mirror of
https://github.com/isar/libmdbx.git
synced 2026-02-17 10:49:13 +08:00
mdbx-doc: provide non-API docs via doxygen (squashed).
Change-Id: Ie33858517f964f794ec182a1e8bb630730a0f172
This commit is contained in:
58
AUTHORS
58
AUTHORS
@@ -1,32 +1,32 @@
|
||||
Contributors
|
||||
============
|
||||
|
||||
Alexey Naumov <alexey.naumov@gmail.com>
|
||||
Chris Mikkelson <cmikk@qwest.net>
|
||||
Claude Brisson <claude.brisson@gmail.com>
|
||||
David Barbour <dmbarbour@gmail.com>
|
||||
David Wilson <dw@botanicus.net>
|
||||
dreamsxin <dreamsxin@126.com>
|
||||
Hallvard Furuseth <hallvard@openldap.org>, <h.b.furuseth@usit.uio.no>
|
||||
Heiko Becker <heirecka@exherbo.org>
|
||||
Howard Chu <hyc@openldap.org>, <hyc@symas.com>
|
||||
Ignacio Casal Quinteiro <ignacio.casal@nice-software.com>
|
||||
James Rouzier <rouzier@gmail.com>
|
||||
Jean-Christophe DUBOIS <jcd@tribudubois.net>
|
||||
John Hewson <john@jahewson.com>
|
||||
Klaus Malorny <klaus.malorny@knipp.de>
|
||||
Kurt Zeilenga <kurt.zeilenga@isode.com>
|
||||
Leonid Yuriev <leo@yuriev.ru>, <lyuryev@ptsecurity.com>
|
||||
Lorenz Bauer <lmb@cloudflare.com>
|
||||
Luke Yeager <lyeager@nvidia.com>
|
||||
Martin Hedenfalk <martin@bzero.se>
|
||||
Ondrej Kuznik <ondrej.kuznik@acision.com>
|
||||
Orivej Desh <orivej@gmx.fr>
|
||||
Oskari Timperi <oskari.timperi@iki.fi>
|
||||
Pavel Medvedev <pmedvedev@gmail.com>
|
||||
Philipp Storz <philipp.storz@bareos.com>
|
||||
Quanah Gibson-Mount <quanah@openldap.org>
|
||||
Salvador Ortiz <sog@msg.com.mx>
|
||||
Sebastien Launay <sebastien@slaunay.fr>
|
||||
Vladimir Romanov <vromanov@gmail.com>
|
||||
Zano Foundation <crypto.sowle@gmail.com>
|
||||
- Alexey Naumov <alexey.naumov@gmail.com>
|
||||
- Chris Mikkelson <cmikk@qwest.net>
|
||||
- Claude Brisson <claude.brisson@gmail.com>
|
||||
- David Barbour <dmbarbour@gmail.com>
|
||||
- David Wilson <dw@botanicus.net>
|
||||
- dreamsxin <dreamsxin@126.com>
|
||||
- Hallvard Furuseth <hallvard@openldap.org>, <h.b.furuseth@usit.uio.no>
|
||||
- Heiko Becker <heirecka@exherbo.org>
|
||||
- Howard Chu <hyc@openldap.org>, <hyc@symas.com>
|
||||
- Ignacio Casal Quinteiro <ignacio.casal@nice-software.com>
|
||||
- James Rouzier <rouzier@gmail.com>
|
||||
- Jean-Christophe DUBOIS <jcd@tribudubois.net>
|
||||
- John Hewson <john@jahewson.com>
|
||||
- Klaus Malorny <klaus.malorny@knipp.de>
|
||||
- Kurt Zeilenga <kurt.zeilenga@isode.com>
|
||||
- Leonid Yuriev <leo@yuriev.ru>, <lyuryev@ptsecurity.com>
|
||||
- Lorenz Bauer <lmb@cloudflare.com>
|
||||
- Luke Yeager <lyeager@nvidia.com>
|
||||
- Martin Hedenfalk <martin@bzero.se>
|
||||
- Ondrej Kuznik <ondrej.kuznik@acision.com>
|
||||
- Orivej Desh <orivej@gmx.fr>
|
||||
- Oskari Timperi <oskari.timperi@iki.fi>
|
||||
- Pavel Medvedev <pmedvedev@gmail.com>
|
||||
- Philipp Storz <philipp.storz@bareos.com>
|
||||
- Quanah Gibson-Mount <quanah@openldap.org>
|
||||
- Salvador Ortiz <sog@msg.com.mx>
|
||||
- Sebastien Launay <sebastien@slaunay.fr>
|
||||
- Vladimir Romanov <vromanov@gmail.com>
|
||||
- Zano Foundation <crypto.sowle@gmail.com>
|
||||
|
||||
20
GNUmakefile
20
GNUmakefile
@@ -254,8 +254,24 @@ docs/Doxyfile: docs/Doxyfile.in src/version.c
|
||||
-e "s|\$${MDBX_VERSION_REVISION}|$(MDBX_GIT_REVISION)|" \
|
||||
docs/Doxyfile.in > $@
|
||||
|
||||
doxygen: docs/Doxyfile mdbx.h LICENSE AUTHORS
|
||||
rm -rf docs/html && mkdir -p docs/html && cp LICENSE AUTHORS docs/html/ && doxygen docs/Doxyfile
|
||||
define md-extract-section
|
||||
docs/__$(1).md: $(2)
|
||||
sed -n '/<!-- section-begin $(1) -->/,/<!-- section-end -->/p' $$< > $$@ && test -s $$@
|
||||
|
||||
endef
|
||||
$(foreach section,overview mithril characteristics improvements history usage performance bindings,$(eval $(call md-extract-section,$(section),README.md)))
|
||||
|
||||
docs/overall.md: docs/__overview.md docs/_toc.md docs/__mithril.md docs/__history.md AUTHORS LICENSE
|
||||
echo -e "\\mainpage Overall\n\\section brief Brief" | cat - $(filter %.md, $?) > $@ && echo -e "\n\n\nLicense\n=======\n" | cat AUTHORS - LICENSE >> $@
|
||||
|
||||
docs/intro.md: docs/_preface.md docs/__characteristics.md docs/__improvements.md docs/_restrictions.md docs/__performance.md
|
||||
cat $? | sed 's/^Performance comparison$$/Performance comparison {#performance}/' > $@
|
||||
|
||||
docs/usage.md: docs/__usage.md docs/_starting.md docs/__bindings.md
|
||||
echo -e "\\page usage Usage\n\\section getting Getting the libmdbx" | cat - $? | sed 's/^Bindings$$/Bindings {#bindings}/' > $@
|
||||
|
||||
doxygen: docs/Doxyfile docs/overall.md docs/intro.md docs/usage.md mdbx.h ChangeLog.md
|
||||
rm -rf docs/html && cp mdbx.h ChangeLog.md docs/ && (cd docs && doxygen Doxyfile)
|
||||
|
||||
.PHONY: dist release-assets
|
||||
dist: libmdbx-sources-$(MDBX_VERSION_SUFFIX).tar.gz $(lastword $(MAKEFILE_LIST))
|
||||
|
||||
78
README.md
78
README.md
@@ -1,13 +1,14 @@
|
||||
<!-- Required extensions: pymdownx.betterem, pymdownx.tilde, pymdownx.emoji, pymdownx.tasklist, pymdownx.superfences -->
|
||||
|
||||
libmdbx
|
||||
=======
|
||||
========
|
||||
|
||||
<!-- section-begin overview -->
|
||||
_libmdbx_ is an extremely fast, compact, powerful, embedded,
|
||||
transactional [key-value store](https://en.wikipedia.org/wiki/Key-value_database)
|
||||
database, with [permissive license](LICENSE).
|
||||
transactional [key-value database](https://en.wikipedia.org/wiki/Key-value_database),
|
||||
with [permissive license](./LICENSE).
|
||||
_MDBX_ has a specific set of properties and capabilities,
|
||||
focused on creating unique lightweight solutions with extraordinary performance.
|
||||
focused on creating unique lightweight solutions.
|
||||
|
||||
1. Allows **a swarm of multi-threaded processes to
|
||||
[ACID]((https://en.wikipedia.org/wiki/ACID))ly read and update** several
|
||||
@@ -43,13 +44,15 @@ neglected in favour of write performance.
|
||||
7. Supports Linux, Windows, MacOS, Android, iOS, FreeBSD, DragonFly, Solaris,
|
||||
OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with
|
||||
**POSIX.1-2008**.
|
||||
<!-- section-end -->
|
||||
|
||||
Historically, _MDBX_ is a deeply revised and extended descendant of the amazing
|
||||
[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
_MDBX_ inherits all benefits from _LMDB_, but resolves some issues and adds [a set of improvements](#improvements-beyond-lmdb).
|
||||
|
||||
<!-- section-begin mithril -->
|
||||
The next version is under active non-public development from scratch and will be
|
||||
released as **_MithrilDB_** and `libmithrildb` for libraries & packages.
|
||||
released as _**MithrilDB**_ and `libmithrildb` for libraries & packages.
|
||||
Admittedly mythical [Mithril](https://en.wikipedia.org/wiki/Mithril) is
|
||||
resembling silver but being stronger and lighter than steel. Therefore
|
||||
_MithrilDB_ is a rightly relevant name.
|
||||
@@ -58,6 +61,7 @@ _MithrilDB_ is a rightly relevant name.
|
||||
> License](https://www.apache.org/licenses/LICENSE-2.0). The goal of this
|
||||
> revolution is to provide a clearer and robust API, add more features and
|
||||
> new valuable properties of the database.
|
||||
<!-- section-end -->
|
||||
|
||||
[](https://t.me/libmdbx)
|
||||
[](https://travis-ci.org/erthink/libmdbx)
|
||||
@@ -71,10 +75,10 @@ _MithrilDB_ is a rightly relevant name.
|
||||
-----
|
||||
|
||||
## Table of Contents
|
||||
- [Overview](#overview)
|
||||
- [Characteristics](#characteristics)
|
||||
- [Features](#features)
|
||||
- [Limitations](#limitations)
|
||||
- [Caveats & Gotchas](#caveats--gotchas)
|
||||
- [Gotchas](#gotchas)
|
||||
- [Comparison with other databases](#comparison-with-other-databases)
|
||||
- [Improvements beyond LMDB](#improvements-beyond-lmdb)
|
||||
- [History & Acknowledgments](#history)
|
||||
@@ -90,7 +94,9 @@ _MithrilDB_ is a rightly relevant name.
|
||||
- [Async-write mode](#async-write-mode)
|
||||
- [Cost comparison](#cost-comparison)
|
||||
|
||||
# Overview
|
||||
# Characteristics
|
||||
|
||||
<!-- section-begin characteristics -->
|
||||
|
||||
## Features
|
||||
|
||||
@@ -146,7 +152,7 @@ transaction journal. No crash recovery needed. No maintenance is required.
|
||||
- **Database size**: up to `2147483648` pages (8 [TiB](https://en.wikipedia.org/wiki/Tebibyte) for default 4K pagesize, 128 [TiB](https://en.wikipedia.org/wiki/Tebibyte) for 64K pagesize).
|
||||
- **Maximum sub-databases**: `32765`.
|
||||
|
||||
## Caveats & Gotchas
|
||||
## Gotchas
|
||||
|
||||
1. There cannot be more than one writer at a time, i.e. no more than one write transaction at a time.
|
||||
|
||||
@@ -165,11 +171,14 @@ so you should reconsider using brute force techniques and double check your code
|
||||
On the one hand, in the case of MDBX, a simple linear search may be more profitable than complex indexes.
