mirror of
https://github.com/isar/libmdbx.git
synced 2025-08-23 21:14:28 +08:00
mdbx: merge branch master into devel.
This commit is contained in:
@@ -1,22 +0,0 @@
|
|||||||
version: 2
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
branches:
|
|
||||||
ignore:
|
|
||||||
- gh-pages
|
|
||||||
docker:
|
|
||||||
- image: circleci/buildpack-deps:20.04
|
|
||||||
environment:
|
|
||||||
- TESTDB: /tmp/test.db
|
|
||||||
- TESTLOG: /tmp/test.log
|
|
||||||
steps:
|
|
||||||
- checkout
|
|
||||||
- run: ulimit -c unlimited && MDBX_BUILD_OPTIONS="-DNDEBUG=1 -DMDBX_FORCE_ASSERTIONS=1" make test-ubsan
|
|
||||||
- run:
|
|
||||||
command: |
|
|
||||||
mkdir -p /tmp/artifacts
|
|
||||||
mv -t /tmp/artifacts $TESTLOG $TESTDB core.*
|
|
||||||
when: on_fail
|
|
||||||
- store_artifacts:
|
|
||||||
path: /tmp/artifacts
|
|
||||||
destination: test-artifacts
|
|
||||||
@@ -1,6 +0,0 @@
|
|||||||
freebsd_instance:
|
|
||||||
image_family: freebsd-12-1-snap
|
|
||||||
|
|
||||||
task:
|
|
||||||
install_script: pkg install -y gmake bash git
|
|
||||||
script: git fetch --tags --force && gmake MDBX_BUILD_OPTIONS="-DNDEBUG=1 -DMDBX_FORCE_ASSERTIONS=1" check
|
|
||||||
12
.github/FUNDING.yml
vendored
12
.github/FUNDING.yml
vendored
@@ -1,12 +0,0 @@
|
|||||||
# These are supported funding model platforms
|
|
||||||
|
|
||||||
github: # Replace with up to 4 GitHub Sponsors-enabled usernames e.g., [user1, user2]
|
|
||||||
patreon: # Replace with a single Patreon username
|
|
||||||
open_collective: # Replace with a single Open Collective username
|
|
||||||
ko_fi: # Replace with a single Ko-fi username
|
|
||||||
tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
|
|
||||||
community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
|
|
||||||
liberapay: # Replace with a single Liberapay username
|
|
||||||
issuehunt: # Replace with a single IssueHunt username
|
|
||||||
otechie: # Replace with a single Otechie username
|
|
||||||
custom: ['https://sobe.ru/na/libmdbx']
|
|
||||||
11
.github/actions/spelling/excludes.txt
vendored
11
.github/actions/spelling/excludes.txt
vendored
@@ -1,11 +0,0 @@
|
|||||||
\.def$
|
|
||||||
^AUTHORS$
|
|
||||||
^\.github/FUNDING\.yml$
|
|
||||||
^\.github/actions/spelling/
|
|
||||||
^\.github/workflows/ci\.yml$
|
|
||||||
^\.github/workflows/coverity\.yml$
|
|
||||||
^\.github/workflows/doxygen-github-pages\.yml$
|
|
||||||
^\.gitignore$
|
|
||||||
^\.travis\.yml$
|
|
||||||
^packages/buildroot/
|
|
||||||
^CMakeSettings\.json$
|
|
||||||
2030
.github/actions/spelling/expect.txt
vendored
2030
.github/actions/spelling/expect.txt
vendored
File diff suppressed because it is too large
Load Diff
6
.github/actions/spelling/patterns.txt
vendored
6
.github/actions/spelling/patterns.txt
vendored
@@ -1,6 +0,0 @@
|
|||||||
# numbers
|
|
||||||
(?:[\\0][xX]|[uU]\+|#)[0-9a-fA-FgGrR]{2,}[uU]?[lL]{0,2}\b
|
|
||||||
# avoid false positive
|
|
||||||
-{1,2}force\W
|
|
||||||
# flags
|
|
||||||
(?!\w)-{1,2}[fDW]
|
|
||||||
69
.github/workflows/MinGW.yml
vendored
69
.github/workflows/MinGW.yml
vendored
@@ -1,69 +0,0 @@
|
|||||||
name: MinGW
|
|
||||||
|
|
||||||
on:
|
|
||||||
pull_request:
|
|
||||||
push:
|
|
||||||
branches: mingw
|
|
||||||
paths-ignore:
|
|
||||||
- '.circleci/**'
|
|
||||||
- '.github/actions/spelling/**'
|
|
||||||
- 'docs/**'
|
|
||||||
- 'packages**'
|
|
||||||
- .cirrus.yml
|
|
||||||
- .clang-format
|
|
||||||
- .gitignore
|
|
||||||
- .travis.yml
|
|
||||||
- AUTHORS
|
|
||||||
- COPYRIGHT
|
|
||||||
- ChangeLog.md
|
|
||||||
- LICENSE
|
|
||||||
- README.md
|
|
||||||
- appveyor.yml
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
runs-on: [windows-latest]
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v2
|
|
||||||
- name: fetch tags
|
|
||||||
run: git fetch --unshallow --tags --prune --force
|
|
||||||
- name: append PATH
|
|
||||||
run: echo 'C:/ProgramData/chocolatey/lib/mingw/tools/install/mingw64/bin' >> $GITHUB_PATH
|
|
||||||
- name: update mingw64
|
|
||||||
# wanna version >= 10.2
|
|
||||||
run: choco upgrade mingw -y --no-progress && refreshenv
|
|
||||||
- name: build-make
|
|
||||||
shell: bash
|
|
||||||
run: |
|
|
||||||
CC=gcc CXX=g++ make MDBX_BUILD_OPTIONS=-DMDBX_DEBUG=1 all build-test tools-static
|
|
||||||
- name: configure-dll
|
|
||||||
shell: bash
|
|
||||||
run: |
|
|
||||||
mkdir build-dll && cd build-dll && \
|
|
||||||
cmake -G "MinGW Makefiles" -DMDBX_BUILD_SHARED_LIBRARY:BOOL=ON -DMDBX_INSTALL_STATIC:BOOL=OFF -DMDBX_ENABLE_TESTS:BOOL=ON ..
|
|
||||||
- name: build-dll
|
|
||||||
shell: bash
|
|
||||||
run: cd build-dll && cmake --build .
|
|
||||||
- name: test-dll
|
|
||||||
shell: bash
|
|
||||||
run: |
|
|
||||||
export "PATH=/c/programdata/chocolatey/lib/mingw/tools/install/mingw64/bin:$PATH" && \
|
|
||||||
cd build-dll && \
|
|
||||||
./mdbx_test.exe --progress --console=no --pathname=test.db --dont-cleanup-after basic && \
|
|
||||||
./mdbx_chk.exe -nvv test.db
|
|
||||||
- name: configure-static
|
|
||||||
shell: bash
|
|
||||||
run: |
|
|
||||||
mkdir build-static && cd build-static && \
|
|
||||||
cmake -G "MinGW Makefiles" -DMDBX_BUILD_SHARED_LIBRARY:BOOL=OFF -DMDBX_INSTALL_STATIC:BOOL=ON -DMDBX_ENABLE_TESTS:BOOL=ON ..
|
|
||||||
- name: build-static
|
|
||||||
shell: bash
|
|
||||||
run: |
|
|
||||||
cd build-static && cmake --build .
|
|
||||||
- name: run-test
|
|
||||||
shell: bash
|
|
||||||
run: |
|
|
||||||
export "PATH=/c/programdata/chocolatey/lib/mingw/tools/install/mingw64/bin:$PATH" && \
|
|
||||||
cd build-static && \
|
|
||||||
./mdbx_test.exe --progress --console=no --pathname=test.db --dont-cleanup-after basic && \
|
|
||||||
./mdbx_chk.exe -nvv test.db
|
|
||||||
41
.github/workflows/android.yml
vendored
41
.github/workflows/android.yml
vendored
@@ -1,41 +0,0 @@
|
|||||||
name: Android
|
|
||||||
|
|
||||||
on:
|
|
||||||
pull_request:
|
|
||||||
push:
|
|
||||||
branches-ignore:
|
|
||||||
- coverity_scan
|
|
||||||
paths-ignore:
|
|
||||||
- '.circleci/**'
|
|
||||||
- '.github/actions/spelling/**'
|
|
||||||
- 'docs/**'
|
|
||||||
- 'packages**'
|
|
||||||
- .cirrus.yml
|
|
||||||
- .clang-format
|
|
||||||
- .gitignore
|
|
||||||
- .travis.yml
|
|
||||||
- AUTHORS
|
|
||||||
- COPYRIGHT
|
|
||||||
- ChangeLog.md
|
|
||||||
- LICENSE
|
|
||||||
- README.md
|
|
||||||
- appveyor.yml
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v2
|
|
||||||
- name: fetch tags
|
|
||||||
run: git fetch --unshallow --tags --prune --force
|
|
||||||
- uses: nttld/setup-ndk@v1
|
|
||||||
id: setup-ndk
|
|
||||||
with:
|
|
||||||
ndk-version: r21e
|
|
||||||
add-to-path: true
|
|
||||||
- name: configure
|
|
||||||
env:
|
|
||||||
ANDROID_NDK_HOME: ${{ steps.setup-ndk.outputs.ndk-path }}
|
|
||||||
run: cmake --version && cmake --toolchain "${{ steps.setup-ndk.outputs.ndk-path }}/build/cmake/android.toolchain.cmake"
|
|
||||||
- name: build
|
|
||||||
run: cmake --build .
|
|
||||||
40
.github/workflows/ci.yml
vendored
40
.github/workflows/ci.yml
vendored
@@ -1,40 +0,0 @@
|
|||||||
name: CI
|
|
||||||
|
|
||||||
on:
|
|
||||||
pull_request:
|
|
||||||
push:
|
|
||||||
branches-ignore:
|
|
||||||
- coverity_scan
|
|
||||||
paths-ignore:
|
|
||||||
- '.circleci/**'
|
|
||||||
- '.github/actions/spelling/**'
|
|
||||||
- 'docs/**'
|
|
||||||
- 'packages**'
|
|
||||||
- .cirrus.yml
|
|
||||||
- .clang-format
|
|
||||||
- .gitignore
|
|
||||||
- .travis.yml
|
|
||||||
- AUTHORS
|
|
||||||
- COPYRIGHT
|
|
||||||
- ChangeLog.md
|
|
||||||
- LICENSE
|
|
||||||
- README.md
|
|
||||||
- appveyor.yml
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
runs-on: ${{ matrix.os }}
|
|
||||||
strategy:
|
|
||||||
matrix:
|
|
||||||
#, windows-latest
|
|
||||||
os: [ubuntu-latest, macos-latest, ubuntu-18.04]
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v2
|
|
||||||
- name: fetch tags
|
|
||||||
run: git fetch --unshallow --tags --prune --force
|
|
||||||
- name: make check
|
|
||||||
run: make MDBX_BUILD_OPTIONS="-DNDEBUG=1 -DMDBX_FORCE_ASSERTIONS=1" --keep-going all && MALLOC_CHECK_=7 MALLOC_PERTURB_=42 make MDBX_BUILD_OPTIONS="-DNDEBUG=1 -DMDBX_FORCE_ASSERTIONS=1" --keep-going check
|
|
||||||
shell: bash
|
|
||||||
- name: if_failure
|
|
||||||
if: failure()
|
|
||||||
run: for F in *.err; do echo --- $F; cat $F; done
|
|
||||||
55
.github/workflows/coverity.yml
vendored
55
.github/workflows/coverity.yml
vendored
@@ -1,55 +0,0 @@
|
|||||||
name: Coverity
|
|
||||||
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
branches: coverity_scan
|
|
||||||
paths-ignore:
|
|
||||||
- '.circleci/**'
|
|
||||||
- '.github/actions/spelling/**'
|
|
||||||
- 'docs/**'
|
|
||||||
- 'packages**'
|
|
||||||
- .cirrus.yml
|
|
||||||
- .clang-format
|
|
||||||
- .gitignore
|
|
||||||
- .travis.yml
|
|
||||||
- AUTHORS
|
|
||||||
- COPYRIGHT
|
|
||||||
- ChangeLog.md
|
|
||||||
- LICENSE
|
|
||||||
- README.md
|
|
||||||
- appveyor.yml
|
|
||||||
|
|
||||||
env:
|
|
||||||
COVERITY_SCAN_PROJECT_NAME: 'ReOpen/libmdbx'
|
|
||||||
COVERITY_SCAN_TOKEN: ${{ secrets.COVERITY_SCAN_TOKEN }}
|
|
||||||
COVERITY_SCAN_BUILD_COMMAND: 'make MDBX_BUILD_OPTIONS=-DMDBX_DEBUG=2 CXXSTD=-std=gnu++17 build-test'
|
|
||||||
COVERITY_SCAN_NOTIFICATION_EMAIL: 'leo@yuriev.ru'
|
|
||||||
COVERITY_UNSUPPORTED_COMPILER_INVOCATION: 1
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v2
|
|
||||||
- name: fetch tags
|
|
||||||
run: git fetch --unshallow --tags --prune --force
|
|
||||||
- name: Download Coverity Build Tool
|
|
||||||
run: |
|
|
||||||
wget -q https://scan.coverity.com/download/cxx/linux64 --post-data "token=$COVERITY_SCAN_TOKEN&project=$COVERITY_SCAN_PROJECT_NAME" -O cov-analysis-linux64.tar.gz
|
|
||||||
mkdir cov-analysis-linux64
|
|
||||||
tar xzf cov-analysis-linux64.tar.gz --strip 1 -C cov-analysis-linux64
|
|
||||||
- name: Build with cov-build
|
|
||||||
run: |
|
|
||||||
export PATH=`pwd`/cov-analysis-linux64/bin:$PATH
|
|
||||||
cov-build --dir cov-int $COVERITY_SCAN_BUILD_COMMAND
|
|
||||||
- name: Submit the result to Coverity Scan
|
|
||||||
run: |
|
|
||||||
tar czvf libmdbx.tgz cov-int
|
|
||||||
curl \
|
|
||||||
--form project=$COVERITY_SCAN_PROJECT_NAME \
|
|
||||||
--form token=$COVERITY_SCAN_TOKEN \
|
|
||||||
--form email=$COVERITY_SCAN_NOTIFICATION_EMAIL \
|
|
||||||
--form file=@libmdbx.tgz \
|
|
||||||
--form version=$GITHUB_SHA \
|
|
||||||
--form description="GithubActionCI $GITHUB_ACTION" \
|
|
||||||
https://scan.coverity.com/builds?project=$COVERITY_SCAN_PROJECT_NAME
|
|
||||||
29
.github/workflows/doxygen-github-pages.yml
vendored
29
.github/workflows/doxygen-github-pages.yml
vendored
@@ -1,29 +0,0 @@
|
|||||||
name: doxygen-github-pages
|
|
||||||
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
branches: master
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
runs-on: ubuntu-20.04
|
|
||||||
steps:
|
|
||||||
- name: Set Actions Allow Unsecure Commands (temporary)
|
|
||||||
run: |
|
|
||||||
echo "ACTIONS_ALLOW_UNSECURE_COMMANDS=true" >> $GITHUB_ENV
|
|
||||||
- name: Checkout code
|
|
||||||
uses: actions/checkout@v2.3.1
|
|
||||||
with:
|
|
||||||
fetch-depth: 0
|
|
||||||
- name: Install doxygen
|
|
||||||
run: sudo apt install doxygen graphviz fonts-freefont-ttf
|
|
||||||
- name: Build html docs
|
|
||||||
run: make doxygen && cp -R .circleci docs/html/
|
|
||||||
- name: Deploy gh-pages
|
|
||||||
uses: JamesIves/github-pages-deploy-action@3.5.7
|
|
||||||
with:
|
|
||||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
|
||||||
BRANCH: gh-pages
|
|
||||||
FOLDER: docs/html
|
|
||||||
CLEAN: true
|
|
||||||
SINGLE_COMMIT: true
|
|
||||||
58
.github/workflows/release-assets.yml
vendored
58
.github/workflows/release-assets.yml
vendored
@@ -1,58 +0,0 @@
|
|||||||
# Based on the https://github.com/actions/upload-release-asset example
|
|
||||||
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
# Sequence of patterns matched against refs/tags
|
|
||||||
tags:
|
|
||||||
- 'v*' # Push events to matching v*, i.e. v1.0, v20.15.10
|
|
||||||
|
|
||||||
name: Upload Release Asset
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
name: Upload Release Asset
|
|
||||||
runs-on: ubuntu-20.04
|
|
||||||
steps:
|
|
||||||
- name: Checkout code
|
|
||||||
uses: actions/checkout@v2
|
|
||||||
with:
|
|
||||||
fetch-depth: 0
|
|
||||||
- name: Build assets
|
|
||||||
run: |
|
|
||||||
make release-assets
|
|
||||||
- id: name
|
|
||||||
run: |
|
|
||||||
echo "::set-output name=tarball::$(ls *.tar.gz)"
|
|
||||||
echo "::set-output name=zip::$(ls *.zip)"
|
|
||||||
echo "::set-output name=suffix_unix::$(sed 's|^\([0-9]\{1,\}\.[0-9]\{1,\}\.[0-9]\{1,\}\)\.\(.*\)$|\1|' dist/VERSION.txt)"
|
|
||||||
echo "::set-output name=suffix_dos::$(sed 's|^\([0-9]\{1,\}\.[0-9]\{1,\}\.[0-9]\{1,\}\)\.\(.*\)$|\1|' dist/VERSION.txt | tr . _)"
|
|
||||||
- name: Create Release
|
|
||||||
id: create_release
|
|
||||||
uses: actions/create-release@v1
|
|
||||||
env:
|
|
||||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
|
||||||
with:
|
|
||||||
tag_name: ${{ github.ref }}
|
|
||||||
release_name: Release ${{ github.ref }}
|
|
||||||
draft: true
|
|
||||||
prerelease: true
|
|
||||||
- name: Upload tarball
|
|
||||||
uses: actions/upload-release-asset@v1
|
|
||||||
env:
|
|
||||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
|
||||||
with:
|
|
||||||
upload_url: ${{ steps.create_release.outputs.upload_url }}
|
|
||||||
asset_path: ${{ steps.name.outputs.tarball }}
|
|
||||||
asset_name: libmdbx-amalgamated-${{ steps.name.outputs.suffix_unix }}.tar.gz
|
|
||||||
# asset_label: Amalgamated source tarball
|
|
||||||
asset_content_type: application/tar+gzip
|
|
||||||
- name: Upload zip
|
|
||||||
uses: actions/upload-release-asset@v1
|
|
||||||
env:
|
|
||||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
|
||||||
with:
|
|
||||||
upload_url: ${{ steps.create_release.outputs.upload_url }}
|
|
||||||
asset_path: ${{ steps.name.outputs.zip }}
|
|
||||||
asset_name: libmdbx-amalgamated-${{ steps.name.outputs.suffix_dos }}.zip
|
|
||||||
# asset_label: Amalgamated source zip-archive
|
|
||||||
asset_content_type: application/zip
|
|
||||||
14
.github/workflows/spelling.yml
vendored
14
.github/workflows/spelling.yml
vendored
@@ -1,14 +0,0 @@
|
|||||||
name: Spell checking
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
branches: spelling
|
|
||||||
pull_request:
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
build:
|
|
||||||
runs-on: ubuntu-20.04
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v2
|
|
||||||
with:
|
|
||||||
fetch-depth: 5
|
|
||||||
- uses: check-spelling/check-spelling@main
|
|
||||||
89
.travis.yml
89
.travis.yml
@@ -1,89 +0,0 @@
|
|||||||
language: c cpp
|
|
||||||
sudo: false
|
|
||||||
|
|
||||||
env:
|
|
||||||
global:
|
|
||||||
- secure: "M+W+heGGyRQJoBq2W0uqWVrpL4KBXmL0MFL7FSs7f9vmAaDyEgziUXeZRj3GOKzW4kTef3LpIeiu9SmvqSMoQivGGiomZShqPVl045o/OUgRCAT7Al1RLzEZ0efSHpIPf0PZ6byEf6GR2ML76OfuL6JxTVdnz8iVyO2sgLE1HbX1VeB+wgd/jfMeOBhCCXskfK6MLyZihfMYsiYZYSaV98ZDhDLSlzuuRIgzb0bMi8aL6AErs0WLW0NelRBeHkKPYfAUc85pdQHscgrJw6Rh/zT6+8BQ/q5f4IgWhiu4xoRg3Ngl7SNoedRQh93ADM3UG2iGl6HDFpVORaXcFWKAtuYY+kHQ0HB84BRYpQmeBuXNpltsfxQ3d1Q3u0RlE45zRvmr2+X1mFnkcNUAWISLPbsOUlriDQM8irGwRpho77/uYnRC00bJsHW//s6+uPf9zrAw1nI4f0y3PAWukGF/xs6HAI3FZPsuSSnx18Tj3Opgbc9Spop+V3hkhdiJoPGpNKTkFX4ZRXfkPgoRVJmtp4PpbpH0Ps/mCriKjMEfGGi0HcVCi0pEGLXiecdqJ5KPg5+22zNycEujQBJcNTKd9shN+R3glrbmhAxTEzGdGwxXXJ2ybwJ2PWJLMYZ7g98nLyX+uQPaA3BlsbYJHNeS5283/9pJsd9DzfHKsN2nFSc="
|
|
||||||
|
|
||||||
addons:
|
|
||||||
apt:
|
|
||||||
sources:
|
|
||||||
- ubuntu-toolchain-r-test
|
|
||||||
packages:
|
|
||||||
- cmake
|
|
||||||
- clang-format
|
|
||||||
update: true
|
|
||||||
|
|
||||||
matrix:
|
|
||||||
include:
|
|
||||||
- os: linux
|
|
||||||
dist: focal
|
|
||||||
compiler: gcc
|
|
||||||
env: CC=cc CXX=c++
|
|
||||||
- os: linux
|
|
||||||
dist: focal
|
|
||||||
compiler: clang
|
|
||||||
env: CC=clang CXX=clang++
|
|
||||||
- os: linux
|
|
||||||
dist: bionic
|
|
||||||
compiler: gcc
|
|
||||||
env: CC=cc CXX=c++
|
|
||||||
- os: linux
|
|
||||||
dist: bionic
|
|
||||||
compiler: clang
|
|
||||||
env: CC=clang CXX=clang++
|
|
||||||
- os: linux
|
|
||||||
dist: xenial
|
|
||||||
compiler: gcc
|
|
||||||
env: CC=cc CXX=c++
|
|
||||||
- os: linux
|
|
||||||
dist: xenial
|
|
||||||
compiler: clang
|
|
||||||
env: CC=clang CXX=clang++
|
|
||||||
- os: osx
|
|
||||||
osx_image: xcode11.3
|
|
||||||
env: CC=cc CXX=c++
|
|
||||||
- os: osx
|
|
||||||
osx_image: xcode9.4
|
|
||||||
env: CC=cc CXX=c++
|
|
||||||
|
|
||||||
before_script: |
|
|
||||||
if [ "${TRAVIS_BRANCH}" = "coverity_scan" ]; then
|
|
||||||
# call Coverity Scan manually of addons.coverity_scan for first job only
|
|
||||||
if [ "${TRAVIS_JOB_NUMBER}" = "${TRAVIS_BUILD_NUMBER}.1" ]; then
|
|
||||||
export COVERITY_SCAN_BRANCH=1
|
|
||||||
echo -n | openssl s_client -connect scan.coverity.com:443 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | sudo tee -a /etc/ssl/certs/ca-
|
|
||||||
curl -s 'https://scan.coverity.com/scripts/travisci_build_coverity_scan.sh' -o coverity_scan.sh
|
|
||||||
else
|
|
||||||
echo 'echo "Skip CoverityScan for unrelated os/compiler"' > coverity_scan.sh
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
script: |
|
|
||||||
${CC} --version
|
|
||||||
${CXX} --version
|
|
||||||
git fetch --unshallow --tags --prune --force || exit 1
|
|
||||||
if [ ! -s ./coverity_scan.sh ]; then
|
|
||||||
make --keep-going all && MALLOC_CHECK_=7 MALLOC_PERTURB_=42 make --keep-going check
|
|
||||||
else
|
|
||||||
COVERITY_UNSUPPORTED_COMPILER_INVOCATION=1 \
|
|
||||||
COVERITY_SCAN_PROJECT_NAME="ReOpen/libmdbx" \
|
|
||||||
COVERITY_SCAN_NOTIFICATION_EMAIL="leo@yuriev.ru" \
|
|
||||||
COVERITY_SCAN_BUILD_COMMAND_PREPEND="" \
|
|
||||||
COVERITY_SCAN_BUILD_COMMAND="make MDBX_BUILD_OPTIONS=-DMDBX_DEBUG=2 CXXSTD=-std=gnu++17 build-test" \
|
|
||||||
COVERITY_SCAN_BRANCH_PATTERN="$TRAVIS_BRANCH" \
|
|
||||||
bash ./coverity_scan.sh || cat cov-int/scm_log.txt
|
|
||||||
fi
|
|
||||||
|
|
||||||
after_script: |
|
|
||||||
if [ "${TRAVIS_BRANCH}" != "coverity_scan" -a "${TRAVIS_JOB_NUMBER}" = "${TRAVIS_BUILD_NUMBER}.1" ] && make reformat && [[ -n $(git diff) ]]; then
|
|
||||||
echo "You must run 'make reformat' before submitting a pull request"
|
|
||||||
echo "-------------------------------------------------------------------------------"
|
|
||||||
git diff
|
|
||||||
sleep 1
|
|
||||||
echo "-------------------------------------------------------------------------------"
|
|
||||||
sleep 1
|
|
||||||
exit -1
|
|
||||||
fi
|
|
||||||
echo "-------------------------------------------------------------------------------"
|
|
||||||
sleep 1
|
|
||||||
@@ -14,7 +14,7 @@
|
|||||||
|
|
||||||
##
|
##
|
||||||
## libmdbx = { Revised and extended descendant of Symas LMDB. }
|
## libmdbx = { Revised and extended descendant of Symas LMDB. }
|
||||||
## Please see README.md at https://github.com/erthink/libmdbx
|
## Please see README.md at https://gitflic.ru/project/erthink/libmdbx
|
||||||
##
|
##
|
||||||
## Libmdbx is superior to LMDB in terms of features and reliability,
|
## Libmdbx is superior to LMDB in terms of features and reliability,
|
||||||
## not inferior in performance. libmdbx works on Linux, FreeBSD, MacOS X
|
## not inferior in performance. libmdbx works on Linux, FreeBSD, MacOS X
|
||||||
|
|||||||
172
ChangeLog.md
172
ChangeLog.md
@@ -3,21 +3,33 @@ ChangeLog
|
|||||||
|
|
||||||
### TODO
|
### TODO
|
||||||
|
|
||||||
- [Engage an "overlapped I/O" on Windows](https://github.com/erthink/libmdbx/issues/224).
