим
|
||||
набором свойств и возможностей, ориентированный на создание уникальных
|
||||
легковесных решений с предельной производительностью.
|
||||
_libmdbx_ [wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom) provides parallel read transactions
|
||||
without atomic operations or synchronization primitives.
|
||||
|
||||
_libmdbx_ позволяет множеству процессов совместно читать и обновлять
|
||||
несколько key-value таблиц с соблюдением [ACID](https://ru.wikipedia.org/wiki/ACID),
|
||||
при минимальных накладных расходах и амортизационной стоимости любых операций Olog(N).
|
||||
_libmdbx_ uses [B+Trees](https://en.wikipedia.org/wiki/B%2B_tree) and [mmap](https://en.wikipedia.org/wiki/Memory-mapped_file),
|
||||
doesn't use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). This might have caveats for some workloads.
|
||||
|
||||
_libmdbx_ обеспечивает
|
||||
[serializability](https://en.wikipedia.org/wiki/Serializability)
|
||||
изменений и согласованность данных после аварий. При этом транзакции
|
||||
изменяющие данные никак не мешают операциям чтения и выполняются строго
|
||||
последовательно с использованием единственного
|
||||
[мьютекса](https://en.wikipedia.org/wiki/Mutual_exclusion).
|
||||
### Comparison with other DBs
|
||||
|
||||
_libmdbx_ позволяет выполнять операции чтения с гарантиями
|
||||
[wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom),
|
||||
параллельно на каждом ядре CPU, без использования атомарных операций
|
||||
и/или примитивов синхронизации.
|
||||
Because _libmdbx_ is currently overhauled, I think it's better to just link
|
||||
[chapter of Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) here.
|
||||
|
||||
_libmdbx_ не использует [LSM](https://en.wikipedia.org/wiki/Log-structured_merge-tree), а основан на [B+Tree](https://en.wikipedia.org/wiki/B%2B_tree) с [отображением](https://en.wikipedia.org/wiki/Memory-mapped_file) всех данных в память,
|
||||
при этом текущая версия не использует [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging).
|
||||
Это предопределяет многие свойства, в том числе удачные и противопоказанные сценарии использования.
|
||||
### History
|
||||
|
||||
### Сравнение с другими СУБД
|
||||
|
||||
Ввиду того, что в _libmdbx_ сейчас происходит революция, я посчитал лучшим решением
|
||||
ограничится здесь ссылкой на [главу Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) в описании _BoltDB_.
|
||||
|
||||
|
||||
### История
|
||||
|
||||
_libmdbx_ является результатом переработки и развития "Lightning Memory-Mapped Database",
|
||||
известной под аббревиатурой
|
||||
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
Изначально доработка производилась в составе проекта
|
||||
[ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP). Примерно за год
|
||||
работы внесенные изменения приобрели самостоятельную ценность. Осенью
|
||||
2015 доработанный движок был выделен в отдельный проект, который был
|
||||
[представлен на конференции Highload++
|
||||
2015](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
|
||||
В начале 2017 года движок _libmdbx_ получил новый импульс развития,
|
||||
благодаря использованию в [Fast Positive
|
||||
Tables](https://github.com/leo-yuriev/libfpta), aka ["Позитивные
|
||||
Таблицы"](https://github.com/leo-yuriev/libfpta) by [Positive
|
||||
Technologies](https://www.ptsecurity.ru).
|
||||
_libmdbx_ design is based on [Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
Initial development was going in [ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project, about a year later it
|
||||
received separate development effort and in autumn 2015 was isolated to separate project, which was
|
||||
[presented at Highload++ 2015 conference](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
|
||||
Since early 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/leo-yuriev/libfpta),
|
||||
by [Positive Technologies](https://www.ptsecurity.ru).
|
||||
|
||||
#### Acknowledgements
|
||||
|
||||
@@ -99,565 +74,373 @@ Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code,
|
||||
which was used for begin development of LMDB.
|
||||
|
||||
|
||||
Основные свойства
|
||||
Main features
|
||||
=================
|
||||
|
||||
_libmdbx_ наследует все ключевые возможности и особенности от
|
||||
своего прародителя [LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database),
|
||||
но с устранением ряда описываемых далее проблем и архитектурных недочетов.
|
||||
_libmdbx_ inherits all keys features and characteristics from
|
||||
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database):
|
||||
|
||||
1. Данные хранятся в упорядоченном отображении (ordered map), ключи всегда
|
||||
отсортированы, поддерживается выборка диапазонов (range lookups).
|
||||
1. Data is stored in ordered map, keys are always sorted, range lookups are supported.
|
||||
|
||||
2. Данные отображается в память каждого работающего с БД процесса.
|
||||
К данным и ключам обеспечивается прямой доступ в памяти без необходимости их
|
||||
копирования.
|
||||
2. Data is [mmaped](https://en.wikipedia.org/wiki/Memory-mapped_file) to memory of each worker DB process, read transactions are zero-copy
|
||||
|
||||
3. Транзакции согласно
|
||||
[ACID](https://ru.wikipedia.org/wiki/ACID), посредством
|
||||
[MVCC](https://ru.wikipedia.org/wiki/MVCC) и
|
||||
[COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8).
|
||||
Изменения строго последовательны и не блокируются чтением,
|
||||
конфликты между транзакциями не возможны.
|
||||
При этом гарантируется чтение только зафиксированных данных, см [relaxing serializability](https://en.wikipedia.org/wiki/Serializability).
|
||||
3. Transactions are [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, thanks to
|
||||
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) and [CoW](https://en.wikipedia.org/wiki/Copy-on-write).
|
||||
Writes are strongly serialized and aren't blocked by reads, transactions can't conflict with each other.
|
||||
Reads are guaranteed to get only commited data
|
||||
([relaxing serializability](https://en.wikipedia.org/wiki/Serializability#Relaxing_serializability)).
|
||||
|
||||
4. Чтение и поиск [без блокировок](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B1%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B0%D1%8F_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F),
|
||||
без [атомарных операций](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F).
|
||||
Читатели не блокируются операциями записи и не конкурируют
|
||||
между собой, чтение масштабируется линейно по ядрам CPU.
|
||||
> Для точности следует отметить, что "подключение к БД" (старт первой
|
||||
> читающей транзакции в потоке) и "отключение от БД" (закрытие БД или
|
||||
> завершение потока) требуют краткосрочного захвата блокировки для
|
||||
> регистрации/дерегистрации текущего потока в "таблице читателей".