|
||||
On the other hand, if you make something suboptimally, you can notice detrimentally only on sufficiently large data.
|
||||
|
||||
### Comparison with other databases
|
||||
## Comparison with other databases
|
||||
For now please refer to [chapter of "BoltDB comparison with other
|
||||
databases"](https://github.com/coreos/bbolt#comparison-with-other-databases)
|
||||
which is also (mostly) applicable to _libmdbx_.
|
||||
|
||||
<!-- section-end -->
|
||||
<!-- section-begin improvements -->
|
||||
|
||||
Improvements beyond LMDB
|
||||
========================
|
||||
|
||||
@@ -180,7 +189,7 @@ out-of-the-box, not silently and catastrophically break down. The list
|
||||
below is pruned down to the improvements most notable and obvious from
|
||||
the user's point of view.
|
||||
|
||||
### Added Features:
|
||||
## Added Features
|
||||
|
||||
1. Keys could be more than 2 times longer than _LMDB_.
|
||||
> For DB with default page size _libmdbx_ support keys up to 1300 bytes
|
||||
@@ -230,7 +239,7 @@ and/or optimize query execution plans.
|
||||
|
||||
12. Support for opening databases in the exclusive mode, including on a network share.
|
||||
|
||||
### Added Abilities:
|
||||
## Added Abilities
|
||||
|
||||
1. Zero-length for keys and values.
|
||||
|
||||
@@ -248,7 +257,7 @@ pair, to the first, to the last, or not set to anything.
|
||||
> _libmdbx_ allows one _at once_ with getting previous value
|
||||
> and addressing the particular item from multi-value with the same key.
|
||||
|
||||
### Other fixes and specifics:
|
||||
## Other fixes and specifics
|
||||
|
||||
1. Fixed more than 10 significant errors, in particular: page leaks, wrong sub-database statistics, segfault in several conditions, nonoptimal page merge strategy, updating an existing record with a change in data size (including for multimap), etc.
|
||||
|
||||
@@ -282,7 +291,13 @@ against incompetent user actions (aka
|
||||
_libmdbx_ may be a little lag in performance tests from LMDB where the
|
||||
named mutexes are used.
|
||||
|
||||
### History
|
||||
<!-- section-end -->
|
||||
<!-- section-begin history -->
|
||||
|
||||
# History
|
||||
|
||||
Historically, _MDBX_ is a deeply revised and extended descendant of the
|
||||
[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
At first the development was carried out within the
|
||||
[ReOpenLDAP](https://github.com/erthink/ReOpenLDAP) project. About a
|
||||
year later _libmdbx_ was separated into a standalone project, which was
|
||||
@@ -292,18 +307,26 @@ conference](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
Since 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/erthink/libfpta),
|
||||
and development is funded by [Positive Technologies](https://www.ptsecurity.com).
|
||||
|
||||
### Acknowledgments
|
||||
## Acknowledgments
|
||||
Howard Chu <hyc@openldap.org> is the author of LMDB, from which
|
||||
originated the MDBX in 2015.
|
||||
|
||||
Martin Hedenfalk <martin@bzero.se> is the author of `btree.c` code, which
|
||||
was used to begin development of LMDB.
|
||||
|
||||
<!-- section-end -->
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Usage
|
||||
=====
|
||||
|
||||
<!-- section-begin usage -->
|
||||
Currently, libmdbx is only available in a
|
||||
[source code](https://en.wikipedia.org/wiki/Source_code) form.
|
||||
Packages support for common Linux distributions is planned in the future,
|
||||
since release the version 1.0.
|
||||
|
||||
## Source code embedding
|
||||
|
||||
_libmdbx_ provides two official ways for integration in source code form:
|
||||
@@ -316,7 +339,7 @@ _libmdbx_ provides two official ways for integration in source code form:
|
||||
> This allows you to build as _libmdbx_ and testing tool.
|
||||
> On the other hand, this way requires you to pull git tags, and use C++11 compiler for test tool.
|
||||
|
||||
**_Please, avoid using any other techniques._** Otherwise, at least
|
||||
_**Please, avoid using any other techniques.**_ Otherwise, at least
|
||||
don't ask for support and don't name such chimeras `libmdbx`.
|
||||
|
||||
The amalgamated source code could be created from the original clone of git
|
||||
@@ -434,21 +457,30 @@ To build _libmdbx_ for iOS, we recommend using CMake with the
|
||||
"[toolchain file](https://cmake.org/cmake/help/latest/variable/CMAKE_TOOLCHAIN_FILE.html)"
|
||||
from the [ios-cmake](https://github.com/leetal/ios-cmake) project.
|
||||
|
||||
<!-- section-end -->
|
||||
|
||||
## API description
|
||||
For more information and API description see the [mdbx.h](mdbx.h) header.
|
||||
Please do not hesitate to point out errors in the documentation,
|
||||
including creating [PR](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/proposing-changes-to-your-work-with-pull-requests) with corrections and improvements.
|
||||
|
||||
## Bindings
|
||||
<!-- section-begin bindings -->
|
||||
|
||||
| Runtime | GitHub | Author |
|
||||
| -------- | ------ | ------ |
|
||||
| Rust | [mdbx-rs](https://github.com/Kerollmops/mdbx-rs) | [@Kerollmops](https://github.com/Kerollmops) |
|
||||
| Java | [mdbxjni](https://github.com/castortech/mdbxjni) | [Castor Technologies](https://castortech.com/) |
|
||||
| .NET | [mdbx.NET](https://github.com/wangjia184/mdbx.NET) | [Jerry Wang](https://github.com/wangjia184) |
|
||||
Bindings
|
||||
========
|
||||
|
||||
| Runtime | GitHub | Author |
|
||||
| ------- | ------ | ------ |
|
||||
| Rust | [mdbx-rs](https://github.com/Kerollmops/mdbx-rs) | [Clément Renault](https://github.com/Kerollmops) |
|
||||
| Java | [mdbxjni](https://github.com/castortech/mdbxjni) | [Castor Technologies](https://castortech.com/) |
|
||||
| .NET | [mdbx.NET](https://github.com/wangjia184/mdbx.NET) | [Jerry Wang](https://github.com/wangjia184) |
|
||||
|
||||
<!-- section-end -->
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
<!-- section-begin performance -->
|
||||
|
||||
Performance comparison
|
||||
======================
|
||||
|
||||
@@ -585,6 +617,8 @@ syscall and by scanning the data directory.
|
||||
|
||||
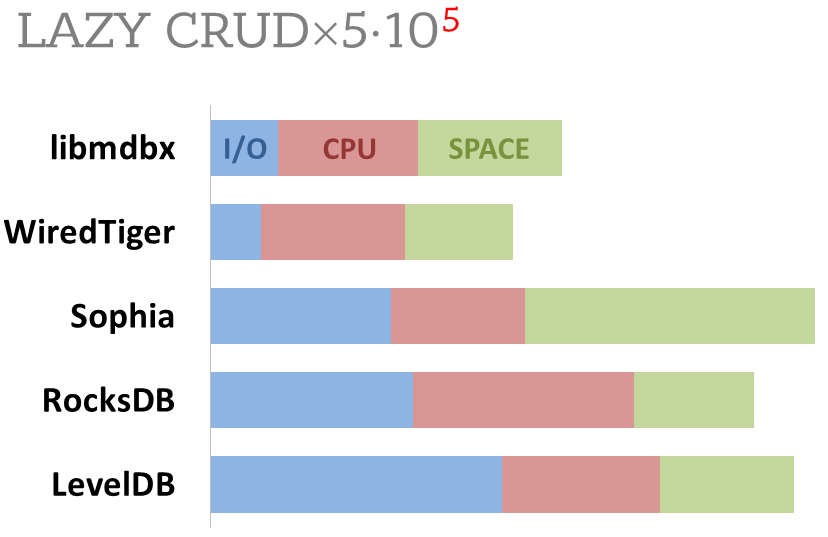
|
||||
|
||||
<!-- section-end -->
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
#### This is a mirror of the origin repository that was moved to [abf.io](https://abf.io/erthink/) because of discriminatory restrictions for Russian Crimea.
|
||||
|
||||
@@ -58,7 +58,7 @@ PROJECT_LOGO =
|
||||
# entered, it will be relative to the location where doxygen was started. If
|
||||
# left blank the current directory will be used.
|
||||
|
||||
OUTPUT_DIRECTORY = docs/
|
||||
OUTPUT_DIRECTORY = .
|
||||
|
||||
# If the CREATE_SUBDIRS tag is set to YES then doxygen will create 4096 sub-
|
||||
# directories (in 2 levels) under the output directory of each output format and
|
||||
@@ -275,7 +275,7 @@ TCL_SUBST =
|
||||
# members will be omitted, etc.
|
||||
# The default value is: NO.
|
||||
|
||||
OPTIMIZE_OUTPUT_FOR_C = NO
|
||||
OPTIMIZE_OUTPUT_FOR_C = YES
|
||||
|
||||
# Set the OPTIMIZE_OUTPUT_JAVA tag to YES if your project consists of Java or
|
||||
# Python sources only. Doxygen will then generate output that is more tailored
|
||||
@@ -467,7 +467,7 @@ LOOKUP_CACHE_SIZE = 0
|
||||
# normally produced when WARNINGS is set to YES.
|
||||
# The default value is: NO.
|
||||
|
||||
EXTRACT_ALL = NO
|
||||
EXTRACT_ALL = YES
|
||||
|
||||
# If the EXTRACT_PRIVATE tag is set to YES, all private members of a class will
|
||||
# be included in the documentation.
|
||||
@@ -661,19 +661,19 @@ STRICT_PROTO_MATCHING = NO
|
||||
# list. This list is created by putting \todo commands in the documentation.
|
||||
# The default value is: YES.
|
||||
|
||||
GENERATE_TODOLIST = YES
|
||||
GENERATE_TODOLIST = NO
|
||||
|
||||
# The GENERATE_TESTLIST tag can be used to enable (YES) or disable (NO) the test
|
||||
# list. This list is created by putting \test commands in the documentation.
|
||||
# The default value is: YES.
|
||||
|
||||
GENERATE_TESTLIST = YES
|
||||
GENERATE_TESTLIST = NO
|
||||
|
||||
# The GENERATE_BUGLIST tag can be used to enable (YES) or disable (NO) the bug
|
||||
# list. This list is created by putting \bug commands in the documentation.
|
||||
# The default value is: YES.
|
||||
|
||||
GENERATE_BUGLIST = YES
|
||||
GENERATE_BUGLIST = NO
|
||||
|
||||
# The GENERATE_DEPRECATEDLIST tag can be used to enable (YES) or disable (NO)
|
||||
# the deprecated list. This list is created by putting \deprecated commands in
|
||||
@@ -686,7 +686,7 @@ GENERATE_DEPRECATEDLIST= YES
|
||||
# sections, marked by \if <section_label> ... \endif and \cond <section_label>
|
||||
# ... \endcond blocks.
|
||||
|
||||
ENABLED_SECTIONS =
|
||||
ENABLED_SECTIONS = doxygen
|
||||
|
||||
# The MAX_INITIALIZER_LINES tag determines the maximum number of lines that the
|
||||
# initial value of a variable or macro / define can have for it to appear in the
|
||||
@@ -829,7 +829,7 @@ WARN_LOGFILE =
|
||||
# spaces. See also FILE_PATTERNS and EXTENSION_MAPPING
|
||||
# Note: If this tag is empty the current directory is searched.
|
||||
|
||||
INPUT = .