|
- [Engage an "overlapped I/O" on Windows](todo4recovery://erased_by_github/libmdbx/issues/224).
|
||||||
- [Simple careful mode for working with corrupted DB](https://github.com/erthink/libmdbx/issues/223).
|
- [Simple careful mode for working with corrupted DB](todo4recovery://erased_by_github/libmdbx/issues/223).
|
||||||
- [Move most of `mdbx_chk` functional to the library API](https://github.com/erthink/libmdbx/issues/204).
|
- [Move most of `mdbx_chk` functional to the library API](todo4recovery://erased_by_github/libmdbx/issues/204).
|
||||||
- [Replace SRW-lock on Windows to allow shrink DB with `MDBX_NOTLS` option](https://github.com/erthink/libmdbx/issues/210).
|
- [Replace SRW-lock on Windows to allow shrink DB with `MDBX_NOTLS` option](todo4recovery://erased_by_github/libmdbx/issues/210).
|
||||||
- [More flexible support of asynchronous runtime/framework(s)](https://github.com/erthink/libmdbx/issues/200).
|
- [More flexible support of asynchronous runtime/framework(s)](todo4recovery://erased_by_github/libmdbx/issues/200).
|
||||||
- [Migration guide from LMDB to MDBX](https://github.com/erthink/libmdbx/issues/199).
|
- [Migration guide from LMDB to MDBX](todo4recovery://erased_by_github/libmdbx/issues/199).
|
||||||
- [Get rid of dirty-pages list in MDBX_WRITEMAP mode](https://github.com/erthink/libmdbx/issues/193).
|
- [Get rid of dirty-pages list in MDBX_WRITEMAP mode](todo4recovery://erased_by_github/libmdbx/issues/193).
|
||||||
- [Large/Overflow pages accounting for dirty-room](https://github.com/erthink/libmdbx/issues/192).
|
- [Large/Overflow pages accounting for dirty-room](todo4recovery://erased_by_github/libmdbx/issues/192).
|
||||||
- [Support for RAW devices](https://github.com/erthink/libmdbx/issues/124).
|
- [Support for RAW devices](todo4recovery://erased_by_github/libmdbx/issues/124).
|
||||||
- [Support MessagePack for Keys & Values](https://github.com/erthink/libmdbx/issues/115).
|
- [Support MessagePack for Keys & Values](todo4recovery://erased_by_github/libmdbx/issues/115).
|
||||||
- [Engage new terminology](https://github.com/erthink/libmdbx/issues/137).
|
- [Engage new terminology](todo4recovery://erased_by_github/libmdbx/issues/137).
|
||||||
- Packages for [Astra Linux](https://astralinux.ru/), [ALT Linux](https://www.altlinux.org/), [ROSA Linux](https://www.rosalinux.ru/), etc.
|
- Packages for [Astra Linux](https://astralinux.ru/), [ALT Linux](https://www.altlinux.org/), [ROSA Linux](https://www.rosalinux.ru/), etc.
|
||||||
|
|
||||||
|
|
||||||
## v0.11.7 (underway)
|
## v0.11.7 (scheduled at 2022-04-22)
|
||||||
|
|
||||||
|
The stable risen release after the Github's intentional malicious disaster.
|
||||||
|
|
||||||
|
#### We have migrated to a reliable trusted infrastructure
|
||||||
|
The origin for now is at [GitFlic](https://gitflic.ru/project/erthink/libmdbx)
|
||||||
|
since on 2022-04-15 the Github administration, without any warning nor
|
||||||
|
explanation, deleted _libmdbx_ along with a lot of other projects,
|
||||||
|
simultaneously blocking access for many developers.
|
||||||
|
For the same reason ~~Github~~ is blacklisted forever.
|
||||||
|
|
||||||
|
GitFlic's developers plan to support other languages,
|
||||||
|
including English 和 中文, in the near future.
|
||||||
|
|
||||||
New:
|
New:
|
||||||
|
|
||||||
@@ -25,6 +37,8 @@ New:
|
|||||||
- Support for Microsoft Visual Studio 2022.
|
- Support for Microsoft Visual Studio 2022.
|
||||||
- Support build by MinGW' make from command line without CMake.
|
- Support build by MinGW' make from command line without CMake.
|
||||||
- Added `mdbx::filesystem` C++ API namespace that corresponds to `std::filesystem` or `std::experimental::filesystem`.
|
- Added `mdbx::filesystem` C++ API namespace that corresponds to `std::filesystem` or `std::experimental::filesystem`.
|
||||||
|
- Created [website](https://libmdbx.website.yandexcloud.net/) for online auto-generated documentation.
|
||||||
|
- Used `todo4recovery://erased_by_github/` for dead (or temporarily lost) resources deleted by ~~Github~~.
|
||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
@@ -44,11 +58,11 @@ Minors:
|
|||||||
- Resolved all warnings from MinGW while used without CMake.
|
- Resolved all warnings from MinGW while used without CMake.
|
||||||
|
|
||||||
|
|
||||||
## v0.11.6 (scheduled for 2022-03-24)
|
## v0.11.6 at 2022-03-24
|
||||||
|
|
||||||
The stable release with the complete workaround for an incoherence flaw of Linux unified page/buffer cache.
|
The stable release with the complete workaround for an incoherence flaw of Linux unified page/buffer cache.
|
||||||
Nonetheless the cause for this trouble may be an issue of Intel CPU cache/MESI.
|
Nonetheless the cause for this trouble may be an issue of Intel CPU cache/MESI.
|
||||||
See [issue#269](https://github.com/erthink/libmdbx/issues/269) for more information.
|
See [issue#269](todo4recovery://erased_by_github/libmdbx/issues/269) for more information.
|
||||||
|
|
||||||
Acknowledgements:
|
Acknowledgements:
|
||||||
|
|
||||||
@@ -57,8 +71,8 @@ Acknowledgements:
|
|||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- [Added complete workaround](https://github.com/erthink/libmdbx/issues/269) for an incoherence flaw of Linux unified page/buffer cache.
|
- [Added complete workaround](todo4recovery://erased_by_github/libmdbx/issues/269) for an incoherence flaw of Linux unified page/buffer cache.
|
||||||
- [Fixed](https://github.com/erthink/libmdbx/issues/272) cursor reusing for read-only transactions.
|
- [Fixed](todo4recovery://erased_by_github/libmdbx/issues/272) cursor reusing for read-only transactions.
|
||||||
- Fixed copy&paste typo inside `mdbx::cursor::find_multivalue()`.
|
- Fixed copy&paste typo inside `mdbx::cursor::find_multivalue()`.
|
||||||
|
|
||||||
Minors:
|
Minors:
|
||||||
@@ -73,7 +87,7 @@ Minors:
|
|||||||
## v0.11.5 at 2022-02-23
|
## v0.11.5 at 2022-02-23
|
||||||
|
|
||||||
The release with the temporary hotfix for a flaw of Linux unified page/buffer cache.
|
The release with the temporary hotfix for a flaw of Linux unified page/buffer cache.
|
||||||
See [issue#269](https://github.com/erthink/libmdbx/issues/269) for more information.
|
See [issue#269](todo4recovery://erased_by_github/libmdbx/issues/269) for more information.
|
||||||
|
|
||||||
Acknowledgements:
|
Acknowledgements:
|
||||||
|
|
||||||
@@ -83,10 +97,10 @@ Acknowledgements:
|
|||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- [Added hotfix](https://github.com/erthink/libmdbx/issues/269) for a flaw of Linux unified page/buffer cache.
|
- [Added hotfix](todo4recovery://erased_by_github/libmdbx/issues/269) for a flaw of Linux unified page/buffer cache.
|
||||||
- [Fixed/Reworked](https://github.com/erthink/libmdbx/pull/270) move-assignment operators for "managed" classes of C++ API.
|
- [Fixed/Reworked](todo4recovery://erased_by_github/libmdbx/pull/270) move-assignment operators for "managed" classes of C++ API.
|
||||||
- Fixed potential `SIGSEGV` while open DB with overrided non-default page size.
|
- Fixed potential `SIGSEGV` while open DB with overrided non-default page size.
|
||||||
- [Made](https://github.com/erthink/libmdbx/issues/267) `mdbx_env_open()` idempotence in failure cases.
|
- [Made](todo4recovery://erased_by_github/libmdbx/issues/267) `mdbx_env_open()` idempotence in failure cases.
|
||||||
- Refined/Fixed pages reservation inside `mdbx_update_gc()` to avoid non-reclamation in a rare cases.
|
- Refined/Fixed pages reservation inside `mdbx_update_gc()` to avoid non-reclamation in a rare cases.
|
||||||
- Fixed typo in a retained space calculation for the hsr-callback.
|
- Fixed typo in a retained space calculation for the hsr-callback.
|
||||||
|
|
||||||
@@ -119,15 +133,15 @@ New features, extensions and improvements:
|
|||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- Fixed handling `MDBX_opt_rp_augment_limit` for GC's records from huge transactions (Erigon/Akula/Ethereum).
|
- Fixed handling `MDBX_opt_rp_augment_limit` for GC's records from huge transactions (Erigon/Akula/Ethereum).
|
||||||
- [Fixed](https://github.com/erthink/libmdbx/issues/258) build on Android (avoid including `sys/sem.h`).
|
- [Fixed](todo4recovery://erased_by_github/libmdbx/issues/258) build on Android (avoid including `sys/sem.h`).
|
||||||
- [Fixed](https://github.com/erthink/libmdbx/pull/261) missing copy assignment operator for `mdbx::move_result`.
|
- [Fixed](todo4recovery://erased_by_github/libmdbx/pull/261) missing copy assignment operator for `mdbx::move_result`.
|
||||||
- Fixed missing `&` for `std::ostream &operator<<()` overloads.
|
- Fixed missing `&` for `std::ostream &operator<<()` overloads.
|
||||||
- Fixed unexpected `EXDEV` (Cross-device link) error from `mdbx_env_copy()`.
|
- Fixed unexpected `EXDEV` (Cross-device link) error from `mdbx_env_copy()`.
|
||||||
- Fixed base64 encoding/decoding bugs in auxillary C++ API.
|
- Fixed base64 encoding/decoding bugs in auxillary C++ API.
|
||||||
- Fixed overflow of `pgno_t` during checking PNL on 64-bit platforms.
|
- Fixed overflow of `pgno_t` during checking PNL on 64-bit platforms.
|
||||||
- [Fixed](https://github.com/erthink/libmdbx/issues/260) excessive PNL checking after sort for spilling.
|
- [Fixed](todo4recovery://erased_by_github/libmdbx/issues/260) excessive PNL checking after sort for spilling.
|
||||||
- Reworked checking `MAX_PAGENO` and DB upper-size geometry limit.
|
- Reworked checking `MAX_PAGENO` and DB upper-size geometry limit.
|
||||||
- [Fixed](https://github.com/erthink/libmdbx/issues/265) build for some combinations of versions of MSVC and Windows SDK.
|
- [Fixed](todo4recovery://erased_by_github/libmdbx/issues/265) build for some combinations of versions of MSVC and Windows SDK.
|
||||||
|
|
||||||
Minors:
|
Minors:
|
||||||
|
|
||||||
@@ -154,10 +168,10 @@ Acknowledgements:
|
|||||||
|
|
||||||
New features, extensions and improvements:
|
New features, extensions and improvements:
|
||||||
|
|
||||||
- [Added](https://github.com/erthink/libmdbx/issues/236) `mdbx_cursor_get_batch()`.
|
- [Added](todo4recovery://erased_by_github/libmdbx/issues/236) `mdbx_cursor_get_batch()`.
|
||||||
- [Added](https://github.com/erthink/libmdbx/issues/250) `MDBX_SET_UPPERBOUND`.
|
- [Added](todo4recovery://erased_by_github/libmdbx/issues/250) `MDBX_SET_UPPERBOUND`.
|
||||||
- C++ API is finalized now.
|
- C++ API is finalized now.
|
||||||
- The GC update stage has been [significantly speeded](https://github.com/erthink/libmdbx/issues/254) when fixing huge Erigon's transactions (Ethereum ecosystem).
|
- The GC update stage has been [significantly speeded](todo4recovery://erased_by_github/libmdbx/issues/254) when fixing huge Erigon's transactions (Ethereum ecosystem).
|
||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
@@ -168,12 +182,12 @@ Minors:
|
|||||||
|
|
||||||
- Fixed returning `MDBX_RESULT_TRUE` (unexpected -1) from `mdbx_env_set_option()`.
|
- Fixed returning `MDBX_RESULT_TRUE` (unexpected -1) from `mdbx_env_set_option()`.
|
||||||
- Added `mdbx_env_get_syncbytes()` and `mdbx_env_get_syncperiod()`.
|
- Added `mdbx_env_get_syncbytes()` and `mdbx_env_get_syncperiod()`.
|
||||||
- [Clarified](https://github.com/erthink/libmdbx/pull/249) description of `MDBX_INTEGERKEY`.
|
- [Clarified](todo4recovery://erased_by_github/libmdbx/pull/249) description of `MDBX_INTEGERKEY`.
|
||||||
- Reworked/simplified `mdbx_env_sync_internal()`.
|
- Reworked/simplified `mdbx_env_sync_internal()`.
|
||||||
- [Fixed](https://github.com/erthink/libmdbx/issues/248) extra assertion inside `mdbx_cursor_put()` for `MDBX_DUPFIXED` cases.
|
- [Fixed](todo4recovery://erased_by_github/libmdbx/issues/248) extra assertion inside `mdbx_cursor_put()` for `MDBX_DUPFIXED` cases.
|
||||||
- Avoiding extra looping inside `mdbx_env_info_ex()`.
|
- Avoiding extra looping inside `mdbx_env_info_ex()`.
|
||||||
- Explicitly enabled core dumps from stochastic tests scripts on Linux.
|
- Explicitly enabled core dumps from stochastic tests scripts on Linux.
|
||||||
- [Fixed](https://github.com/erthink/libmdbx/issues/253) `mdbx_override_meta()` to avoid false-positive assertions.
|
- [Fixed](todo4recovery://erased_by_github/libmdbx/issues/253) `mdbx_override_meta()` to avoid false-positive assertions.
|
||||||
- For compatibility reverted returning `MDBX_ENODATA`for some cases.
|
- For compatibility reverted returning `MDBX_ENODATA`for some cases.
|
||||||
|
|
||||||
|
|
||||||
@@ -189,10 +203,10 @@ Acknowledgements:
|
|||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- [Fixed compilation](https://github.com/erthink/libmdbx/pull/239) with `devtoolset-9` on CentOS/RHEL 7.
|
- [Fixed compilation](todo4recovery://erased_by_github/libmdbx/pull/239) with `devtoolset-9` on CentOS/RHEL 7.
|
||||||
- [Fixed unexpected `MDBX_PROBLEM` error](https://github.com/erthink/libmdbx/issues/242) because of update an obsolete meta-page.
|
- [Fixed unexpected `MDBX_PROBLEM` error](todo4recovery://erased_by_github/libmdbx/issues/242) because of update an obsolete meta-page.
|
||||||
- [Fixed returning `MDBX_NOTFOUND` error](https://github.com/erthink/libmdbx/issues/243) in case an inexact value found for `MDBX_GET_BOTH` operation.
|
- [Fixed returning `MDBX_NOTFOUND` error](todo4recovery://erased_by_github/libmdbx/issues/243) in case an inexact value found for `MDBX_GET_BOTH` operation.
|
||||||
- [Fixed compilation](https://github.com/erthink/libmdbx/issues/245) without kernel/libc-devel headers.
|
- [Fixed compilation](todo4recovery://erased_by_github/libmdbx/issues/245) without kernel/libc-devel headers.
|
||||||
|
|
||||||
Minors:
|
Minors:
|
||||||
|
|
||||||
@@ -209,7 +223,7 @@ Minors:
|
|||||||
|
|
||||||
The database format signature has been changed to prevent
|
The database format signature has been changed to prevent
|
||||||
forward-interoperability with an previous releases, which may lead to a
|
forward-interoperability with an previous releases, which may lead to a
|
||||||
[false positive diagnosis of database corruption](https://github.com/erthink/libmdbx/issues/238)
|
[false positive diagnosis of database corruption](todo4recovery://erased_by_github/libmdbx/issues/238)
|
||||||
due to flaws of an old library versions.
|
due to flaws of an old library versions.
|
||||||
|
|
||||||
This change is mostly invisible:
|
This change is mostly invisible:
|
||||||
@@ -258,7 +272,7 @@ Acknowledgements:
|
|||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- Fixed possibility of looping update GC during transaction commit (no public issue since the problem was discovered inside [Positive Technologies](https://www.ptsecurity.ru)).
|
- Fixed possibility of looping update GC during transaction commit (no public issue since the problem was discovered inside [Positive Technologies](https://www.ptsecurity.ru)).
|
||||||
- Fixed `#pragma pack` to avoid provoking some compilers to generate code with [unaligned access](https://github.com/erthink/libmdbx/issues/235).
|
- Fixed `#pragma pack` to avoid provoking some compilers to generate code with [unaligned access](todo4recovery://erased_by_github/libmdbx/issues/235).
|
||||||
- Fixed `noexcept` for potentially throwing `txn::put()` of C++ API.
|
- Fixed `noexcept` for potentially throwing `txn::put()` of C++ API.
|
||||||
|
|
||||||
Minors:
|
Minors:
|
||||||
@@ -284,7 +298,7 @@ Extensions and improvements:
|
|||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- Always setup `madvise` while opening DB (fixes https://github.com/erthink/libmdbx/issues/231).
|
- Always setup `madvise` while opening DB (fixes todo4recovery://erased_by_github/libmdbx/issues/231).
|
||||||
- Fixed checking legacy `P_DIRTY` flag (`0x10`) for nested/sub-pages.
|
- Fixed checking legacy `P_DIRTY` flag (`0x10`) for nested/sub-pages.
|
||||||
|
|
||||||
Minors:
|
Minors:
|
||||||
@@ -305,11 +319,11 @@ Acknowledgements:
|
|||||||
- [Lionel Debroux](https://github.com/debrouxl) for fuzzing tests and reporting bugs.
|
- [Lionel Debroux](https://github.com/debrouxl) for fuzzing tests and reporting bugs.
|
||||||
- [Sergey Fedotov](https://github.com/SergeyFromHell/) for [`node-mdbx` NodeJS bindings](https://www.npmjs.com/package/node-mdbx).
|
- [Sergey Fedotov](https://github.com/SergeyFromHell/) for [`node-mdbx` NodeJS bindings](https://www.npmjs.com/package/node-mdbx).
|
||||||
- [Kris Zyp](https://github.com/kriszyp) for [`lmdbx-store` NodeJS bindings](https://github.com/kriszyp/lmdbx-store).
|
- [Kris Zyp](https://github.com/kriszyp) for [`lmdbx-store` NodeJS bindings](https://github.com/kriszyp/lmdbx-store).
|
||||||
- [Noel Kuntze](https://github.com/Thermi) for [draft Python bindings](https://github.com/erthink/libmdbx/commits/python-bindings).
|
- [Noel Kuntze](https://github.com/Thermi) for [draft Python bindings](todo4recovery://erased_by_github/libmdbx/commits/python-bindings).
|
||||||
|
|
||||||
New features, extensions and improvements:
|
New features, extensions and improvements:
|
||||||
|
|
||||||
- [Allow to predefine/override `MDBX_BUILD_TIMESTAMP` for builds reproducibility](https://github.com/erthink/libmdbx/issues/201).
|
- [Allow to predefine/override `MDBX_BUILD_TIMESTAMP` for builds reproducibility](todo4recovery://erased_by_github/libmdbx/issues/201).
|
||||||
- Added options support for `long-stochastic` script.
|
- Added options support for `long-stochastic` script.
|
||||||
- Avoided `MDBX_TXN_FULL` error for large transactions when possible.
|
- Avoided `MDBX_TXN_FULL` error for large transactions when possible.
|
||||||
- The `MDBX_READERS_LIMIT` increased to `32767`.
|
- The `MDBX_READERS_LIMIT` increased to `32767`.
|
||||||
@@ -317,7 +331,7 @@ New features, extensions and improvements:
|
|||||||
- Minimized the size of poisoned/unpoisoned regions to avoid Valgrind/ASAN stuck.
|
- Minimized the size of poisoned/unpoisoned regions to avoid Valgrind/ASAN stuck.
|
||||||
- Added more workarounds for QEMU for testing builds for 32-bit platforms, Alpha and Sparc architectures.
|
- Added more workarounds for QEMU for testing builds for 32-bit platforms, Alpha and Sparc architectures.
|
||||||
- `mdbx_chk` now skips iteration & checking of DB' records if corresponding page-tree is corrupted (to avoid `SIGSEGV`, ASAN failures, etc).
|
- `mdbx_chk` now skips iteration & checking of DB' records if corresponding page-tree is corrupted (to avoid `SIGSEGV`, ASAN failures, etc).
|
||||||
- Added more checks for [rare/fuzzing corruption cases](https://github.com/erthink/libmdbx/issues/217).
|
- Added more checks for [rare/fuzzing corruption cases](todo4recovery://erased_by_github/libmdbx/issues/217).
|
||||||
|
|
||||||
Backward compatibility break:
|
Backward compatibility break:
|
||||||
|
|
||||||
@@ -329,18 +343,18 @@ Backward compatibility break:
|
|||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- Fixed excess meta-pages checks in case `mdbx_chk` is called to check the DB for a specific meta page and thus could prevent switching to the selected meta page, even if the check passed without errors.
|
- Fixed excess meta-pages checks in case `mdbx_chk` is called to check the DB for a specific meta page and thus could prevent switching to the selected meta page, even if the check passed without errors.
|
||||||
- Fixed [recursive use of SRW-lock on Windows cause by `MDBX_NOTLS` option](https://github.com/erthink/libmdbx/issues/203).
|
- Fixed [recursive use of SRW-lock on Windows cause by `MDBX_NOTLS` option](todo4recovery://erased_by_github/libmdbx/issues/203).
|
||||||
- Fixed [log a warning during a new DB creation](https://github.com/erthink/libmdbx/issues/205).
|
- Fixed [log a warning during a new DB creation](todo4recovery://erased_by_github/libmdbx/issues/205).
|
||||||
- Fixed [false-negative `mdbx_cursor_eof()` result](https://github.com/erthink/libmdbx/issues/207).
|
- Fixed [false-negative `mdbx_cursor_eof()` result](todo4recovery://erased_by_github/libmdbx/issues/207).
|
||||||
- Fixed [`make install` with non-GNU `install` utility (OSX, BSD)](https://github.com/erthink/libmdbx/issues/208).
|
- Fixed [`make install` with non-GNU `install` utility (OSX, BSD)](todo4recovery://erased_by_github/libmdbx/issues/208).
|
||||||
- Fixed [installation by `CMake` in special cases by complete use `GNUInstallDirs`'s variables](https://github.com/erthink/libmdbx/issues/209).
|
- Fixed [installation by `CMake` in special cases by complete use `GNUInstallDirs`'s variables](todo4recovery://erased_by_github/libmdbx/issues/209).
|
||||||
- Fixed [C++ Buffer issue with `std::string` and alignment](https://github.com/erthink/libmdbx/issues/191).
|
- Fixed [C++ Buffer issue with `std::string` and alignment](todo4recovery://erased_by_github/libmdbx/issues/191).
|
||||||
- Fixed `safe64_reset()` for platforms without atomic 64-bit compare-and-swap.
|
- Fixed `safe64_reset()` for platforms without atomic 64-bit compare-and-swap.
|
||||||
- Fixed hang/shutdown on big-endian platforms without `__cxa_thread_atexit()`.
|
- Fixed hang/shutdown on big-endian platforms without `__cxa_thread_atexit()`.
|
||||||
- Fixed [using bad meta-pages if DB was partially/recoverable corrupted](https://github.com/erthink/libmdbx/issues/217).