|
||||
4. Reads and queries are [non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm),
|
||||
don't use [atomic operations](https://en.wikipedia.org/wiki/Linearizability#High-level_atomic_operations).
|
||||
Readers don't block each other and aren't blocked by writers. Read perfomance scales linearly with CPU core count.
|
||||
> Though "connect to DB" (start of first read transaction in thread) and "disconnect from DB" (shutdown or thread
|
||||
> termination) requires to acquire a lock to register/unregister current thread from "readers table"
|
||||
|
||||
5. Эффективное хранение дубликатов (ключей с несколькими
|
||||
значениями), без дублирования ключей, с сортировкой значений, в
|
||||
том числе целочисленных (для вторичных индексов).
|
||||
5. Keys with multiple values are stored efficiently without key duplication, sorted by value, including intereger
|
||||
(for secondary indexes).
|
||||
|
||||
6. Эффективная поддержка коротких ключей фиксированной длины, в том числе целочисленных.
|
||||
6. Efficient operation on short fixed length keys, including integer ones.
|
||||
|
||||
7. Амортизационная стоимость любой операции Olog(N),
|
||||
[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor) и RAF (Read Amplification Factor) также Olog(N).
|
||||
7. [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor) и RAF (Read Amplification Factor)
|
||||
are Olog(N).
|
||||
|
||||
8. Нет [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) и журнала
|
||||
транзакций, после сбоев не требуется восстановление. Не требуется компактификация
|
||||
или какое-либо периодическое обслуживание. Поддерживается резервное копирование
|
||||
"по горячему", на работающей БД без приостановки изменения данных.
|
||||
8. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) and transaction journal.
|
||||
In case of a crash no recovery needed. No need for regular maintenance. Backups can be made on the fly on working DB
|
||||
without freezing writers.
|
||||
|
||||
9. Отсутствует какое-либо внутреннее управление памятью или кэшированием. Всё
|
||||
необходимое штатно выполняет ядро ОС!
|
||||
9. No custom memory management, all done with standard OS syscalls.
|
||||
|
||||
|
||||
Сравнение производительности
|
||||
============================
|
||||
Perfomance comparison
|
||||
=====================
|
||||
|
||||
Все представленные ниже данные получены многократным прогоном тестов на
|
||||
ноутбуке Lenovo Carbon-2, i7-4600U 2.1 ГГц, 8 Гб ОЗУ, с SSD-диском
|
||||
SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Гб.
|
||||
All benchmark were done by multiple test runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 ГГц, 8 Гб ОЗУ, SSD
|
||||
SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
|
||||
|
||||
Исходный код бенчмарка [_IOArena_](https://github.com/pmwkaa/ioarena) и
|
||||
сценарии тестирования [доступны на
|
||||
github](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015).
|
||||
Benchmark: [_IOArena_](https://github.com/pmwkaa/ioarena)
|
||||
[test scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
### Интегральная производительность
|
||||
### Integral perfomance
|
||||
|
||||
Показана соотнесенная сумма ключевых показателей производительности в трёх
|
||||
бенчмарках:
|
||||
Here showed sum of perfomance metrics in 3 benchmarks:
|
||||
|
||||
- Чтение/Поиск на машине с 4-мя процессорами;
|
||||
- Read/Search on 4 CPU cores machine;
|
||||
|
||||
- Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями
|
||||
(вставка, чтение, обновление, удаление) в режиме **синхронной фиксации**
|
||||
данных (fdatasync при завершении каждой транзакции или аналог);
|
||||
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations
|
||||
in sync-write mode (fdatasync is called after each transaction);
|
||||
|
||||
- Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями
|
||||
(вставка, чтение, обновление, удаление) в режиме **отложенной фиксации**
|
||||
данных (отложенная запись посредством файловой систем или аналог);
|
||||
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations
|
||||
in lazy-write mode (moment to sync data to persistent storage is decided by OS);
|
||||
|
||||
*Бенчмарк в режиме асинхронной записи не включен по двум причинам:*
|
||||
*Reasons why asynchronous mode isn't benchmarked here:*
|
||||
|
||||
1. Такое сравнение не совсем правомочно, его следует делать с движками
|
||||
ориентированными на хранение данных в памяти ([Tarantool](https://tarantool.io/), [Redis](https://redis.io/)).
|
||||
1. It doesn't make sense as it has to be done with DB engines, oriented for keeping data in memory e.g.
|
||||
[Tarantool](https://tarantool.io/), [Redis](https://redis.io/)), etc.
|
||||
|
||||
2. Превосходство libmdbx становится еще более подавляющем, что мешает
|
||||
восприятию информации.
|
||||
2. perfomance gap is too high to compare in any meaningful way.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
### Масштабируемость чтения
|
||||
### Read Scalability
|
||||
|
||||
Для каждого движка показана суммарная производительность при
|
||||
одновременном выполнении запросов чтения/поиска в 1-2-4-8 потоков на
|
||||
машине с 4-мя физическими процессорами.
|
||||
Summary perfomance with concurrent read/search queries in 1-2-4-8 threads on 4 CPU cores machine.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
### Синхронная фиксация
|
||||
### Sync-write mode
|
||||
|
||||
- Линейная шкала слева и темные прямоугольники соответствуют количеству
|
||||
транзакций в секунду, усредненному за всё время теста.
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean transactions per second
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
- Logarithmic scale on right is in seconds and yellow intervals mean execution time of transactions.
|
||||
Each interval shows minimal and maximum execution time, cross marks standart deviation.
|
||||
|
||||
Выполняется **10.000 транзакций в режиме синхронной фиксации данных** на
|
||||
диске. При этом требуется гарантия, что при аварийном выключении питания
|
||||
(или другом подобном сбое) все данные будут консистентны и полностью
|
||||
соответствовать последней завершенной транзакции. В _libmdbx_ в этом
|
||||
режиме при фиксации каждой транзакции выполняется системный вызов
|
||||
[fdatasync](https://linux.die.net/man/2/fdatasync).
|
||||
**10,000 transactions in sync-write mode**. In case of a crash all data is consistent and state is right after last successful transaction. [fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after each write transaction in this mode.
|
||||
|
||||
В каждой транзакции выполняется комбинированная CRUD-операция (две
|
||||
вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует
|
||||
на пустой базе, а при завершении, в результате выполняемых действий, в
|
||||
базе насчитывается 10.000 небольших key-value записей.
|
||||
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
|
||||
Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
### Отложенная фиксация
|
||||
### Lazy-write mode
|
||||
|
||||
- Линейная шкала слева и темные прямоугольники соответствуют количеству
|
||||
транзакций в секунду, усредненному за всё время теста.
