mirror of
https://github.com/isar/libmdbx.git
synced 2026-03-21 16:49:15 +08:00
mdbx: minor README fixes.
Change-Id: Ib49a2eea78043274ab96e0b7ad78241ad38bb432
This commit is contained in:
110
README.md
110
README.md
@@ -9,10 +9,10 @@ database, with [permissive license](LICENSE).
|
||||
_MDBX_ has a specific set of properties and capabilities,
|
||||
focused on creating unique lightweight solutions with extraordinary performance.
|
||||
|
||||
1. Allows **swarm of multi-threaded processes to
|
||||
1. Allows **a swarm of multi-threaded processes to
|
||||
[ACID]((https://en.wikipedia.org/wiki/ACID))ly read and update** several
|
||||
key-value [maps](https://en.wikipedia.org/wiki/Associative_array) and
|
||||
[multimaps](https://en.wikipedia.org/wiki/Multimap) in a localy-shared
|
||||
[multimaps](https://en.wikipedia.org/wiki/Multimap) in a locally-shared
|
||||
database.
|
||||
|
||||
2. Provides **extraordinary performance**, minimal overhead through
|
||||
@@ -20,11 +20,11 @@ database.
|
||||
`Olog(N)` operations costs by virtue of [B+
|
||||
tree](https://en.wikipedia.org/wiki/B%2B_tree).
|
||||
|
||||
3. Requires **no maintenance and no crash recovery** since doesn't use
|
||||
3. Requires **no maintenance and no crash recovery** since it doesn't use
|
||||
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging), but that might
|
||||
be a caveat for write-intensive workloads with durability requirements.
|
||||
|
||||
4. **Compact and friendly for fully embeddeding**. Only 25KLOC of `C11`,
|
||||
4. **Compact and friendly for fully embedding**. Only 25KLOC of `C11`,
|
||||
64K x86 binary code, no internal threads neither processes, but
|
||||
implements a simplified variant of the [Berkeley
|
||||
DB](https://en.wikipedia.org/wiki/Berkeley_DB) and
|
||||
@@ -44,20 +44,20 @@ neglected in favour of write performance.
|
||||
OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with
|
||||
**POSIX.1-2008**.
|
||||
|
||||
Historically, _MDBX_ is deeply revised and extended descendant of amazing
|
||||
Historically, _MDBX_ is a deeply revised and extended descendant of the amazing
|
||||
[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
|
||||
_MDBX_ inherits all benefits from _LMDB_, but resolves some issues and adds [set of improvements](#improvements-beyond-lmdb).
|
||||
_MDBX_ inherits all benefits from _LMDB_, but resolves some issues and adds [a set of improvements](#improvements-beyond-lmdb).
|
||||
|
||||
The next version is under active non-public development from scratch and will be
|
||||
released as **_MithrilDB_** and `libmithrildb` for libraries & packages.
|
||||
Admittedly mythical [Mithril](https://en.wikipedia.org/wiki/Mithril) is
|
||||
resembling silver but being stronger and lighter than steel. Therefore
|
||||
_MithrilDB_ is rightly relevant name.
|
||||
_MithrilDB_ is a rightly relevant name.
|
||||
> _MithrilDB_ will be radically different from _libmdbx_ by the new
|
||||
> database format and API based on C++17, as well as the [Apache 2.0
|
||||
> License](https://www.apache.org/licenses/LICENSE-2.0). The goal of this
|
||||
> revolution is to provide a clearer and robust API, add more features and
|
||||
> new valuable properties of database.
|
||||
> new valuable properties of the database.
|
||||
|
||||
[](https://t.me/libmdbx)
|
||||
[](https://travis-ci.org/erthink/libmdbx)
|
||||
@@ -112,13 +112,13 @@ and [CoW](https://en.wikipedia.org/wiki/Copy-on-write).
|
||||
|
||||
- Transactions for readers and writers, ones do not block others.
|
||||
|
||||
- Writes are strongly serialized. No transactions conflicts nor deadlocks.
|
||||
- Writes are strongly serialized. No transaction conflicts nor deadlocks.
|
||||
|
||||
- Readers are [non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm), notwithstanding [snapshot isolation](https://en.wikipedia.org/wiki/Snapshot_isolation).