|
||||
INPUT = overall.md intro.md usage.md mdbx.h ChangeLog.md
|
||||
|
||||
# This tag can be used to specify the character encoding of the source files
|
||||
# that doxygen parses. Internally doxygen uses the UTF-8 encoding. Doxygen uses
|
||||
@@ -856,53 +856,7 @@ INPUT_ENCODING = UTF-8
|
||||
# C comment), *.py, *.pyw, *.f90, *.f95, *.f03, *.f08, *.f, *.for, *.tcl, *.vhd,
|
||||
# *.vhdl, *.ucf, *.qsf and *.ice.
|
||||
|
||||
FILE_PATTERNS = *.c \
|
||||
*.cc \
|
||||
*.cxx \
|
||||
*.cpp \
|
||||
*.c++ \
|
||||
*.java \
|
||||
*.ii \
|
||||
*.ixx \
|
||||
*.ipp \
|
||||
*.i++ \
|
||||
*.inl \
|
||||
*.idl \
|
||||
*.ddl \
|
||||
*.odl \
|
||||
*.h \
|
||||
*.hh \
|
||||
*.hxx \
|
||||
*.hpp \
|
||||
*.h++ \
|
||||
*.cs \
|
||||
*.d \
|
||||
*.php \
|
||||
*.php4 \
|
||||
*.php5 \
|
||||
*.phtml \
|
||||
*.inc \
|
||||
*.m \
|
||||
*.markdown \
|
||||
*.md \
|
||||
*.mm \
|
||||
*.dox \
|
||||
*.doc \
|
||||
*.txt \
|
||||
*.py \
|
||||
*.pyw \
|
||||
*.f90 \
|
||||
*.f95 \
|
||||
*.f03 \
|
||||
*.f08 \
|
||||
*.f \
|
||||
*.for \
|
||||
*.tcl \
|
||||
*.vhd \
|
||||
*.vhdl \
|
||||
*.ucf \
|
||||
*.qsf \
|
||||
*.ice
|
||||
FILE_PATTERNS = *.h
|
||||
|
||||
# The RECURSIVE tag can be used to specify whether or not subdirectories should
|
||||
# be searched for input files as well.
|
||||
@@ -950,7 +904,7 @@ EXCLUDE_SYMBOLS =
|
||||
# that contain example code fragments that are included (see the \include
|
||||
# command).
|
||||
|
||||
EXAMPLE_PATH = example/
|
||||
EXAMPLE_PATH = ../
|
||||
|
||||
# If the value of the EXAMPLE_PATH tag contains directories, you can use the
|
||||
# EXAMPLE_PATTERNS tag to specify one or more wildcard pattern (like *.cpp and
|
||||
@@ -1526,7 +1480,7 @@ ECLIPSE_DOC_ID = org.doxygen.Project
|
||||
# The default value is: NO.
|
||||
# This tag requires that the tag GENERATE_HTML is set to YES.
|
||||
|
||||
DISABLE_INDEX = NO
|
||||
DISABLE_INDEX = YES
|
||||
|
||||
# The GENERATE_TREEVIEW tag is used to specify whether a tree-like index
|
||||
# structure should be generated to display hierarchical information. If the tag
|
||||
@@ -1543,7 +1497,7 @@ DISABLE_INDEX = NO
|
||||
# The default value is: NO.
|
||||
# This tag requires that the tag GENERATE_HTML is set to YES.
|
||||
|
||||
GENERATE_TREEVIEW = NO
|
||||
GENERATE_TREEVIEW = YES
|
||||
|
||||
# The ENUM_VALUES_PER_LINE tag can be used to set the number of enum values that
|
||||
# doxygen will group on one line in the generated HTML documentation.
|
||||
@@ -2199,7 +2153,7 @@ INCLUDE_FILE_PATTERNS =
|
||||
# recursively expanded use the := operator instead of the = operator.
|
||||
# This tag requires that the tag ENABLE_PREPROCESSING is set to YES.
|
||||
|
||||
PREDEFINED =
|
||||
PREDEFINED = DOXYGEN_SHOULD_SKIP_THIS
|
||||
|
||||
# If the MACRO_EXPANSION and EXPAND_ONLY_PREDEF tags are set to YES then this
|
||||
# tag can be used to specify a list of macro names that should be expanded. The
|
||||
@@ -2264,7 +2218,7 @@ EXTERNAL_GROUPS = YES
|
||||
# be listed.
|
||||
# The default value is: YES.
|
||||
|
||||
EXTERNAL_PAGES = YES
|
||||
EXTERNAL_PAGES = NO
|
||||
|
||||
#---------------------------------------------------------------------------
|
||||
# Configuration options related to the dot tool
|
||||
|
||||
47
docs/_preface.md
Normal file
47
docs/_preface.md
Normal file
@@ -0,0 +1,47 @@
|
||||
\page intro Introduction
|
||||
\section characteristics Characteristics
|
||||
|
||||
Preface {#preface}
|
||||
------------------
|
||||
|
||||
> For the most part, this section is a copy of the corresponding text
|
||||
> from LMDB description, but with some edits reflecting the improvements
|
||||
> and enhancements were made in MDBX.
|
||||
|
||||
MDBX is a Btree-based database management library modeled loosely on the
|
||||
BerkeleyDB API, but much simplified. The entire database (aka "environment")
|
||||
is exposed in a memory map, and all data fetches return data directly from
|
||||
the mapped memory, so no malloc's or memcpy's occur during data fetches.
|
||||
As such, the library is extremely simple because it requires no page caching
|
||||
layer of its own, and it is extremely high performance and memory-efficient.
|
||||
It is also fully transactional with full ACID semantics, and when the memory
|
||||
map is read-only, the database integrity cannot be corrupted by stray pointer
|
||||
writes from application code.
|
||||
|
||||
The library is fully thread-aware and supports concurrent read/write access
|
||||
from multiple processes and threads. Data pages use a copy-on-write strategy
|
||||
so no active data pages are ever overwritten, which also provides resistance
|
||||
to corruption and eliminates the need of any special recovery procedures
|
||||
after a system crash. Writes are fully serialized; only one write transaction
|
||||
may be active at a time, which guarantees that writers can never deadlock.
|
||||
The database structure is multi-versioned so readers run with no locks;
|
||||
writers cannot block readers, and readers don't block writers.
|
||||
|
||||
Unlike other well-known database mechanisms which use either write-ahead
|
||||
transaction logs or append-only data writes, MDBX requires no maintenance
|
||||
during operation. Both write-ahead loggers and append-only databases require
|
||||
periodic checkpointing and/or compaction of their log or database files
|
||||
otherwise they grow without bound. MDBX tracks retired/freed pages within the
|
||||
database and re-uses them for new write operations, so the database size does
|
||||
not grow without bound in normal use. It is worth noting that the "next"
|
||||
version libmdbx (MithrilDB) will solve this problem.
|
||||
|
||||
The memory map can be used as a read-only or read-write map. It is read-only
|
||||
by default as this provides total immunity to corruption. Using read-write
|
||||
mode offers much higher write performance, but adds the possibility for stray
|
||||
application writes thru pointers to silently corrupt the database.
|
||||
Of course if your application code is known to be bug-free (...) then this is
|
||||
not an issue.
|
||||
|
||||
If this is your first time using a transactional embedded key-value store,
|
||||
you may find the \ref starting section below to be helpful.
|
||||
174
docs/_restrictions.md
Normal file
174
docs/_restrictions.md
Normal file
@@ -0,0 +1,174 @@
|
||||
Restrictions & Caveats {#restrictions}
|
||||
======================
|
||||
In addition to those listed for some functions.
|
||||
|
||||
## Troubleshooting the LCK-file
|
||||
1. A broken LCK-file can cause sync issues, including appearance of
|
||||
wrong/inconsistent data for readers. When database opened in the
|
||||
cooperative read-write mode the LCK-file requires to be mapped to
|
||||
memory in read-write access. In this case it is always possible for
|
||||
stray/malfunctioned application could writes thru pointers to
|
||||
silently corrupt the LCK-file.
|
||||
|
||||
Unfortunately, there is no any portable way to prevent such
|
||||
corruption, since the LCK-file is updated concurrently by
|
||||
multiple processes in a lock-free manner and any locking is
|
||||
unwise due to a large overhead.
|
||||
|
||||
The "next" version of libmdbx (MithrilDB) will solve this issue.
|
||||
|
||||
\note Workaround: Just make all programs using the database close it;
|
||||
the LCK-file is always reset on first open.
|
||||
|
||||
2. Stale reader transactions left behind by an aborted program cause
|
||||
further writes to grow the database quickly, and stale locks can
|
||||
block further operation.
|
||||
MDBX checks for stale readers while opening environment and before
|
||||
growth the database. But in some cases, this may not be enough.
|
||||
|
||||
\note Workaround: Check for stale readers periodically, using the
|
||||
`mdbx_reader_check()` function or the mdbx_stat tool.
|
||||
|
||||
3. Stale writers will be cleared automatically by MDBX on supprted
|
||||
platforms. But this is platform-specific, especially of
|
||||
implementation of shared POSIX-mutexes and support for robust
|
||||
mutexes. For instance there are no known issues on Linux, OSX,
|
||||
Windows and FreeBSD.
|
||||
|
||||
\note Workaround: Otherwise just make all programs using the database
|
||||
close it; the LCK-file is always reset on first open
|
||||
of the environment.
|
||||
|
||||
|
||||
## Remote filesystems
|
||||
Do not use MDBX databases on remote filesystems, even between processes
|
||||
on the same host. This breaks file locks on some platforms, possibly
|
||||
memory map sync, and certainly sync between programs on different hosts.
|
||||
|
||||
On the other hand, MDBX support the exclusive database operation over
|
||||
a network, and cooperative read-only access to the database placed on
|
||||
a read-only network shares.
|
||||
|
||||
|
||||
## Child processes
|
||||
Do not use opened `MDBX_env` instance(s) in a child processes after `fork()`.
|
||||
It would be insane to call fork() and any MDBX-functions simultaneously
|
||||
from multiple threads. The best way is to prevent the presence of open
|
||||
MDBX-instances during `fork()`.
|
||||
|
||||
The `MDBX_TXN_CHECKPID` build-time option, which is ON by default on
|
||||
non-Windows platforms (i.e. where `fork()` is available), enables PID
|
||||
checking at a few critical points. But this does not give any guarantees,
|
||||
but only allows you to detect such errors a little sooner. Depending on
|
||||
the platform, you should expect an application crash and/or database
|
||||
corruption in such cases.
|
||||
|
||||
On the other hand, MDBX allow calling `mdbx_close_env()` in such cases to
|
||||
release resources, but no more and in general this is a wrong way.
|
||||
|
||||
## Read-only mode
|
||||
There is no pure read-only mode in a normal explicitly way, since
|
||||
readers need write access to LCK-file to be ones visible for writer.
|
||||
|
||||
So MDBX always tries to open/create LCK-file for read-write, but switches
|
||||
to without-LCK mode on appropriate errors (`EROFS`, `EACCESS`, `EPERM`)
|
||||
if the read-only mode was requested by the `MDBX_RDONLY` flag which is
|
||||
described below.
|
||||
|
||||
The "next" version of libmdbx (MithrilDB) will solve this issue for the "many
|
||||
readers without writer" case.
|
||||
|
||||
|
||||
## One thread - One transaction
|
||||
A thread can only use one transaction at a time, plus any nested
|
||||
read-write transactions in the non-writemap mode. Each transaction
|
||||
belongs to one thread. The `MDBX_NOTLS` flag changes this for read-only
|
||||
transactions. See below.