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
- Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standart deviation.
|
||||
|
||||
Выполняется **100.000 транзакций в режиме отложенной фиксации данных**
|
||||
на диске. При этом требуется гарантия, что при аварийном выключении
|
||||
питания (или другом подобном сбое) все данные будут консистентны на
|
||||
момент завершения одной из транзакций, но допускается потеря изменений
|
||||
из некоторого количества последних транзакций, что для многих движков
|
||||
предполагает включение
|
||||
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) (write-ahead
|
||||
logging) либо журнала транзакций, который в свою очередь опирается на
|
||||
гарантию упорядоченности данных в журналируемой файловой системе.
|
||||
_libmdbx_ при этом не ведет WAL, а передает весь контроль файловой
|
||||
системе и ядру ОС.
|
||||
**100,000 transactions in lazy-write mode**.
|
||||
In case of a crash all data is consistent and state is right after one of last transactions, but transactions after it
|
||||
will be lost. Other DB engines use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction journal for that,
|
||||
which in turn depends on order of operations in journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations
|
||||
to filesystem and OS kernel (mmap).
|
||||
|
||||
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
|
||||
Benchmark starts on empty database and after full run the database contains 100,000 small key-value records.
|
||||
|
||||
В каждой транзакции выполняется комбинированная CRUD-операция (две
|
||||
вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует
|
||||
на пустой базе, а при завершении, в результате выполняемых действий, в
|
||||
базе насчитывается 100.000 небольших key-value записей.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
### Асинхронная фиксация
|
||||
### Async-write mode
|
||||
|
||||
- Линейная шкала слева и темные прямоугольники соответствуют количеству
|
||||
транзакций в секунду, усредненному за всё время теста.
|
||||
- Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second
|
||||
|
||||
- Логарифмическая шкала справа и желтые интервальные отрезки
|
||||
соответствуют времени выполнения транзакций. При этом каждый отрезок
|
||||
показывает минимальное и максимальное время затраченное на выполнение
|
||||
транзакций, а крестиком отмечено среднеквадратичное значение.
|
||||
- Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standart deviation.
|
||||
|
||||
Выполняется **1.000.000 транзакций в режиме асинхронной фиксации
|
||||
данных** на диске. При этом требуется гарантия, что при аварийном
|
||||
выключении питания (или другом подобном сбое) все данные будут
|
||||
консистентны на момент завершения одной из транзакций, но допускается
|
||||
потеря изменений из значительного количества последних транзакций. Во
|
||||
всех движках при этом включался режим предполагающий минимальную
|
||||
нагрузку на диск по-записи, и соответственно минимальную гарантию
|
||||
сохранности данных. В _libmdbx_ при этом используется режим асинхронной
|
||||
записи измененных страниц на диск посредством ядра ОС и системного
|
||||
вызова [msync(MS_ASYNC)](https://linux.die.net/man/2/msync).
|
||||
**1,000,000 transactions in async-write mode**. In case of a crash all data will be consistent and state will be right after one of last transactions, but lost transaction count is much higher than in lazy-write mode. All DB engines in this mode do as little writes as possible on persistent storage. _libmdbx_ uses [msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode.
|
||||
|
||||
В каждой транзакции выполняется комбинированная CRUD-операция (две
|
||||
вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует
|
||||
на пустой базе, а при завершении, в результате выполняемых действий, в
|
||||
базе насчитывается 10.000 небольших key-value записей.
|
||||
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
|
||||
Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
### Потребление ресурсов
|
||||
### Cost comparison
|
||||
|
||||
Показана соотнесенная сумма использованных ресурсов в ходе бенчмарка в
|
||||
режиме отложенной фиксации:
|
||||
Summary of used resources during lazy-write mode benchmarks:
|
||||
|
||||
- суммарное количество операций ввода-вывода (IOPS), как записи, так и
|
||||
чтения.
|
||||
- read and write IOPS
|
||||
|
||||
- суммарное затраченное время процессора, как в режиме пользовательских процессов,
|
||||
так и в режиме ядра ОС.
|
||||
- sum of user CPU time and sys CPU time
|
||||
|
||||
- использованное место на диске при завершении теста, после закрытия БД из тестирующего процесса,
|
||||
но без ожидания всех внутренних операций обслуживания (компактификации LSM и т.п.).
|
||||
- used space on persistent storage after the test and closed DB, but not waiting for the end of all internal
|
||||
housekeeping operations (LSM compactification, etc)
|
||||
|
||||
Движок _ForestDB_ был исключен при оформлении результатов, так как
|
||||
относительно конкурентов многократно превысил потребление каждого из
|
||||
ресурсов (потратил процессорное время на генерацию IOPS для заполнения
|
||||
диска), что не позволяло наглядно сравнить показатели остальных движков
|
||||
на одной диаграмме.
|
||||
_ForestDB_ is excluded because benchmark showed it's resource consumption for each resource (CPU, IOPS) much higher than other engines which prevents to meaningfully compare it with them.
|
||||
|
||||
Все данные собирались посредством системного вызова
|
||||
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) и
|
||||
сканированием директорий с данными.
|
||||
All benchmark data is gathered by [getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) syscall and by
|
||||
scanning data directory.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
## Недостатки и Компромиссы
|
||||
## Gotchas
|
||||
|
||||
1. Единовременно может выполняться не более одной транзакция изменения данных
|
||||
(один писатель). Зато все изменения всегда последовательны, не может быть
|
||||
конфликтов или логических ошибок при откате транзакций.
|
||||
1.
|
||||
At one moment there can be only one writer. But this allows to serialize writes and eliminate any possibility
|
||||
of conflict or logical errors during transaction rollback.
|
||||
|
||||
2. Отсутствие [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging)
|
||||
обуславливает относительно большой
|
||||
[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write
|
||||
Amplification Factor). Поэтому фиксация изменений на диске может быть
|
||||
достаточно дорогой и являться главным ограничением производительности
|
||||
при интенсивном изменении данных.