|
||||
|
||||
- Nested write transactions.
|
||||
|
||||
- Reads scales linearly across CPUs.
|
||||
- Reads scale linearly across CPUs.
|
||||
|
||||
- Continuous zero-overhead database compactification.
|
||||
|
||||
@@ -153,7 +153,7 @@ transaction journal. No crash recovery needed. No maintenance is required.
|
||||
2. MDBX is based on [B+ tree](https://en.wikipedia.org/wiki/B%2B_tree), so access to database pages is mostly random.
|
||||
Thus SSDs provide a significant performance boost over spinning disks for large databases.
|
||||
|
||||
3. MDBX uses [shadow paging](https://en.wikipedia.org/wiki/Shadow_paging) instead of [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). Thus syncing data to disk might be bottleneck for write intensive workload.
|
||||
3. MDBX uses [shadow paging](https://en.wikipedia.org/wiki/Shadow_paging) instead of [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). Thus syncing data to disk might be a bottleneck for write intensive workload.
|
||||
|
||||
4. MDBX uses [copy-on-write](https://en.wikipedia.org/wiki/Copy-on-write) for [snapshot isolation](https://en.wikipedia.org/wiki/Snapshot_isolation) during updates, but read transactions prevents recycling an old retired/freed pages, since it read ones. Thus altering of data during a parallel
|
||||
long-lived read operation will increase the process work set, may exhaust entire free database space,
|
||||
@@ -161,9 +161,9 @@ the database can grow quickly, and result in performance degradation.
|
||||
Try to avoid long running read transactions.
|
||||
|
||||
5. MDBX is extraordinarily fast and provides minimal overhead for data access,
|
||||
so you should reconsider about use brute force techniques and double check your code.
|
||||
so you should reconsider using brute force techniques and double check your code.
|
||||
On the one hand, in the case of MDBX, a simple linear search may be more profitable than complex indexes.
|
||||
On the other hand, if you make something suboptimally, you can notice a detrimentally only on sufficiently large data.
|
||||
On the other hand, if you make something suboptimally, you can notice detrimentally only on sufficiently large data.
|
||||
|
||||
### Comparison with other databases
|
||||
For now please refer to [chapter of "BoltDB comparison with other
|
||||
@@ -189,13 +189,13 @@ the user's point of view.
|
||||
|
||||
2. Up to 20% faster than _LMDB_ in [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) benchmarks.
|
||||
> Benchmarks of the in-[tmpfs](https://en.wikipedia.org/wiki/Tmpfs) scenarios,
|
||||
> that tests the speed of engine itself, shown that _libmdbx_ 10-20% faster than _LMDB_.
|
||||
> These and other results could be easily reproduced with [ioArena](https://github.com/pmwkaa/ioarena) just by `make bench-quartet`,
|
||||
> that tests the speed of the engine itself, showned that _libmdbx_ 10-20% faster than _LMDB_.
|
||||
> These and other results could be easily reproduced with [ioArena](https://github.com/pmwkaa/ioarena) just by `make bench-quartet` command,
|
||||
> including comparisons with [RockDB](https://en.wikipedia.org/wiki/RocksDB)
|
||||
> and [WiredTiger](https://en.wikipedia.org/wiki/WiredTiger).
|
||||
|
||||
3. Automatic on-the-fly database size adjustment, both increment and reduction.
|
||||
> _libmdbx_ manage the database size according to parameters specified
|
||||
> _libmdbx_ manages the database size according to parameters specified
|
||||
> by `mdbx_env_set_geometry()` function,
|
||||
> ones include the growth step and the truncation threshold.
|
||||
>
|
||||
@@ -204,19 +204,19 @@ the user's point of view.
|
||||
|
||||
4. Automatic continuous zero-overhead database compactification.
|
||||
> During each commit _libmdbx_ merges suitable freeing pages into unallocated area
|
||||
> at the end of file, and then truncate unused space when a lot enough of.
|
||||
> at the end of file, and then truncates unused space when a lot enough of.
|
||||
|
||||
5. The same database format for 32- and 64-bit builds.
|
||||
> _libmdbx_ database format depends only on the [endianness](https://en.wikipedia.org/wiki/Endianness) but not on the [bitness](https://en.wiktionary.org/wiki/bitness).