|
||||
|
||||
Do not start more than one transaction for a one thread. If you think
|
||||
about this, it's really strange to do something with two data snapshots
|
||||
at once, which may be different. MDBX checks and preventing this by
|
||||
returning corresponding error code (`MDBX_TXN_OVERLAPPING`, `MDBX_BAD_RSLOT`,
|
||||
`MDBX_BUSY`) unless you using `MDBX_NOTLS` option on the environment.
|
||||
Nonetheless, with the `MDBX_NOTLS` option, you must know exactly what you
|
||||
are doing, otherwise you will get deadlocks or reading an alien data.
|
||||
|
||||
|
||||
## Do not open twice
|
||||
Do not have open an MDBX database twice in the same process at the same
|
||||
time. By default MDBX prevent this in most cases by tracking databases
|
||||
opening and return `MDBX_BUSY` if anyone LCK-file is already open.
|
||||
|
||||
The reason for this is that when the "Open file description" locks (aka
|
||||
OFD-locks) are not available, MDBX uses POSIX locks on files, and these
|
||||
locks have issues if one process opens a file multiple times. If a single
|
||||
process opens the same environment multiple times, closing it once will
|
||||
remove all the locks held on it, and the other instances will be
|
||||
vulnerable to corruption from other processes.
|
||||
|
||||
For compatibility with LMDB which allows multi-opening, MDBX can be
|
||||
configured at runtime by `mdbx_setup_debug(MDBX_DBG_LEGACY_MULTIOPEN, ...)`
|
||||
prior to calling other MDBX funcitons. In this way MDBX will track
|
||||
databases opening, detect multi-opening cases and then recover POSIX file
|
||||
locks as necessary. However, lock recovery can cause unexpected pauses,
|
||||
such as when another process opened the database in exclusive mode before
|
||||
the lock was restored - we have to wait until such a process releases the
|
||||
database, and so on.
|
||||
|
||||
|
||||
## Long-lived read transactions
|
||||
Avoid long-lived read transactions, especially in the scenarios with a
|
||||
high rate of write transactions. Long-lived read transactions prevents
|
||||
recycling pages retired/freed by newer write transactions, thus the
|
||||
database can grow quickly.
|
||||
|
||||
Understanding the problem of long-lived read transactions requires some
|
||||
explanation, but can be difficult for quick perception. So is is
|
||||
reasonable to simplify this as follows:
|
||||
1. Garbage collection problem exists in all databases one way or
|
||||
another, e.g. VACUUM in PostgreSQL. But in MDBX it's even more
|
||||
discernible because of high transaction rate and intentional
|
||||
internals simplification in favor of performance.
|
||||
|
||||
2. MDBX employs Multiversion concurrency control on the Copy-on-Write
|
||||
basis, that allows multiple readers runs in parallel with a write
|
||||
transaction without blocking. An each write transaction needs free
|
||||
pages to put the changed data, that pages will be placed in the new
|
||||
b-tree snapshot at commit. MDBX efficiently recycling pages from
|
||||
previous created unused snapshots, BUT this is impossible if anyone
|
||||
a read transaction use such snapshot.
|
||||
|
||||
3. Thus massive altering of data during a parallel long read operation
|
||||
will increase the process's work set and may exhaust entire free
|
||||
database space.
|
||||
|
||||
A good example of long readers is a hot backup to the slow destination
|
||||
or debugging of a client application while retaining an active read
|
||||
transaction. LMDB this results in `MDBX_MAP_FULL` error and subsequent write
|
||||
performance degradation.
|
||||
|
||||
MDBX mostly solve "long-lived" readers issue by the lack-of-space callback
|
||||
which allow to aborts long readers, and by the `MDBX_LIFORECLAIM` mode which
|
||||
addresses subsequent performance degradation.
|
||||
The "next" version of libmdbx (MithrilDB) will completely solve this.
|
||||
|
||||
- Avoid suspending a process with active transactions. These would then be
|
||||
"long-lived" as above.
|
||||
|
||||
The "next" version of libmdbx (MithrilDB) will solve this issue.
|
||||
|
||||
- Avoid aborting a process with an active read-only transaction in scenaries
|
||||
with high rate of write transactions. The transaction becomes "long-lived"
|
||||
as above until a check for stale readers is performed or the LCK-file is
|
||||
reset, since the process may not remove it from the lockfile. This does
|
||||
not apply to write transactions if the system clears stale writers, see
|
||||
above.
|
||||
|
||||
|
||||
## Space reservation
|
||||
An MDBX database configuration will often reserve considerable unused
|
||||
memory address space and maybe file size for future growth. This does
|
||||
not use actual memory or disk space, but users may need to understand
|
||||
the difference so they won't be scared off.
|
||||
|
||||
\todo To write about the Read/Write Amplification Factors
|
||||
241
docs/_starting.md
Normal file
241
docs/_starting.md
Normal file
@@ -0,0 +1,241 @@
|
||||
Getting started {#starting}
|
||||
===============
|
||||
|
||||
> This section is based on Bert Hubert's intro "LMDB Semantics", with
|
||||
> edits reflecting the improvements and enhancements were made in MDBX.
|
||||
> See Bert Hubert's [original](https://github.com/ahupowerdns/ahutils/blob/master/lmdb-semantics.md).
|
||||
|
||||
Everything starts with an environment, created by `mdbx_env_create()`.
|
||||
Once created, this environment must also be opened with `mdbx_env_open()`,
|
||||
and after use be closed by `mdbx_env_close()`. At that a non-zero value of the
|
||||
last argument "mode" supposes MDBX will create database and directory if ones
|
||||
does not exist. In this case the non-zero "mode" argument specifies the file
|
||||
mode bits be applied when a new files are created by `open()` function.
|
||||
|
||||
Within that directory, a lock file (aka LCK-file) and a storage file (aka
|
||||
DXB-file) will be generated. If you don't want to use a directory, you can
|
||||
pass the `MDBX_NOSUBDIR` option, in which case the path you provided is used
|
||||
directly as the DXB-file, and another file with a "-lck" suffix added
|
||||
will be used for the LCK-file.
|
||||
|
||||
Once the environment is open, a transaction can be created within it using
|
||||
`mdbx_txn_begin()`. Transactions may be read-write or read-only, and read-write
|
||||
transactions may be nested. A transaction must only be used by one thread at
|
||||
a time. Transactions are always required, even for read-only access. The
|
||||
transaction provides a consistent view of the data.
|
||||
|
||||
Once a transaction has been created, a database (i.e. key-value space inside
|
||||
the environment) can be opened within it using `mdbx_dbi_open()`. If only one
|
||||
database will ever be used in the environment, a `NULL` can be passed as the
|
||||
database name. For named databases, the `MDBX_CREATE` flag must be used to
|
||||
create the database if it doesn't already exist. Also, `mdbx_env_set_maxdbs()`
|
||||
must be called after `mdbx_env_create()` and before `mdbx_env_open()` to set
|
||||
the maximum number of named databases you want to support.
|
||||
|
||||
\note A single transaction can open multiple databases. Generally databases
|
||||
should only be opened once, by the first transaction in the process.
|
||||
|
||||
Within a transaction, `mdbx_get()` and `mdbx_put()` can store single key-value
|
||||
pairs if that is all you need to do (but see \ref Cursors below if you want to do
|
||||
more).
|
||||
|
||||
A key-value pair is expressed as two `MDBX_val` structures. This struct that is
|
||||
exactly similar to POSIX's `struct iovec` and has two fields, `iov_len` and
|
||||
`iov_base`. The data is a `void` pointer to an array of `iov_len` bytes.
|
||||
\note The notable difference between MDBX and LMDB is that MDBX support zero
|
||||
length keys.
|
||||
|
||||
Because MDBX is very efficient (and usually zero-copy), the data returned in
|
||||
an `MDBX_val` structure may be memory-mapped straight from disk. In other words
|
||||
look but do not touch (or `free()` for that matter). Once a transaction is
|
||||
closed, the values can no longer be used, so make a copy if you need to keep
|
||||
them after that.
|
||||
|
||||
## Cursors {#Cursors}
|
||||
To do more powerful things, we must use a cursor.
|
||||
|
||||
Within the transaction, a cursor can be created with `mdbx_cursor_open()`.
|
||||
With this cursor we can store/retrieve/delete (multiple) values using
|
||||
`mdbx_cursor_get()`, `mdbx_cursor_put()` and `mdbx_cursor_del()`.
|
||||
|
||||
The `mdbx_cursor_get()` positions itself depending on the cursor operation
|
||||
requested, and for some operations, on the supplied key. For example, to list
|
||||
all key-value pairs in a database, use operation `MDBX_FIRST` for the first
|
||||
call to `mdbx_cursor_get()`, and `MDBX_NEXT` on subsequent calls, until the end
|
||||
is hit.
|
||||
|
||||
To retrieve all keys starting from a specified key value, use `MDBX_SET`. For
|
||||
more cursor operations, see the API description below.
|
||||
|
||||
When using `mdbx_cursor_put()`, either the function will position the cursor
|
||||
for you based on the key, or you can use operation `MDBX_CURRENT` to use the
|
||||
current position of the cursor. \note Note that key must then match the current
|
||||
position's key.
|
||||
|
||||
|
||||
## Summarizing the opening
|
||||
|
||||
So we have a cursor in a transaction which opened a database in an
|
||||
environment which is opened from a filesystem after it was separately
|
||||
created.
|
||||
|
||||
Or, we create an environment, open it from a filesystem, create a transaction
|
||||
within it, open a database within that transaction, and create a cursor
|
||||
within all of the above.
|
||||
|
||||
Got it?
|
||||
|
||||
|
||||
## Threads and processes
|
||||
|
||||
Do not have open an database twice in the same process at the same time, MDBX
|
||||
will track and prevent this. Instead, share the MDBX environment that has
|
||||
opened the file across all threads. The reason for this is:
|
||||
- When the "Open file description" locks (aka OFD-locks) are not available,
|
||||
MDBX uses POSIX locks on files, and these locks have issues if one process
|
||||
opens a file multiple times.
|
||||
- If a single process opens the same environment multiple times, closing it
|
||||
once will remove all the locks held on it, and the other instances will be
|
||||
vulnerable to corruption from other processes.
|
||||
+ For compatibility with LMDB which allows multi-opening, MDBX can be
|
||||
configured at runtime by `mdbx_setup_debug(MDBX_DBG_LEGACY_MULTIOPEN, ...)`
|
||||
prior to calling other MDBX funcitons. In this way MDBX will track
|
||||
databases opening, detect multi-opening cases and then recover POSIX file
|
||||
locks as necessary. However, lock recovery can cause unexpected pauses,
|
||||
such as when another process opened the database in exclusive mode before
|
||||
the lock was restored - we have to wait until such a process releases the
|
||||
database, and so on.
|
||||
|
||||
Do not use opened MDBX environment(s) after `fork()` in a child process(es),
|
||||
MDBX will check and prevent this at critical points. Instead, ensure there is
|
||||
no open MDBX-instance(s) during fork(), or atleast close it immediately after
|
||||
`fork()` in the child process and reopen if required - for instance by using
|
||||
`pthread_atfork()`. The reason for this is:
|
||||
- For competitive consistent reading, MDBX assigns a slot in the shared
|
||||
table for each process that interacts with the database. This slot is
|
||||
populated with process attributes, including the PID.