|
||||
> В качестве компромисса _libmdbx_ предлагает несколько режимов ленивой
|
||||
> и/или периодической фиксации. В том числе режим `MAPASYNC`, при котором
|
||||
> изменения происходят только в памяти и асинхронно фиксируются на диске
|
||||
> ядром ОС.
|
||||
2. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) means relatively
|
||||
big [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor).
|
||||
Because of this syncing data to disk might be quite resource intensive and be main perfomance bottleneck
|
||||
during intensive write workload.
|
||||
> As compromise _libmdbx_ allows several modes of lazy and/or periodic syncing, including `MAPASYNC` mode, which modificates
|
||||
> data in memory and asynchronously syncs data to disc, moment to sync is picked by OS.
|
||||
>
|
||||
> Однако, следует воспринимать это свойство аккуратно и взвешенно.
|
||||
> Например, полная фиксация транзакции в БД с журналом потребует минимум 2
|
||||
> IOPS (скорее всего 3-4) из-за накладных расходов в файловой системе. В
|
||||
> _libmdbx_ фиксация транзакции также требует от 2 IOPS. Однако, в БД с
|
||||
> журналом кол-во IOPS будет меняться в зависимости от файловой системы,
|
||||
> но не от кол-ва записей или их объема. Тогда как в _libmdbx_ кол-во
|
||||
> будет расти логарифмически от кол-во записей/строк в БД (по высоте
|
||||
> b+tree).
|
||||
> Although this should be used with care, synchronous transactions in a DB with transaction journal will require 2 IOPS
|
||||
> minimum (probably 3-4 in practice) because of filesystem overhead, overhead depends on filesystem, not on record
|
||||
> count or record size. In _libmdbx_ IOPS count will grow logarithmically depending on record count in DB (height of B+ tree)
|
||||
> and will require at least 2 IOPS per transaction too.
|
||||
|
||||
3. [COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8)
|
||||
для реализации [MVCC](https://ru.wikipedia.org/wiki/MVCC) выполняется на
|
||||
уровне страниц в [B+
|
||||
дереве](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
||||
Поэтому изменение данных амортизационно требует копирования Olog(N)
|
||||
страниц, что расходует [пропускную способность оперативной
|
||||
памяти](https://en.wikipedia.org/wiki/Memory_bandwidth) и является
|
||||
основным ограничителем производительности в режиме `MAPASYNC`.
|
||||
> Этот недостаток неустраним, тем не менее следует дать некоторые пояснения.
|
||||
> Дело в том, что фиксация изменений на диске потребует гораздо более
|
||||
> значительного копирования данных в памяти и массы других затратных операций.
|
||||
> Поэтому обусловленное этим недостатком падение производительности становится
|
||||
> заметным только при отказе от фиксации изменений на диске.
|
||||
> Соответственно, корректнее сказать что _libmdbx_ позволяет
|
||||
> получить персистентность ценой минимального падения производительности.
|
||||
> Если же нет необходимости оперативно сохранять данные, то логичнее
|
||||
> использовать `std::map`.
|
||||
|
||||
4. В _LMDB_ существует проблема долгих чтений (приостановленных читателей),
|
||||
которая приводит к деградации производительности и переполнению БД.
|
||||
> В _libmdbx_ предложены средства для предотвращения, быстрого выхода из
|
||||
> некомфортной ситуации и устранения её последствий. Подробности ниже.
|
||||
|
||||
5. В _LMDB_ есть вероятность разрушения БД в режиме `WRITEMAP+MAPASYNC`.
|
||||
В _libmdbx_ для `WRITEMAP+MAPASYNC` гарантируется как сохранность базы,
|
||||
так и согласованность данных.
|
||||
> Дополнительно, в качестве альтернативы, предложен режим `UTTERLY_NOSYNC`.
|
||||
> Подробности ниже.
|
||||
3. [CoW](https://en.wikipedia.org/wiki/Copy-on-write)
|
||||
for [MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) is done on memory page level with [B+
|
||||
trees](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
|
||||
Therefore altering data requires to copy about Olog(N) memory pages, which uses [memory bandwidth](https://en.wikipedia.org/wiki/Memory_bandwidth) and is main perfomance bottleneck in `MAPASYNC` mode.
|
||||
> This is unavoidable, but isn't that bad. Syncing data to disk requires much more similiar operations which will
|
||||
> be done by OS, therefore this is noticeable only if data sync to persistent storage is fully disabled.
|
||||
> _libmdbx_ allows to safely save data to persistent storage with minimal perfomance overhead. If there is no need
|
||||
> to save data to persistent storage then it's much more preferrable to use `std::map`.
|
||||
|
||||
|
||||
#### Проблема долгих чтений
|
||||
4. LMDB has a problem of long-time readers which degrades perfomance and bloats DB
|
||||
> _libmdbx_ addresses that, details below.
|
||||
|
||||
*Следует отметить*, что проблема "сборки мусора" так или иначе
|
||||
существует во всех СУБД (Vacuum в PostgreSQL). Однако в случае _libmdbx_
|
||||
и LMDB она проявляется более остро, прежде всего из-за высокой
|
||||
производительности, а также из-за намеренного упрощения внутренних
|
||||
механизмов ради производительности.
|
||||
|
||||
Понимание проблемы требует некоторых пояснений, которые
|
||||
изложены ниже, но могут быть сложны для быстрого восприятия.
|
||||
Поэтому, тезисно:
|
||||
|
||||
* Изменение данных на фоне долгой операции чтения может
|
||||
приводить к исчерпанию места в БД.
|
||||
|
||||
* После чего любая попытка обновить данные будет приводить к
|
||||
ошибке `MAP_FULL` до завершения долгой операции чтения.
|
||||
|
||||
* Характерными примерами долгих чтений являются горячее
|
||||
резервное копирования и отладка клиентского приложения при
|
||||
активной транзакции чтения.
|
||||
|
||||
* В оригинальной _LMDB_ после этого будет наблюдаться
|
||||
устойчивая деградация производительности всех механизмов
|
||||
обратной записи на диск (в I/O контроллере, в гипервизоре,
|
||||
в ядре ОС).