|
||||
|
||||
6. LIFO policy for Garbage Collection recycling. This can significantly increase write performance due write-back disk cache up to several times in a best case scenario.
|
||||
> LIFO means that for reuse will be taken latest became unused pages.
|
||||
> LIFO means that for reuse will be taken the latest becames unused pages.
|
||||
> Therefore the loop of database pages circulation becomes as short as possible.
|
||||
> In other words, the set of pages, that are (over)written in memory and on disk during a series of write transactions, will be as small as possible.
|
||||
> Thus creates ideal conditions for the battery-backed or flash-backed disk cache efficiency.
|
||||
|
||||
7. Fast estimation of range query result volume, i.e. how many items can
|
||||
be found between a `KEY1` and a `KEY2`. This is prerequisite for build
|
||||
be found between a `KEY1` and a `KEY2`. This is a prerequisite for build
|
||||
and/or optimize query execution plans.
|
||||
> _libmdbx_ performs a rough estimate based on common B-tree pages of the paths from root to corresponding keys.
|
||||
|
||||
@@ -228,7 +228,7 @@ and/or optimize query execution plans.
|
||||
|
||||
11. Callback for lack-of-space condition of database that allows you to control and/or resolve such situations.
|
||||
|
||||
12. Support for opening database in the exclusive mode, including on a network share.
|
||||
12. Support for opening databases in the exclusive mode, including on a network share.
|
||||
|
||||
### Added Abilities:
|
||||
|
||||
@@ -245,14 +245,14 @@ pair, to the first, to the last, or not set to anything.
|
||||
> for a write transaction, reading lag and holdover space for read transactions.
|
||||
|
||||
5. Extended update and delete operations.
|
||||
> _libmdbx_ allows ones _at once_ with getting previous value
|
||||
> _libmdbx_ allows one _at once_ with getting previous value
|
||||
> and addressing the particular item from multi-value with the same key.
|
||||
|
||||
### Other fixes and specifics:
|
||||
|
||||
1. Fixed more than 10 significant errors, in particular: page leaks, wrong sub-database statistics, segfault in several conditions, unoptimal page merge strategy, updating an existing record with a change in data size (including for multimap), etc.
|
||||
1. Fixed more than 10 significant errors, in particular: page leaks, wrong sub-database statistics, segfault in several conditions, nonoptimal page merge strategy, updating an existing record with a change in data size (including for multimap), etc.
|
||||
|
||||
2. All cursors can be reused and should be closed explicitly, regardless ones were opened within write or read transaction.
|
||||
2. All cursors can be reused and should be closed explicitly, regardless ones were opened within a write or read transaction.
|
||||
|
||||
3. Opening database handles are spared from race conditions and
|
||||
pre-opening is not needed.
|
||||
@@ -262,15 +262,15 @@ pre-opening is not needed.
|
||||
5. Guarantee of database integrity even in asynchronous unordered write-to-disk mode.
|
||||
> _libmdbx_ propose additional trade-off by implementing append-like manner for updates
|
||||
> in `MDBX_SAFE_NOSYNC` and `MDBX_WRITEMAP|MDBX_MAPASYNC` modes, that avoid database corruption after a system crash
|
||||
> contrary to LMDB. Nevertheless, the `MDBX_UTTERLY_NOSYNC` mode available to match LMDB behaviour,
|
||||
> and for a special use-cases.
|
||||
> contrary to LMDB. Nevertheless, the `MDBX_UTTERLY_NOSYNC` mode is available to match LMDB behaviour,
|
||||
> and for special use-cases.
|
||||
|
||||
6. On **MacOS & iOS** the `fcntl(F_FULLFSYNC)` syscall is used _by
|
||||
default_ to synchronize data with the disk, as this is [the only way to
|
||||
guarantee data
|
||||
durability](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man2/fsync.2.html)
|
||||
in case of power failure. Unfortunately, in scenarios with high write
|
||||
intensity, the use of `F_FULLFSYNC` significant degrades performance
|
||||
intensity, the use of `F_FULLFSYNC` significantly degrades performance
|
||||
compared to LMDB, where the `fsync()` syscall is used. Therefore,
|
||||
_libmdbx_ allows you to override this behavior by defining the
|
||||
`MDBX_OSX_SPEED_INSTEADOF_DURABILITY=1` option while build the library.