|
- Fixed [using bad meta-pages if DB was partially/recoverable corrupted](todo4recovery://erased_by_github/libmdbx/issues/217).
|
||||||
- Fixed extra `noexcept` for `buffer::&assign_reference()`.
|
- Fixed extra `noexcept` for `buffer::&assign_reference()`.
|
||||||
- Fixed `bootid` generation on Windows for case of change system' time.
|
- Fixed `bootid` generation on Windows for case of change system' time.
|
||||||
- Fixed [test framework keygen-related issue](https://github.com/erthink/libmdbx/issues/127).
|
- Fixed [test framework keygen-related issue](todo4recovery://erased_by_github/libmdbx/issues/127).
|
||||||
|
|
||||||
|
|
||||||
## v0.10.1 at 2021-06-01
|
## v0.10.1 at 2021-06-01
|
||||||
@@ -361,10 +375,10 @@ New features:
|
|||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- Fixed minor "foo not used" warnings from modern C++ compilers when building the C++ part of the library.
|
- Fixed minor "foo not used" warnings from modern C++ compilers when building the C++ part of the library.
|
||||||
- Fixed confusing/messy errors when build library from unfit github's archives (https://github.com/erthink/libmdbx/issues/197).
|
- Fixed confusing/messy errors when build library from unfit github's archives (todo4recovery://erased_by_github/libmdbx/issues/197).
|
||||||
- Fixed `#elsif` typo.
|
- Fixed `#elsif` typo.
|
||||||
- Fixed rare unexpected `MDBX_PROBLEM` error during altering data in huge transactions due to wrong spilling/oust of dirty pages (https://github.com/erthink/libmdbx/issues/195).
|
- Fixed rare unexpected `MDBX_PROBLEM` error during altering data in huge transactions due to wrong spilling/oust of dirty pages (todo4recovery://erased_by_github/libmdbx/issues/195).
|
||||||
- Re-Fixed WSL1/WSL2 detection with distinguishing (https://github.com/erthink/libmdbx/issues/97).
|
- Re-Fixed WSL1/WSL2 detection with distinguishing (todo4recovery://erased_by_github/libmdbx/issues/97).
|
||||||
|
|
||||||
|
|
||||||
## v0.10.0 at 2021-05-09
|
## v0.10.0 at 2021-05-09
|
||||||
@@ -387,7 +401,7 @@ New features:
|
|||||||
and conjointly with the `MDBX_ENV_CHECKPID=0` and `MDBX_TXN_CHECKOWNER=0` options can yield
|
and conjointly with the `MDBX_ENV_CHECKPID=0` and `MDBX_TXN_CHECKOWNER=0` options can yield
|
||||||
up to 30% more performance compared to LMDB.
|
up to 30% more performance compared to LMDB.
|
||||||
- Using float point (exponential quantized) representation for internal 16-bit values
|
- Using float point (exponential quantized) representation for internal 16-bit values
|
||||||
of grow step and shrink threshold when huge ones (https://github.com/erthink/libmdbx/issues/166).
|
of grow step and shrink threshold when huge ones (todo4recovery://erased_by_github/libmdbx/issues/166).
|
||||||
To minimize the impact on compatibility, only the odd values inside the upper half
|
To minimize the impact on compatibility, only the odd values inside the upper half
|
||||||
of the range (i.e. 32769..65533) are used for the new representation.
|
of the range (i.e. 32769..65533) are used for the new representation.
|
||||||
- Added the `mdbx_drop` similar to LMDB command-line tool to purge or delete (sub)database(s).
|
- Added the `mdbx_drop` similar to LMDB command-line tool to purge or delete (sub)database(s).
|
||||||
@@ -396,7 +410,7 @@ New features:
|
|||||||
- The internal node sizes were refined, resulting in a reduction in large/overflow pages in some use cases
|
- The internal node sizes were refined, resulting in a reduction in large/overflow pages in some use cases
|
||||||
and a slight increase in limits for a keys size to ≈½ of page size.
|
and a slight increase in limits for a keys size to ≈½ of page size.
|
||||||
- Added to `mdbx_chk` output number of keys/items on pages.
|
- Added to `mdbx_chk` output number of keys/items on pages.
|
||||||
- Added explicit `install-strip` and `install-no-strip` targets to the `Makefile` (https://github.com/erthink/libmdbx/pull/180).
|
- Added explicit `install-strip` and `install-no-strip` targets to the `Makefile` (todo4recovery://erased_by_github/libmdbx/pull/180).
|
||||||
- Major rework page splitting (af9b7b560505684249b76730997f9e00614b8113) for
|
- Major rework page splitting (af9b7b560505684249b76730997f9e00614b8113) for
|
||||||
- An "auto-appending" feature upon insertion for both ascending and
|
- An "auto-appending" feature upon insertion for both ascending and
|
||||||
descending key sequences. As a result, the optimality of page filling
|
descending key sequences. As a result, the optimality of page filling
|
||||||
@@ -404,7 +418,7 @@ New features:
|
|||||||
inserting ordered sequences of keys,
|
inserting ordered sequences of keys,
|
||||||
- A "splitting at middle" to make page tree more balanced on average.
|
- A "splitting at middle" to make page tree more balanced on average.
|
||||||
- Added `mdbx_get_sysraminfo()` to the API.
|
- Added `mdbx_get_sysraminfo()` to the API.
|
||||||
- Added guessing a reasonable maximum DB size for the default upper limit of geometry (https://github.com/erthink/libmdbx/issues/183).
|
- Added guessing a reasonable maximum DB size for the default upper limit of geometry (todo4recovery://erased_by_github/libmdbx/issues/183).
|
||||||
- Major rework internal labeling of a dirty pages (958fd5b9479f52f2124ab7e83c6b18b04b0e7dda) for
|
- Major rework internal labeling of a dirty pages (958fd5b9479f52f2124ab7e83c6b18b04b0e7dda) for
|
||||||
a "transparent spilling" feature with the gist to make a dirty pages
|
a "transparent spilling" feature with the gist to make a dirty pages
|
||||||
be ready to spilling (writing to a disk) without further altering ones.
|
be ready to spilling (writing to a disk) without further altering ones.
|
||||||
@@ -420,7 +434,7 @@ New features:
|
|||||||
- Support `make help` to list available make targets.
|
- Support `make help` to list available make targets.
|
||||||
- Silently `make`'s build by default.
|
- Silently `make`'s build by default.
|
||||||
- Preliminary [Python bindings](https://github.com/Thermi/libmdbx/tree/python-bindings) is available now
|
- Preliminary [Python bindings](https://github.com/Thermi/libmdbx/tree/python-bindings) is available now
|
||||||
by [Noel Kuntze](https://github.com/Thermi) (https://github.com/erthink/libmdbx/issues/147).
|
by [Noel Kuntze](https://github.com/Thermi) (todo4recovery://erased_by_github/libmdbx/issues/147).
|
||||||
|
|
||||||
Backward compatibility break:
|
Backward compatibility break:
|
||||||
|
|
||||||
@@ -435,22 +449,22 @@ Backward compatibility break:
|
|||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- Fixed performance regression due non-optimal C11 atomics usage (https://github.com/erthink/libmdbx/issues/160).
|
- Fixed performance regression due non-optimal C11 atomics usage (todo4recovery://erased_by_github/libmdbx/issues/160).
|
||||||
- Fixed "reincarnation" of subDB after it deletion (https://github.com/erthink/libmdbx/issues/168).
|
- Fixed "reincarnation" of subDB after it deletion (todo4recovery://erased_by_github/libmdbx/issues/168).
|
||||||
- Fixed (disallowing) implicit subDB deletion via operations on `@MAIN`'s DBI-handle.
|
- Fixed (disallowing) implicit subDB deletion via operations on `@MAIN`'s DBI-handle.
|
||||||
- Fixed a crash of `mdbx_env_info_ex()` in case of a call for a non-open environment (https://github.com/erthink/libmdbx/issues/171).
|
- Fixed a crash of `mdbx_env_info_ex()` in case of a call for a non-open environment (todo4recovery://erased_by_github/libmdbx/issues/171).
|
||||||
- Fixed the selecting/adjustment values inside `mdbx_env_set_geometry()` for implicit out-of-range cases (https://github.com/erthink/libmdbx/issues/170).
|
- Fixed the selecting/adjustment values inside `mdbx_env_set_geometry()` for implicit out-of-range cases (todo4recovery://erased_by_github/libmdbx/issues/170).
|
||||||
- Fixed `mdbx_env_set_option()` for set initial and limit size of dirty page list ((https://github.com/erthink/libmdbx/issues/179).
|
- Fixed `mdbx_env_set_option()` for set initial and limit size of dirty page list ((todo4recovery://erased_by_github/libmdbx/issues/179).
|
||||||
- Fixed an unreasonably huge default upper limit for DB geometry (https://github.com/erthink/libmdbx/issues/183).
|
- Fixed an unreasonably huge default upper limit for DB geometry (todo4recovery://erased_by_github/libmdbx/issues/183).
|
||||||
- Fixed `constexpr` specifier for the `slice::invalid()`.
|
- Fixed `constexpr` specifier for the `slice::invalid()`.
|
||||||
- Fixed (no)readahead auto-handling (https://github.com/erthink/libmdbx/issues/164).
|
- Fixed (no)readahead auto-handling (todo4recovery://erased_by_github/libmdbx/issues/164).
|
||||||
- Fixed non-alloy build for Windows.
|
- Fixed non-alloy build for Windows.
|
||||||
- Switched to using Heap-functions instead of LocalAlloc/LocalFree on Windows.
|
- Switched to using Heap-functions instead of LocalAlloc/LocalFree on Windows.
|
||||||
- Fixed `mdbx_env_stat_ex()` to returning statistics of the whole environment instead of MainDB only (https://github.com/erthink/libmdbx/issues/190).
|
- Fixed `mdbx_env_stat_ex()` to returning statistics of the whole environment instead of MainDB only (todo4recovery://erased_by_github/libmdbx/issues/190).
|
||||||
- Fixed building by GCC 4.8.5 (added workaround for a preprocessor's bug).
|
- Fixed building by GCC 4.8.5 (added workaround for a preprocessor's bug).
|
||||||
- Fixed building C++ part for iOS <= 13.0 (unavailability of `std::filesystem::path`).
|
- Fixed building C++ part for iOS <= 13.0 (unavailability of `std::filesystem::path`).
|
||||||
- Fixed building for Windows target versions prior to Windows Vista (`WIN32_WINNT < 0x0600`).
|
- Fixed building for Windows target versions prior to Windows Vista (`WIN32_WINNT < 0x0600`).
|
||||||
- Fixed building by MinGW for Windows (https://github.com/erthink/libmdbx/issues/155).
|
- Fixed building by MinGW for Windows (todo4recovery://erased_by_github/libmdbx/issues/155).
|
||||||
|
|
||||||
|
|
||||||
## v0.9.3 at 2021-02-02
|
## v0.9.3 at 2021-02-02
|
||||||
@@ -470,7 +484,7 @@ Removed options and features:
|
|||||||
New features:
|
New features:
|
||||||
|
|
||||||
- Package for FreeBSD is available now by Mahlon E. Smith.
|
- Package for FreeBSD is available now by Mahlon E. Smith.
|
||||||
- New API functions to get/set various options (https://github.com/erthink/libmdbx/issues/128):
|
- New API functions to get/set various options (todo4recovery://erased_by_github/libmdbx/issues/128):
|
||||||
- the maximum number of named databases for the environment;
|
- the maximum number of named databases for the environment;
|
||||||
- the maximum number of threads/reader slots;
|
- the maximum number of threads/reader slots;
|
||||||
- threshold (since the last unsteady commit) to force flush the data buffers to disk;
|
- threshold (since the last unsteady commit) to force flush the data buffers to disk;
|
||||||
@@ -483,7 +497,7 @@ New features:
|
|||||||
- maximal part of the dirty pages may be spilled when necessary;
|
- maximal part of the dirty pages may be spilled when necessary;
|
||||||
- minimal part of the dirty pages should be spilled when necessary;
|
- minimal part of the dirty pages should be spilled when necessary;
|
||||||
- how much of the parent transaction dirty pages will be spilled while start each child transaction;
|
- how much of the parent transaction dirty pages will be spilled while start each child transaction;
|
||||||
- Unlimited/Dynamic size of retired and dirty page lists (https://github.com/erthink/libmdbx/issues/123).
|
- Unlimited/Dynamic size of retired and dirty page lists (todo4recovery://erased_by_github/libmdbx/issues/123).
|
||||||
- Added `-p` option (purge subDB before loading) to `mdbx_load` tool.
|
- Added `-p` option (purge subDB before loading) to `mdbx_load` tool.
|
||||||
- Reworked spilling of large transaction and committing of nested transactions:
|
- Reworked spilling of large transaction and committing of nested transactions:
|
||||||
- page spilling code reworked to avoid the flaws and bugs inherited from LMDB;
|
- page spilling code reworked to avoid the flaws and bugs inherited from LMDB;
|
||||||
@@ -493,22 +507,22 @@ New features:
|
|||||||
- Added `MDBX_ENABLE_REFUND` and `MDBX_PNL_ASCENDING` internal/advanced build options.
|
- Added `MDBX_ENABLE_REFUND` and `MDBX_PNL_ASCENDING` internal/advanced build options.
|
||||||
- Added `mdbx_default_pagesize()` function.
|
- Added `mdbx_default_pagesize()` function.
|
||||||
- Better support architectures with a weak/relaxed memory consistency model (ARM, AARCH64, PPC, MIPS, RISC-V, etc) by means [C11 atomics](https://en.cppreference.com/w/c/atomic).
|
- Better support architectures with a weak/relaxed memory consistency model (ARM, AARCH64, PPC, MIPS, RISC-V, etc) by means [C11 atomics](https://en.cppreference.com/w/c/atomic).
|
||||||
- Speed up page number lists and dirty page lists (https://github.com/erthink/libmdbx/issues/132).
|
- Speed up page number lists and dirty page lists (todo4recovery://erased_by_github/libmdbx/issues/132).
|
||||||
- Added `LIBMDBX_NO_EXPORTS_LEGACY_API` build option.
|
- Added `LIBMDBX_NO_EXPORTS_LEGACY_API` build option.
|
||||||
|
|
||||||
Fixes:
|
Fixes:
|
||||||
|
|
||||||
- Fixed missing cleanup (null assigned) in the C++ commit/abort (https://github.com/erthink/libmdbx/pull/143).
|
- Fixed missing cleanup (null assigned) in the C++ commit/abort (todo4recovery://erased_by_github/libmdbx/pull/143).
|
||||||
- Fixed `mdbx_realloc()` for case of nullptr and `MDBX_WITHOUT_MSVC_CRT=ON` for Windows.
|
- Fixed `mdbx_realloc()` for case of nullptr and `MDBX_WITHOUT_MSVC_CRT=ON` for Windows.
|
||||||
- Fixed the possibility to use invalid and renewed (closed & re-opened, dropped & re-created) DBI-handles (https://github.com/erthink/libmdbx/issues/146).
|
- Fixed the possibility to use invalid and renewed (closed & re-opened, dropped & re-created) DBI-handles (todo4recovery://erased_by_github/libmdbx/issues/146).
|
||||||
- Fixed 4-byte aligned access to 64-bit integers, including access to the `bootid` meta-page's field (https://github.com/erthink/libmdbx/issues/153).
|
- Fixed 4-byte aligned access to 64-bit integers, including access to the `bootid` meta-page's field (todo4recovery://erased_by_github/libmdbx/issues/153).
|
||||||
- Fixed minor/potential memory leak during page flushing and unspilling.
|
- Fixed minor/potential memory leak during page flushing and unspilling.
|
||||||
- Fixed handling states of cursors's and subDBs's for nested transactions.
|
- Fixed handling states of cursors's and subDBs's for nested transactions.
|
||||||
- Fixed page leak in extra rare case the list of retired pages changed during update GC on transaction commit.
|
- Fixed page leak in extra rare case the list of retired pages changed during update GC on transaction commit.
|
||||||
- Fixed assertions to avoid false-positive UB detection by CLANG/LLVM (https://github.com/erthink/libmdbx/issues/153).
|
- Fixed assertions to avoid false-positive UB detection by CLANG/LLVM (todo4recovery://erased_by_github/libmdbx/issues/153).
|
||||||
- Fixed `MDBX_TXN_FULL` and regressive `MDBX_KEYEXIST` during large transaction commit with `MDBX_LIFORECLAIM` (https://github.com/erthink/libmdbx/issues/123).
|
- Fixed `MDBX_TXN_FULL` and regressive `MDBX_KEYEXIST` during large transaction commit with `MDBX_LIFORECLAIM` (todo4recovery://erased_by_github/libmdbx/issues/123).
|
||||||
- Fixed auto-recovery (`weak->steady` with the same boot-id) when Database size at last weak checkpoint is large than at last steady checkpoint.
|
- Fixed auto-recovery (`weak->steady` with the same boot-id) when Database size at last weak checkpoint is large than at last steady checkpoint.
|
||||||
- Fixed operation on systems with unusual small/large page size, including PowerPC (https://github.com/erthink/libmdbx/issues/157).
|
- Fixed operation on systems with unusual small/large page size, including PowerPC (todo4recovery://erased_by_github/libmdbx/issues/157).
|
||||||
|
|
||||||
|
|
||||||
## v0.9.2 at 2020-11-27
|
## v0.9.2 at 2020-11-27
|
||||||
@@ -546,11 +560,11 @@ Fixes:
|
|||||||
- Fixed copy&paste typos.
|
- Fixed copy&paste typos.
|
||||||
- Fixed minor false-positive GCC warning.
|
- Fixed minor false-positive GCC warning.
|
||||||
- Added workaround for broken `DEFINE_ENUM_FLAG_OPERATORS` from Windows SDK.
|
- Added workaround for broken `DEFINE_ENUM_FLAG_OPERATORS` from Windows SDK.
|
||||||
- Fixed cursor state after multimap/dupsort repeated deletes (https://github.com/erthink/libmdbx/issues/121).
|
- Fixed cursor state after multimap/dupsort repeated deletes (todo4recovery://erased_by_github/libmdbx/issues/121).
|
||||||
- Added `SIGPIPE` suppression for internal thread during `mdbx_env_copy()`.
|
- Added `SIGPIPE` suppression for internal thread during `mdbx_env_copy()`.
|
||||||
- Fixed extra-rare `MDBX_KEY_EXIST` error during `mdbx_commit()` (https://github.com/erthink/libmdbx/issues/131).
|
- Fixed extra-rare `MDBX_KEY_EXIST` error during `mdbx_commit()` (todo4recovery://erased_by_github/libmdbx/issues/131).
|
||||||
- Fixed spilled pages checking (https://github.com/erthink/libmdbx/issues/126).
|
- Fixed spilled pages checking (todo4recovery://erased_by_github/libmdbx/issues/126).
|
||||||
- Fixed `mdbx_load` for 'plain text' and without `-s name` cases (https://github.com/erthink/libmdbx/issues/136).
|
- Fixed `mdbx_load` for 'plain text' and without `-s name` cases (todo4recovery://erased_by_github/libmdbx/issues/136).
|
||||||
- Fixed save/restore/commit of cursors for nested transactions.
|
- Fixed save/restore/commit of cursors for nested transactions.
|
||||||
- Fixed cursors state in rare/special cases (move next beyond end-of-data, after deletion and so on).
|
- Fixed cursors state in rare/special cases (move next beyond end-of-data, after deletion and so on).
|
||||||
- Added workaround for MSVC 19.28 (Visual Studio 16.8) (but may still hang during compilation).
|
- Added workaround for MSVC 19.28 (Visual Studio 16.8) (but may still hang during compilation).
|
||||||
@@ -566,7 +580,7 @@ Fixes:
|
|||||||
Added features:
|
Added features:
|
||||||
|
|
||||||
- Preliminary C++ API with support for C++17 polymorphic allocators.
|
- Preliminary C++ API with support for C++17 polymorphic allocators.
|
||||||
- [Online C++ API reference](https://erthink.github.io/libmdbx/) by Doxygen.
|
- [Online C++ API reference](https://erased_by_github_and_to_be_restored.todo/libmdbx/) by Doxygen.
|
||||||
- Quick reference for Insert/Update/Delete operations.
|
- Quick reference for Insert/Update/Delete operations.
|
||||||
- Explicit `MDBX_SYNC_DURABLE` to sync modes for API clarity.
|
- Explicit `MDBX_SYNC_DURABLE` to sync modes for API clarity.
|
||||||
- Explicit `MDBX_ALLDUPS` and `MDBX_UPSERT` for API clarity.
|
- Explicit `MDBX_ALLDUPS` and `MDBX_UPSERT` for API clarity.
|
||||||
@@ -611,7 +625,7 @@ Fixes:
|
|||||||
|
|
||||||
Added features:
|
Added features:
|
||||||
|
|
||||||
- [Online C API reference](https://erthink.github.io/libmdbx/) by Doxygen.
|
- [Online C API reference](https://erased_by_github_and_to_be_restored.todo/libmdbx/) by Doxygen.
|
||||||
- Separated enums for environment, sub-databases, transactions, copying and data-update flags.
|
- Separated enums for environment, sub-databases, transactions, copying and data-update flags.
|
||||||
|
|
||||||
Deprecated functions and flags:
|
Deprecated functions and flags:
|
||||||
|
|||||||
191
README.md
191
README.md
@@ -1,35 +1,46 @@
|
|||||||
<!-- Required extensions: pymdownx.betterem, pymdownx.tilde, pymdownx.emoji, pymdownx.tasklist, pymdownx.superfences -->
|
<!-- Required extensions: pymdownx.betterem, pymdownx.tilde, pymdownx.emoji, pymdownx.tasklist, pymdownx.superfences -->
|
||||||
|
|
||||||
|
### The origin has been migrated to [GitFlic](https://gitflic.ru/project/erthink/libmdbx)
|
||||||
|
since on 2022-04-15 the Github administration, without any warning
|
||||||
|
nor explanation, deleted _libmdbx_ along with a lot of other projects,
|
||||||
|
simultaneously blocking access for many developers.
|
||||||
|
For the same reason ~~Github~~ is blacklisted forever.
|
||||||
|
|
||||||
|
GitFlic's developers plan to support other languages,
|
||||||
|
including English 和 中文, in the near future.
|
||||||
|
|
||||||
|
### Основной репозиторий перемещен на [GitFlic](https://gitflic.ru/project/erthink/libmdbx)
|
||||||
|
так как 15 апреля 2022 администрация Github без предупреждения и
|
||||||
|
объяснения причин удалила _libmdbx_ вместе с массой других проектов,
|
||||||
|
одновременно заблокировав доступ многим разработчикам.
|
||||||
|
По этой же причине ~~Github~~ навсегда занесен в черный список.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
*The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо.*
|
*The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо.*
|
||||||
|
|
||||||
> Please refer to the online [documentation](https://erthink.github.io/libmdbx/)
|
> Please refer to the online [documentation](https://libmdbx.website.yandexcloud.net)
|
||||||
> with [`C` API description](https://erthink.github.io/libmdbx/group__c__api.html)
|
> with [`C` API description](https://libmdbx.website.yandexcloud.net/group__c__api.html)
|
||||||
> and pay attention to the [`C++` API](https://github.com/erthink/libmdbx/blob/devel/mdbx.h%2B%2B).
|
> and pay attention to the [`C++` API](https://gitflic.ru/project/erthink/libmdbx/blob?file=mdbx.h%2B%2B#line-num-1).
|
||||||
|
|
||||||
> Questions, feedback and suggestions are welcome to the [Telegram' group](https://t.me/libmdbx).
|
> Questions, feedback and suggestions are welcome to the [Telegram' group](https://t.me/libmdbx).
|
||||||
|
|
||||||
> For NEWS take a look to the [ChangeLog](./ChangeLog.md).
|
> For NEWS take a look to the [ChangeLog](https://gitflic.ru/project/erthink/libmdbx/blob?file=ChangeLog.md).
|
||||||
|
|
||||||
[](https://t.me/libmdbx)
|
|
||||||
[](https://github.com/erthink/libmdbx/releases)
|
|
||||||
[](https://github.com/erthink/libmdbx/actions?query=workflow%3ACI)
|
|
||||||
[](https://ci.appveyor.com/project/leo-yuriev/libmdbx/branch/master)
|
|
||||||
[](https://circleci.com/gh/erthink/libmdbx/tree/master)
|
|
||||||
[](https://cirrus-ci.com/github/erthink/libmdbx)
|
|
||||||
[](https://scan.coverity.com/projects/reopen-libmdbx)
|
|
||||||
|
|
||||||
libmdbx
|
libmdbx
|
||||||
========
|
========
|
||||||
|
|
||||||
<!-- section-begin overview -->
|
<!-- section-begin overview -->
|
||||||
_libmdbx_ is an extremely fast, compact, powerful, embedded,
|
|
||||||
transactional [key-value database](https://en.wikipedia.org/wiki/Key-value_database),
|
_libmdbx_ is an extremely fast, compact, powerful, embedded, transactional
|
||||||
with [permissive license](./LICENSE).
|
[key-value database](https://en.wikipedia.org/wiki/Key-value_database),
|
||||||
|
with [permissive license](https://gitflic.ru/project/erthink/libmdbx/blob?file=LICENSE).