|
||||
|
||||
* В _libmdbx_ предусмотрен механизм аварийного прерывания таких
|
||||
операций, а также режим `LIFO RECLAIM` устраняющий последующую
|
||||
деградацию производительности.
|
||||
|
||||
Операции чтения выполняются в контексте снимка данных (версии
|
||||
БД), который был актуальным на момент старта транзакции чтения. Такой
|
||||
читаемый снимок поддерживается неизменным до завершения операции. В свою
|
||||
очередь, это не позволяет повторно использовать страницы БД в
|
||||
последующих версиях (снимках БД).
|
||||
|
||||
Другими словами, если обновление данных выполняется на фоне долгой
|
||||
операции чтения, то вместо повторного использования "старых" ненужных
|
||||
страниц будут выделяться новые, так как "старые" страницы составляют
|
||||
снимок БД, который еще используется долгой операцией чтения.
|
||||
|
||||
В результате, при интенсивном изменении данных и достаточно длительной
|
||||
операции чтения, в БД могут быть исчерпаны свободные страницы, что не
|
||||
позволит создавать новые снимки/версии БД. Такая ситуация будет
|
||||
сохраняться до завершения операции чтения, которая использует старый
|
||||
снимок данных и препятствует повторному использованию страниц БД.
|
||||
|
||||
Однако, на этом проблемы не заканчиваются. После описанной ситуации, все
|
||||
дополнительные страницы, которые были выделены пока переработка старых
|
||||
была невозможна, будут участвовать в цикле выделения/освобождения до
|
||||
конца жизни экземпляра БД. В оригинальной _LMDB_ этот цикл использования
|
||||
страниц работает по принципу [FIFO](https://ru.wikipedia.org/wiki/FIFO).
|
||||
Поэтому увеличение количества циркулирующий страниц, с точки зрения
|
||||
механизмов кэширования и/или обратной записи, выглядит как увеличение
|
||||
рабочего набор данных. Проще говоря, однократное попадание в ситуацию
|
||||
"уснувшего читателя" приводит к устойчивому эффекту вымывания I/O кэша
|
||||
при всех последующих изменениях данных.
|
||||
|
||||
Для устранения описанных проблемы в _libmdbx_ сделаны существенные
|
||||
доработки, подробности ниже. Иллюстрации к проблеме "долгих чтений"
|
||||
можно найти в [слайдах презентации](http://www.slideshare.net/leoyuriev/lmdb).
|
||||
|
||||
Там же приведен пример количественной оценки прироста производительности
|
||||
за счет эффективной работы [BBWC](https://en.wikipedia.org/wiki/BBWC)
|
||||
при включении `LIFO RECLAIM` в _libmdbx_.
|
||||
5. _LMDB_ is susceptible to DB corruption in `WRITEMAP+MAPASYNC` mode.
|
||||
_libmdbx_ in `WRITEMAP+MAPASYNC` guarantees DB integrity and consistency of data.
|
||||
> Additionaly there is an alternative: `UTTERLY_NOSYNC` mode. Details below
|
||||
|
||||
|
||||
#### Сохранность данных в режиме асинхронной фиксации
|
||||
#### Long-time read transactions problem
|
||||
|
||||
При работе в режиме `WRITEMAP+MAPSYNC` запись измененных страниц
|
||||
выполняется ядром ОС, что имеет ряд преимуществ. Так например, при крахе
|
||||
приложения, ядро ОС сохранит все изменения.
|
||||
Garbage collection problem exists in all databases one way or another (e.g. VACUUM in PostgreSQL).
|
||||
But in _libmbdx_ and LMDB it's even more important because of high perfomance and deliberate
|
||||
simplification of internals with emphasis on perfomance.
|
||||
|
||||
Однако, при аварийном отключении питания или сбое в ядре ОС, на диске
|
||||
может быть сохранена только часть измененных страниц БД. При этом с большой
|
||||
вероятностью может оказаться так, что будут сохранены мета-страницы со
|
||||
ссылками на страницы с новыми версиями данных, но не сами новые данные.
|
||||
В этом случае БД будет безвозвратна разрушена, даже если до аварии
|
||||
производилась полная синхронизация данных (посредством
|
||||
`mdbx_env_sync()`).
|
||||
* Altering data during long read operation may exhaust available space on persistent storage
|
||||
|
||||
В _libmdbx_ эта проблема устранена путем полной переработки
|
||||
пути записи данных:
|
||||
* If available space is exhausted then any attempt to update data
|
||||
results in `MAP_FULL` error until long read operation ends
|
||||
|
||||
* В режиме `WRITEMAP+MAPSYNC` _libmdbx_ не обновляет
|
||||
мета-страницы непосредственно, а поддерживает их теневые копии
|
||||
с переносом изменений после фиксации данных.
|
||||
* Main examples of long readers is hot backup
|
||||
and debugging of client application which actively uses read transactions
|
||||
|
||||
* При завершении транзакций, в зависимости от состояния
|
||||
синхронности данных между диском и оперативной память,
|
||||
_libmdbx_ помечает точки фиксации либо как сильные (strong),
|
||||
либо как слабые (weak). Так например, в режиме
|
||||
`WRITEMAP+MAPSYNC` завершаемые транзакции помечаются как
|
||||
слабые, а при явной синхронизации данных как сильные.
|
||||
* In _LMDB_ this results in degraded perfomace of all operations
|
||||
of syncing data to persistent storage.
|
||||
|
||||
* В _libmdbx_ поддерживается не две, а три отдельные мета-страницы.
|
||||
Это позволяет выполнять фиксацию транзакций с формированием как
|
||||
сильной, так и слабой точки фиксации, без потери двух предыдущих
|
||||
точек фиксации (из которых одна может быть сильной, а вторая слабой).
|
||||
В результате, _libmdbx_ позволяет в произвольном порядке чередовать
|
||||
сильные и слабые точки фиксации без нарушения соответствующих
|
||||
гарантий в случае неожиданной системной аварии во время фиксации.
|
||||
* _libmdbx_ has a mechanism which aborts such operations and `LIFO RECLAIM`
|
||||
mode which addresses perfomance degradation.
|
||||
|
||||
* При открытии БД выполняется автоматический откат к последней
|
||||
сильной фиксации. Этим обеспечивается гарантия сохранности БД.
|
||||
Read operations operate only over snapshot of DB which is consistent on the moment when read transaction started.