|
||||
- After `fork()`, in order to remain connected to a database, the child
|
||||
process must have its own such "slot", which can't be assigned in any
|
||||
simple and robust way another than the regular.
|
||||
- A write transaction from a parent process cannot continue in a child
|
||||
process for obvious reasons.
|
||||
- Moreover, in a multithreaded process at the fork() moment any number of
|
||||
threads could run in critical and/or intermediate sections of MDBX code
|
||||
with interaction and/or racing conditions with threads from other
|
||||
process(es). For instance: shrinking a database or copying it to a pipe,
|
||||
opening or closing environment, begining or finishing a transaction,
|
||||
and so on.
|
||||
= Therefore, any solution other than simply close database (and reopen if
|
||||
necessary) in a child process would be both extreme complicated and so
|
||||
fragile.
|
||||
|
||||
Do not start more than one transaction for a one thread. If you think about
|
||||
this, it's really strange to do something with two data snapshots at once,
|
||||
which may be different. MDBX checks and preventing this by returning
|
||||
corresponding error code (`MDBX_TXN_OVERLAPPING`, `MDBX_BAD_RSLOT`, `MDBX_BUSY`)
|
||||
unless you using `MDBX_NOTLS` option on the environment. Nonetheless, with the
|
||||
`MDBX_NOTLS option`, you must know exactly what you are doing, otherwise you
|
||||
will get deadlocks or reading an alien data.
|
||||
|
||||
Also note that a transaction is tied to one thread by default using Thread
|
||||
Local Storage. If you want to pass read-only transactions across threads,
|
||||
you can use the MDBX_NOTLS option on the environment. Nevertheless, a write
|
||||
transaction entirely should only be used in one thread from start to finish.
|
||||
MDBX checks this in a reasonable manner and return the MDBX_THREAD_MISMATCH
|
||||
error in rules violation.
|
||||
|
||||
|
||||
## Transactions, rollbacks etc
|
||||
|
||||
To actually get anything done, a transaction must be committed using
|
||||
`mdbx_txn_commit()`. Alternatively, all of a transaction's operations
|
||||
can be discarded using `mdbx_txn_abort()`.
|
||||
|
||||
\attention An important difference between MDBX and LMDB is that MDBX required
|
||||
that any opened cursors can be reused and must be freed explicitly, regardless
|
||||
ones was opened in a read-only or write transaction. The REASON for this is
|
||||
eliminates ambiguity which helps to avoid errors such as: use-after-free,
|
||||
double-free, i.e. memory corruption and segfaults.
|
||||
|
||||
For read-only transactions, obviously there is nothing to commit to storage.
|
||||
\attention An another notable difference between MDBX and LMDB is that MDBX make
|
||||
handles opened for existing databases immediately available for other
|
||||
transactions, regardless this transaction will be aborted or reset. The
|
||||
REASON for this is to avoiding the requirement for multiple opening a same
|
||||
handles in concurrent read transactions, and tracking of such open but hidden
|
||||
handles until the completion of read transactions which opened them.
|
||||
|
||||
In addition, as long as a transaction is open, a consistent view of the
|
||||
database is kept alive, which requires storage. A read-only transaction that
|
||||
no longer requires this consistent view should be terminated (committed or
|
||||
aborted) when the view is no longer needed (but see below for an
|
||||
optimization).
|
||||
|
||||
There can be multiple simultaneously active read-only transactions but only
|
||||
one that can write. Once a single read-write transaction is opened, all
|
||||
further attempts to begin one will block until the first one is committed or
|
||||
aborted. This has no effect on read-only transactions, however, and they may
|
||||
continue to be opened at any time.
|
||||
|
||||
|
||||
## Duplicate keys aka Multi-values
|
||||
|
||||
`mdbx_get()` and `mdbx_put()` respectively have no and only some support or
|
||||
multiple key-value pairs with identical keys. If there are multiple values
|
||||
for a key, `mdbx_get()` will only return the first value.
|
||||
|
||||
When multiple values for one key are required, pass the `MDBX_DUPSORT` flag to
|
||||
`mdbx_dbi_open()`. In an `MDBX_DUPSORT` database, by default `mdbx_put()` will
|
||||
not replace the value for a key if the key existed already. Instead it will add
|
||||
the new value to the key. In addition, `mdbx_del()` will pay attention to the
|
||||
value field too, allowing for specific values of a key to be deleted.
|
||||
|
||||
Finally, additional cursor operations become available for traversing through
|
||||
and retrieving duplicate values.
|
||||
|
||||
|
||||
## Some optimization
|
||||
|
||||
If you frequently begin and abort read-only transactions, as an optimization,
|
||||
it is possible to only reset and renew a transaction.
|
||||
|
||||
`mdbx_txn_reset()` releases any old copies of data kept around for a read-only
|
||||
transaction. To reuse this reset transaction, call `mdbx_txn_renew()` on it.
|
||||
Any cursors in this transaction can also be renewed using `mdbx_cursor_renew()`
|
||||
or freed by `mdbx_cursor_close()`.
|
||||
|
||||
To permanently free a transaction, reset or not, use `mdbx_txn_abort()`.
|
||||
|
||||
|
||||
## Cleaning up
|
||||
|
||||
Any created cursors must be closed using `mdbx_cursor_close()`. It is advisable
|
||||
to repeat:
|
||||
\note An important difference between MDBX and LMDB is that MDBX required that
|
||||
any opened cursors can be reused and must be freed explicitly, regardless
|
||||
ones was opened in a read-only or write transaction. The REASON for this is
|
||||
eliminates ambiguity which helps to avoid errors such as: use-after-free,
|
||||
double-free, i.e. memory corruption and segfaults.
|
||||
|
||||
It is very rarely necessary to close a database handle, and in general they
|
||||
should just be left open. When you close a handle, it immediately becomes
|
||||
unavailable for all transactions in the environment. Therefore, you should
|
||||
avoid closing the handle while at least one transaction is using it.
|
||||
|
||||
|
||||
## Now read up on the full API!
|
||||
|
||||
The full MDBX documentation lists further details below, like how to:
|
||||
|
||||
- configure database size and automatic size management
|
||||
- drop and clean a database
|
||||
- detect and report errors
|
||||
- optimize (bulk) loading speed
|
||||
- (temporarily) reduce robustness to gain even more speed
|
||||
- gather statistics about the database
|
||||
- estimate size of range query result
|
||||
- double perfomance by LIFO reclaiming on storages with write-back
|
||||
- use sequences and canary markers
|
||||
- use lack-of-space callback (aka OOM-KICK)
|
||||
- use exclusive mode
|
||||
- define custom sort orders (but this is recommended to be avoided)
|
||||
45
docs/_toc.md
Normal file
45
docs/_toc.md
Normal file
@@ -0,0 +1,45 @@
|
||||
|
||||
_The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо._
|
||||
|
||||
\section toc Table of Contents
|
||||
|
||||
This manual is divided into parts,
|
||||
each of which is divided into several sections.
|
||||
|
||||
1. The \ref intro
|
||||
- \ref characteristics
|
||||
- Preface
|
||||
- Features
|
||||
- Limitations
|
||||
- Gotchas
|
||||
- Comparison with other databases
|
||||
- \ref restrictions
|
||||
- \ref performance
|
||||
- Integral performance
|
||||
- Read Scalability
|
||||
- Sync-write mode
|
||||
- Lazy-write mode
|
||||
- Async-write mode
|
||||
- Cost comparison
|
||||
2. \ref usage
|
||||
- \ref getting
|
||||
- Embedding
|
||||
- Building
|
||||
- \ref starting
|
||||
- Opening
|
||||
- Cursors
|
||||
- Threads and processes
|
||||
- Transactions
|
||||
- Duplicate keys aka Multi-values
|
||||
- Cleaning up
|
||||
- \ref bindings
|
||||
|
||||
3. The `C` API reference manual:
|
||||
- TODO
|
||||
|
||||
Please do not hesitate to point out errors in the documentation,
|
||||
including creating [PR](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/proposing-changes-to-your-work-with-pull-requests) with corrections and improvements.
|
||||
|
||||
---
|
||||
|
||||
\section mithril Mithril DB
|
||||
577
mdbx.h
577
mdbx.h
@@ -1,11 +1,11 @@
|
||||
/*!
|
||||
|
||||
\file mdbx.h
|
||||
\brief The libmdbx C API header file
|
||||
|
||||
\mainpage One of the fastest embeddable key-value ACID database without WAL.
|
||||
|
||||
\section overview OVERVIEW
|
||||
_libmdbx_ is an extremely fast, compact, powerful, embedded,
|
||||
transactional [key-value
|
||||
store](https://en.wikipedia.org/wiki/Key-value_database) database, with
|
||||
[permissive license](./LICENSE). _MDBX_ has a specific set of properties and
|
||||
capabilities, focused on creating unique lightweight solutions with
|
||||
extraordinary performance.
|
||||
|
||||
_libmdbx_ is superior to [LMDB](https://bit.ly/26ts7tL) in terms of features
|
||||
and reliability, not inferior in performance. In comparison to LMDB, _libmdbx_
|
||||
@@ -14,474 +14,13 @@ break down. _libmdbx_ supports Linux, Windows, MacOS, OSX, iOS, Android,
|
||||
FreeBSD, DragonFly, Solaris, OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other
|
||||
systems compliant with POSIX.1-2008.
|
||||
|
||||
Look below for API description, for other information (build, embedding and
|
||||
amalgamation, improvements over LMDB, benchmarking, etc) please refer
|
||||
to [README](https://abf.io/erthink/libmdbx/README.md).
|
||||
_The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо._
|
||||
|
||||
|
||||
> The next version is under active non-public development and will be released
|
||||
> as _MithrilDB_ and `libmithrildb` for libraries & packages. Admittedly
|
||||
> mythical Mithril is resembling silver but being stronger and lighter than
|
||||
> steel. Therefore MithrilDB is a rightly relevant name.
|
||||
>
|
||||
> MithrilDB will be radically different from libmdbx by the new database format
|
||||
> and API based on C++17, as well as the Apache 2.0 License. The goal of this
|
||||
> revolution is to provide a clearer and robust API, add more features and new
|
||||
> valuable properties of database.
|
||||
|
||||
\motto The Future will (be) Positive. Всё будет хорошо.
|
||||
|
||||
|
||||
\section intro INTRODUCTION
|
||||
|
||||
> For the most part, this section is a copy of the corresponding text
|
||||
> from LMDB description, but with some edits reflecting the improvements
|
||||
> and enhancements were made in MDBX.
|
||||
|
||||
MDBX is a Btree-based database management library modeled loosely on the
|
||||
BerkeleyDB API, but much simplified. The entire database (aka "environment")
|
||||
is exposed in a memory map, and all data fetches return data directly from
|
||||
the mapped memory, so no malloc's or memcpy's occur during data fetches.
|
||||
As such, the library is extremely simple because it requires no page caching
|
||||
layer of its own, and it is extremely high performance and memory-efficient.
|
||||
It is also fully transactional with full ACID semantics, and when the memory
|
||||
map is read-only, the database integrity cannot be corrupted by stray pointer
|
||||
writes from application code.
|
||||
|
||||
The library is fully thread-aware and supports concurrent read/write access
|
||||
from multiple processes and threads. Data pages use a copy-on-write strategy
|
||||
so no active data pages are ever overwritten, which also provides resistance
|
||||
to corruption and eliminates the need of any special recovery procedures
|
||||
after a system crash. Writes are fully serialized; only one write transaction
|
||||
may be active at a time, which guarantees that writers can never deadlock.