|
||||||
_libmdbx_ has a specific set of properties and capabilities,
|
_libmdbx_ has a specific set of properties and capabilities,
|
||||||
focused on creating unique lightweight solutions.
|
focused on creating unique lightweight solutions.
|
||||||
|
|
||||||
1. Allows **a swarm of multi-threaded processes to
|
1. Allows **a swarm of multi-threaded processes to
|
||||||
[ACID]((https://en.wikipedia.org/wiki/ACID))ly read and update** several
|
[ACID](https://en.wikipedia.org/wiki/ACID)ly read and update** several
|
||||||
key-value [maps](https://en.wikipedia.org/wiki/Associative_array) and
|
key-value [maps](https://en.wikipedia.org/wiki/Associative_array) and
|
||||||
[multimaps](https://en.wikipedia.org/wiki/Multimap) in a locally-shared
|
[multimaps](https://en.wikipedia.org/wiki/Multimap) in a locally-shared
|
||||||
database.
|
database.
|
||||||
@@ -62,6 +73,7 @@ neglected in favour of write performance.
|
|||||||
7. Supports Linux, Windows, MacOS, Android, iOS, FreeBSD, DragonFly, Solaris,
|
7. Supports Linux, Windows, MacOS, Android, iOS, FreeBSD, DragonFly, Solaris,
|
||||||
OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with
|
OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with
|
||||||
**POSIX.1-2008**.
|
**POSIX.1-2008**.
|
||||||
|
|
||||||
<!-- section-end -->
|
<!-- section-end -->
|
||||||
|
|
||||||
Historically, _libmdbx_ is a deeply revised and extended descendant of the amazing
|
Historically, _libmdbx_ is a deeply revised and extended descendant of the amazing
|
||||||
@@ -69,16 +81,19 @@ Historically, _libmdbx_ is a deeply revised and extended descendant of the amazi
|
|||||||
_libmdbx_ inherits all benefits from _LMDB_, but resolves some issues and adds [a set of improvements](#improvements-beyond-lmdb).
|
_libmdbx_ inherits all benefits from _LMDB_, but resolves some issues and adds [a set of improvements](#improvements-beyond-lmdb).
|
||||||
|
|
||||||
<!-- section-begin mithril -->
|
<!-- section-begin mithril -->
|
||||||
|
|
||||||
The next version is under active non-public development from scratch and will be
|
The next version is under active non-public development from scratch and will be
|
||||||
released as _**MithrilDB**_ and `libmithrildb` for libraries & packages.
|
released as **MithrilDB** and `libmithrildb` for libraries & packages.
|
||||||
Admittedly mythical [Mithril](https://en.wikipedia.org/wiki/Mithril) is
|
Admittedly mythical [Mithril](https://en.wikipedia.org/wiki/Mithril) is
|
||||||
resembling silver but being stronger and lighter than steel. Therefore
|
resembling silver but being stronger and lighter than steel. Therefore
|
||||||
_MithrilDB_ is a rightly relevant name.
|
_MithrilDB_ is a rightly relevant name.
|
||||||
> _MithrilDB_ will be radically different from _libmdbx_ by the new
|
|
||||||
> database format and API based on C++17, as well as the [Apache 2.0
|
> _MithrilDB_ will be radically different from _libmdbx_ by the new
|
||||||
> License](https://www.apache.org/licenses/LICENSE-2.0). The goal of this
|
> database format and API based on C++17, as well as the [Apache 2.0
|
||||||
> revolution is to provide a clearer and robust API, add more features and
|
> License](https://www.apache.org/licenses/LICENSE-2.0). The goal of this
|
||||||
> new valuable properties of the database.
|
> revolution is to provide a clearer and robust API, add more features and
|
||||||
|
> new valuable properties of the database.
|
||||||
|
|
||||||
<!-- section-end -->
|
<!-- section-end -->
|
||||||
|
|
||||||
-----
|
-----
|
||||||
@@ -188,6 +203,7 @@ databases"](https://github.com/coreos/bbolt#comparison-with-other-databases)
|
|||||||
which is also (mostly) applicable to _libmdbx_.
|
which is also (mostly) applicable to _libmdbx_.
|
||||||
|
|
||||||
<!-- section-end -->
|
<!-- section-end -->
|
||||||
|
|
||||||
<!-- section-begin improvements -->
|
<!-- section-begin improvements -->
|
||||||
|
|
||||||
Improvements beyond LMDB
|
Improvements beyond LMDB
|
||||||
@@ -203,45 +219,52 @@ the user's point of view.
|
|||||||
## Added Features
|
## Added Features
|
||||||
|
|
||||||
1. Keys could be more than 2 times longer than _LMDB_.
|
1. Keys could be more than 2 times longer than _LMDB_.
|
||||||
> For DB with default page size _libmdbx_ support keys up to 2022 bytes
|
|
||||||
> and up to 32742 bytes for 64K page size. _LMDB_ allows key size up to
|
> For DB with default page size _libmdbx_ support keys up to 2022 bytes
|
||||||
> 511 bytes and may silently loses data with large values.
|
> and up to 32742 bytes for 64K page size. _LMDB_ allows key size up to
|
||||||
|
> 511 bytes and may silently loses data with large values.
|
||||||
|
|
||||||
2. Up to 30% faster than _LMDB_ in [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) benchmarks.
|
2. Up to 30% faster than _LMDB_ in [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) benchmarks.
|
||||||
> Benchmarks of the in-[tmpfs](https://en.wikipedia.org/wiki/Tmpfs) scenarios,
|
|
||||||
> that tests the speed of the engine itself, showned that _libmdbx_ 10-20% faster than _LMDB_,
|
> Benchmarks of the in-[tmpfs](https://en.wikipedia.org/wiki/Tmpfs) scenarios,
|
||||||
> and up to 30% faster when _libmdbx_ compiled with specific build options
|
> that tests the speed of the engine itself, showned that _libmdbx_ 10-20% faster than _LMDB_,
|
||||||
> which downgrades several runtime checks to be match with LMDB behaviour.
|
> and up to 30% faster when _libmdbx_ compiled with specific build options
|
||||||
>
|
> which downgrades several runtime checks to be match with LMDB behaviour.
|
||||||
> These and other results could be easily reproduced with [ioArena](https://github.com/pmwkaa/ioarena) just by `make bench-quartet` command,
|
>
|
||||||
> including comparisons with [RockDB](https://en.wikipedia.org/wiki/RocksDB)
|
> These and other results could be easily reproduced with [ioArena](https://github.com/pmwkaa/ioarena) just by `make bench-quartet` command,
|
||||||
> and [WiredTiger](https://en.wikipedia.org/wiki/WiredTiger).
|
> including comparisons with [RockDB](https://en.wikipedia.org/wiki/RocksDB)
|
||||||
|
> and [WiredTiger](https://en.wikipedia.org/wiki/WiredTiger).
|
||||||
|
|
||||||
3. Automatic on-the-fly database size adjustment, both increment and reduction.
|
3. Automatic on-the-fly database size adjustment, both increment and reduction.
|
||||||
> _libmdbx_ manages the database size according to parameters specified
|
|
||||||
> by `mdbx_env_set_geometry()` function,
|
> _libmdbx_ manages the database size according to parameters specified
|
||||||
> ones include the growth step and the truncation threshold.
|
> by `mdbx_env_set_geometry()` function,
|
||||||
>
|
> ones include the growth step and the truncation threshold.
|
||||||
> Unfortunately, on-the-fly database size adjustment doesn't work under [Wine](https://en.wikipedia.org/wiki/Wine_(software))
|
>
|
||||||
> due to its internal limitations and unimplemented functions, i.e. the `MDBX_UNABLE_EXTEND_MAPSIZE` error will be returned.
|
> Unfortunately, on-the-fly database size adjustment doesn't work under [Wine](https://en.wikipedia.org/wiki/Wine_(software))
|
||||||
|
> due to its internal limitations and unimplemented functions, i.e. the `MDBX_UNABLE_EXTEND_MAPSIZE` error will be returned.
|
||||||
|
|
||||||
4. Automatic continuous zero-overhead database compactification.
|
4. Automatic continuous zero-overhead database compactification.
|
||||||
> During each commit _libmdbx_ merges a freeing pages which adjacent with the unallocated area
|
|
||||||
> at the end of file, and then truncates unused space when a lot enough of.
|
> During each commit _libmdbx_ merges a freeing pages which adjacent with the unallocated area
|
||||||
|
> at the end of file, and then truncates unused space when a lot enough of.
|
||||||
|
|
||||||
5. The same database format for 32- and 64-bit builds.
|
5. The same database format for 32- and 64-bit builds.
|
||||||
> _libmdbx_ database format depends only on the [endianness](https://en.wikipedia.org/wiki/Endianness) but not on the [bitness](https://en.wiktionary.org/wiki/bitness).
|
|
||||||
|
> _libmdbx_ database format depends only on the [endianness](https://en.wikipedia.org/wiki/Endianness) but not on the [bitness](https://en.wiktionary.org/wiki/bitness).
|
||||||
|
|
||||||
6. LIFO policy for Garbage Collection recycling. This can significantly increase write performance due write-back disk cache up to several times in a best case scenario.
|
6. LIFO policy for Garbage Collection recycling. This can significantly increase write performance due write-back disk cache up to several times in a best case scenario.
|
||||||
> LIFO means that for reuse will be taken the latest becomes unused pages.
|
|
||||||
> Therefore the loop of database pages circulation becomes as short as possible.
|
> LIFO means that for reuse will be taken the latest becomes unused pages.
|
||||||
> In other words, the set of pages, that are (over)written in memory and on disk during a series of write transactions, will be as small as possible.
|
> Therefore the loop of database pages circulation becomes as short as possible.
|
||||||
> Thus creates ideal conditions for the battery-backed or flash-backed disk cache efficiency.
|
> In other words, the set of pages, that are (over)written in memory and on disk during a series of write transactions, will be as small as possible.
|
||||||
|
> Thus creates ideal conditions for the battery-backed or flash-backed disk cache efficiency.
|
||||||
|
|
||||||
7. Fast estimation of range query result volume, i.e. how many items can
|
7. Fast estimation of range query result volume, i.e. how many items can
|
||||||
be found between a `KEY1` and a `KEY2`. This is a prerequisite for build
|
be found between a `KEY1` and a `KEY2`. This is a prerequisite for build
|
||||||
and/or optimize query execution plans.
|
and/or optimize query execution plans.
|
||||||
> _libmdbx_ performs a rough estimate based on common B-tree pages of the paths from root to corresponding keys.
|
|
||||||
|
> _libmdbx_ performs a rough estimate based on common B-tree pages of the paths from root to corresponding keys.
|
||||||
|
|
||||||
8. `mdbx_chk` utility for database integrity check.
|
8. `mdbx_chk` utility for database integrity check.
|
||||||
Since version 0.9.1, the utility supports checking the database using any of the three meta pages and the ability to switch to it.
|
Since version 0.9.1, the utility supports checking the database using any of the three meta pages and the ability to switch to it.
|
||||||
@@ -254,12 +277,14 @@ Since version 0.9.1, the utility supports checking the database using any of the
|
|||||||
or not, that allows to avoid copy-out before updates.
|
or not, that allows to avoid copy-out before updates.
|
||||||
|
|
||||||
12. Extended information of whole-database, sub-databases, transactions, readers enumeration.
|
12. Extended information of whole-database, sub-databases, transactions, readers enumeration.
|
||||||
> _libmdbx_ provides a lot of information, including dirty and leftover pages
|
|
||||||
> for a write transaction, reading lag and holdover space for read transactions.
|
> _libmdbx_ provides a lot of information, including dirty and leftover pages
|
||||||
|
> for a write transaction, reading lag and holdover space for read transactions.
|
||||||
|
|
||||||
13. Extended update and delete operations.
|
13. Extended update and delete operations.
|
||||||
> _libmdbx_ allows one _at once_ with getting previous value
|
|
||||||
> and addressing the particular item from multi-value with the same key.
|
> _libmdbx_ allows one _at once_ with getting previous value
|
||||||
|
> and addressing the particular item from multi-value with the same key.
|
||||||
|
|
||||||
14. Useful runtime options for tuning engine to application's requirements and use cases specific.
|
14. Useful runtime options for tuning engine to application's requirements and use cases specific.
|
||||||
|
|
||||||
@@ -289,9 +314,10 @@ pre-opening is not needed.
|
|||||||
4. Returning `MDBX_EMULTIVAL` error in case of ambiguous update or delete.
|
4. Returning `MDBX_EMULTIVAL` error in case of ambiguous update or delete.
|
||||||
|
|
||||||
5. Guarantee of database integrity even in asynchronous unordered write-to-disk mode.
|
5. Guarantee of database integrity even in asynchronous unordered write-to-disk mode.
|
||||||
> _libmdbx_ propose additional trade-off by `MDBX_SAFE_NOSYNC` with append-like manner for updates,
|
|
||||||
> that avoids database corruption after a system crash contrary to LMDB.
|
> _libmdbx_ propose additional trade-off by `MDBX_SAFE_NOSYNC` with append-like manner for updates,
|
||||||
> Nevertheless, the `MDBX_UTTERLY_NOSYNC` mode is available to match LMDB's behaviour for `MDB_NOSYNC`.
|
> that avoids database corruption after a system crash contrary to LMDB.
|
||||||
|
> Nevertheless, the `MDBX_UTTERLY_NOSYNC` mode is available to match LMDB's behaviour for `MDB_NOSYNC`.
|
||||||
|
|
||||||
6. On **MacOS & iOS** the `fcntl(F_FULLFSYNC)` syscall is used _by
|
6. On **MacOS & iOS** the `fcntl(F_FULLFSYNC)` syscall is used _by
|
||||||
default_ to synchronize data with the disk, as this is [the only way to
|
default_ to synchronize data with the disk, as this is [the only way to
|
||||||
@@ -318,14 +344,22 @@ named mutexes are used.
|
|||||||
Historically, _libmdbx_ is a deeply revised and extended descendant of the
|
Historically, _libmdbx_ is a deeply revised and extended descendant of the
|
||||||
[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||||
At first the development was carried out within the
|
At first the development was carried out within the
|
||||||
[ReOpenLDAP](https://github.com/erthink/ReOpenLDAP) project. About a
|
[ReOpenLDAP](todo4recovery://erased_by_github/ReOpenLDAP) project. About a
|
||||||
year later _libmdbx_ was separated into a standalone project, which was
|
year later _libmdbx_ was separated into a standalone project, which was
|
||||||
[presented at Highload++ 2015
|
[presented at Highload++ 2015
|
||||||
conference](http://www.highload.ru/2015/abstracts/1831.html).
|
conference](http://www.highload.ru/2015/abstracts/1831.html).
|
||||||
|
|
||||||
Since 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/erthink/libfpta),
|
Since 2017 _libmdbx_ is used in [Fast Positive Tables](https://gitflic.ru/project/erthink/libfpta),
|
||||||
and development is funded by [Positive Technologies](https://www.ptsecurity.com).
|
and development is funded by [Positive Technologies](https://www.ptsecurity.com).
|
||||||
|
|
||||||
|
On 2022-04-15 the Github administration, without any warning nor
|
||||||
|
explanation, deleted _libmdbx_ along with a lot of other projects,
|
||||||
|
simultaneously blocking access for many developers. Therefore on
|
||||||
|
2022-04-21 we have migrated to a reliable trusted infrastructure.
|
||||||
|
The origin for now is at [GitFlic](https://gitflic.ru/project/erthink/libmdbx)
|
||||||
|
with backup at [ABF by ROSA Лаб](https://abf.io/erthink/libmdbx).
|
||||||
|
For the same reason ~~Github~~ is blacklisted forever.
|
||||||
|
|
||||||
## Acknowledgments
|
## Acknowledgments
|
||||||
Howard Chu <hyc@openldap.org> is the author of LMDB, from which
|
Howard Chu <hyc@openldap.org> is the author of LMDB, from which
|
||||||
originated the _libmdbx_ in 2015.
|
originated the _libmdbx_ in 2015.
|
||||||
@@ -341,29 +375,25 @@ Usage
|
|||||||
=====
|
=====
|
||||||
|
|
||||||
<!-- section-begin usage -->
|
<!-- section-begin usage -->
|
||||||
|
|
||||||
Currently, libmdbx is only available in a
|
Currently, libmdbx is only available in a
|
||||||
[source code](https://en.wikipedia.org/wiki/Source_code) form.
|
[source code](https://en.wikipedia.org/wiki/Source_code) form.
|
||||||
Packages support for common Linux distributions is planned in the future,
|
Packages support for common Linux distributions is planned in the future,
|
||||||
since release the version 1.0.
|
since release the version 1.0.
|
||||||
|
|
||||||
## Never use tarballs nor zips automatically provided by Github !
|
|
||||||
|
|
||||||
Please don't use tarballs nor zips which are automatically provided by Github.
|
|
||||||
These archives do not contain version information and thus are unfit to build _libmdbx_.
|
|
||||||
Instead of ones just clone the git repository, either download a tarball or zip with the properly amalgamated source core.
|
|
||||||
Moreover, please vote for [ability of disabling auto-creation such unsuitable archives](https://github.community/t/disable-tarball).
|
|
||||||
|
|
||||||
## Source code embedding
|
## Source code embedding
|
||||||
|
|
||||||
_libmdbx_ provides two official ways for integration in source code form:
|
_libmdbx_ provides two official ways for integration in source code form:
|
||||||
|
|
||||||
1. Using the amalgamated source code.
|
1. Using the amalgamated source code.
|
||||||
> The amalgamated source code includes all files required to build and
|
|
||||||
> use _libmdbx_, but not for testing _libmdbx_ itself.
|
> The amalgamated source code includes all files required to build and
|
||||||
|
> use _libmdbx_, but not for testing _libmdbx_ itself.
|
||||||
|
|
||||||
2. Adding the complete original source code as a `git submodule`.
|
2. Adding the complete original source code as a `git submodule`.
|
||||||
> This allows you to build as _libmdbx_ and testing tool.
|
|
||||||
> On the other hand, this way requires you to pull git tags, and use C++11 compiler for test tool.
|
> This allows you to build as _libmdbx_ and testing tool.
|
||||||
|
> On the other hand, this way requires you to pull git tags, and use C++11 compiler for test tool.
|
||||||
|
|
||||||
_**Please, avoid using any other techniques.**_ Otherwise, at least
|
_**Please, avoid using any other techniques.**_ Otherwise, at least
|
||||||
don't ask for support and don't name such chimeras `libmdbx`.
|
don't ask for support and don't name such chimeras `libmdbx`.
|
||||||
@@ -390,8 +420,7 @@ and build options respectively.
|
|||||||
The only significant specificity is that git' tags are required
|
The only significant specificity is that git' tags are required
|
||||||
to build from complete (not amalgamated) source codes.
|
to build from complete (not amalgamated) source codes.
|
||||||
Executing **`git fetch --tags --force --prune`** is enough to get ones,
|
Executing **`git fetch --tags --force --prune`** is enough to get ones,
|
||||||
or `git fetch --unshallow --tags --prune --force` after the Github's
|
and `--unshallow` or `--update-shallow` is required for shallow cloned case.
|
||||||
[`actions/checkout@v2`](https://github.com/actions/checkout) either set **`fetch-depth: 0`** for it.
|
|
||||||
|
|
||||||
So just using CMake or GNU Make in your habitual manner and feel free to
|
So just using CMake or GNU Make in your habitual manner and feel free to
|
||||||
fill an issue or make pull request in the case something will be
|
fill an issue or make pull request in the case something will be
|
||||||
@@ -399,10 +428,10 @@ unexpected or broken down.
|
|||||||
|
|
||||||
### Testing
|
### Testing
|
||||||
The amalgamated source code does not contain any tests for or several reasons.
|
The amalgamated source code does not contain any tests for or several reasons.
|
||||||
Please read [the explanation](https://github.com/erthink/libmdbx/issues/214#issuecomment-870717981) and don't ask to alter this.
|
Please read [the explanation](todo4recovery://erased_by_github/libmdbx/issues/214#issuecomment-870717981) and don't ask to alter this.
|
||||||
So for testing _libmdbx_ itself you need a full source code, i.e. the clone of a git repository, there is no option.
|
So for testing _libmdbx_ itself you need a full source code, i.e. the clone of a git repository, there is no option.
|
||||||
|
|
||||||
The full source code of _libmdbx_ has a [`test` subdirectory](https://github.com/erthink/libmdbx/tree/master/test) with minimalistic test "framework".
|
The full source code of _libmdbx_ has a [`test` subdirectory](https://gitflic.ru/project/erthink/libmdbx/tree/master/test) with minimalistic test "framework".
|
||||||
Actually yonder is a source code of the `mdbx_test` – console utility which has a set of command-line options that allow construct and run a reasonable enough test scenarios.
|
Actually yonder is a source code of the `mdbx_test` – console utility which has a set of command-line options that allow construct and run a reasonable enough test scenarios.
|
||||||
This test utility is intended for _libmdbx_'s developers for testing library itself, but not for use by users.
|
This test utility is intended for _libmdbx_'s developers for testing library itself, but not for use by users.
|
||||||
Therefore, only basic information is provided:
|
Therefore, only basic information is provided:
|
||||||
@@ -413,7 +442,7 @@ Therefore, only basic information is provided:
|
|||||||
- The `Makefile` provide several self-described targets for testing: `smoke`, `test`, `check`, `memcheck`, `test-valgrind`,
|
- The `Makefile` provide several self-described targets for testing: `smoke`, `test`, `check`, `memcheck`, `test-valgrind`,
|
||||||
`test-asan`, `test-leak`, `test-ubsan`, `cross-gcc`, `cross-qemu`, `gcc-analyzer`, `smoke-fault`, `smoke-singleprocess`,
|
`test-asan`, `test-leak`, `test-ubsan`, `cross-gcc`, `cross-qemu`, `gcc-analyzer`, `smoke-fault`, `smoke-singleprocess`,
|
||||||
`test-singleprocess`, 'long-test'. Please run `make --help` if doubt.
|
`test-singleprocess`, 'long-test'. Please run `make --help` if doubt.
|
||||||
- In addition to the `mdbx_test` utility, there is the script [`long_stochastic.sh`](https://github.com/erthink/libmdbx/blob/master/test/long_stochastic.sh),
|
- In addition to the `mdbx_test` utility, there is the script [`long_stochastic.sh`](https://gitflic.ru/project/erthink/libmdbx/blob/master/test/long_stochastic.sh),
|
||||||
which calls `mdbx_test` by going through set of modes and options, with gradually increasing the number of operations and the size of transactions.
|
which calls `mdbx_test` by going through set of modes and options, with gradually increasing the number of operations and the size of transactions.
|
||||||
This script is used for mostly of all automatic testing, including `Makefile` targets and Continuous Integration.
|
This script is used for mostly of all automatic testing, including `Makefile` targets and Continuous Integration.
|
||||||
- Brief information of available command-line options is available by `--help`.
|
- Brief information of available command-line options is available by `--help`.
|
||||||
@@ -561,7 +590,7 @@ from the [ios-cmake](https://github.com/leetal/ios-cmake) project.
|
|||||||
|
|
||||||
## API description
|
## API description
|
||||||
|
|
||||||
Please refer to the online [_libmdbx_ API reference](https://erthink.github.io/libmdbx/)
|
Please refer to the online [_libmdbx_ API reference](https://libmdbx.website.yandexcloud.net/docs)
|
||||||
and/or see the [mdbx.h++](mdbx.h%2B%2B) and [mdbx.h](mdbx.h) headers.
|
and/or see the [mdbx.h++](mdbx.h%2B%2B) and [mdbx.h](mdbx.h) headers.