|
||||
@@ -279,13 +279,13 @@ _libmdbx_ allows you to override this behavior by defining the
|
||||
it allows place the database on network drives, and provides protection
|
||||
against incompetent user actions (aka
|
||||
[poka-yoke](https://en.wikipedia.org/wiki/Poka-yoke)). Therefore
|
||||
_libmdbx_ may be a little lag in performance tests from LMDB where a
|
||||
_libmdbx_ may be a little lag in performance tests from LMDB where the
|
||||
named mutexes are used.
|
||||
|
||||
### History
|
||||
At first the development was carried out within the
|
||||
[ReOpenLDAP](https://github.com/erthink/ReOpenLDAP) project. About a
|
||||
year later _libmdbx_ was separated into standalone project, which was
|
||||
year later _libmdbx_ was separated into a standalone project, which was
|
||||
[presented at Highload++ 2015
|
||||
conference](http://www.highload.ru/2015/abstracts/1831.html).
|
||||
|
||||
@@ -297,7 +297,7 @@ Howard Chu <hyc@openldap.org> is the author of LMDB, from which
|
||||
originated the MDBX in 2015.
|
||||
|
||||
Martin Hedenfalk <martin@bzero.se> is the author of `btree.c` code, which
|
||||
was used for begin development of LMDB.
|
||||
was used to begin development of LMDB.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@@ -309,7 +309,7 @@ Usage
|
||||
_libmdbx_ provides two official ways for integration in source code form:
|
||||
|
||||
1. Using the amalgamated source code.
|
||||
> The amalgamated source code includes all files requires to build and
|
||||
> The amalgamated source code includes all files required to build and
|
||||
> use _libmdbx_, but not for testing _libmdbx_ itself.
|
||||
|
||||
2. Adding the complete original source code as a `git submodule`.
|
||||
@@ -319,7 +319,7 @@ _libmdbx_ provides two official ways for integration in source code form:
|
||||
**_Please, avoid using any other techniques._** Otherwise, at least
|
||||
don't ask for support and don't name such chimeras `libmdbx`.
|
||||
|
||||
The amalgamated source code could be created from original clone of git
|
||||
The amalgamated source code could be created from the original clone of git
|
||||
repository on Linux by executing `make dist`. As a result, the desired
|
||||
set of files will be formed in the `dist` subdirectory.
|
||||
|
||||
@@ -335,7 +335,7 @@ are completely traditional and have minimal prerequirements like
|
||||
target platform. Obviously you need building tools itself, i.e. `git`,
|
||||
`cmake` or GNU `make` with `bash`.
|
||||
|
||||
So just use CMake or GNU Make in your habitual manner and feel free to
|
||||
So just using CMake or GNU Make in your habitual manner and feel free to
|
||||
fill an issue or make pull request in the case something will be
|
||||
unexpected or broken down.
|
||||
|
||||
@@ -367,7 +367,7 @@ where there are no similar bugs in the pthreads implementation.
|
||||
|
||||
### Linux and other platforms with GNU Make
|
||||
To build the library it is enough to execute `make all` in the directory
|
||||
of source code, and `make check` for execute the basic tests.
|
||||
of source code, and `make check` to execute the basic tests.
|
||||
|
||||
If the `make` installed on the system is not GNU Make, there will be a
|
||||
lot of errors from make when trying to build. In this case, perhaps you
|
||||
@@ -380,14 +380,14 @@ Make is called by the gmake command or may be missing. In addition,
|
||||
|
||||
You need to install the required components: GNU Make, bash, C and C++
|
||||
compilers compatible with GCC or CLANG. After that, to build the
|
||||
library, it is enough execute `gmake all` (or `make all`) in the
|
||||
library, it is enough to execute `gmake all` (or `make all`) in the
|
||||
directory with source code, and `gmake check` (or `make check`) to run
|
||||
the basic tests.
|
||||
|
||||
### Windows
|
||||
For build _libmdbx_ on Windows the _original_ CMake and [Microsoft Visual
|
||||
Studio 2019](https://en.wikipedia.org/wiki/Microsoft_Visual_Studio) are
|
||||
recommended. Otherwise do not forget add `ntdll.lib` to linking.