|
||||
The database structure is multi-versioned so readers run with no locks;
|
||||
writers cannot block readers, and readers don't block writers.
|
||||
|
||||
Unlike other well-known database mechanisms which use either write-ahead
|
||||
transaction logs or append-only data writes, MDBX requires no maintenance
|
||||
during operation. Both write-ahead loggers and append-only databases require
|
||||
periodic checkpointing and/or compaction of their log or database files
|
||||
otherwise they grow without bound. MDBX tracks retired/freed pages within the
|
||||
database and re-uses them for new write operations, so the database size does
|
||||
not grow without bound in normal use. It is worth noting that the "next"
|
||||
version libmdbx (MithrilDB) will solve this problem.
|
||||
|
||||
The memory map can be used as a read-only or read-write map. It is read-only
|
||||
by default as this provides total immunity to corruption. Using read-write
|
||||
mode offers much higher write performance, but adds the possibility for stray
|
||||
application writes thru pointers to silently corrupt the database.
|
||||
Of course if your application code is known to be bug-free (...) then this is
|
||||
not an issue.
|
||||
|
||||
If this is your first time using a transactional embedded key-value store,
|
||||
you may find the "GETTING STARTED" section below to be helpful.
|
||||
|
||||
|
||||
\section start GETTING STARTED
|
||||
|
||||
> This section is based on Bert Hubert's intro "LMDB Semantics", with
|
||||
> edits reflecting the improvements and enhancements were made in MDBX.
|
||||
> See https://bit.ly/2maejGY for Bert Hubert's original.
|
||||
|
||||
Everything starts with an environment, created by `mdbx_env_create()`.
|
||||
Once created, this environment must also be opened with mdbx_env_open(),
|
||||
and after use be closed by `mdbx_env_close()`. At that a non-zero value of the
|
||||
last argument "mode" supposes MDBX will create database and directory if ones
|
||||
does not exist. In this case the non-zero "mode" argument specifies the file
|
||||
mode bits be applied when a new files are created by `open()` function.
|
||||
|
||||
Within that directory, a lock file (aka LCK-file) and a storage file (aka
|
||||
DXB-file) will be generated. If you don't want to use a directory, you can
|
||||
pass the `MDBX_NOSUBDIR` option, in which case the path you provided is used
|
||||
directly as the DXB-file, and another file with a "-lck" suffix added
|
||||
will be used for the LCK-file.
|
||||
|
||||
Once the environment is open, a transaction can be created within it using
|
||||
`mdbx_txn_begin()`. Transactions may be read-write or read-only, and read-write
|
||||
transactions may be nested. A transaction must only be used by one thread at
|
||||
a time. Transactions are always required, even for read-only access. The
|
||||
transaction provides a consistent view of the data.
|
||||
|
||||
Once a transaction has been created, a database (i.e. key-value space inside
|
||||
the environment) can be opened within it using `mdbx_dbi_open()`. If only one
|
||||
database will ever be used in the environment, a `NULL` can be passed as the
|
||||
database name. For named databases, the `MDBX_CREATE` flag must be used to
|
||||
create the database if it doesn't already exist. Also, mdbx_env_set_maxdbs()
|
||||
must be called after `mdbx_env_create()` and before `mdbx_env_open()` to set the
|
||||
maximum number of named databases you want to support.
|
||||
|
||||
\note A single transaction can open multiple databases. Generally databases
|
||||
should only be opened once, by the first transaction in the process.
|
||||
|
||||
Within a transaction, `mdbx_get()` and `mdbx_put()` can store single key-value
|
||||
pairs if that is all you need to do (but see CURSORS below if you want to do
|
||||
more).
|
||||
|
||||
A key-value pair is expressed as two `MDBX_val` structures. This struct that is
|
||||
exactly similar to POSIX's struct iovec and has two fields, iov_len and
|
||||
iov_base. The data is a void pointer to an array of iov_len bytes.
|
||||
\note The notable difference between MDBX and LMDB is that MDBX support zero
|
||||
length keys.
|
||||
|
||||
Because MDBX is very efficient (and usually zero-copy), the data returned in
|
||||
an MDBX_val structure may be memory-mapped straight from disk. In other words
|
||||
look but do not touch (or free() for that matter). Once a transaction is
|
||||
closed, the values can no longer be used, so make a copy if you need to keep
|
||||
them after that.
|
||||
|
||||
\subsection cursors CURSORS
|
||||
To do more powerful things, we must use a cursor.
|
||||
|
||||
Within the transaction, a cursor can be created with `mdbx_cursor_open()`.
|
||||
With this cursor we can store/retrieve/delete (multiple) values using
|
||||
`mdbx_cursor_get()`, `mdbx_cursor_put()` and `mdbx_cursor_del()`.
|
||||
|
||||
The `mdbx_cursor_get()` positions itself depending on the cursor operation
|
||||
requested, and for some operations, on the supplied key. For example, to list
|
||||
all key-value pairs in a database, use operation `MDBX_FIRST` for the first
|
||||
call to `mdbx_cursor_get()`, and `MDBX_NEXT` on subsequent calls, until the end
|
||||
is hit.
|
||||
|
||||
To retrieve all keys starting from a specified key value, use `MDBX_SET`. For
|
||||
more cursor operations, see the API description below.
|
||||
|
||||
When using `mdbx_cursor_put()`, either the function will position the cursor
|
||||
for you based on the key, or you can use operation `MDBX_CURRENT` to use the
|
||||
current position of the cursor. \note Note that key must then match the current
|
||||
position's key.
|
||||
|
||||
|
||||
\subsection opening SUMMARIZING THE OPENING
|
||||
|
||||
So we have a cursor in a transaction which opened a database in an
|
||||
environment which is opened from a filesystem after it was separately
|
||||
created.
|
||||
|
||||
Or, we create an environment, open it from a filesystem, create a transaction
|
||||
within it, open a database within that transaction, and create a cursor
|
||||
within all of the above.
|
||||
|
||||
Got it?
|
||||
|
||||
|
||||
\subsection threads THREADS AND PROCESSES
|
||||
|
||||
Do not have open an database twice in the same process at the same time, MDBX
|
||||
will track and prevent this. Instead, share the MDBX environment that has
|
||||
opened the file across all threads. The reason for this is:
|
||||
- When the "Open file description" locks (aka OFD-locks) are not available,
|
||||
MDBX uses POSIX locks on files, and these locks have issues if one process
|
||||
opens a file multiple times.
|
||||
- If a single process opens the same environment multiple times, closing it
|
||||
once will remove all the locks held on it, and the other instances will be
|
||||
vulnerable to corruption from other processes.
|
||||
+ For compatibility with LMDB which allows multi-opening, MDBX can be
|
||||
configured at runtime by `mdbx_setup_debug(MDBX_DBG_LEGACY_MULTIOPEN, ...)`
|
||||
prior to calling other MDBX funcitons. In this way MDBX will track
|
||||
databases opening, detect multi-opening cases and then recover POSIX file
|
||||
locks as necessary. However, lock recovery can cause unexpected pauses,
|
||||
such as when another process opened the database in exclusive mode before
|
||||
the lock was restored - we have to wait until such a process releases the
|
||||
database, and so on.
|
||||
|
||||
Do not use opened MDBX environment(s) after `fork()` in a child process(es),
|
||||
MDBX will check and prevent this at critical points. Instead, ensure there is
|
||||
no open MDBX-instance(s) during fork(), or atleast close it immediately after
|
||||
`fork()` in the child process and reopen if required - for instance by using
|
||||
`pthread_atfork()`. The reason for this is:
|
||||
- For competitive consistent reading, MDBX assigns a slot in the shared
|
||||
table for each process that interacts with the database. This slot is
|
||||
populated with process attributes, including the PID.
|
||||
- After `fork()`, in order to remain connected to a database, the child
|
||||
process must have its own such "slot", which can't be assigned in any
|
||||
simple and robust way another than the regular.
|
||||
- A write transaction from a parent process cannot continue in a child
|
||||
process for obvious reasons.
|
||||
- Moreover, in a multithreaded process at the fork() moment any number of
|
||||
threads could run in critical and/or intermediate sections of MDBX code
|
||||
with interaction and/or racing conditions with threads from other
|
||||
process(es). For instance: shrinking a database or copying it to a pipe,
|
||||
opening or closing environment, begining or finishing a transaction,
|
||||
and so on.
|
||||
= Therefore, any solution other than simply close database (and reopen if
|
||||
necessary) in a child process would be both extreme complicated and so
|
||||
fragile.
|
||||
|
||||
Do not start more than one transaction for a one thread. If you think about
|
||||
this, it's really strange to do something with two data snapshots at once,
|
||||
which may be different. MDBX checks and preventing this by returning
|
||||
corresponding error code (`MDBX_TXN_OVERLAPPING`, `MDBX_BAD_RSLOT`, `MDBX_BUSY`)
|
||||
unless you using `MDBX_NOTLS` option on the environment. Nonetheless, with the
|
||||
`MDBX_NOTLS option`, you must know exactly what you are doing, otherwise you
|
||||
will get deadlocks or reading an alien data.
|
||||
|
||||
Also note that a transaction is tied to one thread by default using Thread
|
||||
Local Storage. If you want to pass read-only transactions across threads,
|
||||
you can use the MDBX_NOTLS option on the environment. Nevertheless, a write
|
||||
transaction entirely should only be used in one thread from start to finish.
|
||||
MDBX checks this in a reasonable manner and return the MDBX_THREAD_MISMATCH
|
||||
error in rules violation.
|
||||
|
||||
|
||||
\subsection transactions TRANSACTIONS, ROLLBACKS, etc.
|
||||
|
||||
To actually get anything done, a transaction must be committed using
|
||||
`mdbx_txn_commit()`. Alternatively, all of a transaction's operations
|
||||
can be discarded using `mdbx_txn_abort()`.
|
||||
|
||||
\note An important difference between MDBX and LMDB is that MDBX required that
|
||||
any opened cursors can be reused and must be freed explicitly, regardless
|
||||
ones was opened in a read-only or write transaction. The REASON for this is
|
||||
eliminates ambiguity which helps to avoid errors such as: use-after-free,
|
||||
double-free, i.e. memory corruption and segfaults.
|
||||
|
||||
For read-only transactions, obviously there is nothing to commit to storage.
|
||||
\note An another notable difference between MDBX and LMDB is that MDBX make
|
||||
handles opened for existing databases immediately available for other
|
||||
transactions, regardless this transaction will be aborted or reset. The
|
||||
REASON for this is to avoiding the requirement for multiple opening a same
|
||||
handles in concurrent read transactions, and tracking of such open but hidden
|
||||
handles until the completion of read transactions which opened them.
|
||||
|
||||
In addition, as long as a transaction is open, a consistent view of the
|
||||
database is kept alive, which requires storage. A read-only transaction that
|
||||
no longer requires this consistent view should be terminated (committed or
|
||||
aborted) when the view is no longer needed (but see below for an
|
||||
optimization).
|
||||
|
||||
There can be multiple simultaneously active read-only transactions but only
|
||||
one that can write. Once a single read-write transaction is opened, all
|
||||
further attempts to begin one will block until the first one is committed or
|
||||
aborted. This has no effect on read-only transactions, however, and they may
|
||||
continue to be opened at any time.
|
||||
|
||||
|
||||
\subsection dups DUPLICATE KEYS aka MULTI-VALUEs
|
||||
|
||||
`mdbx_get()` and `mdbx_put()` respectively have no and only some support or
|
||||
multiple key-value pairs with identical keys. If there are multiple values
|
||||
for a key, `mdbx_get()` will only return the first value.