|
||||||
|
|
||||||
<!-- section-begin bindings -->
|
<!-- section-begin bindings -->
|
||||||
@@ -581,7 +610,7 @@ Bindings
|
|||||||
| Rust | [libmdbx-rs](https://github.com/vorot93/libmdbx-rs) | [Artem Vorotnikov](https://github.com/vorot93) |
|
| Rust | [libmdbx-rs](https://github.com/vorot93/libmdbx-rs) | [Artem Vorotnikov](https://github.com/vorot93) |
|
||||||
| Rust | [mdbx](https://crates.io/crates/mdbx) | [gcxfd](https://github.com/gcxfd) |
|
| Rust | [mdbx](https://crates.io/crates/mdbx) | [gcxfd](https://github.com/gcxfd) |
|
||||||
| Java | [mdbxjni](https://github.com/castortech/mdbxjni) | [Castor Technologies](https://castortech.com/) |
|
| Java | [mdbxjni](https://github.com/castortech/mdbxjni) | [Castor Technologies](https://castortech.com/) |
|
||||||
| Python (draft) | [python-bindings](https://github.com/erthink/libmdbx/commits/python-bindings) branch | [Noel Kuntze](https://github.com/Thermi)
|
| Python (draft) | [python-bindings](todo4recovery://erased_by_github/libmdbx/commits/python-bindings) branch | [Noel Kuntze](https://github.com/Thermi)
|
||||||
| .NET (obsolete) | [mdbx.NET](https://github.com/wangjia184/mdbx.NET) | [Jerry Wang](https://github.com/wangjia184) |
|
| .NET (obsolete) | [mdbx.NET](https://github.com/wangjia184/mdbx.NET) | [Jerry Wang](https://github.com/wangjia184) |
|
||||||
|
|
||||||
<!-- section-end -->
|
<!-- section-end -->
|
||||||
@@ -620,7 +649,7 @@ Here showed sum of performance metrics in 3 benchmarks:
|
|||||||
|
|
||||||
2. Performance gap is too high to compare in any meaningful way.
|
2. Performance gap is too high to compare in any meaningful way.
|
||||||
|
|
||||||
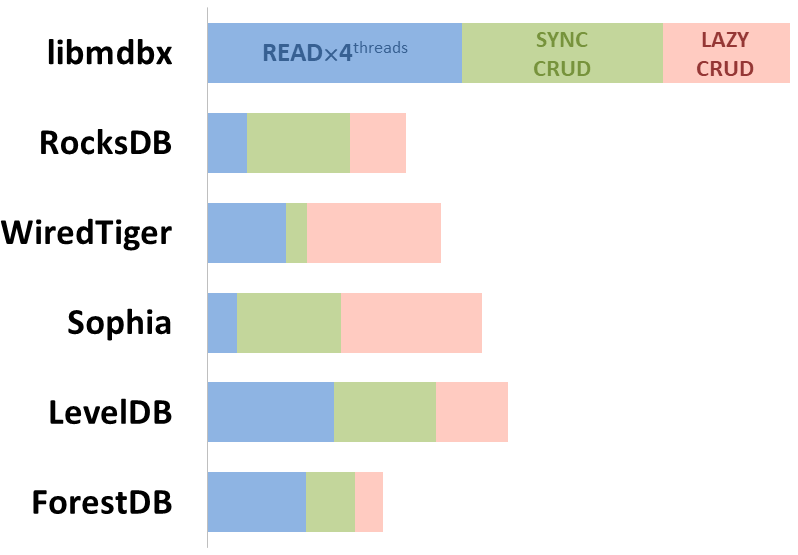
|

|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@@ -629,7 +658,7 @@ Here showed sum of performance metrics in 3 benchmarks:
|
|||||||
Summary performance with concurrent read/search queries in 1-2-4-8
|
Summary performance with concurrent read/search queries in 1-2-4-8
|
||||||
threads on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores).
|
threads on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores).
|
||||||
|
|
||||||
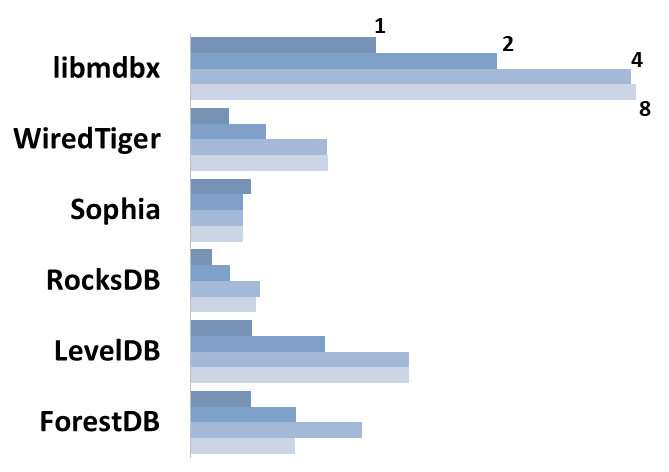
|

|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@@ -651,7 +680,7 @@ In the benchmark each transaction contains combined CRUD operations (2
|
|||||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database
|
inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database
|
||||||
and after full run the database contains 10,000 small key-value records.
|
and after full run the database contains 10,000 small key-value records.
|
||||||
|
|
||||||
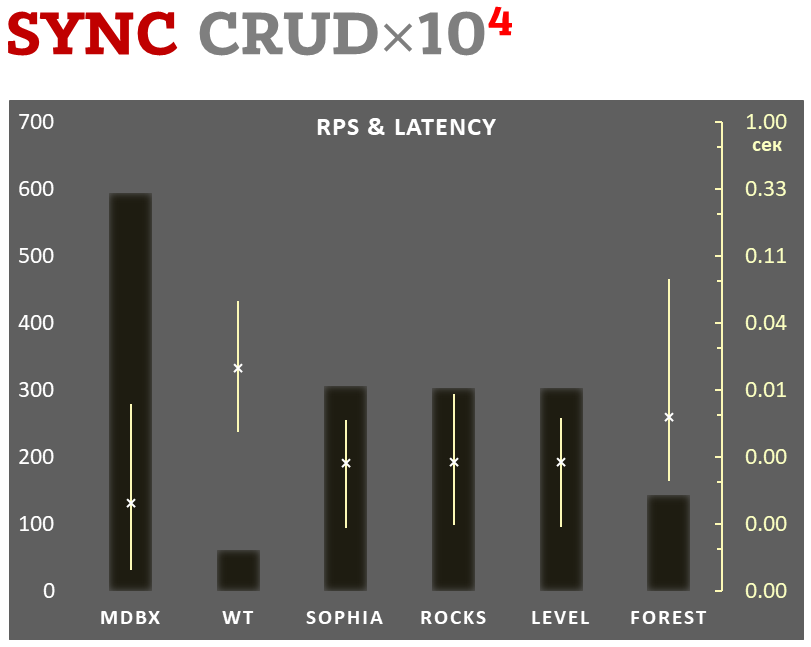
|

|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@@ -678,7 +707,7 @@ and after full run the database contains 100,000 small key-value
|
|||||||
records.
|
records.
|
||||||
|
|
||||||
|
|
||||||
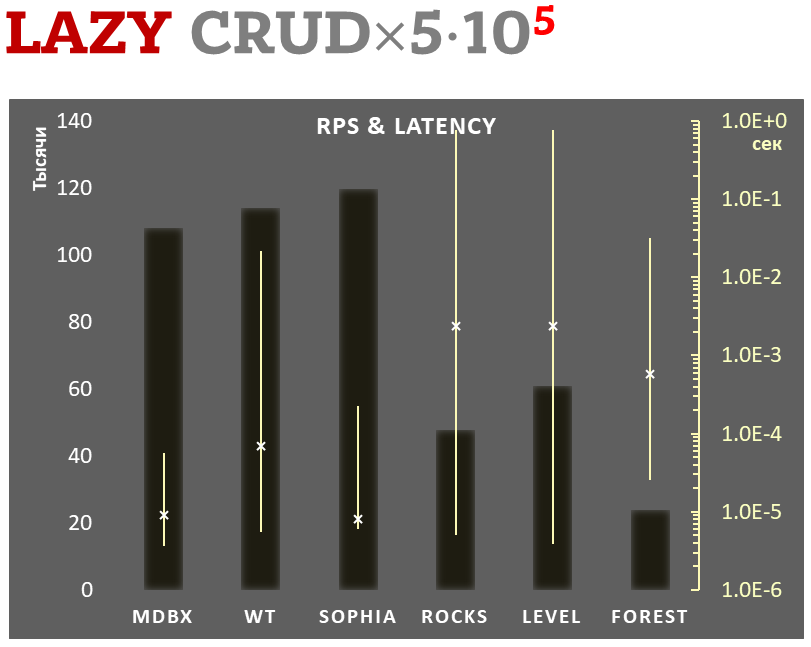
|

|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@@ -702,7 +731,7 @@ In the benchmark each transaction contains combined CRUD operations (2
|
|||||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database
|
inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database
|
||||||
and after full run the database contains 10,000 small key-value records.
|
and after full run the database contains 10,000 small key-value records.
|
||||||
|
|
||||||
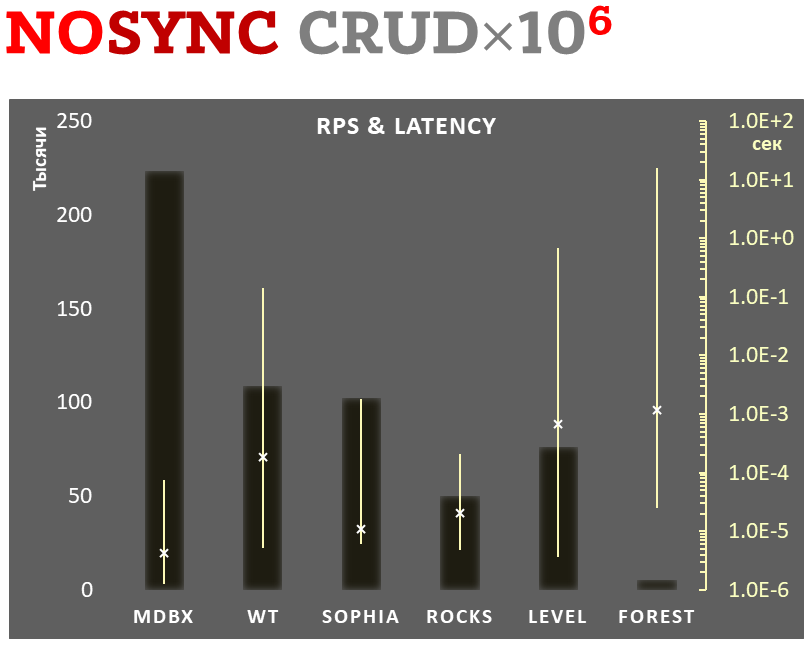
|

|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@@ -726,10 +755,6 @@ All benchmark data is gathered by
|
|||||||
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html)
|
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html)
|
||||||
syscall and by scanning the data directory.
|
syscall and by scanning the data directory.
|
||||||
|
|
||||||
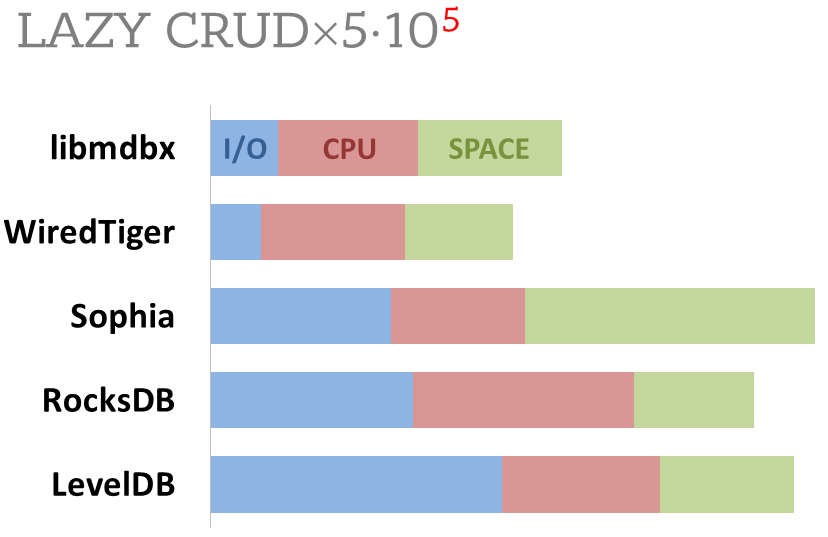
|

|
||||||
|
|
||||||
<!-- section-end -->
|
<!-- section-end -->
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
#### This is a mirror of the origin repository that was moved to [gitflic.ru](https://gitflic.ru/project/erthink/libmdbx) because of discriminatory restrictions for Russian Crimea.
|
|
||||||
|
|||||||
113
appveyor.yml
113
appveyor.yml
@@ -1,113 +0,0 @@
|
|||||||
version: 0.11.6.{build}
|
|
||||||
|
|
||||||
environment:
|
|
||||||
matrix:
|
|
||||||
- APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2015
|
|
||||||
CMAKE_GENERATOR: Visual Studio 14 2015
|
|
||||||
TOOLSET: 140
|
|
||||||
- APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2019
|
|
||||||
CMAKE_GENERATOR: Visual Studio 16 2019
|
|
||||||
TOOLSET: 142
|
|
||||||
MDBX_BUILD_SHARED_LIBRARY: OFF
|
|
||||||
MDBX_WITHOUT_MSVC_CRT: OFF
|
|
||||||
- APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2019
|
|
||||||
CMAKE_GENERATOR: Visual Studio 16 2019
|
|
||||||
TOOLSET: 142
|
|
||||||
MDBX_BUILD_SHARED_LIBRARY: ON
|
|
||||||
MDBX_WITHOUT_MSVC_CRT: ON
|
|
||||||
- APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2019
|
|
||||||
CMAKE_GENERATOR: Visual Studio 16 2019
|
|
||||||
TOOLSET: 142
|
|
||||||
MDBX_BUILD_SHARED_LIBRARY: OFF
|
|
||||||
MDBX_WITHOUT_MSVC_CRT: ON
|
|
||||||
- APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2019
|
|
||||||
CMAKE_GENERATOR: Visual Studio 16 2019
|
|
||||||
TOOLSET: 142
|
|
||||||
MDBX_BUILD_SHARED_LIBRARY: ON
|
|
||||||
MDBX_WITHOUT_MSVC_CRT: OFF
|
|
||||||
- APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2017
|
|
||||||
CMAKE_GENERATOR: Visual Studio 15 2017
|
|
||||||
TOOLSET: 141
|
|
||||||
|
|
||||||
branches:
|
|
||||||
except:
|
|
||||||
- coverity_scan
|
|
||||||
|
|
||||||
configuration:
|
|
||||||
- Debug
|
|
||||||
# MSVC-2019 hangs during code generation/optimization due to its own internal errors.
|
|
||||||
# I have found out that the problem occurs because of the /Ob2 option (see https://github.com/erthink/libmdbx/issues/116).
|
|
||||||
# So the simplest workaround is to using RelWithDebiInfo configuration for testing (cmake will uses /Ob1 option), instead of Release.
|
|
||||||
# - Release
|
|
||||||
- RelWithDebInfo
|
|
||||||
|
|
||||||
platform:
|
|
||||||
- Win32
|
|
||||||
- x64
|
|
||||||
|
|
||||||
# MSVC-2019 may hang up during code generation/optimization due to its own internal errors.
|
|
||||||
matrix:
|
|
||||||
allow_failures:
|
|
||||||
- image: Visual Studio 2019
|
|
||||||
configuration: Release
|
|
||||||
|
|
||||||
# Enable RDP for troubleshooting
|
|
||||||
#init:
|
|
||||||
# - ps: iex ((new-object net.webclient).DownloadString('https://raw.githubusercontent.com/appveyor/ci/master/scripts/enable-rdp.ps1'))
|
|
||||||
|
|
||||||
before_build:
|
|
||||||
- git clean -x -f -d
|
|
||||||
- git submodule sync
|
|
||||||
- git fetch --tags --prune --force
|
|
||||||
- git submodule update --init --recursive
|
|
||||||
- git submodule foreach --recursive git fetch --tags --prune --force
|
|
||||||
- cmake --version
|
|
||||||
|
|
||||||
build_script:
|
|
||||||
- ps: |
|
|
||||||
Write-Output "*******************************************************************************"
|
|
||||||
Write-Output "Configuration: $env:CONFIGURATION"
|
|
||||||
Write-Output "Platform: $env:PLATFORM"
|
|
||||||
Write-Output "Toolchain: $env:CMAKE_GENERATOR v$env:TOOLSET"
|
|
||||||
Write-Output "Options: MDBX_WITHOUT_MSVC_CRT=$env:MDBX_WITHOUT_MSVC_CRT MDBX_BUILD_SHARED_LIBRARY=$env:MDBX_BUILD_SHARED_LIBRARY"
|
|
||||||
Write-Output "*******************************************************************************"
|
|
||||||
|
|
||||||
md _build -Force | Out-Null
|
|
||||||
cd _build
|
|
||||||
|
|
||||||
$generator = $env:CMAKE_GENERATOR
|
|
||||||
if ($env:TOOLSET -lt 142) {
|
|
||||||
if ($env:PLATFORM -eq "x64") {
|
|
||||||
$generator = "$generator Win64"
|
|
||||||
}
|
|
||||||
& cmake -G "$generator" -D CMAKE_CONFIGURATION_TYPES="Debug;Release;RelWithDebInfo" -D MDBX_WITHOUT_MSVC_CRT:BOOL=$env:MDBX_WITHOUT_MSVC_CRT -D MDBX_BUILD_SHARED_LIBRARY:BOOL=$env:MDBX_BUILD_SHARED_LIBRARY ..
|
|
||||||
} else {
|
|
||||||
& cmake -G "$generator" -A $env:PLATFORM -D CMAKE_CONFIGURATION_TYPES="Debug;Release;RelWithDebInfo" -DMDBX_WITHOUT_MSVC_CRT:BOOL=$env:MDBX_WITHOUT_MSVC_CRT -D MDBX_BUILD_SHARED_LIBRARY:BOOL=$env:MDBX_BUILD_SHARED_LIBRARY ..
|
|
||||||
}
|
|
||||||
if ($LastExitCode -ne 0) {
|
|
||||||
throw "Exec: $ErrorMessage"
|
|
||||||
}
|
|
||||||
Write-Output "*******************************************************************************"
|
|
||||||
|
|
||||||
& cmake --build . --config $env:CONFIGURATION
|
|
||||||
if ($LastExitCode -ne 0) {
|
|
||||||
throw "Exec: $ErrorMessage"
|
|
||||||
}
|
|
||||||
Write-Output "*******************************************************************************"
|
|
||||||
|
|
||||||
test_script:
|
|
||||||
- ps: |
|
|
||||||
if (($env:PLATFORM -ne "ARM") -and ($env:PLATFORM -ne "ARM64")) {
|
|
||||||
& ./$env:CONFIGURATION/mdbx_test.exe --progress --console=no --pathname=test.db --dont-cleanup-after basic > test.log
|
|
||||||
Get-Content test.log | Select-Object -last 42
|
|
||||||
if ($LastExitCode -ne 0) {
|
|
||||||
throw "Exec: $ErrorMessage"
|
|
||||||
} else {
|
|
||||||
& ./$env:CONFIGURATION/mdbx_chk.exe -nvv test.db | Tee-Object -file chk.log | Select-Object -last 42
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
on_failure:
|
|
||||||
- ps: Push-AppveyorArtifact \projects\libmdbx\_build\test.log
|
|
||||||
- ps: Push-AppveyorArtifact \projects\libmdbx\_build\test.db
|
|
||||||
- ps: Push-AppveyorArtifact \projects\libmdbx\_build\chk.log
|
|
||||||
225
docs/Doxyfile.in
225
docs/Doxyfile.in
@@ -1,4 +1,4 @@
|
|||||||
# Doxyfile 1.8.17
|
# Doxyfile 1.9.1
|
||||||
|
|
||||||
# This file describes the settings to be used by the documentation system
|
# This file describes the settings to be used by the documentation system
|
||||||
# doxygen (www.doxygen.org) for a project.
|
# doxygen (www.doxygen.org) for a project.
|
||||||
@@ -227,6 +227,14 @@ QT_AUTOBRIEF = NO
|
|||||||
|
|
||||||
MULTILINE_CPP_IS_BRIEF = NO
|
MULTILINE_CPP_IS_BRIEF = NO
|
||||||
|
|
||||||
|
# By default Python docstrings are displayed as preformatted text and doxygen's
|
||||||
|
# special commands cannot be used. By setting PYTHON_DOCSTRING to NO the
|
||||||
|
# doxygen's special commands can be used and the contents of the docstring
|
||||||
|
# documentation blocks is shown as doxygen documentation.
|
||||||
|
# The default value is: YES.
|
||||||
|
|
||||||
|
PYTHON_DOCSTRING = YES
|
||||||
|
|
||||||
# If the INHERIT_DOCS tag is set to YES then an undocumented member inherits the
|
# If the INHERIT_DOCS tag is set to YES then an undocumented member inherits the
|
||||||
# documentation from any documented member that it re-implements.
|
# documentation from any documented member that it re-implements.
|
||||||
# The default value is: YES.
|
# The default value is: YES.
|
||||||
@@ -263,12 +271,6 @@ TAB_SIZE = 4
|
|||||||
|
|
||||||
ALIASES =
|
ALIASES =
|
||||||
|
|
||||||
# This tag can be used to specify a number of word-keyword mappings (TCL only).
|
|
||||||
# A mapping has the form "name=value". For example adding "class=itcl::class"
|
|
||||||
# will allow you to use the command class in the itcl::class meaning.
|
|
||||||
|
|
||||||
TCL_SUBST =
|
|
||||||
|
|
||||||
# Set the OPTIMIZE_OUTPUT_FOR_C tag to YES if your project consists of C sources
|
# Set the OPTIMIZE_OUTPUT_FOR_C tag to YES if your project consists of C sources
|
||||||
# only. Doxygen will then generate output that is more tailored for C. For
|
# only. Doxygen will then generate output that is more tailored for C. For
|
||||||
# instance, some of the names that are used will be different. The list of all
|
# instance, some of the names that are used will be different. The list of all
|
||||||
@@ -310,18 +312,21 @@ OPTIMIZE_OUTPUT_SLICE = NO
|
|||||||
# extension. Doxygen has a built-in mapping, but you can override or extend it
|
# extension. Doxygen has a built-in mapping, but you can override or extend it
|
||||||
# using this tag. The format is ext=language, where ext is a file extension, and
|
# using this tag. The format is ext=language, where ext is a file extension, and
|
||||||
# language is one of the parsers supported by doxygen: IDL, Java, JavaScript,
|
# language is one of the parsers supported by doxygen: IDL, Java, JavaScript,
|
||||||
# Csharp (C#), C, C++, D, PHP, md (Markdown), Objective-C, Python, Slice,
|
# Csharp (C#), C, C++, D, PHP, md (Markdown), Objective-C, Python, Slice, VHDL,
|
||||||
# Fortran (fixed format Fortran: FortranFixed, free formatted Fortran:
|
# Fortran (fixed format Fortran: FortranFixed, free formatted Fortran:
|
||||||
# FortranFree, unknown formatted Fortran: Fortran. In the later case the parser
|
# FortranFree, unknown formatted Fortran: Fortran. In the later case the parser
|
||||||
# tries to guess whether the code is fixed or free formatted code, this is the
|
# tries to guess whether the code is fixed or free formatted code, this is the
|
||||||
# default for Fortran type files), VHDL, tcl. For instance to make doxygen treat
|
# default for Fortran type files). For instance to make doxygen treat .inc files
|
||||||
# .inc files as Fortran files (default is PHP), and .f files as C (default is
|
# as Fortran files (default is PHP), and .f files as C (default is Fortran),
|
||||||
# Fortran), use: inc=Fortran f=C.
|
# use: inc=Fortran f=C.
|
||||||
#
|
#
|
||||||
# Note: For files without extension you can use no_extension as a placeholder.
|
# Note: For files without extension you can use no_extension as a placeholder.
|
||||||
#
|
#
|
||||||
# Note that for custom extensions you also need to set FILE_PATTERNS otherwise
|
# Note that for custom extensions you also need to set FILE_PATTERNS otherwise
|
||||||
# the files are not read by doxygen.
|
# the files are not read by doxygen. When specifying no_extension you should add
|
||||||
|
# * to the FILE_PATTERNS.
|
||||||
|
#
|
||||||
|
# Note see also the list of default file extension mappings.
|
||||||
|
|
||||||
EXTENSION_MAPPING =
|
EXTENSION_MAPPING =
|
||||||
|
|
||||||
@@ -455,6 +460,19 @@ TYPEDEF_HIDES_STRUCT = YES
|
|||||||
|
|
||||||
LOOKUP_CACHE_SIZE = 0
|
LOOKUP_CACHE_SIZE = 0
|
||||||
|
|
||||||
|
# The NUM_PROC_THREADS specifies the number threads doxygen is allowed to use
|
||||||
|
# during processing. When set to 0 doxygen will based this on the number of
|
||||||
|
# cores available in the system. You can set it explicitly to a value larger
|
||||||
|
# than 0 to get more control over the balance between CPU load and processing
|
||||||
|
# speed. At this moment only the input processing can be done using multiple
|
||||||
|
# threads. Since this is still an experimental feature the default is set to 1,
|
||||||
|
# which efficively disables parallel processing. Please report any issues you
|
||||||
|
# encounter. Generating dot graphs in parallel is controlled by the
|
||||||
|
# DOT_NUM_THREADS setting.
|
||||||
|
# Minimum value: 0, maximum value: 32, default value: 1.
|
||||||
|
|
||||||
|
NUM_PROC_THREADS = 1
|
||||||
|
|
||||||
#---------------------------------------------------------------------------
|
#---------------------------------------------------------------------------
|
||||||
# Build related configuration options
|
# Build related configuration options
|
||||||
#---------------------------------------------------------------------------
|
#---------------------------------------------------------------------------
|
||||||
@@ -518,6 +536,13 @@ EXTRACT_LOCAL_METHODS = NO
|
|||||||
|
|
||||||
EXTRACT_ANON_NSPACES = NO
|
EXTRACT_ANON_NSPACES = NO
|
||||||
|
|
||||||
|
# If this flag is set to YES, the name of an unnamed parameter in a declaration
|
||||||
|
# will be determined by the corresponding definition. By default unnamed
|
||||||
|
# parameters remain unnamed in the output.
|
||||||
|
# The default value is: YES.
|
||||||
|
|
||||||
|
RESOLVE_UNNAMED_PARAMS = YES
|
||||||
|
|
||||||
# If the HIDE_UNDOC_MEMBERS tag is set to YES, doxygen will hide all
|
# If the HIDE_UNDOC_MEMBERS tag is set to YES, doxygen will hide all
|
||||||
# undocumented members inside documented classes or files. If set to NO these
|
# undocumented members inside documented classes or files. If set to NO these
|
||||||
# members will be included in the various overviews, but no documentation
|
# members will be included in the various overviews, but no documentation
|
||||||
@@ -555,11 +580,18 @@ HIDE_IN_BODY_DOCS = NO
|
|||||||
|
|
||||||
INTERNAL_DOCS = NO
|
INTERNAL_DOCS = NO
|
||||||
|
|
||||||
# If the CASE_SENSE_NAMES tag is set to NO then doxygen will only generate file
|
# With the correct setting of option CASE_SENSE_NAMES doxygen will better be
|
||||||
# names in lower-case letters. If set to YES, upper-case letters are also
|
# able to match the capabilities of the underlying filesystem. In case the
|
||||||
# allowed. This is useful if you have classes or files whose names only differ
|
# filesystem is case sensitive (i.e. it supports files in the same directory
|
||||||
# in case and if your file system supports case sensitive file names. Windows
|
# whose names only differ in casing), the option must be set to YES to properly
|
||||||
# (including Cygwin) ands Mac users are advised to set this option to NO.
|
# deal with such files in case they appear in the input. For filesystems that
|
||||||
|
# are not case sensitive the option should be be set to NO to properly deal with
|
||||||
|
# output files written for symbols that only differ in casing, such as for two
|
||||||
|
# classes, one named CLASS and the other named Class, and to also support
|
||||||
|
# references to files without having to specify the exact matching casing. On
|
||||||
|
# Windows (including Cygwin) and MacOS, users should typically set this option
|
||||||
|
# to NO, whereas on Linux or other Unix flavors it should typically be set to
|
||||||
|
# YES.
|
||||||
# The default value is: system dependent.
|
# The default value is: system dependent.
|
||||||
|
|
||||||
CASE_SENSE_NAMES = NO
|
CASE_SENSE_NAMES = NO
|
||||||
@@ -798,7 +830,10 @@ WARN_IF_DOC_ERROR = YES
|
|||||||
WARN_NO_PARAMDOC = NO
|
WARN_NO_PARAMDOC = NO
|
||||||
|
|
||||||
# If the WARN_AS_ERROR tag is set to YES then doxygen will immediately stop when
|
# If the WARN_AS_ERROR tag is set to YES then doxygen will immediately stop when
|
||||||
# a warning is encountered.
|
# a warning is encountered. If the WARN_AS_ERROR tag is set to FAIL_ON_WARNINGS
|
||||||
|
# then doxygen will continue running as if WARN_AS_ERROR tag is set to NO, but
|
||||||
|
# at the end of the doxygen process doxygen will return with a non-zero status.
|
||||||
|
# Possible values are: NO, YES and FAIL_ON_WARNINGS.
|
||||||
# The default value is: NO.
|
# The default value is: NO.
|
||||||
|
|
||||||
WARN_AS_ERROR = NO
|
WARN_AS_ERROR = NO
|
||||||
@@ -829,13 +864,19 @@ WARN_LOGFILE =
|
|||||||
# spaces. See also FILE_PATTERNS and EXTENSION_MAPPING
|
# spaces. See also FILE_PATTERNS and EXTENSION_MAPPING
|
||||||
# Note: If this tag is empty the current directory is searched.
|
# Note: If this tag is empty the current directory is searched.
|
||||||
|
|
||||||
INPUT = overall.md intro.md usage.md mdbx.h mdbx.h++ options.h ChangeLog.md
|
INPUT = overall.md \
|
||||||
|
intro.md \
|
||||||
|
usage.md \
|
||||||
|
mdbx.h \
|
||||||
|
mdbx.h++ \
|
||||||
|
options.h \
|
||||||
|
ChangeLog.md
|
||||||
|
|
||||||
# This tag can be used to specify the character encoding of the source files
|
# This tag can be used to specify the character encoding of the source files
|
||||||
# that doxygen parses. Internally doxygen uses the UTF-8 encoding. Doxygen uses
|
# that doxygen parses. Internally doxygen uses the UTF-8 encoding. Doxygen uses
|
||||||
# libiconv (or the iconv built into libc) for the transcoding. See the libiconv
|
# libiconv (or the iconv built into libc) for the transcoding. See the libiconv
|
||||||
# documentation (see: https://www.gnu.org/software/libiconv/) for the list of
|
# documentation (see:
|
||||||
# possible encodings.
|
# https://www.gnu.org/software/libiconv/) for the list of possible encodings.
|
||||||
# The default value is: UTF-8.
|
# The default value is: UTF-8.
|
||||||
|
|
||||||
INPUT_ENCODING = UTF-8
|
INPUT_ENCODING = UTF-8
|
||||||
@@ -848,13 +889,15 @@ INPUT_ENCODING = UTF-8
|
|||||||
# need to set EXTENSION_MAPPING for the extension otherwise the files are not
|
# need to set EXTENSION_MAPPING for the extension otherwise the files are not
|
||||||
# read by doxygen.
|
# read by doxygen.
|
||||||
#
|
#
|
||||||
|
# Note the list of default checked file patterns might differ from the list of
|
||||||
|
# default file extension mappings.
|
||||||
|
#
|
||||||
# If left blank the following patterns are tested:*.c, *.cc, *.cxx, *.cpp,
|
# If left blank the following patterns are tested:*.c, *.cc, *.cxx, *.cpp,
|
||||||
# *.c++, *.java, *.ii, *.ixx, *.ipp, *.i++, *.inl, *.idl, *.ddl, *.odl, *.h,
|
# *.c++, *.java, *.ii, *.ixx, *.ipp, *.i++, *.inl, *.idl, *.ddl, *.odl, *.h,
|
||||||
# *.hh, *.hxx, *.hpp, *.h++, *.cs, *.d, *.php, *.php4, *.php5, *.phtml, *.inc,
|
# *.hh, *.hxx, *.hpp, *.h++, *.cs, *.d, *.php, *.php4, *.php5, *.phtml, *.inc,
|
||||||
# *.m, *.markdown, *.md, *.mm, *.dox (to be provided as doxygen C comment),
|
# *.m, *.markdown, *.md, *.mm, *.dox (to be provided as doxygen C comment),
|
||||||
# *.doc (to be provided as doxygen C comment), *.txt (to be provided as doxygen
|
# *.py, *.pyw, *.f90, *.f95, *.f03, *.f08, *.f18, *.f, *.for, *.vhd, *.vhdl,
|
||||||
# C comment), *.py, *.pyw, *.f90, *.f95, *.f03, *.f08, *.f, *.for, *.tcl, *.vhd,
|
# *.ucf, *.qsf and *.ice.
|
||||||
# *.vhdl, *.ucf, *.qsf and *.ice.
|
|
||||||
|
|
||||||
FILE_PATTERNS = *.h
|
FILE_PATTERNS = *.h
|
||||||
|
|
||||||
@@ -1069,16 +1112,22 @@ USE_HTAGS = NO
|
|||||||
VERBATIM_HEADERS = YES
|
VERBATIM_HEADERS = YES
|
||||||
|
|
||||||
# If the CLANG_ASSISTED_PARSING tag is set to YES then doxygen will use the
|
# If the CLANG_ASSISTED_PARSING tag is set to YES then doxygen will use the
|
||||||
# clang parser (see: http://clang.llvm.org/) for more accurate parsing at the
|
# clang parser (see:
|
||||||
# cost of reduced performance. This can be particularly helpful with template
|
# http://clang.llvm.org/) for more accurate parsing at the cost of reduced
|
||||||
# rich C++ code for which doxygen's built-in parser lacks the necessary type
|
# performance. This can be particularly helpful with template rich C++ code for
|
||||||
# information.
|
# which doxygen's built-in parser lacks the necessary type information.
|
||||||
# Note: The availability of this option depends on whether or not doxygen was
|
# Note: The availability of this option depends on whether or not doxygen was
|
||||||
# generated with the -Duse_libclang=ON option for CMake.
|
# generated with the -Duse_libclang=ON option for CMake.
|
||||||
# The default value is: NO.
|
# The default value is: NO.
|
||||||
|
|
||||||
CLANG_ASSISTED_PARSING = NO
|
CLANG_ASSISTED_PARSING = NO
|
||||||
|
|
||||||
|
# If clang assisted parsing is enabled and the CLANG_ADD_INC_PATHS tag is set to
|
||||||
|
# YES then doxygen will add the directory of each input to the include path.
|
||||||
|
# The default value is: YES.
|
||||||
|
|
||||||
|
CLANG_ADD_INC_PATHS = YES
|
||||||
|
|
||||||
# If clang assisted parsing is enabled you can provide the compiler with command
|
# If clang assisted parsing is enabled you can provide the compiler with command
|
||||||
# line options that you would normally use when invoking the compiler. Note that
|
# line options that you would normally use when invoking the compiler. Note that
|
||||||
# the include paths will already be set by doxygen for the files and directories
|
# the include paths will already be set by doxygen for the files and directories
|
||||||
@@ -1088,10 +1137,13 @@ CLANG_ASSISTED_PARSING = NO
|
|||||||
CLANG_OPTIONS =
|
CLANG_OPTIONS =
|
||||||
|
|
||||||
# If clang assisted parsing is enabled you can provide the clang parser with the
|
# If clang assisted parsing is enabled you can provide the clang parser with the
|
||||||
# path to the compilation database (see:
|
# path to the directory containing a file called compile_commands.json. This
|
||||||
# http://clang.llvm.org/docs/HowToSetupToolingForLLVM.html) used when the files
|
# file is the compilation database (see:
|
||||||
# were built. This is equivalent to specifying the "-p" option to a clang tool,
|
# http://clang.llvm.org/docs/HowToSetupToolingForLLVM.html) containing the
|
||||||
# such as clang-check. These options will then be passed to the parser.
|
# options used when the source files were built. This is equivalent to
|
||||||
|
# specifying the -p option to a clang tool, such as clang-check. These options
|
||||||
|
# will then be passed to the parser. Any options specified with CLANG_OPTIONS
|
||||||
|
# will be added as well.
|
||||||
# Note: The availability of this option depends on whether or not doxygen was
|
# Note: The availability of this option depends on whether or not doxygen was
|
||||||
# generated with the -Duse_libclang=ON option for CMake.
|
# generated with the -Duse_libclang=ON option for CMake.
|
||||||
|
|
||||||
@@ -1108,13 +1160,6 @@ CLANG_DATABASE_PATH =
|
|||||||
|
|
||||||
ALPHABETICAL_INDEX = YES
|
ALPHABETICAL_INDEX = YES
|
||||||
|
|
||||||
# The COLS_IN_ALPHA_INDEX tag can be used to specify the number of columns in
|
|
||||||
# which the alphabetical index list will be split.
|
|
||||||
# Minimum value: 1, maximum value: 20, default value: 5.
|
|
||||||
# This tag requires that the tag ALPHABETICAL_INDEX is set to YES.
|
|
||||||
|
|
||||||
COLS_IN_ALPHA_INDEX = 5
|
|
||||||
|
|
||||||
# In case all classes in a project start with a common prefix, all classes will
|
# In case all classes in a project start with a common prefix, all classes will
|
||||||
# be put under the same header in the alphabetical index. The IGNORE_PREFIX tag
|
# be put under the same header in the alphabetical index. The IGNORE_PREFIX tag
|
||||||
# can be used to specify a prefix (or a list of prefixes) that should be ignored
|
# can be used to specify a prefix (or a list of prefixes) that should be ignored
|
||||||
@@ -1285,10 +1330,11 @@ HTML_INDEX_NUM_ENTRIES = 100
|
|||||||
|
|
||||||
# If the GENERATE_DOCSET tag is set to YES, additional index files will be
|
# If the GENERATE_DOCSET tag is set to YES, additional index files will be
|
||||||
# generated that can be used as input for Apple's Xcode 3 integrated development
|
# generated that can be used as input for Apple's Xcode 3 integrated development
|
||||||
# environment (see: https://developer.apple.com/xcode/), introduced with OSX
|
# environment (see:
|
||||||
# 10.5 (Leopard). To create a documentation set, doxygen will generate a
|
# https://developer.apple.com/xcode/), introduced with OSX 10.5 (Leopard). To
|
||||||
# Makefile in the HTML output directory. Running make will produce the docset in
|
# create a documentation set, doxygen will generate a Makefile in the HTML
|
||||||
# that directory and running make install will install the docset in
|
# output directory. Running make will produce the docset in that directory and
|
||||||
|
# running make install will install the docset in
|
||||||
# ~/Library/Developer/Shared/Documentation/DocSets so that Xcode will find it at
|
# ~/Library/Developer/Shared/Documentation/DocSets so that Xcode will find it at
|
||||||
# startup. See https://developer.apple.com/library/archive/featuredarticles/Doxy
|
# startup. See https://developer.apple.com/library/archive/featuredarticles/Doxy
|
||||||
# genXcode/_index.html for more information.
|
# genXcode/_index.html for more information.
|
||||||
@@ -1330,8 +1376,8 @@ DOCSET_PUBLISHER_NAME = Publisher
|
|||||||
# If the GENERATE_HTMLHELP tag is set to YES then doxygen generates three
|
# If the GENERATE_HTMLHELP tag is set to YES then doxygen generates three
|
||||||
# additional HTML index files: index.hhp, index.hhc, and index.hhk. The
|
# additional HTML index files: index.hhp, index.hhc, and index.hhk. The
|
||||||
# index.hhp is a project file that can be read by Microsoft's HTML Help Workshop
|
# index.hhp is a project file that can be read by Microsoft's HTML Help Workshop
|
||||||
# (see: https://www.microsoft.com/en-us/download/details.aspx?id=21138) on
|
# (see:
|
||||||
# Windows.
|
# https://www.microsoft.com/en-us/download/details.aspx?id=21138) on Windows.
|
||||||
#
|
#
|
||||||
# The HTML Help Workshop contains a compiler that can convert all HTML output
|
# The HTML Help Workshop contains a compiler that can convert all HTML output
|
||||||
# generated by doxygen into a single compiled HTML file (.chm). Compiled HTML
|
# generated by doxygen into a single compiled HTML file (.chm). Compiled HTML
|
||||||
@@ -1361,7 +1407,7 @@ CHM_FILE =
|
|||||||
HHC_LOCATION =
|
HHC_LOCATION =
|
||||||
|
|
||||||
# The GENERATE_CHI flag controls if a separate .chi index file is generated
|
# The GENERATE_CHI flag controls if a separate .chi index file is generated
|
||||||
# (YES) or that it should be included in the master .chm file (NO).
|
# (YES) or that it should be included in the main .chm file (NO).
|
||||||
# The default value is: NO.
|
# The default value is: NO.
|
||||||
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
|
# This tag requires that the tag GENERATE_HTMLHELP is set to YES.
|
||||||
|
|
||||||
@@ -1406,7 +1452,8 @@ QCH_FILE =
|
|||||||
|
|
||||||
# The QHP_NAMESPACE tag specifies the namespace to use when generating Qt Help
|
# The QHP_NAMESPACE tag specifies the namespace to use when generating Qt Help
|
||||||
# Project output. For more information please see Qt Help Project / Namespace
|
# Project output. For more information please see Qt Help Project / Namespace
|
||||||
# (see: https://doc.qt.io/archives/qt-4.8/qthelpproject.html#namespace).
|
# (see:
|
||||||
|
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#namespace).
|
||||||
# The default value is: org.doxygen.Project.
|
# The default value is: org.doxygen.Project.
|
||||||
# This tag requires that the tag GENERATE_QHP is set to YES.
|
# This tag requires that the tag GENERATE_QHP is set to YES.
|
||||||
|
|
||||||
@@ -1414,8 +1461,8 @@ QHP_NAMESPACE = org.doxygen.Project
|
|||||||
|
|
||||||
# The QHP_VIRTUAL_FOLDER tag specifies the namespace to use when generating Qt
|
# The QHP_VIRTUAL_FOLDER tag specifies the namespace to use when generating Qt
|
||||||
# Help Project output. For more information please see Qt Help Project / Virtual
|
# Help Project output. For more information please see Qt Help Project / Virtual
|
||||||
# Folders (see: https://doc.qt.io/archives/qt-4.8/qthelpproject.html#virtual-
|
# Folders (see:
|
||||||
# folders).
|
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#virtual-folders).
|
||||||
# The default value is: doc.
|
# The default value is: doc.
|
||||||
# This tag requires that the tag GENERATE_QHP is set to YES.
|
# This tag requires that the tag GENERATE_QHP is set to YES.
|
||||||
|
|
||||||
@@ -1423,16 +1470,16 @@ QHP_VIRTUAL_FOLDER = doc
|
|||||||
|
|
||||||
# If the QHP_CUST_FILTER_NAME tag is set, it specifies the name of a custom
|
# If the QHP_CUST_FILTER_NAME tag is set, it specifies the name of a custom
|
||||||
# filter to add. For more information please see Qt Help Project / Custom
|
# filter to add. For more information please see Qt Help Project / Custom
|
||||||
# Filters (see: https://doc.qt.io/archives/qt-4.8/qthelpproject.html#custom-
|
# Filters (see:
|
||||||
# filters).
|
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#custom-filters).