|
||||
recommended. Otherwise do not forget to add `ntdll.lib` to linking.
|
||||
|
||||
Building by MinGW, MSYS or Cygwin is potentially possible. However,
|
||||
these scripts are not tested and will probably require you to modify the
|
||||
@@ -395,15 +395,22 @@ CMakeLists.txt or Makefile respectively.
|
||||
|
||||
It should be noted that in _libmdbx_ was efforts to resolve
|
||||
runtime dependencies from CRT and other libraries Visual Studio.
|
||||
For this is enough define the `MDBX_AVOID_CRT` during build.
|
||||
For this is enough to define the `MDBX_AVOID_CRT` during build.
|
||||
|
||||
An example of running a basic test script can be found in the
|
||||
[CI-script](appveyor.yml) for [AppVeyor](https://www.appveyor.com/). To
|
||||
run the [long stochastic test scenario](test/long_stochastic.sh),
|
||||
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) is required, and
|
||||
the such testing is recommended with place the test data on the
|
||||
such testing is recommended with placing the test data on the
|
||||
[RAM-disk](https://en.wikipedia.org/wiki/RAM_drive).
|
||||
|
||||
### Windows Subsystem for Linux
|
||||
_libmdbx_ could be used in [WSL2](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_2)
|
||||
but NOT in [WSL1](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_1) environment.
|
||||
This is a consequence of the fundamental shortcomings of _WSL1_ and cannot be fixed.
|
||||
To avoid data loss, _libmdbx_ returns the `ENOLCK` (37, "No record locks available")
|
||||
error when opening the database in a _WSL1_ environment.
|
||||
|
||||
### MacOS
|
||||
Current [native build tools](https://en.wikipedia.org/wiki/Xcode) for
|
||||
MacOS include GNU Make, CLANG and an outdated version of bash.
|
||||
@@ -427,13 +434,6 @@ To build _libmdbx_ for iOS, we recommend using CMake with the
|
||||
"[toolchain file](https://cmake.org/cmake/help/latest/variable/CMAKE_TOOLCHAIN_FILE.html)"
|
||||
from the [ios-cmake](https://github.com/leetal/ios-cmake) project.
|
||||
|
||||
### Windows Subsystem for Linux
|
||||
_libmdbx_ could be using in [WSL2](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_2)
|
||||
but NOT in [WSL1](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_1) environment.
|
||||
This is a consequence of the fundamental shortcomings of _WSL1_ and cannot be fixed.
|
||||
To avoid data loss, _libmdbx_ returns the `ENOLCK` (37, "No record locks available")
|
||||
error when opening the database in a _WSL1_ environment.
|
||||
|
||||
## API description
|
||||
For more information and API description see the [mdbx.h](mdbx.h) header.
|
||||
Please do not hesitate to point out errors in the documentation,
|
||||
@@ -461,7 +461,7 @@ SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
|
||||
|
||||
Here showed sum of performance metrics in 3 benchmarks:
|
||||
|
||||
- Read/Search on machine with 4 logical CPU in HyperThreading mode (i.e. actually 2 physical CPU cores);
|
||||
- Read/Search on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores);
|
||||
|
||||
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD)
|
||||
operations in sync-write mode (fdatasync is called after each
|
||||
@@ -486,7 +486,7 @@ Here showed sum of performance metrics in 3 benchmarks:
|
||||
## Read Scalability
|
||||
|
||||
Summary performance with concurrent read/search queries in 1-2-4-8
|
||||
threads on machine with 4 logical CPU in HyperThreading mode (i.e. actually 2 physical CPU cores).
|
||||
threads on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores).