|
||||
This snapshot doesn't change throughout the transaction but this leads to inability to reclaim the pages until
|
||||
read transaction ends.
|
||||
|
||||
Такая гарантия надежности не дается бесплатно. Для
|
||||
сохранности данных, страницы формирующие крайний снимок с
|
||||
сильной фиксацией, не должны повторно использоваться
|
||||
(перезаписываться) до формирования следующей сильной точки
|
||||
фиксации. Таким образом, крайняя точка фиксации создает
|
||||
описанный выше эффект "долгого чтения". Разница же здесь в том,
|
||||
что при исчерпании свободных страниц ситуация будет
|
||||
автоматически исправлена, посредством записи изменений на диск
|
||||
и формированием новой сильной точки фиксации.
|
||||
In _LMDB_ this leads to a problem that memory pages, allocated for operations during long read, will be used for operations
|
||||
and won't be reclaimed until DB process terminates. In _LMDB_ they are used in
|
||||
[FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)) manner, which causes increased page count
|
||||
and less chance of cache hit during I/O. In other words: one long-time reader can impact perfomance of all database
|
||||
until it'll be reopened.
|
||||
|
||||
Таким образом, в режиме безопасной асинхронной фиксации _libmdbx_ будет
|
||||
всегда использовать новые страницы до исчерпания места в БД или до явного
|
||||
формирования сильной точки фиксации посредством `mdbx_env_sync()`.
|
||||
При этом суммарный трафик записи на диск будет примерно такой-же,
|
||||
как если бы отдельно фиксировалась каждая транзакций.
|
||||
_libmdbx_ addresses the problem, details below. Illustrations to this problem can be found in the
|
||||
[presentation](http://www.slideshare.net/leoyuriev/lmdb). There is also example of perfomance increase thanks to
|
||||
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) when `LIFO RECLAIM` enabled in _libmdbx_.
|
||||
|
||||
В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` когда
|
||||
при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
#### Data safety in async-write mode
|
||||
|
||||
В последующих версиях _libmdbx_ будут предусмотрены средства
|
||||
для асинхронной записи данных на диск с автоматическим
|
||||
формированием сильных точек фиксации.
|
||||
In `WRITEMAP+MAPSYNC` mode dirty pages are written to persistent storage by kernel. This means that in case of application
|
||||
crash OS kernel will write all dirty data to disk and nothing will be lost. But in case of hardware malfunction or OS kernel
|
||||
fatal error only some dirty data might be synced to disk, and there is high probability that pages with metadata saved,
|
||||
will point to non-saved, hence non-existent, data pages. In such situation DB is completely corrupted and can't be
|
||||
repaired even if there was full sync before the crash via `mdbx_env_sync().
|
||||
|
||||
_libmdbx_ addresses this by fully reimplementing write path of data:
|
||||
|
||||
* In `WRITEMAP+MAPSYNC` mode meta-data pages aren't updated in place, instead their shadow copies are used and their updates
|
||||
are synced after data is flushed to disk.
|
||||
|
||||
* During transaction commit _libmdbx_ marks synchronization points as steady or weak depending on how much synchronization
|
||||
needed between RAM and persistent storage, e.g. in `WRITEMAP+MAPSYNC` commited transactions are marked as weak,
|
||||
but during explicit data synchronization - as steady.
|
||||
|
||||
* _libmdbx_ maintains three separate meta-pages instead of two. This allows to commit transaction with steady or
|
||||
weak synchronization point without losing two previous synchronization points (one of them can be steady, and second - weak).
|
||||
This allows to order weak and steady synchronization points in any order without losing consistency in case of system crash.
|
||||
|
||||
* During DB open _libmdbx_ rollbacks to the last steady synchronization point, this guarantees database integrity.
|
||||
|
||||
For data safety pages which form database snapshot with steady synchronization point must not be updated until next steady
|
||||
synchronization point. So last steady synchronization point creates "long-time read" effect. The only difference that in case
|
||||
of memory exhaustion the problem will be immediatly addressed by flushing changes to persistent storage and forming new steady
|
||||
synchronization point.
|
||||
|
||||
So in async-write mode _libmdbx_ will always use new pages until memory is exhausted or `mdbx_env_sync()`is invoked. Total
|
||||
disk usage will be almost the same as in sync-write mode.
|
||||
|
||||
Current _libmdbx_ gives a choice of safe async-write mode (default) and `UTTERLY_NOSYNC` mode which may result in full DB
|
||||
corruption during system crash as with LMDB.
|
||||
|
||||
Next version of _libmdbx_ will create steady synchronization points automatically in async-write mode.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Доработки и усовершенствования относительно LMDB
|
||||
Improvements over LMDB
|
||||
================================================
|
||||
|
||||
1. Режим `LIFO RECLAIM`.
|
||||
1. `LIFO RECLAIM` mode:
|
||||
|
||||
Для повторного использования выбираются не самые старые, а
|
||||
самые новые страницы из доступных. За счет этого цикл
|
||||
использования страниц всегда имеет минимальную длину и не
|
||||
зависит от общего числа выделенных страниц.
|
||||
The newest pages are picked for reuse instead of the oldest.
|
||||
This allows to minimize reclaim loop and make it execution time independent from total page count.
|
||||
|
||||
В результате механизмы кэширования и обратной записи работают с
|
||||
максимально возможной эффективностью. В случае использования
|
||||
контроллера дисков или системы хранения с
|
||||
[BBWC](https://en.wikipedia.org/wiki/BBWC) возможно
|
||||
многократное увеличение производительности по записи
|
||||
(обновлению данных).
|
||||
This results in OS kernel cache mechanisms working with maximum efficiency.
|
||||
In case of using disc controllers or storages with
|
||||
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) this may greatly improve
|
||||
write perfomance.
|
||||
|
||||
2. Обработчик `OOM-KICK`.
|
||||
2. `OOM-KICK` callback.
|
||||
|
||||
Посредством `mdbx_env_set_oomfunc()` может быть установлен
|
||||
внешний обработчик (callback), который будет вызван при
|
||||
исчерпания свободных страниц из-за долгой операцией чтения.
|
||||
Обработчику будет передан PID и pthread_id виновника.
|
||||
В свою очередь обработчик может предпринять одно из действий:
|
||||
`mdbx_env_set_oomfunc()` allows to set a callback, which will be called
|
||||
in the event of memory exhausting during long-time read transaction.