|
||||||
# This tag requires that the tag GENERATE_QHP is set to YES.
|
# This tag requires that the tag GENERATE_QHP is set to YES.
|
||||||
|
|
||||||
QHP_CUST_FILTER_NAME =
|
QHP_CUST_FILTER_NAME =
|
||||||
|
|
||||||
# The QHP_CUST_FILTER_ATTRS tag specifies the list of the attributes of the
|
# The QHP_CUST_FILTER_ATTRS tag specifies the list of the attributes of the
|
||||||
# custom filter to add. For more information please see Qt Help Project / Custom
|
# custom filter to add. For more information please see Qt Help Project / Custom
|
||||||
# Filters (see: https://doc.qt.io/archives/qt-4.8/qthelpproject.html#custom-
|
# Filters (see:
|
||||||
# filters).
|
# https://doc.qt.io/archives/qt-4.8/qthelpproject.html#custom-filters).
|
||||||
# This tag requires that the tag GENERATE_QHP is set to YES.
|
# This tag requires that the tag GENERATE_QHP is set to YES.
|
||||||
|
|
||||||
QHP_CUST_FILTER_ATTRS =
|
QHP_CUST_FILTER_ATTRS =
|
||||||
@@ -1444,9 +1491,9 @@ QHP_CUST_FILTER_ATTRS =
|
|||||||
|
|
||||||
QHP_SECT_FILTER_ATTRS =
|
QHP_SECT_FILTER_ATTRS =
|
||||||
|
|
||||||
# The QHG_LOCATION tag can be used to specify the location of Qt's
|
# The QHG_LOCATION tag can be used to specify the location (absolute path
|
||||||
# qhelpgenerator. If non-empty doxygen will try to run qhelpgenerator on the
|
# including file name) of Qt's qhelpgenerator. If non-empty doxygen will try to
|
||||||
# generated .qhp file.
|
# run qhelpgenerator on the generated .qhp file.
|
||||||
# This tag requires that the tag GENERATE_QHP is set to YES.
|
# This tag requires that the tag GENERATE_QHP is set to YES.
|
||||||
|
|
||||||
QHG_LOCATION =
|
QHG_LOCATION =
|
||||||
@@ -1523,6 +1570,17 @@ TREEVIEW_WIDTH = 250
|
|||||||
|
|
||||||
EXT_LINKS_IN_WINDOW = NO
|
EXT_LINKS_IN_WINDOW = NO
|
||||||
|
|
||||||
|
# If the HTML_FORMULA_FORMAT option is set to svg, doxygen will use the pdf2svg
|
||||||
|
# tool (see https://github.com/dawbarton/pdf2svg) or inkscape (see
|
||||||
|
# https://inkscape.org) to generate formulas as SVG images instead of PNGs for
|
||||||
|
# the HTML output. These images will generally look nicer at scaled resolutions.
|
||||||
|
# Possible values are: png (the default) and svg (looks nicer but requires the
|
||||||
|
# pdf2svg or inkscape tool).
|
||||||
|
# The default value is: png.
|
||||||
|
# This tag requires that the tag GENERATE_HTML is set to YES.
|
||||||
|
|
||||||
|
HTML_FORMULA_FORMAT = png
|
||||||
|
|
||||||
# Use this tag to change the font size of LaTeX formulas included as images in
|
# Use this tag to change the font size of LaTeX formulas included as images in
|
||||||
# the HTML documentation. When you change the font size after a successful
|
# the HTML documentation. When you change the font size after a successful
|
||||||
# doxygen run you need to manually remove any form_*.png images from the HTML
|
# doxygen run you need to manually remove any form_*.png images from the HTML
|
||||||
@@ -1562,7 +1620,7 @@ USE_MATHJAX = YES
|
|||||||
|
|
||||||
# When MathJax is enabled you can set the default output format to be used for
|
# When MathJax is enabled you can set the default output format to be used for
|
||||||
# the MathJax output. See the MathJax site (see:
|
# the MathJax output. See the MathJax site (see:
|
||||||
# http://docs.mathjax.org/en/latest/output.html) for more details.
|
# http://docs.mathjax.org/en/v2.7-latest/output.html) for more details.
|
||||||
# Possible values are: HTML-CSS (which is slower, but has the best
|
# Possible values are: HTML-CSS (which is slower, but has the best
|
||||||
# compatibility), NativeMML (i.e. MathML) and SVG.
|
# compatibility), NativeMML (i.e. MathML) and SVG.
|
||||||
# The default value is: HTML-CSS.
|
# The default value is: HTML-CSS.
|
||||||
@@ -1578,7 +1636,7 @@ MATHJAX_FORMAT = HTML-CSS
|
|||||||
# Content Delivery Network so you can quickly see the result without installing
|
# Content Delivery Network so you can quickly see the result without installing
|
||||||
# MathJax. However, it is strongly recommended to install a local copy of
|
# MathJax. However, it is strongly recommended to install a local copy of
|
||||||
# MathJax from https://www.mathjax.org before deployment.
|
# MathJax from https://www.mathjax.org before deployment.
|
||||||
# The default value is: https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/.
|
# The default value is: https://cdn.jsdelivr.net/npm/mathjax@2.
|
||||||
# This tag requires that the tag USE_MATHJAX is set to YES.
|
# This tag requires that the tag USE_MATHJAX is set to YES.
|
||||||
|
|
||||||
MATHJAX_RELPATH = https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/
|
MATHJAX_RELPATH = https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/
|
||||||
@@ -1592,7 +1650,8 @@ MATHJAX_EXTENSIONS =
|
|||||||
|
|
||||||
# The MATHJAX_CODEFILE tag can be used to specify a file with javascript pieces
|
# The MATHJAX_CODEFILE tag can be used to specify a file with javascript pieces
|
||||||
# of code that will be used on startup of the MathJax code. See the MathJax site
|
# of code that will be used on startup of the MathJax code. See the MathJax site
|
||||||
# (see: http://docs.mathjax.org/en/latest/output.html) for more details. For an
|
# (see:
|
||||||
|
# http://docs.mathjax.org/en/v2.7-latest/output.html) for more details. For an
|
||||||
# example see the documentation.
|
# example see the documentation.
|
||||||
# This tag requires that the tag USE_MATHJAX is set to YES.
|
# This tag requires that the tag USE_MATHJAX is set to YES.
|
||||||
|
|
||||||
@@ -1639,7 +1698,8 @@ SERVER_BASED_SEARCH = NO
|
|||||||
#
|
#
|
||||||
# Doxygen ships with an example indexer (doxyindexer) and search engine
|
# Doxygen ships with an example indexer (doxyindexer) and search engine
|
||||||
# (doxysearch.cgi) which are based on the open source search engine library
|
# (doxysearch.cgi) which are based on the open source search engine library
|
||||||
# Xapian (see: https://xapian.org/).
|
# Xapian (see:
|
||||||
|
# https://xapian.org/).
|
||||||
#
|
#
|
||||||
# See the section "External Indexing and Searching" for details.
|
# See the section "External Indexing and Searching" for details.
|
||||||
# The default value is: NO.
|
# The default value is: NO.
|
||||||
@@ -1652,8 +1712,9 @@ EXTERNAL_SEARCH = NO
|
|||||||
#
|
#
|
||||||
# Doxygen ships with an example indexer (doxyindexer) and search engine
|
# Doxygen ships with an example indexer (doxyindexer) and search engine
|
||||||
# (doxysearch.cgi) which are based on the open source search engine library
|
# (doxysearch.cgi) which are based on the open source search engine library
|
||||||
# Xapian (see: https://xapian.org/). See the section "External Indexing and
|
# Xapian (see:
|
||||||
# Searching" for details.
|
# https://xapian.org/). See the section "External Indexing and Searching" for
|
||||||
|
# details.
|
||||||
# This tag requires that the tag SEARCHENGINE is set to YES.
|
# This tag requires that the tag SEARCHENGINE is set to YES.
|
||||||
|
|
||||||
SEARCHENGINE_URL =
|
SEARCHENGINE_URL =
|
||||||
@@ -1817,9 +1878,11 @@ LATEX_EXTRA_FILES =
|
|||||||
|
|
||||||
PDF_HYPERLINKS = YES
|
PDF_HYPERLINKS = YES
|
||||||
|
|
||||||
# If the USE_PDFLATEX tag is set to YES, doxygen will use pdflatex to generate
|
# If the USE_PDFLATEX tag is set to YES, doxygen will use the engine as
|
||||||
# the PDF file directly from the LaTeX files. Set this option to YES, to get a
|
# specified with LATEX_CMD_NAME to generate the PDF file directly from the LaTeX
|
||||||
# higher quality PDF documentation.
|
# files. Set this option to YES, to get a higher quality PDF documentation.
|
||||||
|
#
|
||||||
|
# See also section LATEX_CMD_NAME for selecting the engine.
|
||||||
# The default value is: YES.
|
# The default value is: YES.
|
||||||
# This tag requires that the tag GENERATE_LATEX is set to YES.
|
# This tag requires that the tag GENERATE_LATEX is set to YES.
|
||||||
|
|
||||||
@@ -2123,8 +2186,6 @@ MACRO_EXPANSION = YES
|
|||||||
|
|
||||||
EXPAND_ONLY_PREDEF = YES
|
EXPAND_ONLY_PREDEF = YES
|
||||||
|
|
||||||
EXPAND_AS_DEFINED = LIBMDBX_INLINE_API
|
|
||||||
|
|
||||||
# If the SEARCH_INCLUDES tag is set to YES, the include files in the
|
# If the SEARCH_INCLUDES tag is set to YES, the include files in the
|
||||||
# INCLUDE_PATH will be searched if a #include is found.
|
# INCLUDE_PATH will be searched if a #include is found.
|
||||||
# The default value is: YES.
|
# The default value is: YES.
|
||||||
@@ -2332,10 +2393,32 @@ UML_LOOK = NO
|
|||||||
# but if the number exceeds 15, the total amount of fields shown is limited to
|
# but if the number exceeds 15, the total amount of fields shown is limited to
|
||||||
# 10.
|
# 10.
|
||||||
# Minimum value: 0, maximum value: 100, default value: 10.
|
# Minimum value: 0, maximum value: 100, default value: 10.
|
||||||
# This tag requires that the tag HAVE_DOT is set to YES.
|
# This tag requires that the tag UML_LOOK is set to YES.
|
||||||
|
|
||||||
UML_LIMIT_NUM_FIELDS = 10
|
UML_LIMIT_NUM_FIELDS = 10
|
||||||
|
|
||||||
|
# If the DOT_UML_DETAILS tag is set to NO, doxygen will show attributes and
|
||||||
|
# methods without types and arguments in the UML graphs. If the DOT_UML_DETAILS
|
||||||
|
# tag is set to YES, doxygen will add type and arguments for attributes and
|
||||||
|
# methods in the UML graphs. If the DOT_UML_DETAILS tag is set to NONE, doxygen
|
||||||
|
# will not generate fields with class member information in the UML graphs. The
|
||||||
|
# class diagrams will look similar to the default class diagrams but using UML
|
||||||
|
# notation for the relationships.
|
||||||
|
# Possible values are: NO, YES and NONE.
|
||||||
|
# The default value is: NO.
|
||||||
|
# This tag requires that the tag UML_LOOK is set to YES.
|
||||||
|
|
||||||
|
DOT_UML_DETAILS = NO
|
||||||
|
|
||||||
|
# The DOT_WRAP_THRESHOLD tag can be used to set the maximum number of characters
|
||||||
|
# to display on a single line. If the actual line length exceeds this threshold
|
||||||
|
# significantly it will wrapped across multiple lines. Some heuristics are apply
|
||||||
|
# to avoid ugly line breaks.
|
||||||
|
# Minimum value: 0, maximum value: 1000, default value: 17.
|
||||||
|
# This tag requires that the tag HAVE_DOT is set to YES.
|
||||||
|
|
||||||
|
DOT_WRAP_THRESHOLD = 17
|
||||||
|
|
||||||
# If the TEMPLATE_RELATIONS tag is set to YES then the inheritance and
|
# If the TEMPLATE_RELATIONS tag is set to YES then the inheritance and
|
||||||
# collaboration graphs will show the relations between templates and their
|
# collaboration graphs will show the relations between templates and their
|
||||||
# instances.
|
# instances.
|
||||||
@@ -2527,9 +2610,11 @@ DOT_MULTI_TARGETS = NO
|
|||||||
|
|
||||||
GENERATE_LEGEND = YES
|
GENERATE_LEGEND = YES
|
||||||
|
|
||||||
# If the DOT_CLEANUP tag is set to YES, doxygen will remove the intermediate dot
|
# If the DOT_CLEANUP tag is set to YES, doxygen will remove the intermediate
|
||||||
# files that are used to generate the various graphs.
|
# files that are used to generate the various graphs.
|
||||||
|
#
|
||||||
|
# Note: This setting is not only used for dot files but also for msc and
|
||||||
|
# plantuml temporary files.
|
||||||
# The default value is: YES.
|
# The default value is: YES.
|
||||||
# This tag requires that the tag HAVE_DOT is set to YES.
|
|
||||||
|
|
||||||
DOT_CLEANUP = YES
|
DOT_CLEANUP = YES
|
||||||
|
|||||||
@@ -2,118 +2,6 @@ Restrictions & Caveats {#restrictions}
|
|||||||
======================
|
======================
|
||||||
In addition to those listed for some functions.
|
In addition to those listed for some functions.
|
||||||
|
|
||||||
## Troubleshooting the LCK-file
|
|
||||||
1. A broken LCK-file can cause sync issues, including appearance of
|
|
||||||
wrong/inconsistent data for readers. When database opened in the
|
|
||||||
cooperative read-write mode the LCK-file requires to be mapped to
|
|
||||||
memory in read-write access. In this case it is always possible for
|
|
||||||
stray/malfunctioned application could writes thru pointers to
|
|
||||||
silently corrupt the LCK-file.
|
|
||||||
|
|
||||||
Unfortunately, there is no any portable way to prevent such
|
|
||||||
corruption, since the LCK-file is updated concurrently by
|
|
||||||
multiple processes in a lock-free manner and any locking is
|
|
||||||
unwise due to a large overhead.
|
|
||||||
|
|
||||||
The "next" version of libmdbx (\ref MithrilDB) will solve this issue.
|
|
||||||
|
|
||||||
\note Workaround: Just make all programs using the database close it;
|
|
||||||
the LCK-file is always reset on first open.
|
|
||||||
|
|
||||||
2. Stale reader transactions left behind by an aborted program cause
|
|
||||||
further writes to grow the database quickly, and stale locks can
|
|
||||||
block further operation.
|
|
||||||
MDBX checks for stale readers while opening environment and before
|
|
||||||
growth the database. But in some cases, this may not be enough.
|
|
||||||
|
|
||||||
\note Workaround: Check for stale readers periodically, using the
|
|
||||||
\ref mdbx_reader_check() function or the mdbx_stat tool.
|
|
||||||
|
|
||||||
3. Stale writers will be cleared automatically by MDBX on supported
|
|
||||||
platforms. But this is platform-specific, especially of
|
|
||||||
implementation of shared POSIX-mutexes and support for robust
|
|
||||||
mutexes. For instance there are no known issues on Linux, OSX,
|
|
||||||
Windows and FreeBSD.
|
|
||||||
|
|
||||||
\note Workaround: Otherwise just make all programs using the database
|
|
||||||
close it; the LCK-file is always reset on first open of the environment.
|
|
||||||
|
|
||||||
|
|
||||||
## Remote filesystems
|
|
||||||
Do not use MDBX databases on remote filesystems, even between processes
|
|
||||||
on the same host. This breaks file locks on some platforms, possibly
|
|
||||||
memory map sync, and certainly sync between programs on different hosts.
|
|
||||||
|
|
||||||
On the other hand, MDBX support the exclusive database operation over
|
|
||||||
a network, and cooperative read-only access to the database placed on
|
|
||||||
a read-only network shares.
|
|
||||||
|
|
||||||
|
|
||||||
## Child processes
|
|
||||||
Do not use opened \ref MDBX_env instance(s) in a child processes after `fork()`.
|
|
||||||
It would be insane to call fork() and any MDBX-functions simultaneously
|
|
||||||
from multiple threads. The best way is to prevent the presence of open
|
|
||||||
MDBX-instances during `fork()`.
|
|
||||||
|
|
||||||
The \ref MDBX_ENV_CHECKPID build-time option, which is ON by default on
|
|
||||||
non-Windows platforms (i.e. where `fork()` is available), enables PID
|
|
||||||
checking at a few critical points. But this does not give any guarantees,
|
|
||||||
but only allows you to detect such errors a little sooner. Depending on
|
|
||||||
the platform, you should expect an application crash and/or database
|
|
||||||
corruption in such cases.
|
|
||||||
|
|
||||||
On the other hand, MDBX allow calling \ref mdbx_env_close() in such cases to
|
|
||||||
release resources, but no more and in general this is a wrong way.
|
|
||||||
|
|
||||||
## Read-only mode
|
|
||||||
There is no pure read-only mode in a normal explicitly way, since
|
|
||||||
readers need write access to LCK-file to be ones visible for writer.
|
|
||||||
|
|
||||||
So MDBX always tries to open/create LCK-file for read-write, but switches
|
|
||||||
to without-LCK mode on appropriate errors (`EROFS`, `EACCESS`, `EPERM`)
|
|
||||||
if the read-only mode was requested by the \ref MDBX_RDONLY flag which is
|
|
||||||
described below.
|
|
||||||
|
|
||||||
The "next" version of libmdbx (\ref MithrilDB) will solve this issue for the "many
|
|
||||||
readers without writer" case.
|
|
||||||
|
|
||||||
|
|
||||||
## One thread - One transaction
|
|
||||||
A thread can only use one transaction at a time, plus any nested
|
|
||||||
read-write transactions in the non-writemap mode. Each transaction
|
|
||||||
belongs to one thread. The \ref MDBX_NOTLS flag changes this for read-only
|
|
||||||
transactions. See below.
|
|
||||||
|
|
||||||
Do not start more than one transaction for a one thread. If you think
|
|
||||||
about this, it's really strange to do something with two data snapshots
|
|
||||||
at once, which may be different. MDBX checks and preventing this by
|
|
||||||
returning corresponding error code (\ref MDBX_TXN_OVERLAPPING, \ref MDBX_BAD_RSLOT,
|
|
||||||
\ref MDBX_BUSY) unless you using \ref MDBX_NOTLS option on the environment.
|
|
||||||
Nonetheless, with the `MDBX_NOTLS` option, you must know exactly what you
|
|
||||||
are doing, otherwise you will get deadlocks or reading an alien data.
|
|
||||||
|
|
||||||
|
|
||||||
## Do not open twice
|
|
||||||
Do not have open an MDBX database twice in the same process at the same
|
|
||||||
time. By default MDBX prevent this in most cases by tracking databases
|
|
||||||
opening and return \ref MDBX_BUSY if anyone LCK-file is already open.
|
|
||||||
|
|
||||||
The reason for this is that when the "Open file description" locks (aka
|
|
||||||
OFD-locks) are not available, MDBX uses POSIX locks on files, and these
|
|
||||||
locks have issues if one process opens a file multiple times. If a single
|
|
||||||
process opens the same environment multiple times, closing it once will
|
|
||||||
remove all the locks held on it, and the other instances will be
|
|
||||||
vulnerable to corruption from other processes.
|
|
||||||
|
|
||||||
For compatibility with LMDB which allows multi-opening, MDBX can be
|
|
||||||
configured at runtime by `mdbx_setup_debug(MDBX_DBG_LEGACY_MULTIOPEN, ...)`
|
|
||||||
prior to calling other MDBX functions. In this way MDBX will track
|
|
||||||
databases opening, detect multi-opening cases and then recover POSIX file
|
|
||||||
locks as necessary. However, lock recovery can cause unexpected pauses,
|
|
||||||
such as when another process opened the database in exclusive mode before
|
|
||||||
the lock was restored - we have to wait until such a process releases the
|
|
||||||
database, and so on.
|
|
||||||
|
|
||||||
|
|
||||||
## Long-lived read transactions {#long-lived-read}
|
## Long-lived read transactions {#long-lived-read}
|
||||||
Avoid long-lived read transactions, especially in the scenarios with a
|
Avoid long-lived read transactions, especially in the scenarios with a
|
||||||
@@ -162,6 +50,7 @@ The "next" version of libmdbx (\ref MithrilDB) will completely solve this.
|
|||||||
not apply to write transactions if the system clears stale writers, see
|
not apply to write transactions if the system clears stale writers, see
|
||||||
above.
|
above.
|
||||||
|
|
||||||
|
|
||||||
## Large data items and huge transactions
|
## Large data items and huge transactions
|
||||||
|
|
||||||
MDBX allows you to store values up to 1 gigabyte in size, but this is
|
MDBX allows you to store values up to 1 gigabyte in size, but this is
|
||||||
@@ -191,10 +80,123 @@ list of pages to be retired.
|
|||||||
|
|
||||||
Both of these issues will be addressed in MithrilDB.
|
Both of these issues will be addressed in MithrilDB.
|
||||||
|
|
||||||
|
|
||||||
## Space reservation
|
## Space reservation
|
||||||
An MDBX database configuration will often reserve considerable unused
|
An MDBX database configuration will often reserve considerable unused
|
||||||
memory address space and maybe file size for future growth. This does
|
memory address space and maybe file size for future growth. This does
|
||||||
not use actual memory or disk space, but users may need to understand
|
not use actual memory or disk space, but users may need to understand
|
||||||
the difference so they won't be scared off.
|
the difference so they won't be scared off.
|
||||||
|
|
||||||
\todo To write about the Read/Write Amplification Factors
|
|
||||||
|
## Remote filesystems
|
||||||
|
Do not use MDBX databases on remote filesystems, even between processes
|
||||||
|
on the same host. This breaks file locks on some platforms, possibly
|
||||||
|
memory map sync, and certainly sync between programs on different hosts.
|
||||||
|
|
||||||
|
On the other hand, MDBX support the exclusive database operation over
|
||||||
|
a network, and cooperative read-only access to the database placed on
|
||||||
|
a read-only network shares.
|
||||||
|
|
||||||
|
|
||||||
|
## Child processes
|
||||||
|
Do not use opened \ref MDBX_env instance(s) in a child processes after `fork()`.
|
||||||
|
It would be insane to call fork() and any MDBX-functions simultaneously
|
||||||
|
from multiple threads. The best way is to prevent the presence of open
|
||||||
|
MDBX-instances during `fork()`.
|
||||||
|
|
||||||
|
The \ref MDBX_ENV_CHECKPID build-time option, which is ON by default on
|
||||||
|
non-Windows platforms (i.e. where `fork()` is available), enables PID
|
||||||
|
checking at a few critical points. But this does not give any guarantees,
|
||||||
|
but only allows you to detect such errors a little sooner. Depending on
|
||||||
|
the platform, you should expect an application crash and/or database
|
||||||
|
corruption in such cases.
|
||||||
|
|
||||||
|
On the other hand, MDBX allow calling \ref mdbx_env_close() in such cases to
|
||||||
|
release resources, but no more and in general this is a wrong way.
|
||||||
|
|
||||||
|
|
||||||
|
## Read-only mode
|
||||||
|
There is no pure read-only mode in a normal explicitly way, since
|
||||||
|
readers need write access to LCK-file to be ones visible for writer.
|
||||||
|
|
||||||
|
So MDBX always tries to open/create LCK-file for read-write, but switches
|
||||||
|
to without-LCK mode on appropriate errors (`EROFS`, `EACCESS`, `EPERM`)
|
||||||
|
if the read-only mode was requested by the \ref MDBX_RDONLY flag which is
|
||||||
|
described below.
|
||||||
|
|
||||||
|
The "next" version of libmdbx (\ref MithrilDB) will solve this issue for the "many
|
||||||
|
readers without writer" case.
|
||||||
|
|
||||||
|
|
||||||
|
## Troubleshooting the LCK-file
|
||||||
|
1. A broken LCK-file can cause sync issues, including appearance of
|
||||||
|
wrong/inconsistent data for readers. When database opened in the
|
||||||
|
cooperative read-write mode the LCK-file requires to be mapped to
|
||||||
|
memory in read-write access. In this case it is always possible for
|
||||||
|
stray/malfunctioned application could writes thru pointers to
|
||||||
|
silently corrupt the LCK-file.
|
||||||
|
|
||||||
|
Unfortunately, there is no any portable way to prevent such
|
||||||
|
corruption, since the LCK-file is updated concurrently by
|
||||||
|
multiple processes in a lock-free manner and any locking is
|
||||||
|
unwise due to a large overhead.
|
||||||
|
|
||||||
|
The "next" version of libmdbx (\ref MithrilDB) will solve this issue.
|
||||||
|
|
||||||
|
\note Workaround: Just make all programs using the database close it;
|
||||||
|
the LCK-file is always reset on first open.
|
||||||
|
|
||||||
|
2. Stale reader transactions left behind by an aborted program cause
|
||||||
|
further writes to grow the database quickly, and stale locks can
|
||||||
|
block further operation.
|
||||||
|
MDBX checks for stale readers while opening environment and before
|
||||||
|
growth the database. But in some cases, this may not be enough.
|
||||||
|
|
||||||
|
\note Workaround: Check for stale readers periodically, using the
|
||||||
|
\ref mdbx_reader_check() function or the mdbx_stat tool.
|
||||||
|
|
||||||
|
3. Stale writers will be cleared automatically by MDBX on supported
|
||||||
|
platforms. But this is platform-specific, especially of
|
||||||
|
implementation of shared POSIX-mutexes and support for robust
|
||||||
|
mutexes. For instance there are no known issues on Linux, OSX,
|
||||||
|
Windows and FreeBSD.
|
||||||
|
|
||||||
|
\note Workaround: Otherwise just make all programs using the database
|
||||||
|
close it; the LCK-file is always reset on first open of the environment.
|
||||||
|
|
||||||
|
|
||||||
|
## One thread - One transaction
|
||||||
|
A thread can only use one transaction at a time, plus any nested
|
||||||
|
read-write transactions in the non-writemap mode. Each transaction
|
||||||
|
belongs to one thread. The \ref MDBX_NOTLS flag changes this for read-only
|
||||||
|
transactions. See below.
|
||||||
|
|
||||||
|
Do not start more than one transaction for a one thread. If you think
|
||||||
|
about this, it's really strange to do something with two data snapshots
|
||||||
|
at once, which may be different. MDBX checks and preventing this by
|
||||||
|
returning corresponding error code (\ref MDBX_TXN_OVERLAPPING, \ref MDBX_BAD_RSLOT,
|
||||||
|
\ref MDBX_BUSY) unless you using \ref MDBX_NOTLS option on the environment.
|
||||||
|
Nonetheless, with the `MDBX_NOTLS` option, you must know exactly what you
|
||||||
|
are doing, otherwise you will get deadlocks or reading an alien data.
|
||||||
|
|
||||||
|
|
||||||
|
## Do not open twice
|
||||||
|
Do not have open an MDBX database twice in the same process at the same
|
||||||
|
time. By default MDBX prevent this in most cases by tracking databases
|
||||||
|
opening and return \ref MDBX_BUSY if anyone LCK-file is already open.
|
||||||
|
|
||||||
|
The reason for this is that when the "Open file description" locks (aka
|
||||||
|
OFD-locks) are not available, MDBX uses POSIX locks on files, and these
|
||||||
|
locks have issues if one process opens a file multiple times. If a single
|
||||||
|
process opens the same environment multiple times, closing it once will
|
||||||
|
remove all the locks held on it, and the other instances will be
|
||||||
|
vulnerable to corruption from other processes.
|
||||||
|
|
||||||
|
For compatibility with LMDB which allows multi-opening, MDBX can be
|
||||||
|
configured at runtime by `mdbx_setup_debug(MDBX_DBG_LEGACY_MULTIOPEN, ...)`
|
||||||
|
prior to calling other MDBX functions. In this way MDBX will track
|
||||||
|
databases opening, detect multi-opening cases and then recover POSIX file
|
||||||
|
locks as necessary. However, lock recovery can cause unexpected pauses,
|
||||||
|
such as when another process opened the database in exclusive mode before
|
||||||
|
the lock was restored - we have to wait until such a process releases the
|
||||||
|
database, and so on.
|
||||||
|
|||||||
@@ -1,4 +1,3 @@
|
|||||||
|
|
||||||
_The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо._
|
_The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо._
|
||||||
|
|
||||||
\section toc Table of Contents
|
\section toc Table of Contents
|
||||||
@@ -23,7 +22,7 @@ each of which is divided into several sections.
|
|||||||
- The \ref mdbx.h++ header file reference
|
- The \ref mdbx.h++ header file reference
|
||||||
|
|
||||||
Please do not hesitate to point out errors in the documentation,
|
Please do not hesitate to point out errors in the documentation,
|
||||||
including creating [PR](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/proposing-changes-to-your-work-with-pull-requests) with corrections and improvements.
|
including creating [merge-request](https://gitflic.ru/project/erthink/libmdbx/merge-request) with corrections and improvements.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
46
mdbx.h
46
mdbx.h
@@ -14,6 +14,12 @@ break down. _libmdbx_ supports Linux, Windows, MacOS, OSX, iOS, Android,
|
|||||||
FreeBSD, DragonFly, Solaris, OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other
|
FreeBSD, DragonFly, Solaris, OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other
|
||||||
systems compliant with POSIX.1-2008.
|
systems compliant with POSIX.1-2008.
|
||||||
|
|
||||||
|
The origin has been migrated to
|
||||||
|
[GitFlic](https://gitflic.ru/project/erthink/libmdbx) since on 2022-04-15
|
||||||
|
the Github administration, without any warning nor explanation, deleted libmdbx
|
||||||
|
along with a lot of other projects, simultaneously blocking access for many
|
||||||
|
developers. For the same reason ~~Github~~ is blacklisted forever.
|
||||||
|
|
||||||
_The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо._
|
_The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо._
|
||||||
|
|
||||||
|
|
||||||
@@ -4826,26 +4832,26 @@ mdbx_get_datacmp(MDBX_db_flags_t flags);
|
|||||||
/** \brief A callback function used to enumerate the reader lock table.
|
/** \brief A callback function used to enumerate the reader lock table.
|
||||||
* \ingroup c_statinfo
|
* \ingroup c_statinfo
|
||||||
*
|
*
|
||||||
* \param [in] ctx An arbitrary context pointer for the callback.
|
* \param [in] ctx An arbitrary context pointer for the callback.
|
||||||
* \param [in] num The serial number during enumeration,
|
* \param [in] num The serial number during enumeration,
|
||||||
* starting from 1.
|
* starting from 1.
|
||||||
* \param [in] slot The reader lock table slot number.
|
* \param [in] slot The reader lock table slot number.
|
||||||
* \param [in] txnid The ID of the transaction being read,
|
* \param [in] txnid The ID of the transaction being read,
|
||||||
* i.e. the MVCC-snapshot number.
|
* i.e. the MVCC-snapshot number.
|
||||||
* \param [in] lag The lag from a recent MVCC-snapshot,
|
* \param [in] lag The lag from a recent MVCC-snapshot,
|
||||||
* i.e. the number of committed write transactions
|
* i.e. the number of committed write transactions
|
||||||
* since the current read transaction started.
|
* since the current read transaction started.
|
||||||
* \param [in] pid The reader process ID.
|
* \param [in] pid The reader process ID.
|
||||||
* \param [in] thread The reader thread ID.
|
* \param [in] thread The reader thread ID.
|
||||||
* \param [in] bytes_used The number of last used page in the MVCC-snapshot
|
* \param [in] bytes_used The number of last used page
|
||||||
* which being read,
|
* in the MVCC-snapshot which being read,
|
||||||
* i.e. database file can't shrinked beyond this.
|
* i.e. database file can't shrinked beyond this.
|
||||||
* \param [in] bytes_retired The total size of the database pages that were
|
* \param [in] bytes_retained The total size of the database pages that were
|
||||||
* retired by committed write transactions after
|
* retired by committed write transactions after
|
||||||
* the reader's MVCC-snapshot,
|
* the reader's MVCC-snapshot,
|
||||||
* i.e. the space which would be freed after
|
* i.e. the space which would be freed after
|
||||||
* the Reader releases the MVCC-snapshot
|
* the Reader releases the MVCC-snapshot
|
||||||
* for reuse by completion read transaction.
|
* for reuse by completion read transaction.
|
||||||
*
|
*
|
||||||
* \returns < 0 on failure, >= 0 on success. \see mdbx_reader_list() */
|
* \returns < 0 on failure, >= 0 on success. \see mdbx_reader_list() */
|
||||||
typedef int(MDBX_reader_list_func)(void *ctx, int num, int slot, mdbx_pid_t pid,
|
typedef int(MDBX_reader_list_func)(void *ctx, int num, int slot, mdbx_pid_t pid,
|
||||||
|
|||||||
10
mdbx.h++
10
mdbx.h++
@@ -13,6 +13,14 @@
|
|||||||
/// - AppleClang, but without C++20 concepts.
|
/// - AppleClang, but without C++20 concepts.
|
||||||
///
|
///
|
||||||
|
|
||||||
|
///
|
||||||
|
/// The origin has been migrated to https://gitflic.ru/project/erthink/libmdbx
|
||||||
|
/// since on 2022-04-15 the Github administration, without any warning nor
|
||||||
|
/// explanation, deleted libmdbx along with a lot of other projects,
|
||||||
|
/// simultaneously blocking access for many developers.
|
||||||
|
/// For the same reason Github is blacklisted forever.
|
||||||
|
///
|
||||||
|
|
||||||
#pragma once
|
#pragma once
|
||||||
|
|
||||||
/* Workaround for modern libstdc++ with CLANG < 4.x */
|
/* Workaround for modern libstdc++ with CLANG < 4.x */
|
||||||
@@ -256,7 +264,7 @@ namespace mdbx {
|
|||||||
// To enable all kinds of an compiler optimizations we use a byte-like type
|
// To enable all kinds of an compiler optimizations we use a byte-like type
|
||||||
// that don't presumes aliases for pointers as does the `char` type and its
|
// that don't presumes aliases for pointers as does the `char` type and its
|
||||||
// derivatives/typedefs.