|
||||
|
||||
When multiple values for one key are required, pass the `MDBX_DUPSORT` flag to
|
||||
`mdbx_dbi_open()`. In an `MDBX_DUPSORT` database, by default `mdbx_put()` will
|
||||
not replace the value for a key if the key existed already. Instead it will add
|
||||
the new value to the key. In addition, `mdbx_del()` will pay attention to the
|
||||
value field too, allowing for specific values of a key to be deleted.
|
||||
|
||||
Finally, additional cursor operations become available for traversing through
|
||||
and retrieving duplicate values.
|
||||
|
||||
|
||||
\subsection optimization SOME OPTIMIZATION
|
||||
|
||||
If you frequently begin and abort read-only transactions, as an optimization,
|
||||
it is possible to only reset and renew a transaction.
|
||||
|
||||
`mdbx_txn_reset()` releases any old copies of data kept around for a read-only
|
||||
transaction. To reuse this reset transaction, call `mdbx_txn_renew()` on it.
|
||||
Any cursors in this transaction can also be renewed using `mdbx_cursor_renew()`
|
||||
or freed by `mdbx_cursor_close()`.
|
||||
|
||||
To permanently free a transaction, reset or not, use `mdbx_txn_abort()`.
|
||||
|
||||
|
||||
\subsection cleanup CLEANING UP
|
||||
|
||||
Any created cursors must be closed using `mdbx_cursor_close()`. It is advisable
|
||||
to repeat:
|
||||
\note An important difference between MDBX and LMDB is that MDBX required that
|
||||
any opened cursors can be reused and must be freed explicitly, regardless
|
||||
ones was opened in a read-only or write transaction. The REASON for this is
|
||||
eliminates ambiguity which helps to avoid errors such as: use-after-free,
|
||||
double-free, i.e. memory corruption and segfaults.
|
||||
|
||||
It is very rarely necessary to close a database handle, and in general they
|
||||
should just be left open. When you close a handle, it immediately becomes
|
||||
unavailable for all transactions in the environment. Therefore, you should
|
||||
avoid closing the handle while at least one transaction is using it.
|
||||
|
||||
|
||||
\subsection api THE FULL API
|
||||
|
||||
The full MDBX documentation lists further details below, like how to:
|
||||
|
||||
- configure database size and automatic size management
|
||||
- drop and clean a database
|
||||
- detect and report errors
|
||||
- optimize (bulk) loading speed
|
||||
- (temporarily) reduce robustness to gain even more speed
|
||||
- gather statistics about the database
|
||||
- estimate size of range query result
|
||||
- double perfomance by LIFO reclaiming on storages with write-back
|
||||
- use sequences and canary markers
|
||||
- use lack-of-space callback (aka OOM-KICK)
|
||||
- use exclusive mode
|
||||
- define custom sort orders (but this is recommended to be avoided)
|
||||
|
||||
\section restrictions RESTRICTIONS & CAVEATS
|
||||
in addition to those listed for some functions.
|
||||
|
||||
- Troubleshooting the LCK-file.
|
||||
1. A broken LCK-file can cause sync issues, including appearance of
|
||||
wrong/inconsistent data for readers. When database opened in the
|
||||
cooperative read-write mode the LCK-file requires to be mapped to
|
||||
memory in read-write access. In this case it is always possible for
|
||||
stray/malfunctioned application could writes thru pointers to
|
||||
silently corrupt the LCK-file.
|
||||
|
||||
Unfortunately, there is no any portable way to prevent such
|
||||
corruption, since the LCK-file is updated concurrently by
|
||||
multiple processes in a lock-free manner and any locking is
|
||||
unwise due to a large overhead.
|
||||
|
||||
The "next" version of libmdbx (MithrilDB) will solve this issue.
|
||||
|
||||
Workaround: Just make all programs using the database close it;
|
||||
the LCK-file is always reset on first open.
|
||||
|
||||
2. Stale reader transactions left behind by an aborted program cause
|
||||
further writes to grow the database quickly, and stale locks can
|
||||
block further operation.
|
||||
MDBX checks for stale readers while opening environment and before
|
||||
growth the database. But in some cases, this may not be enough.
|
||||
|
||||
Workaround: Check for stale readers periodically, using the
|
||||
`mdbx_reader_check()` function or the mdbx_stat tool.
|
||||
|
||||
3. Stale writers will be cleared automatically by MDBX on supprted
|
||||
platforms. But this is platform-specific, especially of
|
||||
implementation of shared POSIX-mutexes and support for robust
|
||||
mutexes. For instance there are no known issues on Linux, OSX,
|
||||
Windows and FreeBSD.
|
||||
|
||||
Workaround: Otherwise just make all programs using the database
|
||||
close it; the LCK-file is always reset on first open
|
||||
of the environment.
|
||||
|
||||
- Do not use MDBX databases on remote filesystems, even between processes
|
||||
on the same host. This breaks file locks on some platforms, possibly
|
||||
memory map sync, and certainly sync between programs on different hosts.
|
||||
|
||||
On the other hand, MDBX support the exclusive database operation over
|
||||
a network, and cooperative read-only access to the database placed on
|
||||
a read-only network shares.
|
||||
|
||||
- Do not use opened `MDBX_env` instance(s) in a child processes after `fork()`.
|
||||
It would be insane to call fork() and any MDBX-functions simultaneously
|
||||
from multiple threads. The best way is to prevent the presence of open
|
||||
MDBX-instances during `fork()`.
|
||||
|
||||
The `MDBX_TXN_CHECKPID` build-time option, which is ON by default on
|
||||
non-Windows platforms (i.e. where `fork()` is available), enables PID
|
||||
checking at a few critical points. But this does not give any guarantees,
|
||||
but only allows you to detect such errors a little sooner. Depending on
|
||||
the platform, you should expect an application crash and/or database
|
||||
corruption in such cases.
|
||||
|
||||
On the other hand, MDBX allow calling `mdbx_close_env()` in such cases to
|
||||
release resources, but no more and in general this is a wrong way.
|
||||
|
||||
- There is no pure read-only mode in a normal explicitly way, since
|
||||
readers need write access to LCK-file to be ones visible for writer.
|
||||
MDBX always tries to open/create LCK-file for read-write, but switches
|
||||
to without-LCK mode on appropriate errors (`EROFS`, `EACCESS`, `EPERM`)
|
||||
if the read-only mode was requested by the `MDBX_RDONLY` flag which is
|
||||
described below.
|
||||
|
||||
The "next" version of libmdbx (MithrilDB) will solve this issue.
|
||||
|
||||
- A thread can only use one transaction at a time, plus any nested
|
||||
read-write transactions in the non-writemap mode. Each transaction
|
||||
belongs to one thread. The `MDBX_NOTLS` flag changes this for read-only
|
||||
transactions. See below.
|
||||
|
||||
Do not start more than one transaction for a one thread. If you think
|
||||
about this, it's really strange to do something with two data snapshots
|
||||
at once, which may be different. MDBX checks and preventing this by
|
||||
returning corresponding error code (`MDBX_TXN_OVERLAPPING`, `MDBX_BAD_RSLOT`,
|
||||
`MDBX_BUSY`) unless you using `MDBX_NOTLS` option on the environment.
|
||||
Nonetheless, with the `MDBX_NOTLS` option, you must know exactly what you
|
||||
are doing, otherwise you will get deadlocks or reading an alien data.
|
||||
|
||||
- Do not have open an MDBX database twice in the same process at the same
|
||||
time. By default MDBX prevent this in most cases by tracking databases
|
||||
opening and return `MDBX_BUSY` if anyone LCK-file is already open.
|
||||
|
||||
The reason for this is that when the "Open file description" locks (aka
|
||||
OFD-locks) are not available, MDBX uses POSIX locks on files, and these
|
||||
locks have issues if one process opens a file multiple times. If a single
|
||||
process opens the same environment multiple times, closing it once will
|
||||
remove all the locks held on it, and the other instances will be
|
||||
vulnerable to corruption from other processes.
|
||||
|
||||
For compatibility with LMDB which allows multi-opening, MDBX can be
|
||||
configured at runtime by `mdbx_setup_debug(MDBX_DBG_LEGACY_MULTIOPEN, ...)`
|
||||
prior to calling other MDBX funcitons. In this way MDBX will track
|
||||
databases opening, detect multi-opening cases and then recover POSIX file
|
||||
locks as necessary. However, lock recovery can cause unexpected pauses,
|
||||
such as when another process opened the database in exclusive mode before
|
||||
the lock was restored - we have to wait until such a process releases the
|
||||
database, and so on.
|
||||
|
||||
- Avoid long-lived read transactions, especially in the scenarios with a
|
||||
high rate of write transactions. Long-lived read transactions prevents
|
||||
recycling pages retired/freed by newer write transactions, thus the
|
||||
database can grow quickly.
|
||||
|
||||
Understanding the problem of long-lived read transactions requires some
|
||||
explanation, but can be difficult for quick perception. So is is
|
||||
reasonable to simplify this as follows:
|
||||
1. Garbage collection problem exists in all databases one way or
|
||||
another, e.g. VACUUM in PostgreSQL. But in MDBX it's even more
|
||||
discernible because of high transaction rate and intentional
|
||||
internals simplification in favor of performance.
|
||||
|
||||
2. MDBX employs Multiversion concurrency control on the Copy-on-Write
|
||||
basis, that allows multiple readers runs in parallel with a write
|
||||
transaction without blocking. An each write transaction needs free
|
||||
pages to put the changed data, that pages will be placed in the new
|
||||
b-tree snapshot at commit. MDBX efficiently recycling pages from
|
||||
previous created unused snapshots, BUT this is impossible if anyone
|
||||
a read transaction use such snapshot.
|
||||
|
||||
3. Thus massive altering of data during a parallel long read operation
|
||||
will increase the process's work set and may exhaust entire free
|
||||
database space.
|
||||
|
||||
A good example of long readers is a hot backup to the slow destination
|
||||
or debugging of a client application while retaining an active read
|
||||
transaction. LMDB this results in `MDBX_MAP_FULL` error and subsequent write
|
||||
performance degradation.
|
||||
|
||||
MDBX mostly solve "long-lived" readers issue by the lack-of-space callback
|
||||
which allow to aborts long readers, and by the `MDBX_LIFORECLAIM` mode which
|
||||
addresses subsequent performance degradation.
|
||||
The "next" version of libmdbx (MithrilDB) will completely solve this.
|
||||
|
||||
- Avoid suspending a process with active transactions. These would then be
|
||||
"long-lived" as above.
|
||||
|
||||
The "next" version of libmdbx (MithrilDB) will solve this issue.
|
||||
|
||||
- Avoid aborting a process with an active read-only transaction in scenaries
|
||||
with high rate of write transactions. The transaction becomes "long-lived"
|
||||
as above until a check for stale readers is performed or the LCK-file is
|
||||
reset, since the process may not remove it from the lockfile. This does
|
||||
not apply to write transactions if the system clears stale writers, see
|
||||
above.
|
||||
|
||||
- An MDBX database configuration will often reserve considerable unused
|
||||
memory address space and maybe file size for future growth. This does
|
||||
not use actual memory or disk space, but users may need to understand
|
||||
the difference so they won't be scared off.
|
||||
|
||||
- \todo The Write Amplification Factor.
|
||||
|
||||
|
||||
\section license LICENSE & COPYRIGHT
|
||||
\section copyright LICENSE & COPYRIGHT
|
||||
|
||||
\authors Copyright 2015-2020 Leonid Yuriev <leo@yuriev.ru>
|
||||
and other _libmdbx_ authors: please see AUTHORS file.