|
||||
Callback will be invoked with PID and pthread_id of offending thread as parameters.
|
||||
Callback can do any of this things to remedy the problem:
|
||||
|
||||
* нейтрализовать виновника (отправить сигнал kill #9), если
|
||||
долгое чтение выполняется сторонним процессом;
|
||||
* wait for read transaction to finish normally;
|
||||
|
||||
* отменить или перезапустить проблемную операцию чтения, если
|
||||
операция выполняется одним из потоков текущего процесса;
|
||||
* kill the offending process (signal 9), if separate process is doing long-time read;
|
||||
|
||||
* подождать некоторое время, в расчете что проблемная операция
|
||||
чтения будет штатно завершена;
|
||||
* abort or restart offending read transaction if it's running in sibling thread;
|
||||
|
||||
* прервать текущую операцию изменения данных с возвратом кода
|
||||
ошибки.
|
||||
* abort current write transaction with returning error code
|
||||
|
||||
3. Гарантия сохранности БД в режиме `WRITEMAP+MAPSYNC`.
|
||||
3. Guarantee of DB integrity in `WRITEMAP+MAPSYNC` mode:
|
||||
|
||||
В текущей версии _libmdbx_ вам предоставляется выбор между безопасным
|
||||
режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC`
|
||||
когда при системной аварии есть шанс полного разрушения БД как в LMDB.
|
||||
Для подробностей смотрите раздел
|
||||
[Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации).
|
||||
Current _libmdbx_ gives a choice of safe async-write mode (default) and `UTTERLY_NOSYNC` mode which may result in full
|
||||
DB corruption during system crash as with LMDB. For details see
|
||||
[Data safety in async-write mode](#data-safety-in-async-write-mode)
|
||||
|
||||
4. Возможность автоматического формирования контрольных точек
|
||||
(сброса данных на диск) при накоплении заданного объёма изменений,
|
||||
устанавливаемого функцией `mdbx_env_set_syncbytes()`.
|
||||
4. Automatic creation of synchronization points (flush changes to persistent storage)
|
||||
when changes reach set threshold (threshold can be set by `mdbx_env_set_syncbytes()`).
|
||||
|
||||
5. Возможность получить отставание текущей транзакции чтения от
|
||||
последней версии данных в БД посредством `mdbx_txn_straggler()`.
|
||||
5. Ability to get how far current readonly snapshot is from latest version of the DB by `mdbx_txn_straggler()`
|
||||
|
||||
6. Утилита mdbx_chk для проверки БД и функция `mdbx_env_pgwalk()` для
|
||||
обхода всех страниц БД.
|
||||
6. mdbx_chk tool for DB checking and `mdbx_env_pgwalk()` for pagewalking all pages in DB
|
||||
|
||||
7. Управление отладкой и получение отладочных сообщений посредством
|
||||
`mdbx_setup_debug()`.
|
||||
7. Control over debugging and receiveing of debugging messages via `mdbx_setup_debug()`
|
||||
|
||||
8. Возможность связать с каждой завершаемой транзакцией до 3
|
||||
дополнительных маркеров посредством `mdbx_canary_put()`, и прочитать их
|
||||
в транзакции чтения посредством `mdbx_canary_get()`.
|
||||
8. Ability to assign up to 3 markers to commiting transaction with `mdbx_canary_put()` and then get them in read transaction
|
||||
by `mdbx_canary_get()`
|
||||
|
||||
9. Возможность узнать есть ли за текущей позицией курсора строка данных
|
||||
посредством `mdbx_cursor_eof()`.
|
||||
9. Check if there is a row with data after current cursor position via `mdbx_cursor_eof()`
|
||||
|
||||
10. Возможность явно запросить обновление существующей записи, без
|
||||
создания новой посредством флажка `MDBX_CURRENT` для `mdbx_put()`.
|
||||
10. Ability to explicitly request update of current record without creating new record. Implemented as `MDBX_CURRENT` flag
|
||||
for `mdbx_put()`
|
||||
|
||||
11. Возможность посредством `mdbx_replace()` обновить или удалить запись
|
||||
с получением предыдущего значения данных, а также адресно изменить
|
||||
конкретное multi-значение.
|
||||
11. Ability to update or delete record and get previous value via `mdbx_replace()` Also can update specific multi-value.
|
||||
|
||||
12. Поддержка ключей и значений нулевой длины, включая сортированные
|
||||
дубликаты.
|
||||
12. Support for keys and values of zero length, including sorted duplicates
|
||||
|
||||
13. Исправленный вариант `mdbx_cursor_count()`, возвращающий корректное
|
||||
количество дубликатов для всех типов таблиц и любого положения курсора.
|
||||
13. Fixed `mdbx_cursor_count()`, which returns correct count of duplicated for all table types and any cursor position
|
||||
|
||||
14. Возможность открыть БД в эксклюзивном режиме посредством
|
||||
`mdbx_env_open_ex()`, например в целях её проверки.
|
||||
14. Ability to open DB in exclusive mode via `mdbx_env_open_ex()`, e.g. for integrity check
|
||||
|
||||
15. Возможность закрыть БД в "грязном" состоянии (без сброса данных и
|
||||
формирования сильной точки фиксации) посредством `mdbx_env_close_ex()`.
|
||||
15. Ability to close DB in "dirty" state (without data flush and creation of steady synchronization point)
|
||||
via `mdbx_env_close_ex()`
|
||||
|
||||
16. Возможность получить посредством `mdbx_env_info()` дополнительную
|
||||
информацию, включая номер самой старой версии БД (снимка данных),
|
||||
который используется одним из читателей.
|
||||
16. Ability to get addition info, including number of the oldest snapshot of DB, which is used by one of the readers.
|
||||
Implemented via `mdbx_env_info()`
|
||||
|
||||
17. Функция `mdbx_del()` не игнорирует дополнительный (уточняющий)
|
||||
аргумент `data` для таблиц без дубликатов (без флажка `MDBX_DUPSORT`), а
|
||||
при его ненулевом значении всегда использует его для сверки с удаляемой
|
||||
записью.