|
// derivatives/typedefs.
|
||||||
// Please see https://github.com/erthink/libmdbx/issues/263
|
// Please see todo4recovery://erased_by_github/libmdbx/issues/263
|
||||||
// for reasoning of the use of `char8_t` type and switching to `__restrict__`.
|
// for reasoning of the use of `char8_t` type and switching to `__restrict__`.
|
||||||
using byte = char8_t;
|
using byte = char8_t;
|
||||||
#else
|
#else
|
||||||
|
|||||||
@@ -9,7 +9,7 @@ This patch adds libmdbx v0.11.1:
|
|||||||
focused on creating unique lightweight solutions.
|
focused on creating unique lightweight solutions.
|
||||||
- libmdbx surpasses the legendary LMDB (Lightning Memory-Mapped Database)
|
- libmdbx surpasses the legendary LMDB (Lightning Memory-Mapped Database)
|
||||||
in terms of reliability, features and performance.
|
in terms of reliability, features and performance.
|
||||||
- https://github.com/erthink/libmdbx
|
- https://gitflic.ru/project/erthink/libmdbx
|
||||||
|
|
||||||
Signed-off-by: Leonid Yuriev <leo@yuriev.ru>
|
Signed-off-by: Leonid Yuriev <leo@yuriev.ru>
|
||||||
Signed-off-by: Yann E. MORIN <yann.morin.1998@free.fr>
|
Signed-off-by: Yann E. MORIN <yann.morin.1998@free.fr>
|
||||||
@@ -71,7 +71,7 @@ index 0000000000..d13f73938f
|
|||||||
+ libmdbx surpasses the legendary LMDB in terms of
|
+ libmdbx surpasses the legendary LMDB in terms of
|
||||||
+ reliability, features and performance.
|
+ reliability, features and performance.
|
||||||
+
|
+
|
||||||
+ https://github.com/erthink/libmdbx
|
+ https://gitflic.ru/project/erthink/libmdbx
|
||||||
+
|
+
|
||||||
+if BR2_PACKAGE_LIBMDBX
|
+if BR2_PACKAGE_LIBMDBX
|
||||||
+
|
+
|
||||||
@@ -107,7 +107,7 @@ index 0000000000..c8b50f9ac3
|
|||||||
--- /dev/null
|
--- /dev/null
|
||||||
+++ b/package/libmdbx/libmdbx.hash
|
+++ b/package/libmdbx/libmdbx.hash
|
||||||
@@ -0,0 +1,5 @@
|
@@ -0,0 +1,5 @@
|
||||||
+# Hashes from: https://github.com/erthink/libmdbx/releases/
|
+# Hashes from: https://gitflic.ru/project/erthink/libmdbx/releases/
|
||||||
+sha256 f954ba8c9768914a92c2b46aac0d66bec674dbb4d7b0f01e362ea2921746ddaa libmdbx-amalgamated-0.11.1.tar.gz
|
+sha256 f954ba8c9768914a92c2b46aac0d66bec674dbb4d7b0f01e362ea2921746ddaa libmdbx-amalgamated-0.11.1.tar.gz
|
||||||
+
|
+
|
||||||
+# Locally calculated
|
+# Locally calculated
|
||||||
@@ -126,7 +126,7 @@ index 0000000000..02d00b1a5a
|
|||||||
+
|
+
|
||||||
+LIBMDBX_VERSION = 0.11.1
|
+LIBMDBX_VERSION = 0.11.1
|
||||||
+LIBMDBX_SOURCE = libmdbx-amalgamated-$(LIBMDBX_VERSION).tar.gz
|
+LIBMDBX_SOURCE = libmdbx-amalgamated-$(LIBMDBX_VERSION).tar.gz
|
||||||
+LIBMDBX_SITE = https://github.com/erthink/libmdbx/releases/download/v$(LIBMDBX_VERSION)
|
+LIBMDBX_SITE = https://gitflic.ru/project/erthink/libmdbx/releases/download/v$(LIBMDBX_VERSION)
|
||||||
+LIBMDBX_SUPPORTS_IN_SOURCE_BUILD = NO
|
+LIBMDBX_SUPPORTS_IN_SOURCE_BUILD = NO
|
||||||
+LIBMDBX_LICENSE = OLDAP-2.8
|
+LIBMDBX_LICENSE = OLDAP-2.8
|
||||||
+LIBMDBX_LICENSE_FILES = LICENSE
|
+LIBMDBX_LICENSE_FILES = LICENSE
|
||||||
|
|||||||
25
src/core.c
25
src/core.c
@@ -5058,7 +5058,7 @@ static int mdbx_iov_write(MDBX_txn *const txn, struct mdbx_iov_ctx *ctx) {
|
|||||||
MDBX_page *wp = (MDBX_page *)ctx->iov[i].iov_base;
|
MDBX_page *wp = (MDBX_page *)ctx->iov[i].iov_base;
|
||||||
const MDBX_page *rp = pgno2page(txn->mt_env, wp->mp_pgno);
|
const MDBX_page *rp = pgno2page(txn->mt_env, wp->mp_pgno);
|
||||||
/* check with timeout as the workaround
|
/* check with timeout as the workaround
|
||||||
* for https://github.com/erthink/libmdbx/issues/269 */
|
* for todo4recovery://erased_by_github/libmdbx/issues/269 */
|
||||||
while (likely(rc == MDBX_SUCCESS) &&
|
while (likely(rc == MDBX_SUCCESS) &&
|
||||||
unlikely(memcmp(wp, rp, ctx->iov[i].iov_len) != 0)) {
|
unlikely(memcmp(wp, rp, ctx->iov[i].iov_len) != 0)) {
|
||||||
if (!timestamp) {
|
if (!timestamp) {
|
||||||
@@ -6400,7 +6400,7 @@ __hot static struct page_result mdbx_page_alloc(MDBX_cursor *mc,
|
|||||||
catch-up with itself by growing while trying to save it. */
|
catch-up with itself by growing while trying to save it. */
|
||||||
(mc->mc_flags & C_RECLAIMING) ||
|
(mc->mc_flags & C_RECLAIMING) ||
|
||||||
/* avoid (recursive) search inside empty tree and while tree is
|
/* avoid (recursive) search inside empty tree and while tree is
|
||||||
updating, https://github.com/erthink/libmdbx/issues/31 */
|
updating, todo4recovery://erased_by_github/libmdbx/issues/31 */
|
||||||
txn->mt_dbs[FREE_DBI].md_entries == 0 ||
|
txn->mt_dbs[FREE_DBI].md_entries == 0 ||
|
||||||
/* If our dirty list is already full, we can't touch GC */
|
/* If our dirty list is already full, we can't touch GC */
|
||||||
(txn->tw.dirtyroom < txn->mt_dbs[FREE_DBI].md_depth &&
|
(txn->tw.dirtyroom < txn->mt_dbs[FREE_DBI].md_depth &&
|
||||||
@@ -6613,7 +6613,8 @@ no_loose:
|
|||||||
MDBX_PGL_LIMIT)) {
|
MDBX_PGL_LIMIT)) {
|
||||||
/* Stop reclaiming to avoid overflow the page list.
|
/* Stop reclaiming to avoid overflow the page list.
|
||||||
* This is a rare case while search for a continuously multi-page region
|
* This is a rare case while search for a continuously multi-page region
|
||||||
* in a large database. https://github.com/erthink/libmdbx/issues/123 */
|
* in a large database.
|
||||||
|
* todo4recovery://erased_by_github/libmdbx/issues/123 */
|
||||||
mdbx_notice("stop reclaiming to avoid PNL overflow: %u (current) + %u "
|
mdbx_notice("stop reclaiming to avoid PNL overflow: %u (current) + %u "
|
||||||
"(chunk) -> %u",
|
"(chunk) -> %u",
|
||||||
MDBX_PNL_SIZE(txn->tw.reclaimed_pglist), gc_len,
|
MDBX_PNL_SIZE(txn->tw.reclaimed_pglist), gc_len,
|
||||||
@@ -7586,7 +7587,7 @@ __cold int mdbx_thread_unregister(const MDBX_env *env) {
|
|||||||
return MDBX_SUCCESS;
|
return MDBX_SUCCESS;
|
||||||
}
|
}
|
||||||
|
|
||||||
/* check against https://github.com/erthink/libmdbx/issues/269 */
|
/* check against todo4recovery://erased_by_github/libmdbx/issues/269 */
|
||||||
static bool meta_checktxnid(const MDBX_env *env, const MDBX_meta *meta,
|
static bool meta_checktxnid(const MDBX_env *env, const MDBX_meta *meta,
|
||||||
bool report) {
|
bool report) {
|
||||||
const txnid_t meta_txnid = constmeta_txnid(env, meta);
|
const txnid_t meta_txnid = constmeta_txnid(env, meta);
|
||||||
@@ -7662,7 +7663,7 @@ static bool meta_checktxnid(const MDBX_env *env, const MDBX_meta *meta,
|
|||||||
}
|
}
|
||||||
|
|
||||||
/* check with timeout as the workaround
|
/* check with timeout as the workaround
|
||||||
* for https://github.com/erthink/libmdbx/issues/269 */
|
* for todo4recovery://erased_by_github/libmdbx/issues/269 */
|
||||||
static int meta_waittxnid(const MDBX_env *env, const MDBX_meta *meta,
|
static int meta_waittxnid(const MDBX_env *env, const MDBX_meta *meta,
|
||||||
uint64_t *timestamp) {
|
uint64_t *timestamp) {
|
||||||
if (likely(meta_checktxnid(env, (const MDBX_meta *)meta, !*timestamp)))
|
if (likely(meta_checktxnid(env, (const MDBX_meta *)meta, !*timestamp)))
|
||||||
@@ -7807,7 +7808,8 @@ static int mdbx_txn_renew0(MDBX_txn *txn, const unsigned flags) {
|
|||||||
snap == meta_txnid(env, meta) &&
|
snap == meta_txnid(env, meta) &&
|
||||||
snap >= atomic_load64(&env->me_lck->mti_oldest_reader,
|
snap >= atomic_load64(&env->me_lck->mti_oldest_reader,
|
||||||
mo_AcquireRelease))) {
|
mo_AcquireRelease))) {
|
||||||
/* workaround for https://github.com/erthink/libmdbx/issues/269 */
|
/* workaround for todo4recovery://erased_by_github/libmdbx/issues/269
|
||||||
|
*/
|
||||||
rc = meta_waittxnid(env, (const MDBX_meta *)meta, ×tamp);
|
rc = meta_waittxnid(env, (const MDBX_meta *)meta, ×tamp);
|
||||||
mdbx_jitter4testing(false);
|
mdbx_jitter4testing(false);
|
||||||
if (likely(rc == MDBX_SUCCESS))
|
if (likely(rc == MDBX_SUCCESS))
|
||||||
@@ -7895,7 +7897,8 @@ static int mdbx_txn_renew0(MDBX_txn *txn, const unsigned flags) {
|
|||||||
mdbx_jitter4testing(false);
|
mdbx_jitter4testing(false);
|
||||||
const MDBX_meta *meta = constmeta_prefer_last(env);
|
const MDBX_meta *meta = constmeta_prefer_last(env);
|
||||||
uint64_t timestamp = 0;
|
uint64_t timestamp = 0;
|
||||||
while ("workaround for https://github.com/erthink/libmdbx/issues/269") {
|
while (
|
||||||
|
"workaround for todo4recovery://erased_by_github/libmdbx/issues/269") {
|
||||||
rc = meta_waittxnid(env, (const MDBX_meta *)meta, ×tamp);
|
rc = meta_waittxnid(env, (const MDBX_meta *)meta, ×tamp);
|
||||||
if (likely(rc == MDBX_SUCCESS))
|
if (likely(rc == MDBX_SUCCESS))
|
||||||
break;
|
break;
|
||||||
@@ -11722,7 +11725,8 @@ mdbx_env_set_geometry(MDBX_env *env, intptr_t size_lower, intptr_t size_now,
|
|||||||
const MDBX_meta *head = constmeta_prefer_last(env);
|
const MDBX_meta *head = constmeta_prefer_last(env);
|
||||||
|
|
||||||
uint64_t timestamp = 0;
|
uint64_t timestamp = 0;
|
||||||
while ("workaround for https://github.com/erthink/libmdbx/issues/269") {
|
while ("workaround for "
|
||||||
|
"todo4recovery://erased_by_github/libmdbx/issues/269") {
|
||||||
meta = *head;
|
meta = *head;
|
||||||
rc = meta_waittxnid(env, &meta, ×tamp);
|
rc = meta_waittxnid(env, &meta, ×tamp);
|
||||||
if (likely(rc == MDBX_SUCCESS))
|
if (likely(rc == MDBX_SUCCESS))
|
||||||
@@ -12985,7 +12989,7 @@ __cold int mdbx_env_open(MDBX_env *env, const char *pathname,
|
|||||||
} else {
|
} else {
|
||||||
#if MDBX_MMAP_INCOHERENT_FILE_WRITE
|
#if MDBX_MMAP_INCOHERENT_FILE_WRITE
|
||||||
/* Temporary `workaround` for OpenBSD kernel's flaw.
|
/* Temporary `workaround` for OpenBSD kernel's flaw.
|
||||||
* See https://github.com/erthink/libmdbx/issues/67 */
|
* See todo4recovery://erased_by_github/libmdbx/issues/67 */
|
||||||
if ((flags & MDBX_WRITEMAP) == 0) {
|
if ((flags & MDBX_WRITEMAP) == 0) {
|
||||||
if (flags & MDBX_ACCEDE)
|
if (flags & MDBX_ACCEDE)
|
||||||
flags |= MDBX_WRITEMAP;
|
flags |= MDBX_WRITEMAP;
|
||||||
@@ -19944,7 +19948,8 @@ __cold static int fetch_envinfo_ex(const MDBX_env *env, const MDBX_txn *txn,
|
|||||||
const size_t size_before_bootid = offsetof(MDBX_envinfo, mi_bootid);
|
const size_t size_before_bootid = offsetof(MDBX_envinfo, mi_bootid);
|
||||||
const size_t size_before_pgop_stat = offsetof(MDBX_envinfo, mi_pgop_stat);
|
const size_t size_before_pgop_stat = offsetof(MDBX_envinfo, mi_pgop_stat);
|
||||||
|
|
||||||
/* is the environment open? (https://github.com/erthink/libmdbx/issues/171) */
|
/* is the environment open?
|
||||||
|
* (todo4recovery://erased_by_github/libmdbx/issues/171) */
|
||||||
if (unlikely(!env->me_map)) {
|
if (unlikely(!env->me_map)) {
|
||||||
/* environment not yet opened */
|
/* environment not yet opened */
|
||||||
#if 1
|
#if 1
|
||||||
|
|||||||
@@ -96,4 +96,4 @@ if no quiet mode was requested.
|
|||||||
.BR mdbx_load (1)
|
.BR mdbx_load (1)
|
||||||
.BR mdbx_drop (1)
|
.BR mdbx_drop (1)
|
||||||
.SH AUTHOR
|
.SH AUTHOR
|
||||||
Leonid Yuriev <https://github.com/erthink>
|
Leonid Yuriev <https://gitflic.ru/user/erthink>
|
||||||
|
|||||||
@@ -65,4 +65,4 @@ free during copying cannot be reused until the copy is done.
|
|||||||
.BR mdbx_drop (1)
|
.BR mdbx_drop (1)
|
||||||
.SH AUTHOR
|
.SH AUTHOR
|
||||||
Howard Chu of Symas Corporation <http://www.symas.com>,
|
Howard Chu of Symas Corporation <http://www.symas.com>,
|
||||||
Leonid Yuriev <https://github.com/erthink>
|
Leonid Yuriev <https://gitflic.ru/user/erthink>
|
||||||
|
|||||||
@@ -91,4 +91,4 @@ utility to load the database using the correct comparison functions.
|
|||||||
.BR mdbx_drop (1)
|
.BR mdbx_drop (1)
|
||||||
.SH AUTHOR
|
.SH AUTHOR
|
||||||
Howard Chu of Symas Corporation <http://www.symas.com>,
|
Howard Chu of Symas Corporation <http://www.symas.com>,
|
||||||
Leonid Yuriev <https://github.com/erthink>
|
Leonid Yuriev <https://gitflic.ru/user/erthink>
|
||||||
|
|||||||
@@ -102,4 +102,4 @@ a diagnostic message being written to standard error.
|
|||||||
.BR mdbx_drop (1)
|
.BR mdbx_drop (1)
|
||||||
.SH AUTHOR
|
.SH AUTHOR
|
||||||
Howard Chu of Symas Corporation <http://www.symas.com>,
|
Howard Chu of Symas Corporation <http://www.symas.com>,
|
||||||
Leonid Yuriev <https://github.com/erthink>
|
Leonid Yuriev <https://gitflic.ru/user/erthink>
|
||||||
|
|||||||
@@ -83,4 +83,4 @@ a diagnostic message being written to standard error.
|
|||||||
.BR mdbx_drop (1)
|
.BR mdbx_drop (1)
|
||||||
.SH AUTHOR
|
.SH AUTHOR
|
||||||
Howard Chu of Symas Corporation <http://www.symas.com>,
|
Howard Chu of Symas Corporation <http://www.symas.com>,
|
||||||
Leonid Yuriev <https://github.com/erthink>
|
Leonid Yuriev <https://gitflic.ru/user/erthink>
|
||||||
|
|||||||
@@ -1157,7 +1157,7 @@ int main(int argc, char *argv[]) {
|
|||||||
envflags &= ~MDBX_RDONLY;
|
envflags &= ~MDBX_RDONLY;
|
||||||
#if MDBX_MMAP_INCOHERENT_FILE_WRITE
|
#if MDBX_MMAP_INCOHERENT_FILE_WRITE
|
||||||
/* Temporary `workaround` for OpenBSD kernel's flaw.
|
/* Temporary `workaround` for OpenBSD kernel's flaw.
|
||||||
* See https://github.com/erthink/libmdbx/issues/67 */
|
* See todo4recovery://erased_by_github/libmdbx/issues/67 */
|
||||||
envflags |= MDBX_WRITEMAP;
|
envflags |= MDBX_WRITEMAP;
|
||||||
#endif /* MDBX_MMAP_INCOHERENT_FILE_WRITE */
|
#endif /* MDBX_MMAP_INCOHERENT_FILE_WRITE */
|
||||||
break;
|
break;
|
||||||
|
|||||||
17
src/osal.c
17
src/osal.c
@@ -678,7 +678,7 @@ MDBX_INTERNAL_FUNC int mdbx_openfile(const enum mdbx_openfile_purpose purpose,
|
|||||||
flags |= O_CLOEXEC;
|
flags |= O_CLOEXEC;
|
||||||
#endif /* O_CLOEXEC */
|
#endif /* O_CLOEXEC */
|
||||||
|
|
||||||
/* Safeguard for https://github.com/erthink/libmdbx/issues/144 */
|
/* Safeguard for todo4recovery://erased_by_github/libmdbx/issues/144 */
|
||||||
#if STDIN_FILENO == 0 && STDOUT_FILENO == 1 && STDERR_FILENO == 2
|
#if STDIN_FILENO == 0 && STDOUT_FILENO == 1 && STDERR_FILENO == 2
|
||||||
int stub_fd0 = -1, stub_fd1 = -1, stub_fd2 = -1;
|
int stub_fd0 = -1, stub_fd1 = -1, stub_fd2 = -1;
|
||||||
static const char dev_null[] = "/dev/null";
|
static const char dev_null[] = "/dev/null";
|
||||||
@@ -710,7 +710,7 @@ MDBX_INTERNAL_FUNC int mdbx_openfile(const enum mdbx_openfile_purpose purpose,
|
|||||||
}
|
}
|
||||||
#endif /* O_DIRECT */
|
#endif /* O_DIRECT */
|
||||||
|
|
||||||
/* Safeguard for https://github.com/erthink/libmdbx/issues/144 */
|
/* Safeguard for todo4recovery://erased_by_github/libmdbx/issues/144 */
|
||||||
#if STDIN_FILENO == 0 && STDOUT_FILENO == 1 && STDERR_FILENO == 2
|
#if STDIN_FILENO == 0 && STDOUT_FILENO == 1 && STDERR_FILENO == 2
|
||||||
if (*fd == STDIN_FILENO) {
|
if (*fd == STDIN_FILENO) {
|
||||||
mdbx_warning("Got STD%s_FILENO/%d, avoid using it by dup(fd)", "IN",
|
mdbx_warning("Got STD%s_FILENO/%d, avoid using it by dup(fd)", "IN",
|
||||||
@@ -1547,7 +1547,8 @@ MDBX_INTERNAL_FUNC int mdbx_munmap(mdbx_mmap_t *map) {
|
|||||||
VALGRIND_MAKE_MEM_NOACCESS(map->address, map->current);
|
VALGRIND_MAKE_MEM_NOACCESS(map->address, map->current);
|
||||||
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
||||||
* when this memory will re-used by malloc or another mmapping.
|
* when this memory will re-used by malloc or another mmapping.
|
||||||
* See https://github.com/erthink/libmdbx/pull/93#issuecomment-613687203 */
|
* See todo4recovery://erased_by_github/libmdbx/pull/93#issuecomment-613687203
|
||||||
|
*/
|
||||||
MDBX_ASAN_UNPOISON_MEMORY_REGION(map->address,
|
MDBX_ASAN_UNPOISON_MEMORY_REGION(map->address,
|
||||||
(map->filesize && map->filesize < map->limit)
|
(map->filesize && map->filesize < map->limit)
|
||||||
? map->filesize
|
? map->filesize
|
||||||
@@ -1623,7 +1624,8 @@ MDBX_INTERNAL_FUNC int mdbx_mresize(const int flags, mdbx_mmap_t *map,
|
|||||||
|
|
||||||
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
||||||
* when this memory will re-used by malloc or another mmapping.
|
* when this memory will re-used by malloc or another mmapping.
|
||||||
* See https://github.com/erthink/libmdbx/pull/93#issuecomment-613687203 */
|
* See todo4recovery://erased_by_github/libmdbx/pull/93#issuecomment-613687203
|
||||||
|
*/
|
||||||
MDBX_ASAN_UNPOISON_MEMORY_REGION(map->address, map->limit);
|
MDBX_ASAN_UNPOISON_MEMORY_REGION(map->address, map->limit);
|
||||||
status = NtUnmapViewOfSection(GetCurrentProcess(), map->address);
|
status = NtUnmapViewOfSection(GetCurrentProcess(), map->address);
|
||||||
if (!NT_SUCCESS(status))
|
if (!NT_SUCCESS(status))
|
||||||
@@ -1888,7 +1890,8 @@ retry_mapview:;
|
|||||||
VALGRIND_MAKE_MEM_NOACCESS(map->address, map->current);
|
VALGRIND_MAKE_MEM_NOACCESS(map->address, map->current);
|
||||||
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
||||||
* when this memory will re-used by malloc or another mmapping.
|
* when this memory will re-used by malloc or another mmapping.
|
||||||
* See https://github.com/erthink/libmdbx/pull/93#issuecomment-613687203
|
* See
|
||||||
|
* todo4recovery://erased_by_github/libmdbx/pull/93#issuecomment-613687203
|
||||||
*/
|
*/
|
||||||
MDBX_ASAN_UNPOISON_MEMORY_REGION(
|
MDBX_ASAN_UNPOISON_MEMORY_REGION(
|
||||||
map->address,
|
map->address,
|
||||||
@@ -1908,7 +1911,9 @@ retry_mapview:;
|
|||||||
VALGRIND_MAKE_MEM_NOACCESS(map->address, map->current);
|
VALGRIND_MAKE_MEM_NOACCESS(map->address, map->current);
|
||||||
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
/* Unpoisoning is required for ASAN to avoid false-positive diagnostic
|
||||||
* when this memory will re-used by malloc or another mmapping.
|
* when this memory will re-used by malloc or another mmapping.
|
||||||
* See https://github.com/erthink/libmdbx/pull/93#issuecomment-613687203 */
|
* See
|
||||||
|
* todo4recovery://erased_by_github/libmdbx/pull/93#issuecomment-613687203
|
||||||
|
*/
|
||||||
MDBX_ASAN_UNPOISON_MEMORY_REGION(
|
MDBX_ASAN_UNPOISON_MEMORY_REGION(
|
||||||
map->address, (map->current < map->limit) ? map->current : map->limit);
|
map->address, (map->current < map->limit) ? map->current : map->limit);
|
||||||
|
|
||||||
|
|||||||
@@ -31,7 +31,7 @@
|
|||||||
fun:mdbx_wipe_steady
|
fun:mdbx_wipe_steady
|
||||||
}
|
}
|
||||||
|
|
||||||
# memcmp() inside mdbx_iov_write() as workaround for https://github.com/erthink/libmdbx/issues/269
|
# memcmp() inside mdbx_iov_write() as workaround for todo4recovery://erased_by_github/libmdbx/issues/269
|
||||||
{
|
{
|
||||||
write-page-check-bcmp
|
write-page-check-bcmp
|
||||||
Memcheck:Cond
|
Memcheck:Cond
|
||||||
|
|||||||
Reference in New Issue
Block a user