|
||||
and other _libmdbx_ authors: please see [AUTHORS](./AUTHORS) file.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted only as authorized by the OpenLDAP Public License.
|
||||
@@ -524,16 +63,12 @@ WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
|
||||
OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
|
||||
\subsection asknowledgements ACKNOWLEDGEMENTS
|
||||
|
||||
Howard Chu (Symas Corporation) - the author of LMDB,
|
||||
from which originated the MDBX in 2015.
|
||||
|
||||
Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code,
|
||||
which was used for begin development of LMDB.
|
||||
|
||||
*******************************************************************************/
|
||||
|
||||
/**
|
||||
\file mdbx.h
|
||||
\brief The libmdbx C API header file
|
||||
*/
|
||||
#pragma once
|
||||
#ifndef LIBMDBX_H
|
||||
#define LIBMDBX_H
|
||||
@@ -577,6 +112,10 @@ typedef pthread_t mdbx_tid_t;
|
||||
#pragma warning(pop)
|
||||
#endif
|
||||
|
||||
/**
|
||||
\defgroup api_macros Common Macros
|
||||
@{ */
|
||||
|
||||
/*----------------------------------------------------------------------------*/
|
||||
|
||||
#ifndef __has_attribute
|
||||
@@ -677,8 +216,8 @@ typedef pthread_t mdbx_tid_t;
|
||||
|
||||
#ifndef DEFINE_ENUM_FLAG_OPERATORS
|
||||
#if defined(__cplusplus)
|
||||
// Define operator overloads to enable bit operations on enum values that are
|
||||
// used to define flags (based on Microsoft's DEFINE_ENUM_FLAG_OPERATORS).
|
||||
/// Define operator overloads to enable bit operations on enum values that are
|
||||
/// used to define flags (based on Microsoft's DEFINE_ENUM_FLAG_OPERATORS).
|
||||
#define DEFINE_ENUM_FLAG_OPERATORS(ENUM) \
|
||||
extern "C++" { \
|
||||
cxx11_constexpr ENUM operator|(ENUM a, ENUM b) { \
|
||||
@@ -716,44 +255,46 @@ typedef pthread_t mdbx_tid_t;
|
||||
#endif
|
||||
#endif /* LIBMDBX_API */
|
||||
|
||||
/**
|
||||
@} The end of Common Macros
|
||||
\defgroup c_api C API
|
||||
@{ */
|
||||
|
||||
#ifdef __cplusplus
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
/**** MDBX version information ************************************************/
|
||||
|
||||
#if defined(LIBMDBX_IMPORTS)
|
||||
#define LIBMDBX_VERINFO_API __dll_import
|
||||
#else
|
||||
#define LIBMDBX_VERINFO_API __dll_export
|
||||
#endif /* LIBMDBX_VERINFO_API */
|
||||
|
||||
typedef struct mdbx_version_info {
|
||||
uint8_t major;
|
||||
uint8_t minor;
|
||||
uint16_t release;
|
||||
uint32_t revision;
|
||||
struct /** source info from git */ {
|
||||
const char *datetime /** committer date, strict ISO-8601 format */;
|
||||
const char *tree /** commit hash (hexadecimal digits) */;
|
||||
const char *commit /** tree hash, i.e. digest of the source code */;
|
||||
const char *describe /** git-describe string */;
|
||||
} git;
|
||||
const char *sourcery /** sourcery anchor for pinning */;
|
||||
} mdbx_version_info;
|
||||
extern LIBMDBX_VERINFO_API const mdbx_version_info mdbx_version;
|
||||
/** MDBX version information */
|
||||
extern LIBMDBX_VERINFO_API const struct MDBX_version_info {
|
||||
uint8_t major; /**< Major version number */
|
||||
uint8_t minor; /**< Minor version number */
|
||||
uint16_t release; /**< Release number of Major.Minor */
|
||||
uint32_t revision; /**< Revision number of Release */
|
||||
struct {
|
||||
const char *datetime; /**< committer date, strict ISO-8601 format */
|
||||
const char *tree; /**< commit hash (hexadecimal digits) */
|
||||
const char *commit; /**< tree hash, i.e. digest of the source code */
|
||||
const char *describe; /**< git-describe string */
|
||||
} git; /**< source information from git */
|
||||
const char *sourcery; /**< sourcery anchor for pinning */
|
||||
} mdbx_version;
|
||||
|
||||
/** MDBX build information.
|
||||
* \warning Some strings could be NULL in case no corresponding information was
|
||||
* provided at build time (i.e. flags). */
|
||||
typedef struct mdbx_build_info {
|
||||
const char *datetime /** build timestamp (ISO-8601 or __DATE__ __TIME__) */;
|
||||
const char *target /** cpu/arch-system-config triplet */;
|
||||
const char *options /** mdbx-related options */;
|
||||
const char *compiler /** compiler */;
|
||||
const char *flags /** CFLAGS */;
|
||||
} mdbx_build_info;
|
||||
extern LIBMDBX_VERINFO_API const mdbx_build_info mdbx_build;
|
||||
/** MDBX build information
|
||||
\attention Some strings could be NULL in case no corresponding information was
|
||||
provided at build time (i.e. flags). */
|
||||
extern LIBMDBX_VERINFO_API const struct MDBX_build_info {
|
||||
const char *datetime; /**< build timestamp (ISO-8601 or __DATE__ __TIME__) */
|
||||
const char *target; /**< cpu/arch-system-config triplet */
|
||||
const char *options; /**< mdbx-related options */
|
||||
const char *compiler; /**< compiler */
|
||||
const char *flags; /**< CFLAGS and CXXFLAGS */
|
||||
} mdbx_build;
|
||||
|
||||
#if defined(_WIN32) || defined(_WIN64)
|
||||
#if !MDBX_BUILD_SHARED_LIBRARY
|
||||
@@ -805,9 +346,8 @@ void LIBMDBX_API NTAPI mdbx_dll_handler(PVOID module, DWORD reason,
|
||||
/**** OPACITY STRUCTURES ******************************************************/
|
||||
|
||||
/** Opaque structure for a database environment.
|
||||
*
|
||||
* \details n environment supports multiple key-value databases (aka key-value
|
||||
* spaces or tables), all residing in the same shared-memory map. */
|
||||
\details An environment supports multiple key-value databases (aka key-value
|
||||
spaces or tables), all residing in the same shared-memory map. */
|
||||
#ifndef __cplusplus
|
||||
typedef struct MDBX_env MDBX_env;
|
||||
#else
|
||||
@@ -815,9 +355,8 @@ struct MDBX_env;
|
||||
#endif
|
||||
|
||||
/** Opaque structure for a transaction handle.
|
||||
*
|
||||
* \details All database operations require a transaction handle. Transactions
|
||||
* may be read-only or read-write. */
|
||||
\details All database operations require a transaction handle. Transactions
|
||||
may be read-only or read-write. */
|
||||
#ifndef __cplusplus
|
||||
typedef struct MDBX_txn MDBX_txn;
|
||||
#else
|
||||
@@ -847,7 +386,7 @@ struct MDBX_cursor;
|
||||
* The same applies to data sizes in databases with the MDBX_DUPSORT flag.
|
||||
* Other data items can in theory be from 0 to 0x7fffffff bytes long.
|
||||
*
|
||||
* (!) The notable difference between MDBX and LMDB is that MDBX support zero
|
||||
* \note The notable difference between MDBX and LMDB is that MDBX support zero
|
||||
* length keys. */
|
||||
#ifndef HAVE_STRUCT_IOVEC
|
||||
struct iovec {
|
||||
@@ -1089,7 +628,7 @@ enum MDBX_env_flags_t {
|
||||
* read-write mode. This offers a significant performance benefit, since the
|
||||
* data will be modified directly in mapped memory and then flushed to disk by
|
||||
* single system call, without any memory management nor copying.
|
||||
* (!) On the other hand, MDBX_WRITEMAP adds the possibility for stray
|
||||
* \note On the other hand, MDBX_WRITEMAP adds the possibility for stray
|
||||
* application writes thru pointers to silently corrupt the database.
|
||||
* Moreover, MDBX_WRITEMAP disallows nested write transactions.
|
||||
*
|
||||
@@ -1394,14 +933,14 @@ enum MDBX_env_flags_t {
|
||||
/** Don't sync anything but keep previous steady commits,
|
||||
* see description in the "SYNC MODES" section above.
|
||||
*
|
||||
* (!) don't combine this flag with MDBX_MAPASYNC
|
||||
* \note don't combine this flag with MDBX_MAPASYNC
|
||||
* since you will got MDBX_UTTERLY_NOSYNC in that way (see below) */
|
||||
MDBX_SAFE_NOSYNC = UINT32_C(0x10000),
|
||||
|
||||
/** Use asynchronous msync when MDBX_WRITEMAP is used,
|
||||
* see description in the "SYNC MODES" section above.
|
||||
*
|
||||
* (!) don't combine this flag with MDBX_SAFE_NOSYNC
|
||||
* \note don't combine this flag with MDBX_SAFE_NOSYNC
|
||||
* since you will got MDBX_UTTERLY_NOSYNC in that way (see below) */
|
||||
MDBX_MAPASYNC = UINT32_C(0x100000),
|
||||
|
||||
@@ -2757,7 +2296,7 @@ typedef int(MDBX_cmp_func)(const MDBX_val *a, const MDBX_val *b);
|
||||
* discarded by calling mdbx_dbi_close(). The old database handle is returned if
|
||||
* the database was already open. The handle may only be closed once.
|
||||
*
|
||||
* (!) A notable difference between MDBX and LMDB is that MDBX make handles
|
||||
* \note A notable difference between MDBX and LMDB is that MDBX make handles
|
||||
* opened for existing databases immediately available for other transactions,
|
||||
* regardless this transaction will be aborted or reset. The REASON for this is
|
||||
* to avoiding the requirement for multiple opening a same handles in concurrent
|
||||
@@ -3896,6 +3435,8 @@ LIBMDBX_API int mdbx_get_attr(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key,
|
||||
MDBX_val *data, mdbx_attr_t *attrptr);
|
||||
#endif /* MDBX_NEXENTA_ATTRS */
|
||||
|
||||
/** @} The end of C API */
|
||||
|
||||
/*******************************************************************************
|
||||
* Workaround for mmaped-lookahead-cross-page-boundary bug
|
||||
* in an obsolete versions of Elbrus's libc and kernels. */
|
||||
|
||||
@@ -18820,7 +18820,7 @@ __dll_export
|
||||
__has_attribute(__externally_visible__)
|
||||
__attribute__((__externally_visible__))
|
||||
#endif
|
||||
const mdbx_build_info mdbx_build = {
|
||||
const struct MDBX_build_info mdbx_build = {
|
||||
#ifdef MDBX_BUILD_TIMESTAMP
|
||||
MDBX_BUILD_TIMESTAMP
|
||||
#else
|
||||
|
||||
@@ -22,7 +22,7 @@ __dll_export
|
||||
__has_attribute(__externally_visible__)
|
||||
__attribute__((__externally_visible__))
|
||||
#endif
|
||||
const mdbx_version_info mdbx_version = {
|
||||
const struct MDBX_version_info mdbx_version = {
|
||||
${MDBX_VERSION_MAJOR},
|
||||
${MDBX_VERSION_MINOR},
|
||||
${MDBX_VERSION_RELEASE},
|
||||
|
||||
Reference in New Issue
Block a user