|
||||
17. `mdbx_del()` doesn't ignore additional argument (specifier) `data`
|
||||
for tables without duplicates (without flag `MDBX_DUPSORT`), if `data` is not zero then always uses it to verify
|
||||
record, which is being deleted
|
||||
|
||||
18. Возможность открыть dbi-таблицу, одновременно с установкой
|
||||
компараторов для ключей и данных, посредством `mdbx_dbi_open_ex()`.
|
||||
18. Ability to open dbi-table with simultaneous setup of comparators for keys and values, via `mdbx_dbi_open_ex()`
|
||||
|
||||
19. Возможность посредством `mdbx_is_dirty()` определить находятся ли
|
||||
некоторый ключ или данные в "грязной" странице БД. Таким образом,
|
||||
избегая лишнего копирования данных перед выполнением модифицирующих
|
||||
операций (значения в размещенные "грязных" страницах могут быть
|
||||
перезаписаны при изменениях, иначе они будут неизменны).
|
||||
19. Ability to find out if key or value are in dirty page. This may be useful to make a decision to avoid
|
||||
excessive CoW before updates. Implemented via `mdbx_is_dirty()`
|
||||
|
||||
20. Корректное обновление текущей записи, в том числе сортированного
|
||||
дубликата, при использовании режима `MDBX_CURRENT` в
|
||||
`mdbx_cursor_put()`.
|
||||
20. Correct update of current recordi in `MDBX_CURRENT` mode of `mdbx_cursor_put()`, including sorted duplicated.
|
||||
|
||||
21. Все курсоры, как в транзакциях только для чтения, так и в пишущих,
|
||||
могут быть переиспользованы посредством `mdbx_cursor_renew()` и ДОЛЖНЫ
|
||||
ОСВОБОЖДАТЬСЯ ЯВНО.
|
||||
>
|
||||
> ## _ВАЖНО_, Обратите внимание!
|
||||
>
|
||||
> Это единственное изменение в API, которое значимо меняет
|
||||
> семантику управления курсорами и может приводить к утечкам
|
||||
> памяти. Следует отметить, что это изменение вынужденно.
|
||||
> Так устраняется неоднозначность с массой тяжких последствий:
|
||||
>
|
||||
> - обращение к уже освобожденной памяти;
|
||||
> - попытки повторного освобождения памяти;
|
||||
21. All cursors in all read and write transactions can be reused by `mdbx_cursor_renew()` and MUST be freed explicitly.
|
||||
> ## Caution
|
||||
>
|
||||
> This is the only change of API, which changes semantics of cursor management
|
||||
> and can lead to memory leaks on misuse. This is a needed change as it eliminates ambiguity
|
||||
> which helps to avoid such errors as:
|
||||
> - use-after-free;
|
||||
> - double-free;
|
||||
> - memory corruption and segfaults.
|
||||
|
||||
22. Дополнительный код ошибки `MDBX_EMULTIVAL`, который возвращается из
|
||||
`mdbx_put()` и `mdbx_replace()` при попытке выполнить неоднозначное
|
||||
обновление или удаления одного из нескольких значений с одним ключом.
|
||||
22. Additional error code `MDBX_EMULTIVAL`, which is returned by `mdbx_put()` and
|
||||
`mdbx_replace()` in case os ambigous update or delete.
|
||||
|
||||
23. Возможность посредством `mdbx_get_ex()` получить значение по
|
||||
заданному ключу, одновременно с количеством дубликатов.
|
||||
23. Ability to get value by key and duplicates count by `mdbx_get_ex()`
|
||||
|
||||
24. Наличие функций `mdbx_cursor_on_first()` и `mdbx_cursor_on_last()`,
|
||||
которые позволяют быстро выяснить стоит ли курсор на первой/последней
|
||||
позиции.
|
||||
24. Functions `mdbx_cursor_on_first() and mdbx_cursor_on_last(), which allows to know if cursor is currently on first or
|
||||
last position respectevely
|
||||
|
||||
25. При завершении читающих транзакций, открытые в них DBI-хендлы не
|
||||
закрываются и не теряются при завершении таких транзакций посредством
|
||||
`mdbx_txn_abort()` или `mdbx_txn_reset()`. Что позволяет избавится от ряда
|
||||
сложно обнаруживаемых ошибок.
|
||||
25. If read transaction is aborted via `mdbx_txn_abort()` or `mdbx_txn_reset()` then DBI-handles, which were opened in it,
|
||||
aren't closed or deleted. This allows to avoid several types of hard-to-debug errors.
|
||||
|
||||
26. Генерация последовательностей посредством `mdbx_dbi_sequence()`.
|
||||
26. Sequence generation via `mdbx_dbi_sequence()`.
|
||||
|
||||
27. Расширенное динамическое управление размером БД, включая выбор
|
||||
размера страницы посредством `mdbx_env_set_geometry()`,
|
||||
в том числе в **Windows**
|
||||
27. Advanced dynamic control over DB size, including ability to choose page size via `mdbx_env_set_geometry()`,
|
||||
including on Windows
|
||||
|
||||
28. Три мета-страницы вместо двух, что позволяет гарантированно
|
||||
консистентно обновлять слабые контрольные точки фиксации без риска
|
||||
повредить крайнюю сильную точку фиксации.
|
||||
28. Three meta-pages instead two, this allows to guarantee consistently update weak synchronisation points without risking to
|
||||
corrupt last steady synchronisation point.
|
||||
|
||||
29. В _libmdbx_ реализован автоматический возврат освобождающихся
|
||||
страниц в область нераспределенного резерва в конце файла данных. При
|
||||
этом уменьшается количество страниц загруженных в память и участвующих в
|
||||
цикле обновления данных и записи на диск. Фактически _libmdbx_ выполняет
|
||||
постоянную компактификацию данных, но не затрачивая на это
|
||||
дополнительных ресурсов, а только освобождая их. При освобождении места
|
||||
в БД и установки соответствующих параметров геометрии базы данных, также будет
|
||||
уменьшаться размер файла на диске, в том числе в **Windows**.
|
||||
29. Automatic reclaim of freed pages to specific reserved space in the end of database file. This lowers amount of pages,
|
||||
loaded to memory, used in update/flush loop. In fact _llibmdbx_ constantly perfoms compactification of data,
|
||||
but doesn't use addition resources for that. Space reclaim of DB and setup of database geometry parameters also decreases
|
||||
size of the database on disk, including on Windows.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
Reference in New Issue
Block a user