|
||||
|
||||
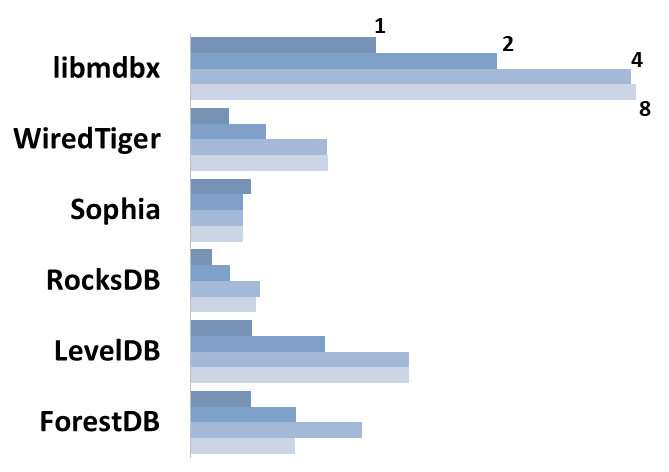
|
||||
|
||||
@@ -502,12 +502,12 @@ threads on machine with 4 logical CPU in HyperThreading mode (i.e. actually 2 ph
|
||||
execution time, cross marks standard deviation.
|
||||
|
||||
**10,000 transactions in sync-write mode**. In case of a crash all data
|
||||
is consistent and state is right after last successful transaction.
|
||||
is consistent and conforms to the last successful transaction. The
|
||||
[fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after
|
||||
each write transaction in this mode.
|
||||
|
||||
In the benchmark each transaction contains combined CRUD operations (2
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database
|
||||
and after full run the database contains 10,000 small key-value records.
|
||||
|
||||
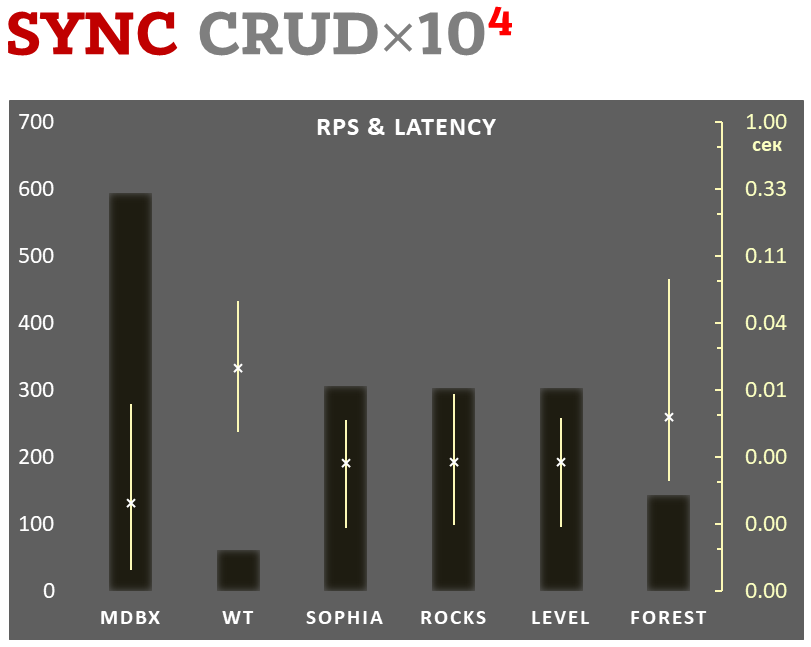
|
||||
@@ -524,15 +524,15 @@ and after full run the database contains 10,000 small key-value records.
|
||||
execution time, cross marks standard deviation.
|
||||
|
||||
**100,000 transactions in lazy-write mode**. In case of a crash all data
|
||||
is consistent and state is right after one of last transactions, but
|
||||
is consistent and conforms to the one of last successful transactions, but
|
||||
transactions after it will be lost. Other DB engines use
|
||||
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction
|
||||
journal for that, which in turn depends on order of operations in
|
||||
journal for that, which in turn depends on order of operations in the
|
||||
journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations
|
||||
to filesystem and OS kernel (mmap).
|
||||
|
||||
In the benchmark each transaction contains combined CRUD operations (2
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database
|
||||
and after full run the database contains 100,000 small key-value
|
||||
records.
|
||||
|
||||
@@ -550,15 +550,13 @@ records.
|
||||
execution time of transactions. Each interval shows minimal and maximum
|
||||
execution time, cross marks standard deviation.
|
||||
|
||||
**1,000,000 transactions in async-write mode**. In case of a crash all
|
||||
data will be consistent and state will be right after one of last
|
||||
transactions, but lost transaction count is much higher than in
|
||||
**1,000,000 transactions in async-write mode**. In case of a crash all data is consistent and conforms to the one of last successful transactions, but lost transaction count is much higher than in
|
||||
lazy-write mode. All DB engines in this mode do as little writes as
|
||||
possible on persistent storage. _libmdbx_ uses
|
||||
[msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode.
|
||||
|
||||
In the benchmark each transaction contains combined CRUD operations (2
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
|
||||
inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database
|
||||
and after full run the database contains 10,000 small key-value records.
|
||||
|
||||
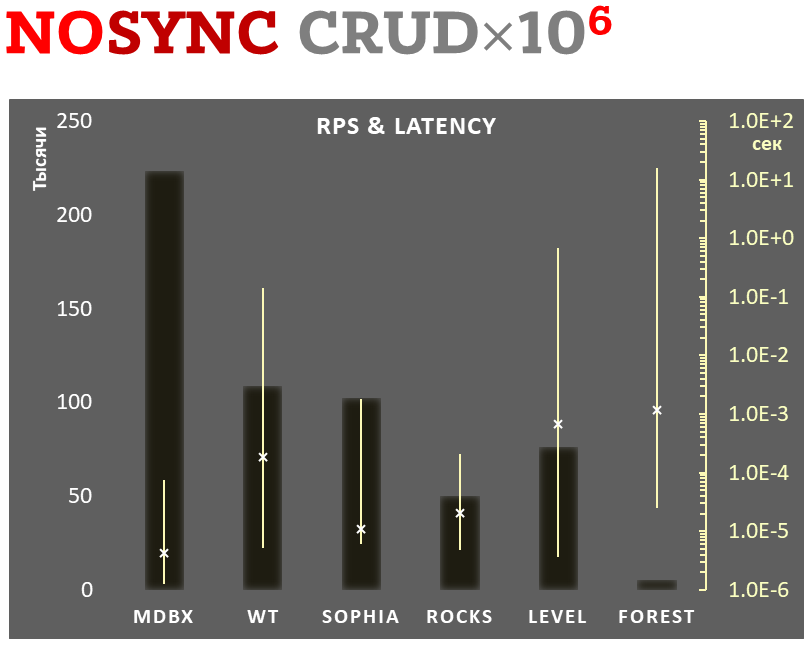
|
||||
@@ -583,7 +581,7 @@ which prevents to meaningfully compare it with them.
|
||||
|
||||
All benchmark data is gathered by
|
||||
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html)
|
||||
syscall and by scanning data directory.
|
||||
syscall and by scanning the data directory.
|
||||
|
||||
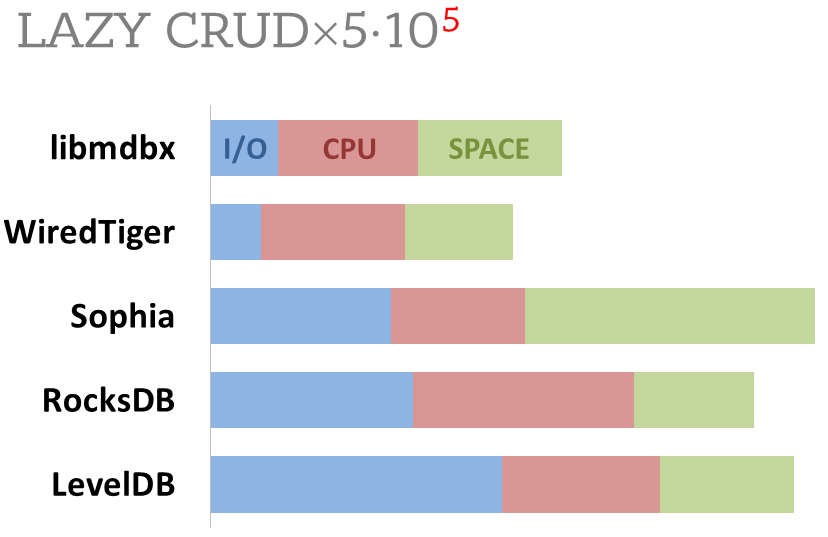
|
||||
|
||||
|
||||
Reference in New Issue
Block a user